连接器同步规则
编辑连接器同步规则
编辑使用连接器同步规则来帮助控制第三方数据源和 Elasticsearch 之间同步的文档。在 Kibana UI 中为每个连接器索引定义同步规则,位于该索引的 同步规则 选项卡下。
可用性和先决条件
编辑在 Elastic 8.8.0 及更高版本中,所有连接器都支持基本同步规则。
一些连接器支持高级同步规则。请在各个连接器的参考文档中了解更多信息。
同步规则类型
编辑有两种类型的同步规则
- 基本同步规则 - 这些规则以表格视图的形式呈现。基本同步规则对于所有连接器都是相同的。
- 高级同步规则 - 这些规则涵盖了无法用基本同步规则表达的复杂查询和过滤场景。高级同步规则通过特定于源的 DSL JSON 代码段定义。
通用数据过滤概念
编辑在讨论同步规则之前,务必先建立对数据过滤概念的基本理解。下图显示数据过滤可能发生在几个不同的过程/位置。
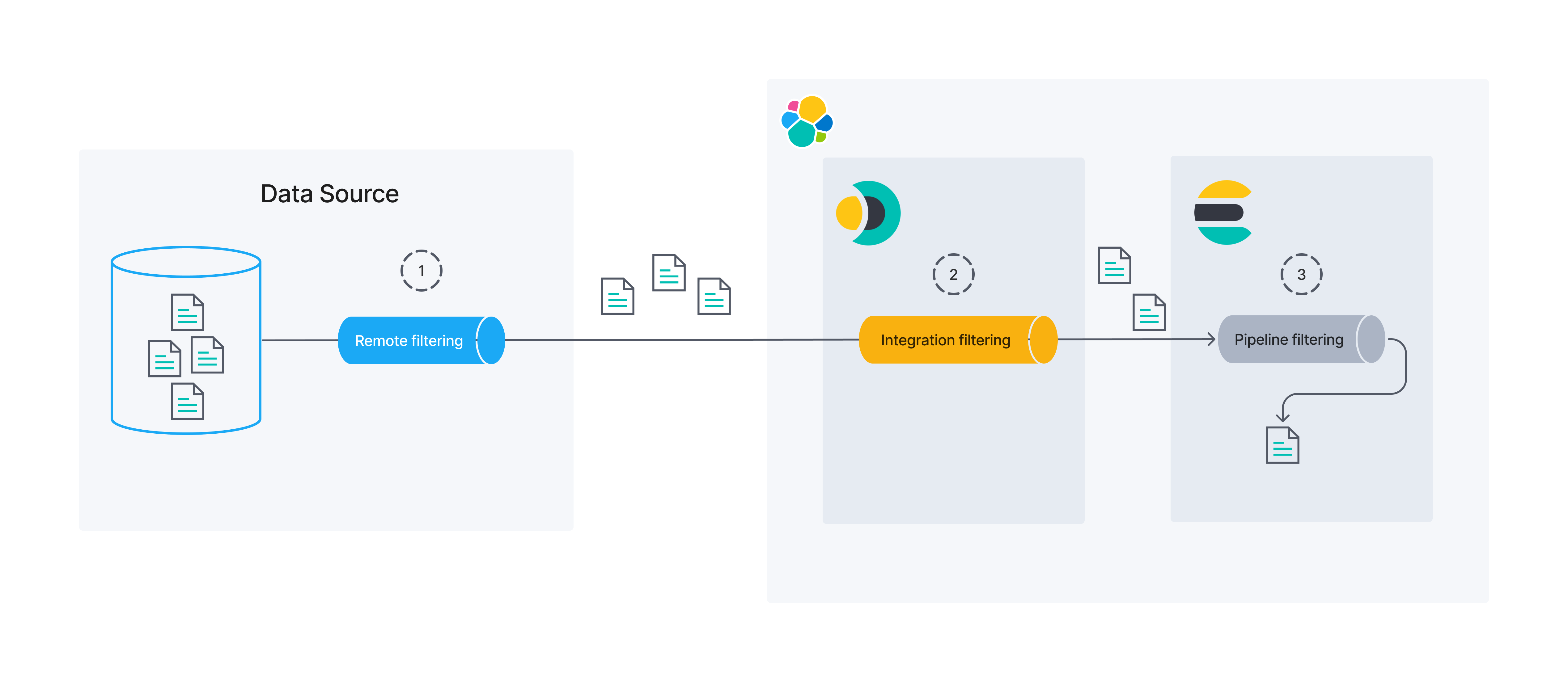
本文档将重点介绍远程和集成过滤。同步规则可用于修改这两者。
远程过滤
编辑数据可能在其源头被过滤。我们称之为远程过滤,因为过滤过程在 Elastic 之外。
集成过滤
编辑集成过滤充当原始数据源和 Elasticsearch 之间的桥梁。在连接器中进行的过滤是集成过滤的一个示例。
管道过滤
编辑最后,Elasticsearch 可以在使用摄取管道持久化之前过滤数据。在本指南中,我们不会重点介绍摄取管道过滤。
目前,基本同步规则是控制连接器集成过滤的唯一方法。请记住,远程过滤的范围远远超出了连接器的范围。为了获得最佳结果,请与数据源的所有者和维护者合作。确保源数据组织良好,并针对连接器进行的查询类型进行了优化。
同步规则概述
编辑在大多数情况下,您的数据湖将包含比您希望向最终用户公开的更多数据。例如,您可能希望搜索产品目录,但不包括供应商联系信息,即使两者出于商业目的而位于同一位置。
过滤数据的最佳时间是在数据管道中的早期。主要有两个原因:
- 性能:向备份数据源发送查询比获取所有数据然后在连接器中过滤它更有效。通过网络发送较小的数据集并在连接器端对其进行处理更快。
- 安全性:查询时过滤在数据源端应用,因此数据不会通过网络发送到连接器中,从而限制了数据的暴露。
在理想情况下,所有过滤都将作为远程过滤完成。
然而,在实践中,这并不总是可能的。某些源不允许强大的远程过滤。其他源允许,但需要特殊设置(在特定字段上构建索引、调整设置等),这可能需要您组织中其他利益相关者的关注。
考虑到这一点,同步规则旨在修改远程过滤和集成过滤。您的目标应该是尽可能多地进行远程过滤,但集成是一个完全可行的后备方案。根据定义,远程过滤在从第三方源获取数据之前应用。集成过滤在从第三方源获取数据之后应用,但在将其摄取到 Elasticsearch 索引之前应用。
所有同步规则在任何摄取管道对给定文档运行之前应用。因此,您可以将摄取管道用于任何必须在集成过滤发生之后进行的处理。
如果添加、编辑或删除了同步规则,它将在下一次完全同步后才会生效。
基本同步规则
编辑每个基本同步规则可以是两种“策略”之一:include 和 exclude。Include 规则用于包含“匹配”指定条件的文档。Exclude 规则用于排除“匹配”指定条件的文档。
“匹配”是根据由“字段”、“规则”和“值”的组合定义的条件确定的。
应使用 字段 列来定义应考虑给定文档上的哪个字段。
以下规则在 规则 列中可用
-
equals- 字段值等于指定的值。 -
starts_with- 字段值以指定的(字符串)值开头。 -
ends_with- 字段值以指定的(字符串)值结尾。 -
contains- 字段值包含指定的(字符串)值。 -
regex- 字段值与指定的正则表达式匹配。 -
>- 字段值大于指定的值。 -
<- 字段值小于指定的值。
最后,值 列取决于
- 指定“字段”中的数据类型
- 选择了哪个“规则”。
例如,[A-Z]{2} 的值对于 regex 规则可能很有意义,但对于 > 规则则不然。同样,当对 ip_address 字段进行操作时,您可能不会有 espresso 的值,但对于 beverage 字段,您可能会有。
基本同步规则示例
编辑示例 1
编辑排除所有 ID 字段值大于 1000 的文档。

示例 2
编辑排除所有 state 字段与指定正则表达式匹配的文档。

性能影响
编辑- 如果您仅依赖于集成过滤阶段中的基本同步规则,则连接器将从数据源获取所有数据
- 对于没有自动分页或类似优化的数据源,获取所有数据可能会导致内存问题。例如,加载一次太大而无法放入内存的数据集。
Elastic 提供的本机 MongoDB 连接器使用分页,因此具有优化的性能。请记住,自定义社区构建的自管理连接器可能没有这些性能优化。
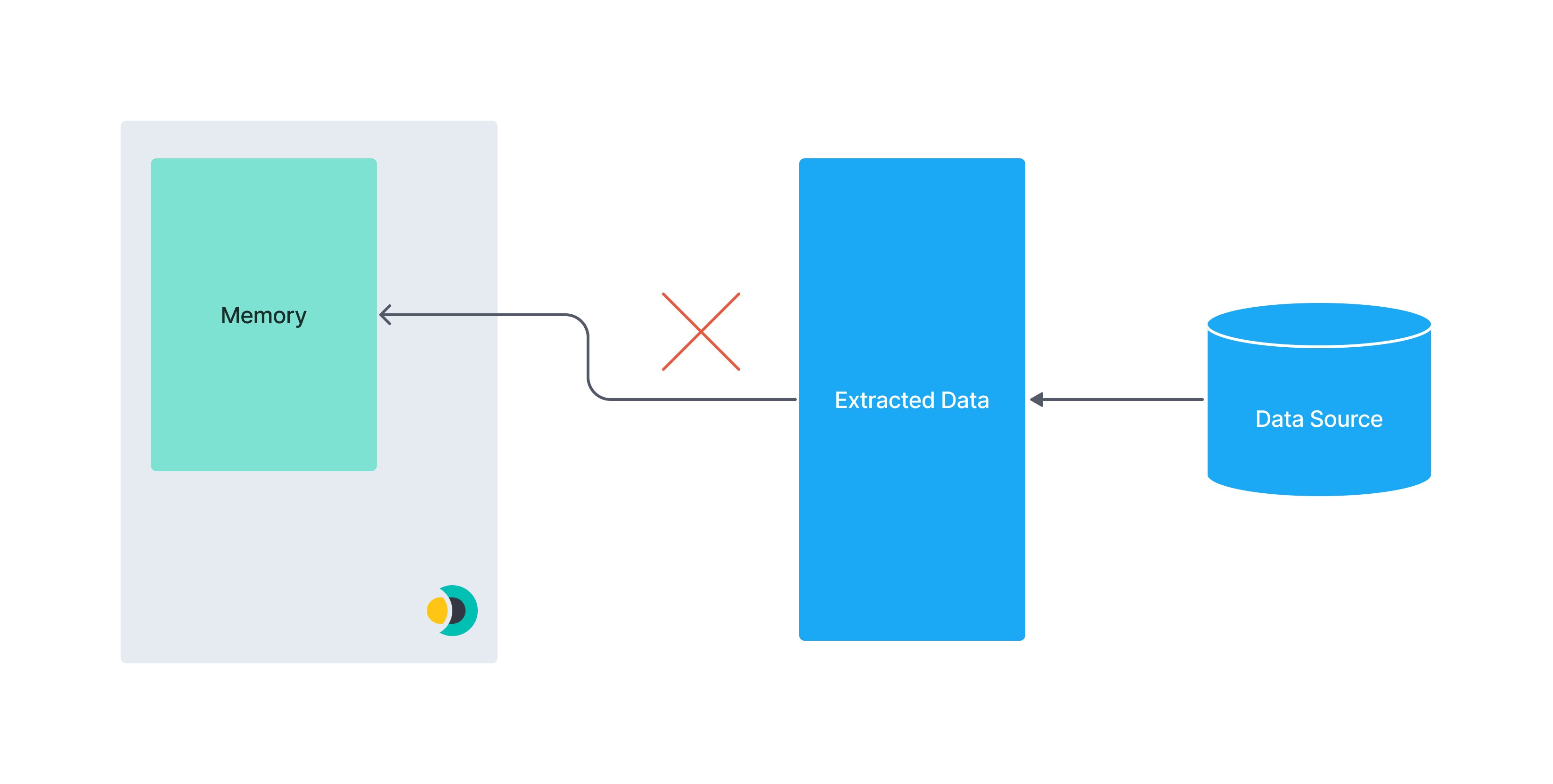
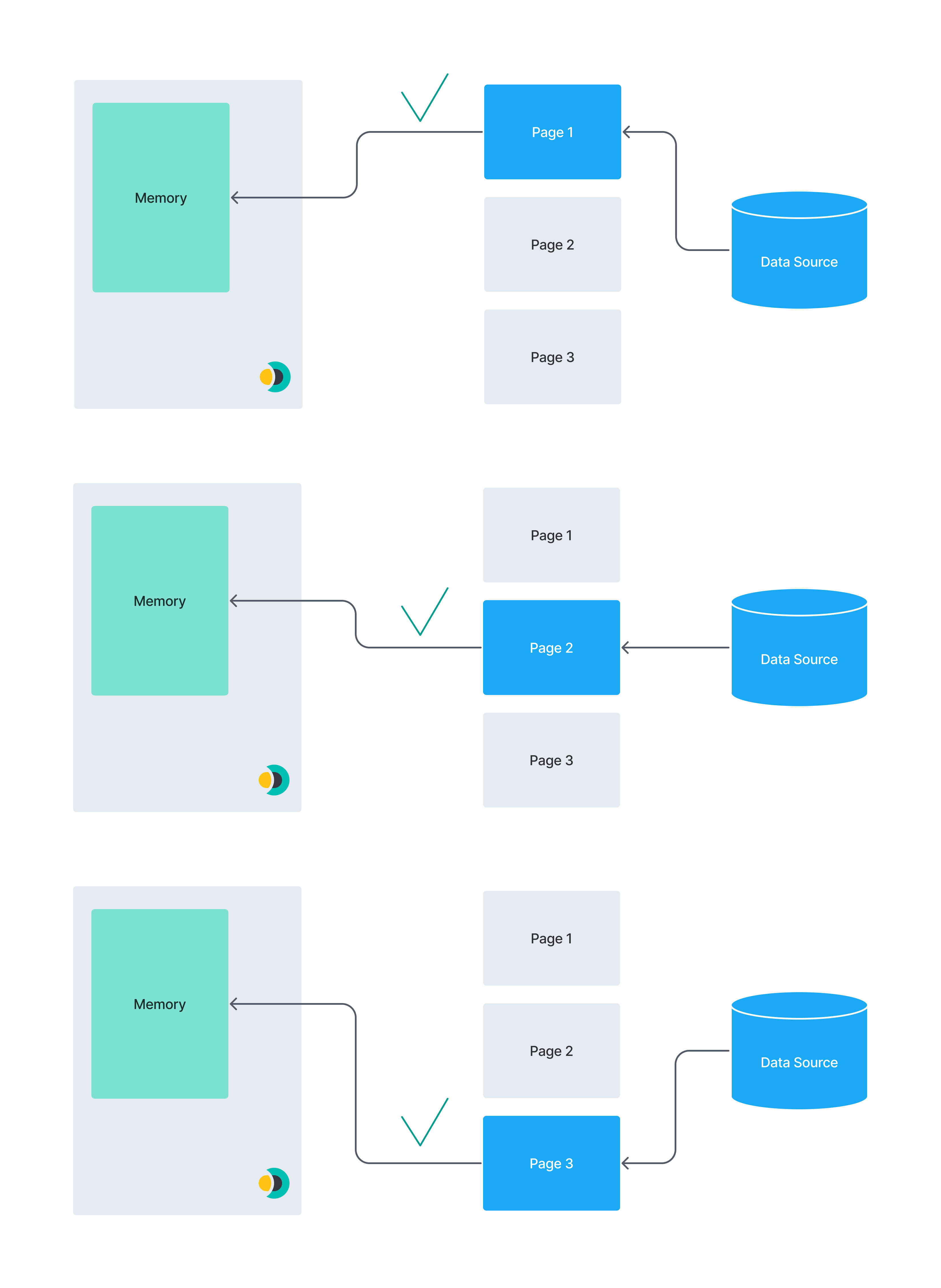
下图说明了分页的概念。一个巨大的数据集可能无法放入连接器实例的内存中。将数据分成较小的块可以降低内存不足错误的风险。
此图说明了一次提取整个数据集
相比之下,此图说明了分页数据集
高级同步规则
编辑高级同步规则会覆盖任何可以从基本同步规则推断出的远程过滤查询。如果定义了高级同步规则,则任何定义的基本同步规则将专门用于集成过滤。
高级同步规则仅用于远程过滤。您可以将高级同步规则视为一种与语言无关的方式来表示对数据源的查询。因此,这些规则是高度特定于源的。
以下连接器支持高级同步规则:
每个支持高级同步规则的连接器都提供了自己的 DSL 来指定规则。有关详细信息,请参阅每个连接器的文档。
组合基本同步规则和高级同步规则
编辑您还可以一起使用基本同步规则和高级同步规则来过滤数据集。
下图概述了高级同步规则、基本同步规则和管道过滤应用于您的文档的顺序
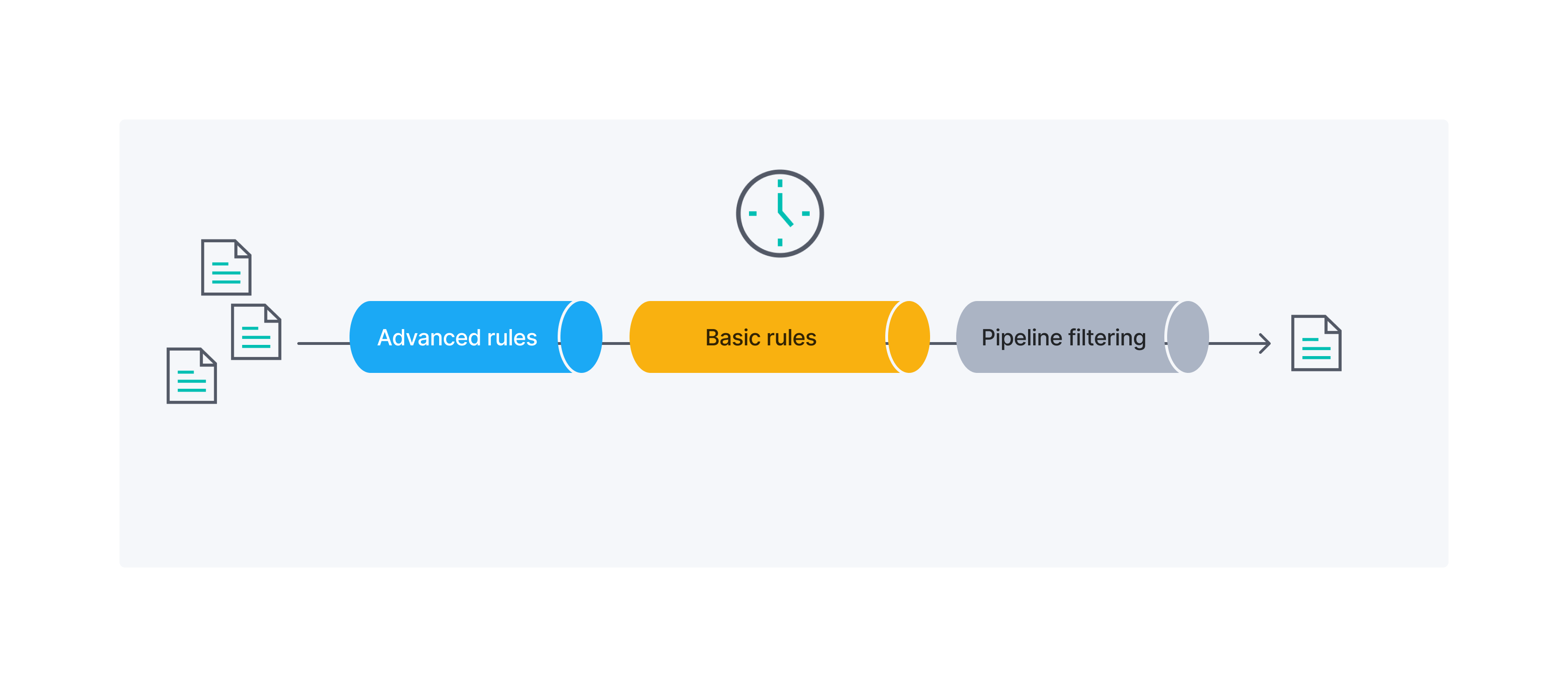
示例
编辑在以下示例中,我们要过滤包含公寓的数据集,使其仅包含具有特定属性的公寓。我们将在整个示例中使用基本同步规则和高级同步规则。
一个示例公寓在 .json 格式中如下所示
{
"id": 1234,
"bedrooms": 3,
"price": 1500,
"address": {
"street": "Street 123",
"government_area": "Area",
"country_information": {
"country_code": "PT",
"country": "Portugal"
}
}
}
目标数据集应满足以下条件
- 每间公寓应至少有3 间卧室
- 公寓的月租金不应超过1500
- ID 为 1234 的公寓应在不考虑前两个条件的情况下被包含在内
- 每间公寓应位于葡萄牙或西班牙
前 3 个条件可以通过基本同步规则处理,但我们需要使用高级同步规则来处理第 4 个条件。
基本同步规则示例
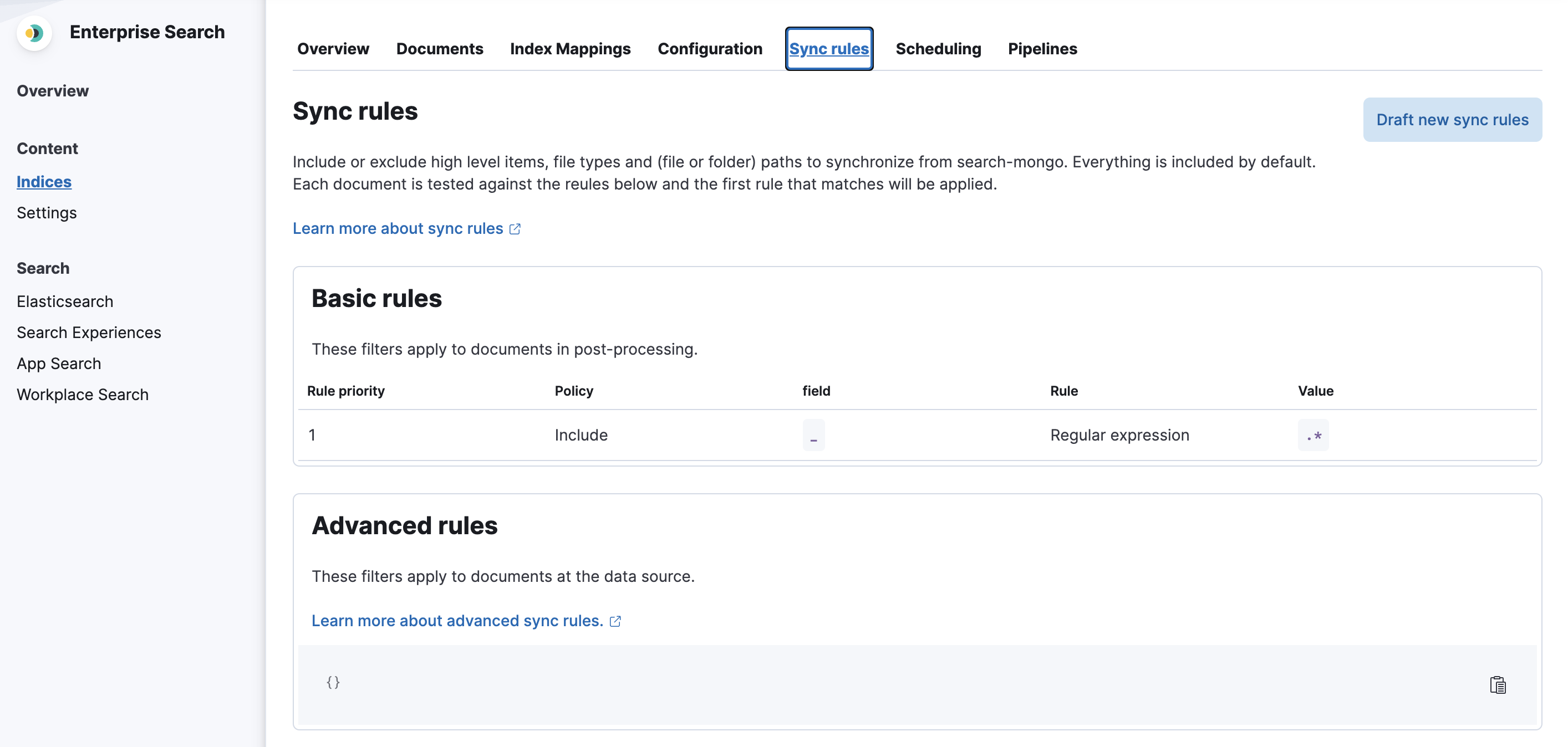
编辑要创建新的基本同步规则,请导航到同步规则选项卡并选择起草新的同步规则
之后,您需要按保存并验证草稿按钮来验证这些规则。请注意,保存后,这些规则将处于草稿状态。除非应用它们,否则它们不会在下一次同步中执行。
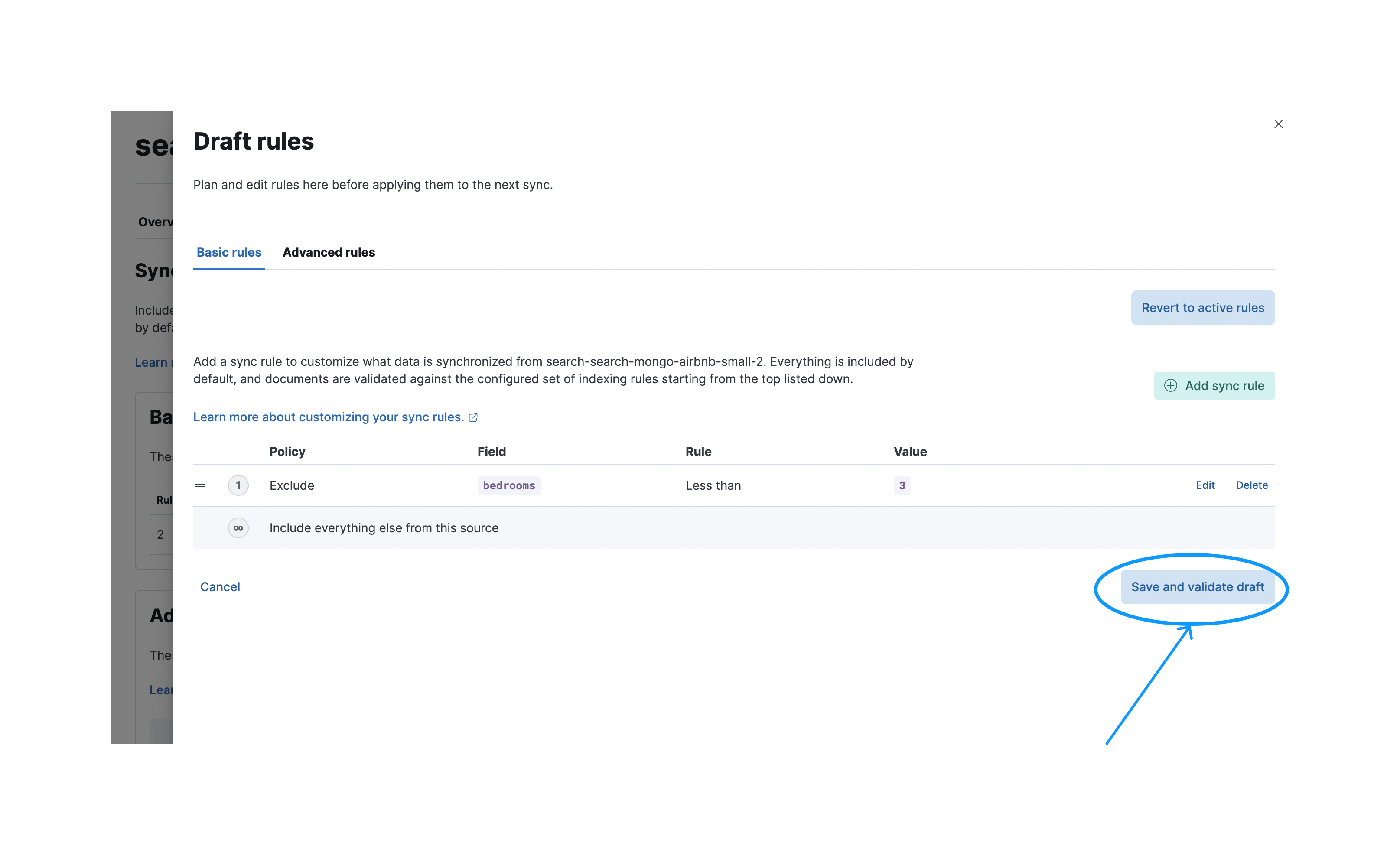
成功验证后,您可以应用规则,以便它们在下一次同步中执行。
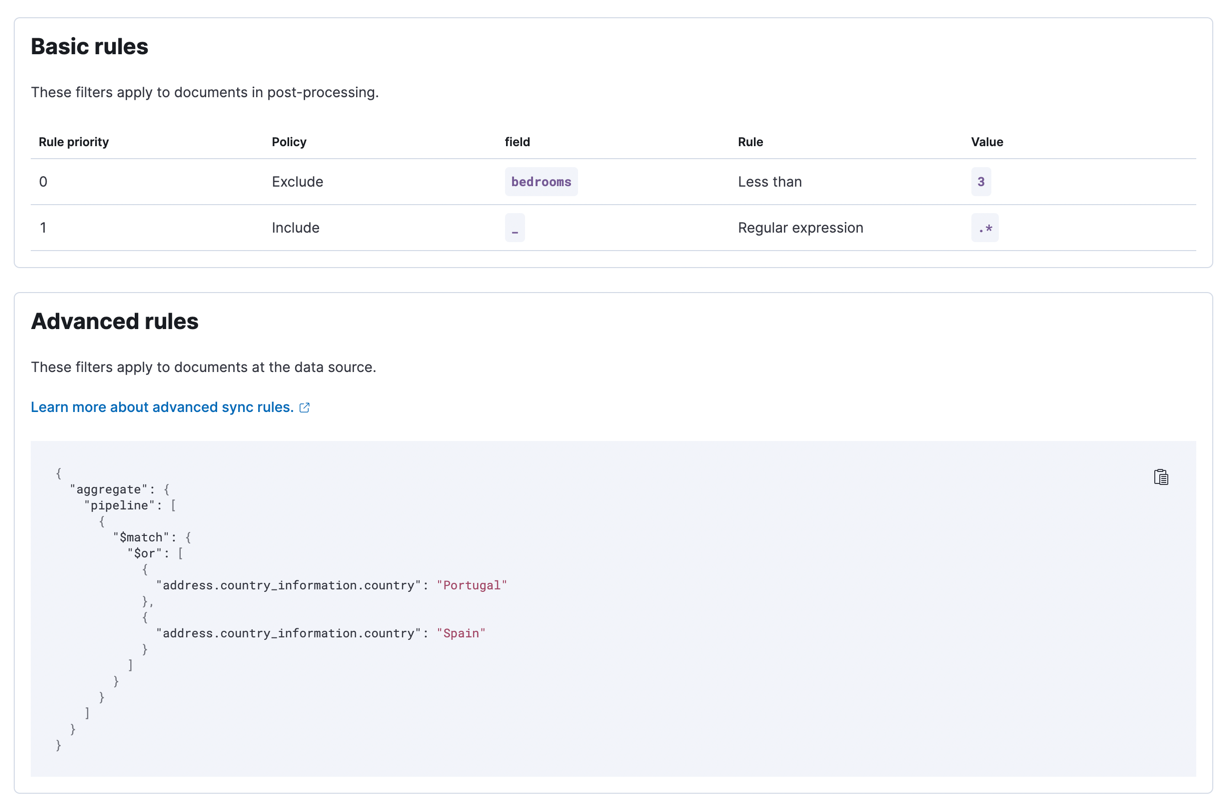
以下条件可以通过基本同步规则覆盖:
- ID 为 1234 的公寓应在不考虑前两个条件的情况下被包含在内
- 每间公寓应至少有三间卧室
- 公寓的月租不应超过 1000 元。
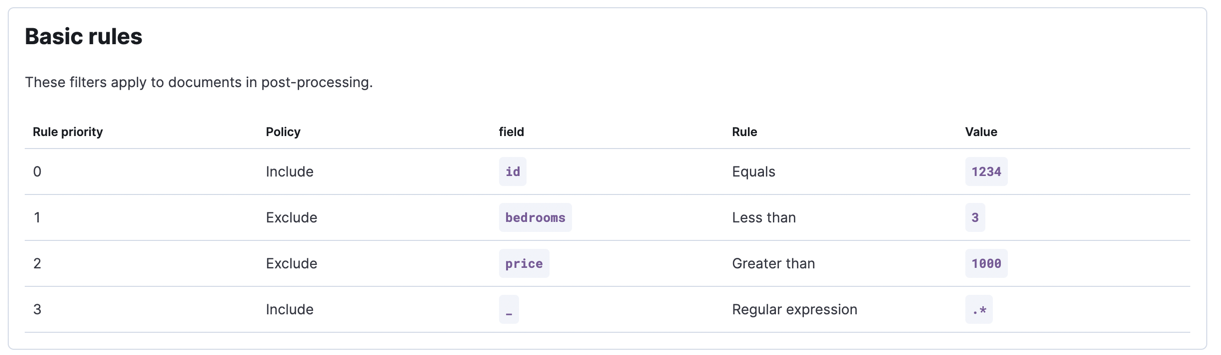
请记住,对于基本同步规则,顺序很重要。不同的顺序可能会导致不同的结果。
高级同步规则示例
编辑您只想包含位于葡萄牙或西班牙的公寓。这里我们需要使用高级同步规则,因为我们正在处理深度嵌套的对象。
假设公寓数据存储在 MongoDB 实例中。对于 MongoDB,我们支持高级同步规则中的聚合管道等功能。一个只选择位于葡萄牙或西班牙的房产的聚合管道如下所示
[
{
"$match": {
"$or": [
{
"address.country_information.country": "Portugal"
},
{
"address.country_information.country": "Spain"
}
]
}
}
]
要创建这些高级同步规则,请导航到同步规则创建对话框并选择高级规则选项卡。现在,您可以将聚合管道粘贴到 aggregate.pipeline 下的输入字段中。
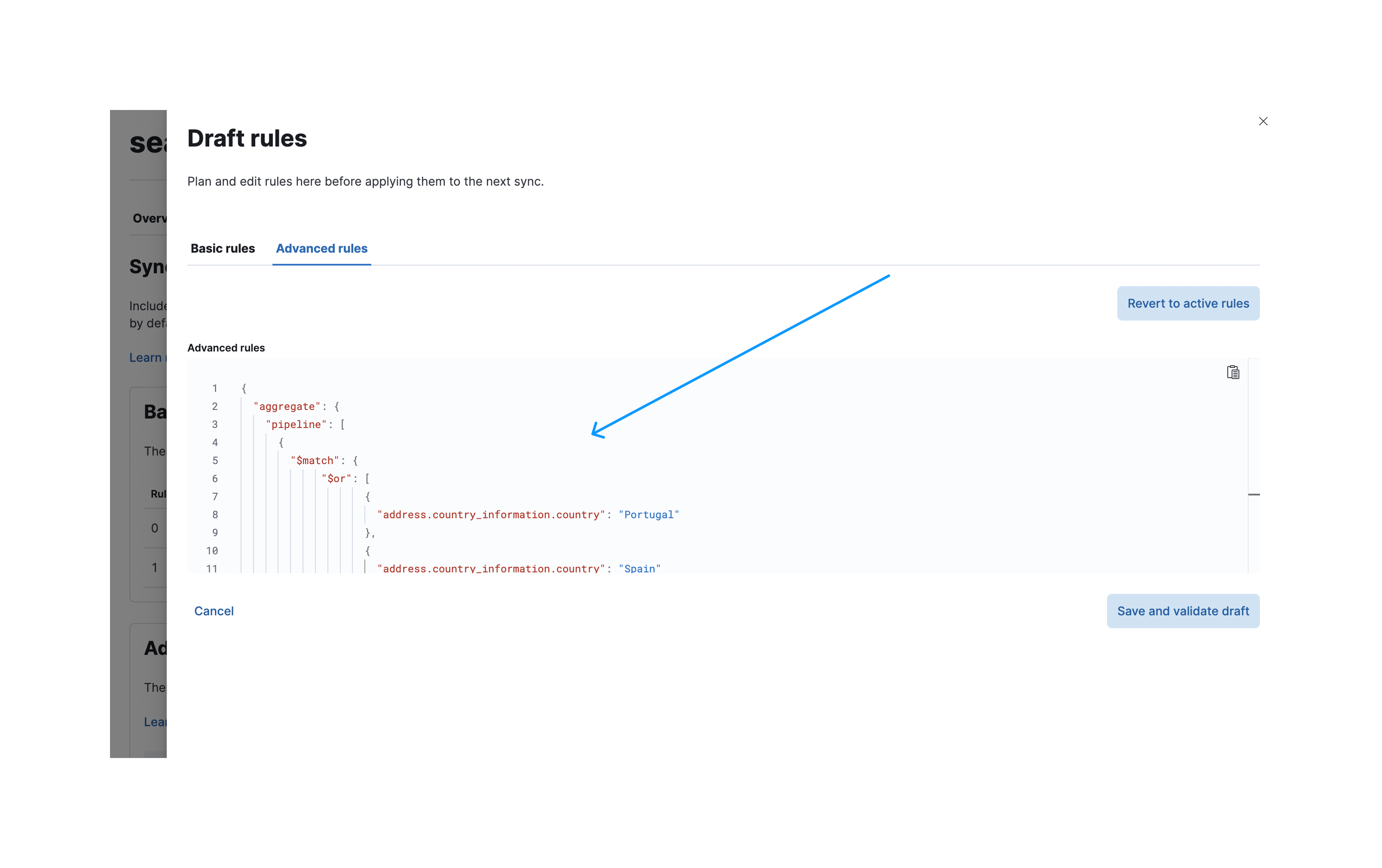
验证后,应用这些规则。以下屏幕截图显示了已应用的同步规则,这些规则将在下次同步时执行
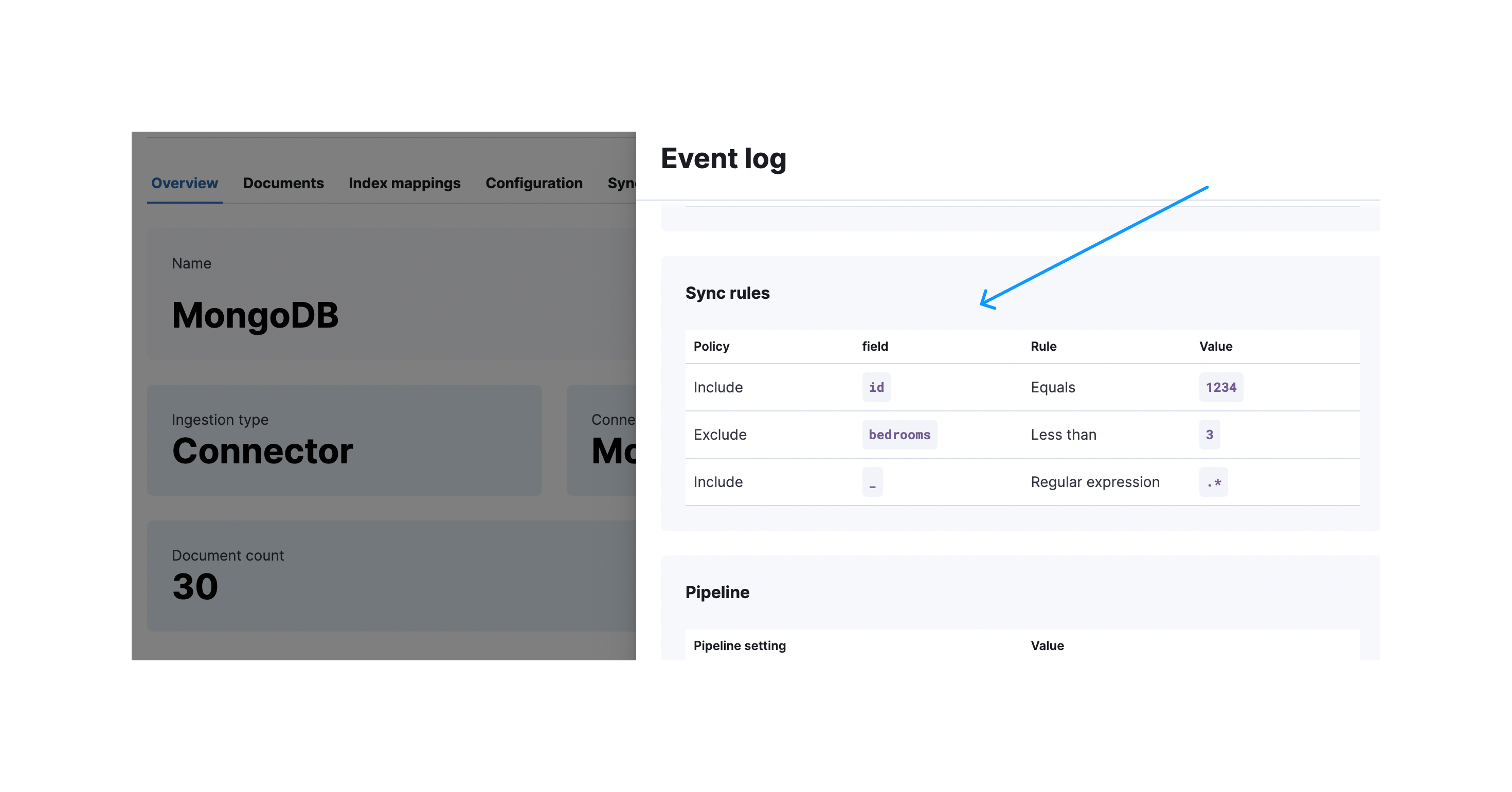
成功同步后,您可以展开同步详细信息以查看应用了哪些规则
当在 UI 外部进行更改时,活动的同步规则可能会失效。具有无效规则的同步作业将失败。一种解决方法是重新验证草稿规则并覆盖无效的活动规则。