调整和分析 Logstash 管道性能
编辑调整和分析 Logstash 管道性能
编辑Logstash 的监控 API 中的 流指标 可以提供有关事件如何在管道中流动的宝贵见解。它们可以揭示您的管道是否资源受限,管道中的哪些部分消耗了最多的资源,并在调整时提供有用的反馈。
工作程序利用率
编辑当管道的 worker_utilization 流指标始终接近 100 时,其所有工作程序都处于处理管道过滤器和输出的状态。我们可以通过查看插件级别的 worker_utilization 和 worker_millis_per_event 流指标来了解管道中哪些插件正在消耗可用的工作程序容量。使用此信息,我们可以获得关于如何调整管道设置以添加资源、如何查找和消除浪费的计算,或意识到需要扩展下游目标容量的直觉。
一般来说,插件可以分为两类
-
CPU 密集型:在不使用网络或磁盘 IO 的情况下对事件内容执行计算的插件倾向于随着可用 CPU 的增加而逐步增加
pipeline.workers;一旦 CPU 用尽,额外的并发性可能会导致更低的吞吐量,因为管道工作程序争夺资源并且在上下文切换中花费的时间增加。 -
IO 密集型:使用网络来丰富事件或传输事件的插件倾向于随着
pipeline.workers的逐步增加和/或调整下面描述的pipeline.batch.*参数而受益。这允许它们更好地利用网络资源,只要这些外部服务没有施加反压(即使 Logstash 正在使用几乎所有可用的 CPU)。
管道的 worker_utilization 离 100 越远,其工作程序在等待事件到达队列中花费的时间就越多。由于大多数管道中的数据量通常是不一致的,因此目标应该是调整管道,使其拥有在高峰期避免将反压传播到其输入的资源。
队列反压
编辑当管道接收事件的速度快于处理事件的速度时,输入最终会遇到反压,从而阻止它们接收额外的事件。根据所使用的输入插件,反压要么向上游传播,要么导致数据丢失。
管道的 queue_backpressure 流指标反映了输入在尝试将事件推入队列中花费了多少时间。该指标在不同管道之间并不完全可比,而是允许您将单个管道的当前行为与自身随时间的变化进行比较。当此指标增长时,向下游查看管道的过滤器和输出,以查看它们是否有效地使用资源、是否分配了足够的资源或是否正在经历自身的反压。
持久队列提供持久性保证,并且可以比默认的内存队列吸收更长时间的反压,但是一旦它满了,它也会传播反压。 queue_persisted_growth_events 流指标是衡量持久队列正在积极吸收多少反压的有用指标,并且应该随着管道生命周期的推移趋向于零(或更少)。负数表示队列正在缩小,并且工作程序正在赶上先前产生的滞后。
与调优相关的设置
编辑Logstash 的默认值旨在为大多数用户提供快速、安全的性能。但是,如果您注意到性能问题,您可能需要修改一些默认值。Logstash 提供以下可配置选项来调整管道性能:pipeline.workers、pipeline.batch.size 和 pipeline.batch.delay。
有关设置这些选项的更多信息,请参阅 logstash.yml。
请确保您已阅读 性能故障排除,然后再修改这些选项。
pipeline.workers设置确定为过滤器和输出处理运行多少个线程。如果您发现事件正在积压,或者 CPU 没有饱和,请考虑增加此参数的值以更好地利用可用的处理能力。即使将此数字增加到可用处理器的数量以上,也可能会获得良好的结果,因为当写入外部系统时,这些线程可能会花费大量时间处于 I/O 等待状态。pipeline.batch.size设置定义单个工作程序线程从队列中收集的最大事件数,然后再尝试执行过滤器和输出。较大的批处理大小通常更有效,但会增加内存开销。输出插件可以将每个批处理作为逻辑单元进行处理。例如,Elasticsearch 输出尝试为接收到的每个批处理发送单个 批量请求。调整pipeline.batch.size设置会调整发送到 Elasticsearch 的批量请求的大小。pipeline.batch.delay设置很少需要调整。此设置调整 Logstash 管道的延迟。管道批处理延迟是管道工作程序在当前批处理尚未满时等待每个新事件的最大时间(毫秒)。在此时间过去且没有更多事件可用后,工作程序开始执行过滤器和输出。工作程序在接收事件和在过滤器中处理该事件之间等待的最大时间是pipeline.batch.delay和pipeline.batch.size设置的乘积。
关于管道配置和性能的说明
编辑如果您计划修改默认管道设置,请考虑以下建议
pipeline.workers和pipeline.batch.size设置的乘积决定了未完成事件的总数。此乘积称为未完成计数。在调整pipeline.workers和pipeline.batch.size设置时,请记住未完成计数的值。间歇地以不规则间隔接收大型事件的管道需要足够的内存来处理这些峰值。在jvm.options配置文件中相应地设置 JVM 堆空间(有关更多信息,请参阅 Logstash 配置文件)。- 衡量每次更改以确保它提高而不是降低性能。
- 确保您留有足够的内存来应对事件大小的突然增加。例如,生成表示为大型文本块的异常的应用程序。
- 工作程序的数量可以设置为高于 CPU 内核的数量,因为输出通常会在 I/O 等待条件下处于空闲状态。
- Java 中的线程具有名称,您可以使用
jstack、top和 VisualVM 图形工具来找出给定线程使用哪些资源。 - 在 Linux 平台上,Logstash 使用描述性名称标记其线程。例如,输入显示为
[base]<inputname,管道工作程序显示为[base]>workerN,其中 N 是一个整数。在可能的情况下,其他线程也会被标记以帮助您识别其用途。
分析堆
编辑在调整 Logstash 时,您可能需要调整堆大小。您可以使用 VisualVM 工具来分析堆。特别是 监视器 窗格对于检查堆分配是否足以满足当前工作负载非常有用。下面的屏幕截图显示了示例 监视器 窗格。第一个窗格检查配置了太多未完成事件的 Logstash 实例。第二个窗格检查配置了适当数量的未完成事件的 Logstash 实例。请注意,此处使用的特定批处理大小很可能不适用于您的特定工作负载,因为 Logstash 的内存需求在很大程度上取决于您发送的消息类型。
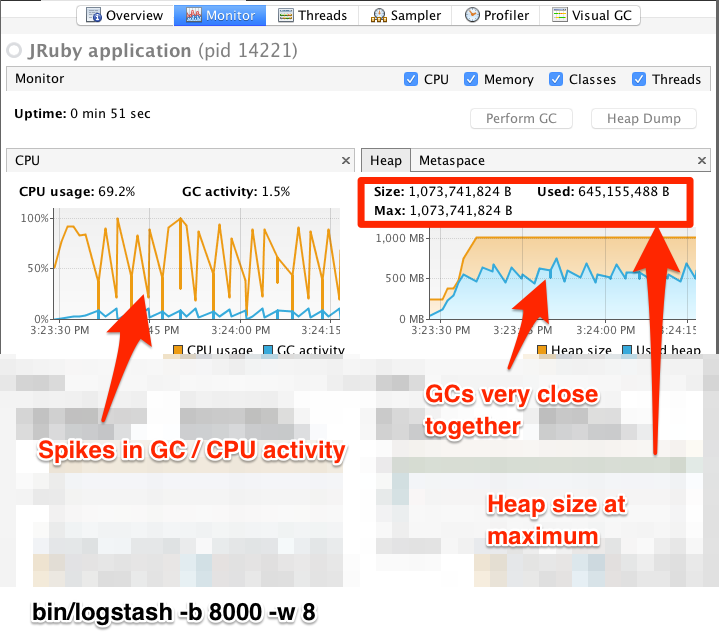
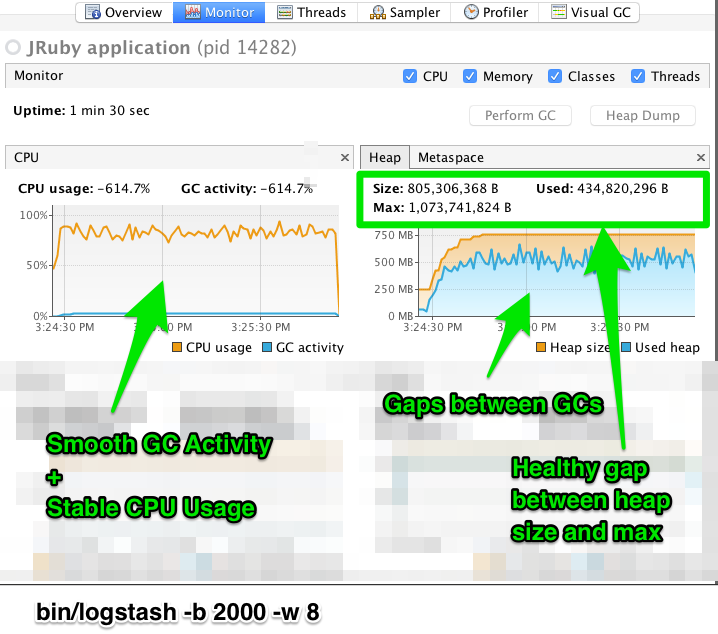
在第一个示例中,我们看到 CPU 没有被非常有效地使用。事实上,JVM 通常不得不停止 VM 以进行“完全 GC”。完全垃圾回收是内存压力过大的常见症状。这在 CPU 图表上的尖峰模式中可见。在配置更有效的示例中,GC 图表模式更平滑,并且 CPU 以更统一的方式使用。您还可以看到分配的堆大小和最大允许大小之间有充足的空间,从而为 JVM GC 提供了很大的操作空间。
使用类似于出色的 VisualGC 插件的工具检查深入的 GC 统计信息表明,过度分配的 VM 在有效的 Eden GC 中花费的时间很少,相比之下,在资源密集型旧代“完全”GC 中花费的时间更多。
只要 GC 模式可以接受,偶尔增加到最大值的堆大小是可以接受的。这种堆大小峰值是响应大量事件通过管道传递而产生的。在一般实践中,在使用的堆内存量和最大值之间保持间隙。本文档不是 JVM GC 调优的全面指南。阅读官方的 Oracle 指南,以获取有关该主题的更多信息。我们还建议阅读 调试 Java 性能。