如何部署命名实体识别
编辑如何部署命名实体识别
编辑您可以使用这些说明在 Elasticsearch 中部署命名实体识别 (NER) 模型,测试模型,并将其添加到推理摄取管道。本例中使用的模型可在HuggingFace 上公开获取。
要求
编辑要按照本页面的过程操作,您必须拥有:
部署 NER 模型
编辑您可以使用Eland 客户端安装自然语言处理模型。使用预构建的 Docker 镜像运行 Eland install model 命令。使用以下命令拉取最新镜像:
docker pull docker.elastic.co/eland/eland
拉取完成后,您的 Eland Docker 客户端即可使用。
从第三方模型参考列表中选择 NER 模型。本例使用未区分大小写的 NER 模型。
通过在 Docker 镜像中运行eland_import_model_hub 命令来安装模型:
docker run -it --rm docker.elastic.co/eland/eland \
eland_import_hub_model \
--cloud-id $CLOUD_ID \
-u <username> -p <password> \
--hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \
--task-type ner \
--start
您需要提供管理员用户名及其密码,并将$CLOUD_ID替换为您的 Cloud 部署的 ID。此 Cloud ID 可从 Cloud 网站上的部署页面复制。
由于在 Eland 导入命令结束时使用了--start选项,Elasticsearch 会部署可立即使用的模型。如果您有多个模型并想要选择要部署的模型,则可以使用 Kibana 中的机器学习 > 模型管理用户界面来管理模型的启动和停止。
转到机器学习 > 已训练模型页面并同步您的已训练模型。页面顶部会显示一条警告消息,内容为“需要同步 ML 作业和已训练模型”。按照链接到“同步您的作业和已训练模型”的说明操作。然后单击同步。您也可以等待每小时发生的自动同步,或者使用同步机器学习对象 API。
测试 NER 模型
编辑可以在 Kibana 的机器学习 > 已训练模型下评估已部署的模型,方法是为相应的模型选择测试模型操作。
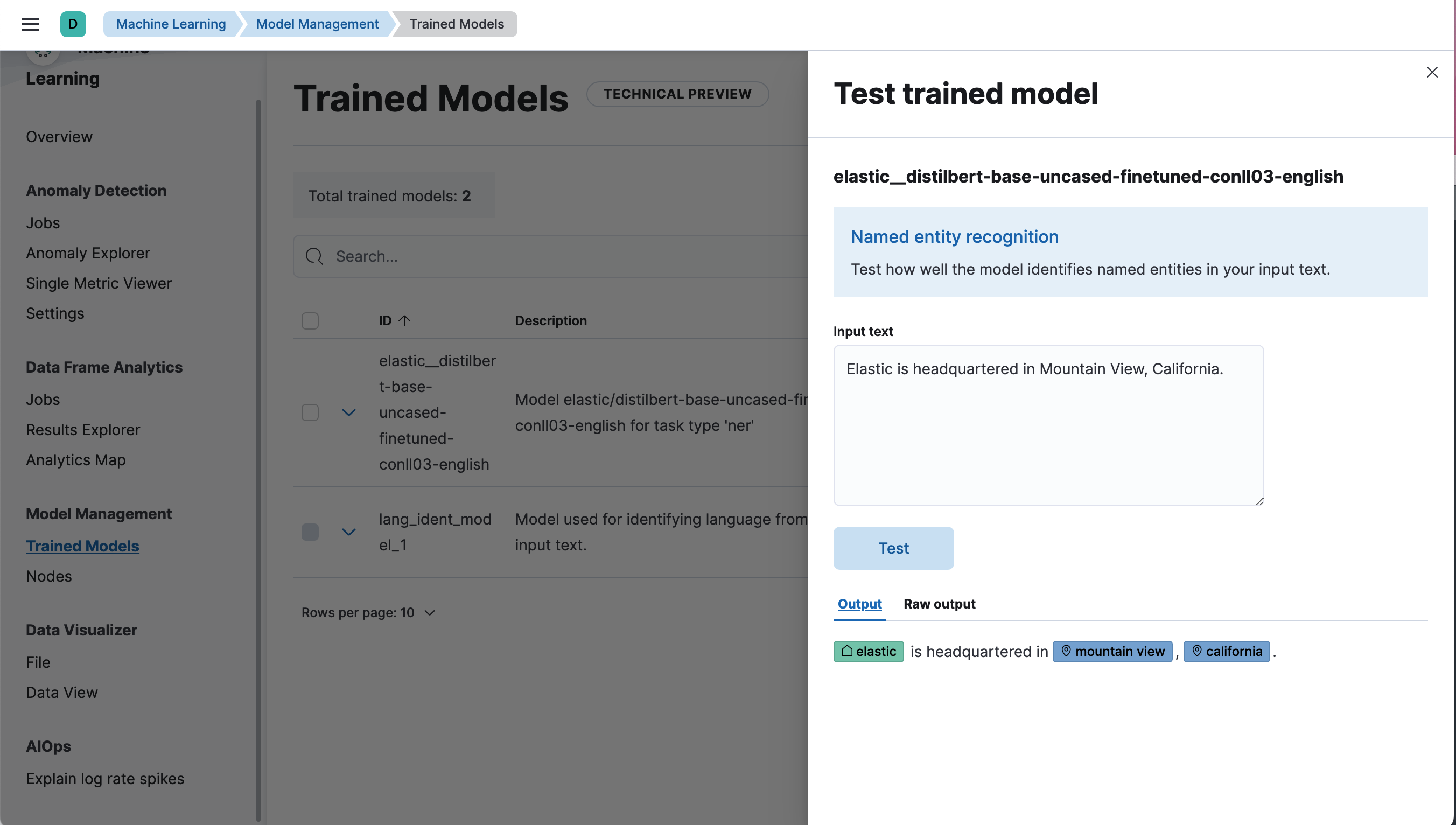
使用 _infer API 测试模型
您还可以使用_infer API评估您的模型。在以下请求中,text_field是模型期望找到输入的字段名称,在模型配置中定义。默认情况下,如果模型是通过 Eland 上传的,则输入字段为text_field。
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/_infer
{
"docs": [
{
"text_field": "Elastic is headquartered in Mountain View, California."
}
]
}
API 返回类似于以下内容的响应:
{
"inference_results": [
{
"predicted_value": "[Elastic](ORG&Elastic) is headquartered in [Mountain View](LOC&Mountain+View), [California](LOC&California).",
"entities": [
{
"entity": "elastic",
"class_name": "ORG",
"class_probability": 0.9958921231805256,
"start_pos": 0,
"end_pos": 7
},
{
"entity": "mountain view",
"class_name": "LOC",
"class_probability": 0.9844731508992688,
"start_pos": 28,
"end_pos": 41
},
{
"entity": "california",
"class_name": "LOC",
"class_probability": 0.9972361009811214,
"start_pos": 43,
"end_pos": 53
}
]
}
]
}
使用示例文本“Elastic 总部位于加利福尼亚州山景城”,模型会找到三个实体:一个组织“Elastic”和两个地点“山景城”和“加利福尼亚州”。
将 NER 模型添加到推理摄取管道
编辑您可以通过在摄取管道中使用推理处理器来对文档进行批量推理。以下示例使用维克多·雨果的小说《悲惨世界》作为推理示例。下载按段落分割的小说文本作为 JSON 文件,然后使用数据可视化工具上传它。上传文件时,将新索引命名为les-miserables。
现在,在堆栈管理 UI中或使用 API 创建摄取管道:
PUT _ingest/pipeline/ner
{
"description": "NER pipeline",
"processors": [
{
"inference": {
"model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english",
"target_field": "ml.ner",
"field_map": {
"paragraph": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"if": "return ctx['ml']['ner'].containsKey('entities')",
"source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
inference处理器的field_map对象将悲惨世界文档中的paragraph字段映射到text_field(模型配置为使用的字段的名称)。target_field是写入推理结果的字段的名称。
script处理器提取实体并按类型对其进行分组。最终结果是检测到输入文本中的人员、地点和组织列表。此 painless 脚本使您可以根据创建的字段构建可视化。
on_failure子句的目的是记录错误。它将_index元字段设置为新值,文档现在存储在那里。它还会设置一个新字段ingest.failure,并将错误消息写入此字段。推理失败可能有许多易于修复的原因。也许模型尚未部署,或者某些源文档中缺少输入字段。通过将失败的文档重定向到另一个索引并设置错误消息,这些失败的推理不会丢失,以后可以查看。修复错误后,从失败的索引重新索引以恢复不成功的请求。
通过您创建的管道摄取小说的文本 - 索引les-miserables -。
POST _reindex
{
"source": {
"index": "les-miserables",
"size": 50
},
"dest": {
"index": "les-miserables-infer",
"pipeline": "ner"
}
}
以源文档中的随机段落为例:
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"line": 12700
}
在文本通过 NER 管道摄取后,查找存储在 Elasticsearch 中的结果文档:
GET /les-miserables-infer/_search
{
"query": {
"term": {
"line": 12700
}
}
}
请求返回标注了一个已识别人员的文档:
(...)
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"@timestamp": "2020-01-01T17:38:25.000+01:00",
"line": 12700,
"ml": {
"ner": {
"predicted_value": "Father [Gillenormand](PER&Gillenormand) did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"entities": [
{
"entity": "gillenormand",
"class_name": "PER",
"class_probability": 0.9452480789333386,
"start_pos": 7,
"end_pos": 19
}
],
"model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english"
}
},
"tags": {
"PER": [
"gillenormand"
]
}
(...)
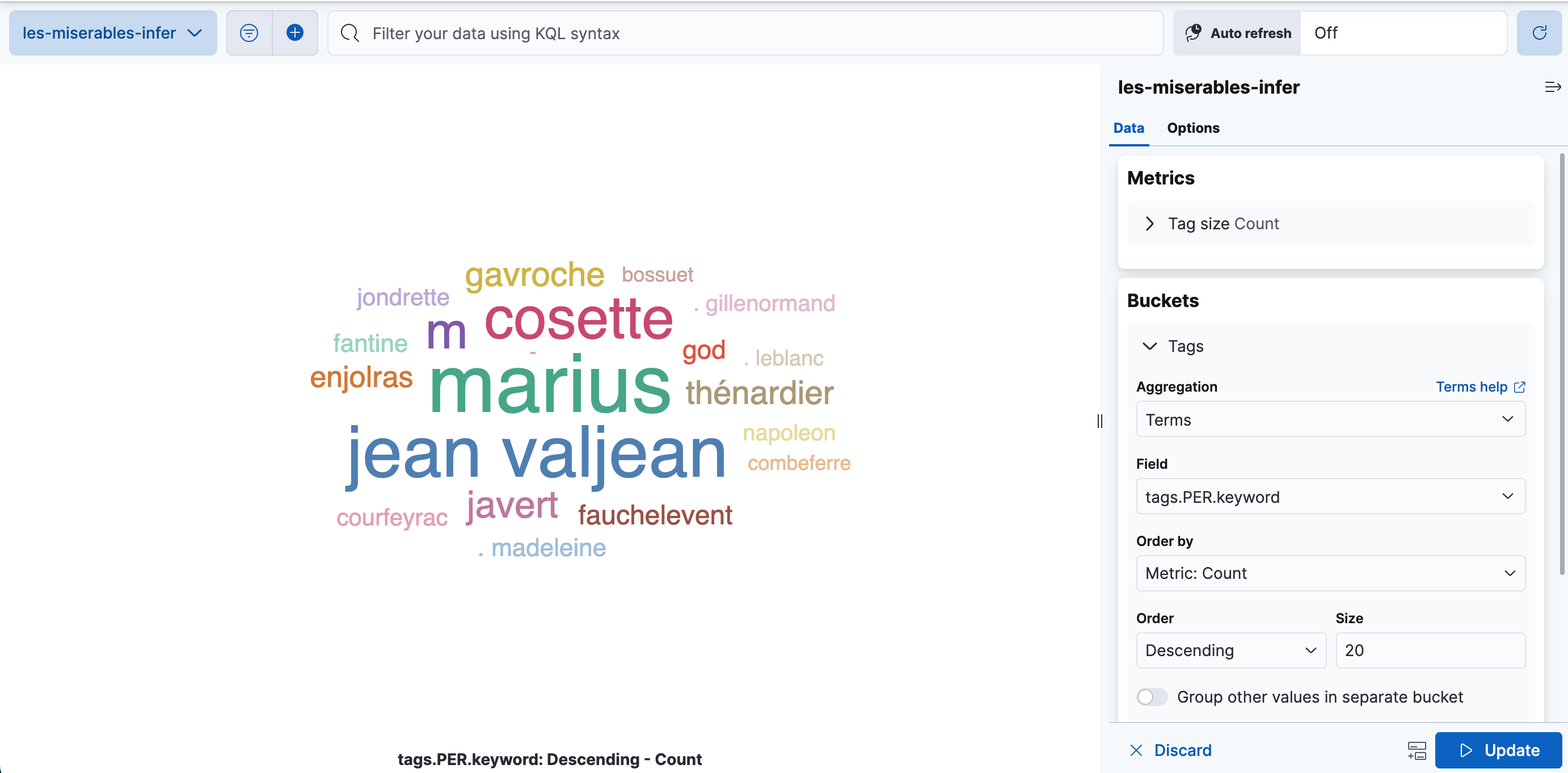
可视化结果
编辑您可以创建词云来可视化推理管道处理的数据。词云是一种可视化工具,它通过出现的频率来缩放单词。它是查看数据中发现的实体的便捷工具。
在 Kibana 中,打开堆栈管理 > 数据视图,并从les-miserables-infer索引模式创建一个新的数据视图。
打开仪表盘并创建一个新的仪表盘。选择基于聚合的类型 > 词云可视化。选择新的数据视图作为源。
添加一个新的桶,使用术语聚合,选择tags.PER.keyword字段,并将大小增加到 20。
如果在创建数据视图时选择了时间字段,则可以选择调整时间选择器以涵盖数据视图中的数据点。
更新并保存可视化。