异常检测入门
编辑异常检测入门
编辑准备好试用异常检测了吗?请按照本教程操作:
- 试用 数据可视化器
- 为 Kibana 样例数据创建异常检测作业
- 使用结果识别数据中可能的异常
在本教程结束时,您应该对机器学习有一个很好的了解,并有望能够将其用于检测您自己数据中的异常。
需要更多上下文?请查看 Elasticsearch 简介,了解相关术语并了解 Elasticsearch 工作原理的基础知识。
试用
编辑-
在使用机器学习功能之前,必须安装 Elasticsearch 和 Kibana。Elasticsearch 存储数据和分析结果。Kibana 提供了一个方便易用的用户界面,用于创建和查看作业。
您可以在自己的硬件上运行 Elasticsearch 和 Kibana,或者使用我们在 Elastic Cloud 上提供的 托管 Elasticsearch 服务。Elasticsearch 服务可在 AWS 和 GCP 上使用。 免费试用 Elasticsearch 服务。
- 验证您的环境是否已正确设置以使用机器学习功能。如果启用了 Elasticsearch 安全功能,则要完成本教程,您需要一个具有管理异常检测作业权限的用户。请参见 设置和安全。
-
- 在 Kibana 首页上,单击 试用样本数据,然后打开 其他样本数据集 部分。
- 选择一个数据集。在本教程中,您将使用 样本 Web 日志。在这里,您可以随意单击所有可用样本数据集上的 添加数据。
这些数据集现在可以准备在 Kibana 的机器学习作业中进行分析。
在 Kibana 中浏览数据
编辑要获得机器学习分析的最佳结果,必须了解您的数据。您必须知道其数据类型以及值的范围和分布。数据可视化器使您可以浏览数据中的字段。
-
在 Web 浏览器中打开 Kibana。如果您在本地运行 Kibana,请转到
https://127.0.0.1:5601/。Kibana 机器学习功能使用弹出窗口。您必须配置 Web 浏览器,使其不会阻止弹出窗口,或者为 Kibana URL 创建例外。
- 单击 Kibana 主菜单中的 机器学习。
- 选择 数据可视化器 选项卡。
- 单击 选择数据视图 并选择
kibana_sample_data_logs数据视图。 - 使用时间过滤器选择您感兴趣的要浏览的时间段。或者,单击 使用完整数据 以查看数据的完整时间范围。
- 可选:您可以更改随机抽样行为,这会影响数据可视化器中使用的每个分片上的文档数量。您可以使用自动随机抽样(平衡准确性和速度)、手动抽样(您可以为抽样百分比选择一个值),或者您可以关闭该功能以使用完整数据集。Kibana 样例数据中的文档数量相对较少,因此您可以关闭随机抽样。对于较大的数据集,请记住,使用较大的样本量会增加查询运行时间并增加集群的负载。
-
浏览数据可视化器中的字段。
您可以按字段名称或 字段类型 过滤列表。数据可视化器指示所选时间段样本中包含每个字段的文档数量。
尤其要注意
clientip、response.keyword和url.keyword字段,因为我们将在异常检测作业中使用它们。对于这些字段,数据可视化器提供不同值的个数、顶级值的列表以及包含该字段的文档的个数和百分比。例如: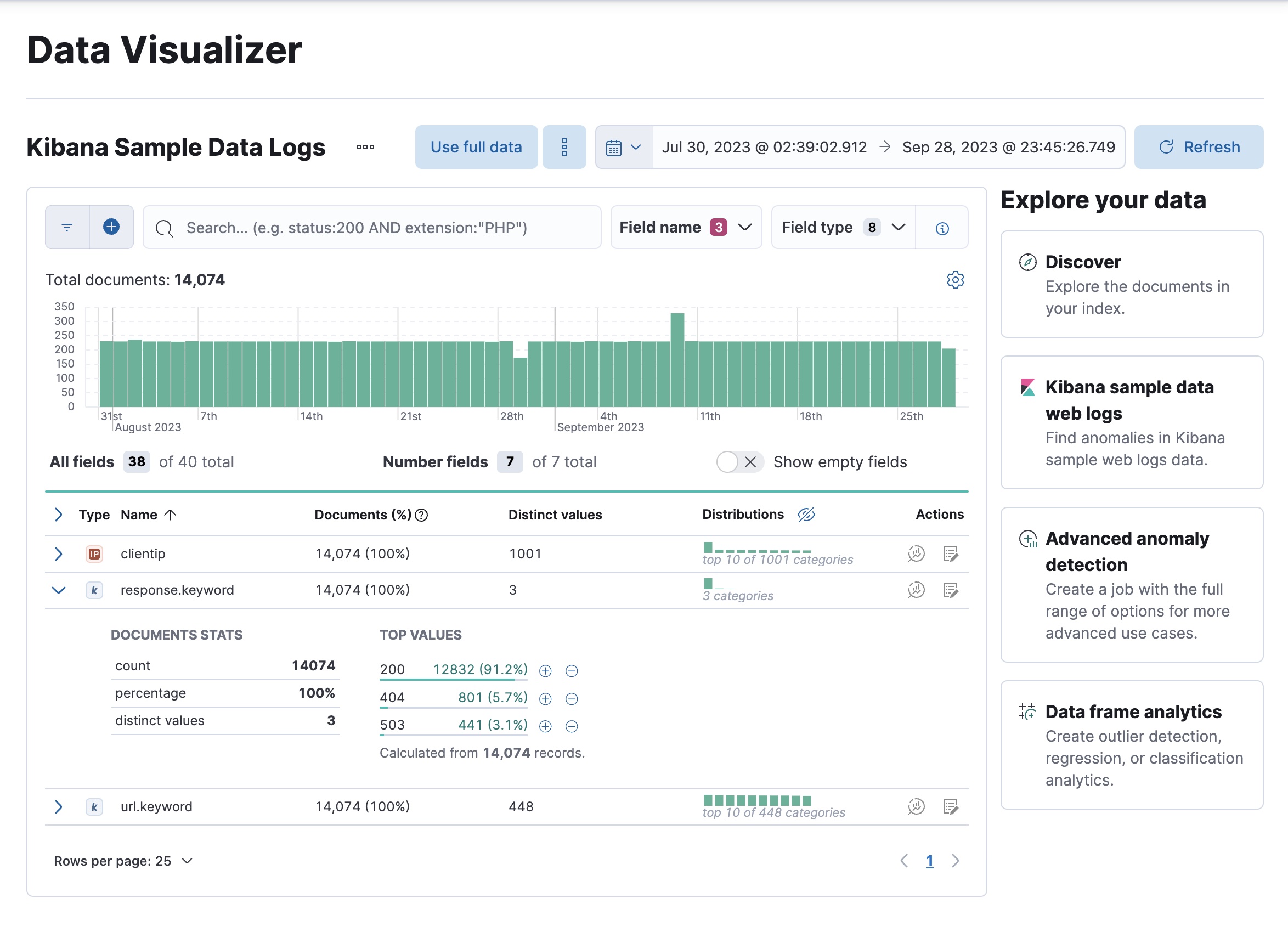
对于数字字段,数据可视化器提供有关最小值、中位数、最大值和顶级值、不同值的个数及其分布的信息。您可以使用分布图更好地了解数据中的值是如何聚类的。例如:
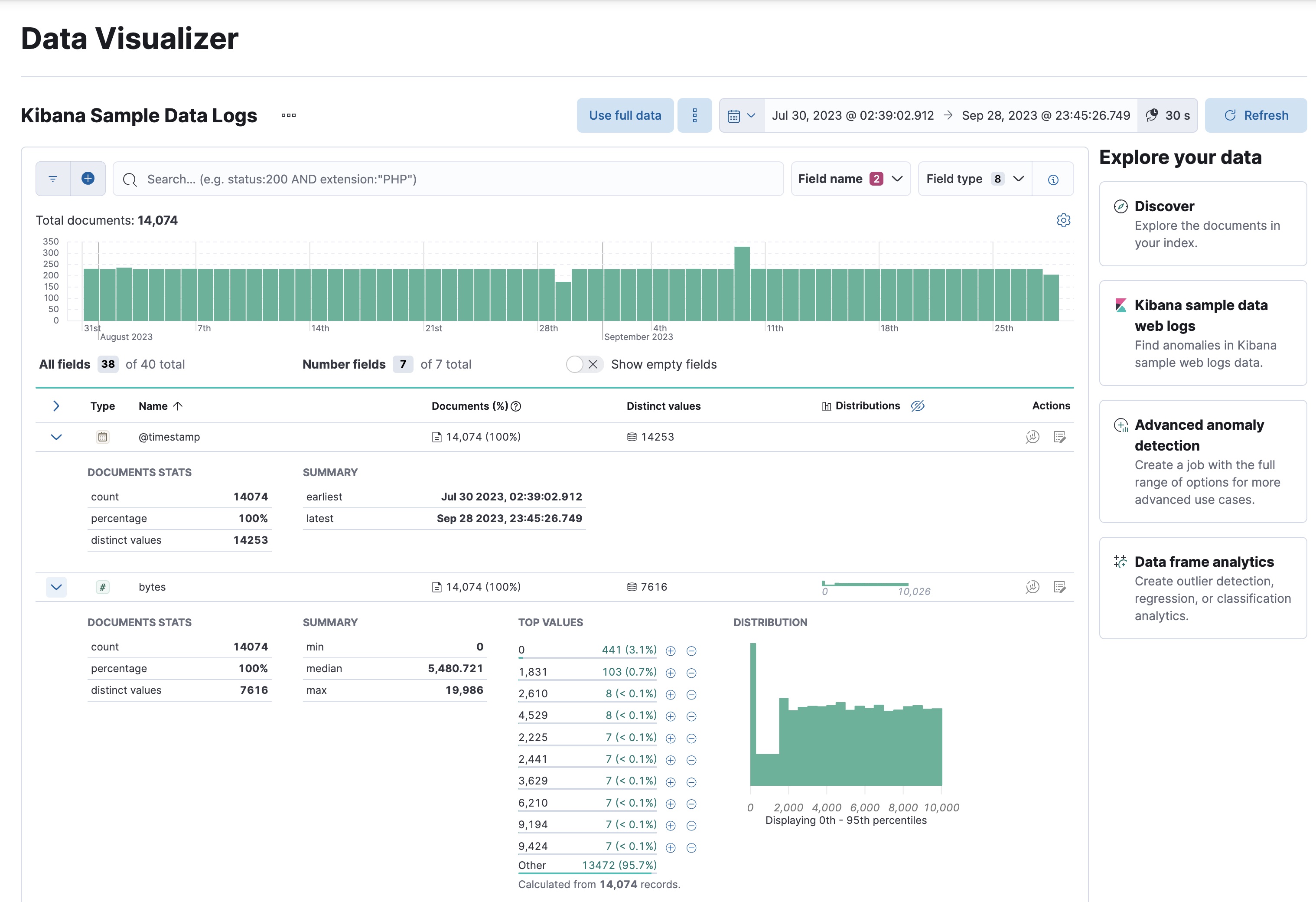
请注意
@timestamp字段中的日期范围。它们与您添加样本数据的时间相关,您稍后在本教程中需要此信息。
现在您已经熟悉了 kibana_sample_data_logs 索引中的数据,您可以创建一些异常检测作业来分析它。
您可以在异常检测向导中查看可选字段的统计信息。弹出窗口中显示的字段统计信息提供了更有意义的上下文,可帮助您选择相关字段。
在 Kibana 中创建样本异常检测作业
编辑此页面上的结果可能与使用样本数据集时获得的实际值不同。这种行为是预期的,因为数据集中的数据点可能会随着时间的推移而发生变化。
Kibana 样例数据集包含一些预先配置的异常检测作业,供您试用。您可以使用以下任一方法添加作业:
- 在 Kibana 首页上加载样本 Web 日志数据集后,单击 查看数据 > ML 作业。
- 在机器学习应用程序中,当您在 数据可视化器 或 异常检测 作业向导中选择
kibana_sample_data_logs数据视图时,它建议您使用其已知配置创建作业。选择 Kibana 样例数据 Web 日志 配置。 - 接受默认值并单击 创建作业。
向导将创建三个作业和三个数据馈送。
如果您想查看作业和数据馈送的所有配置详细信息,可以在 机器学习 > 异常检测 > 作业 页面上进行查看。或者,您可以在 GitHub 上查看配置文件。但是,在本教程中,以下是每个作业目标的简要概述:
-
low_request_rate使用low_count函数查找异常低的请求率 -
response_code_rates使用count函数并按response.keyword值划分分析,以查找按 HTTP 响应代码划分的异常事件率 -
url_scanning使用high_distinct_count函数并对clientip字段执行总体分析,以查找访问异常高不同 URL 计数的客户端 IP
下一步是查看结果并了解这些作业生成的哪些类型的见解!
查看异常检测结果
编辑数据馈送启动且异常检测作业处理了一些数据后,您可以在 Kibana 中查看结果。
根据机器的容量,您可能需要等待几秒钟才能生成初始机器学习分析结果。
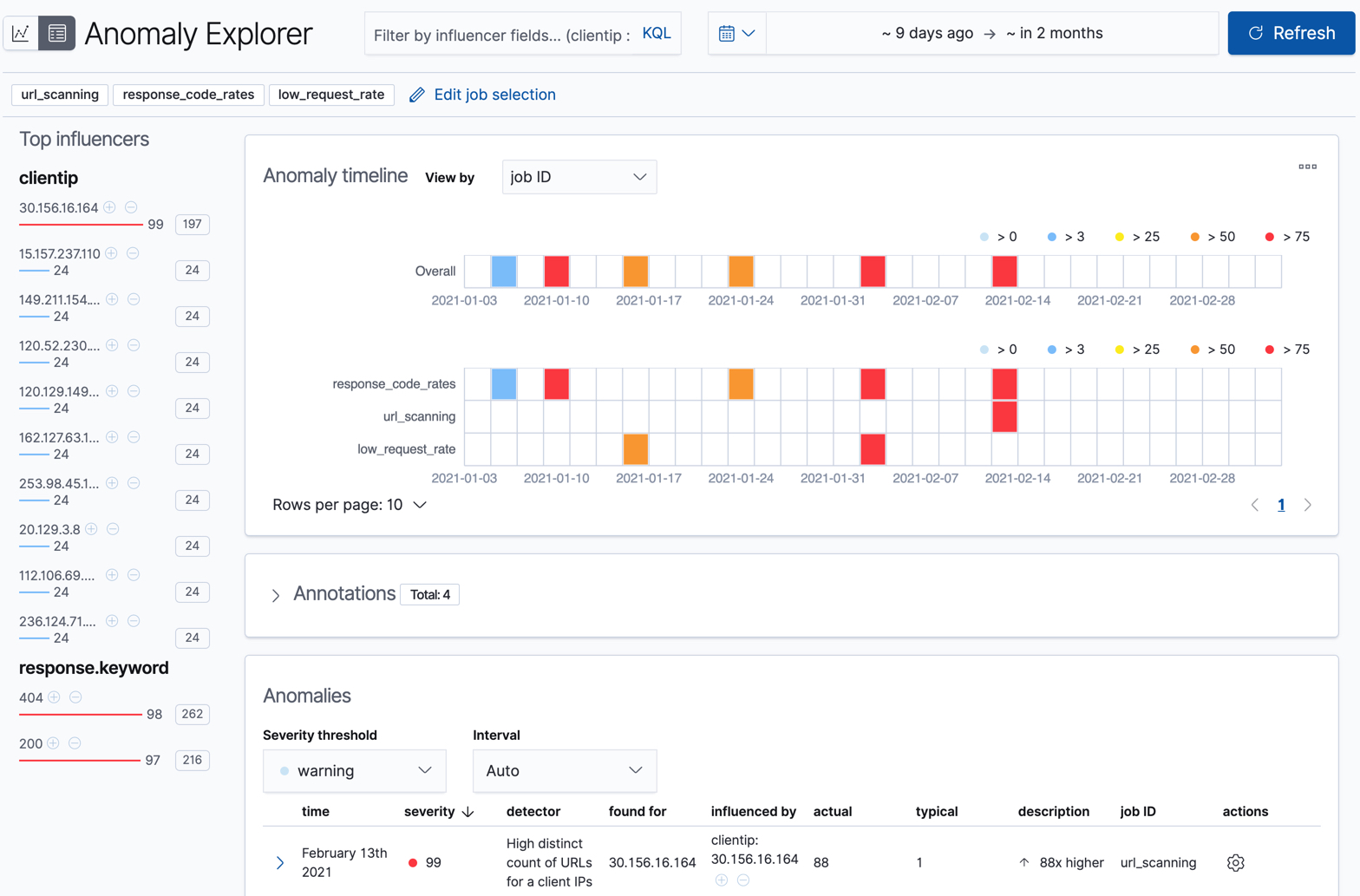
机器学习功能会分析数据输入流,对其行为建模,并根据每个作业中的检测器执行分析。当发生超出模型的事件时,该事件将被识别为异常。您可以立即看到所有三个作业都发现了异常,这些异常由每个作业泳道中的红色块表示。
Kibana 中有两个工具可用于检查异常检测作业的结果:异常资源管理器 和 单指标查看器。您可以通过单击左上角的图标在这些工具之间切换。您还可以编辑作业选择以检查不同的异常检测作业子集。
单指标作业结果
编辑一个样本作业 (low_request_rate) 是一个单指标异常检测作业。它有一个使用 low_count 函数且作业属性有限的单个检测器。如果您想确定网站上的请求率何时大幅下降,则可以使用此类作业。
让我们首先在 单指标查看器 中查看此简单作业。
- 在 机器学习 中选择 异常检测 选项卡,以查看您的异常检测作业列表。
- 单击
low_request_rate作业的 操作 列中的图表图标,以在 单指标查看器 中查看其结果。 - 使用日期选择器的相对模式选择过去一周的开始日期和未来一个月的结束日期,以涵盖大多数已分析的数据点。
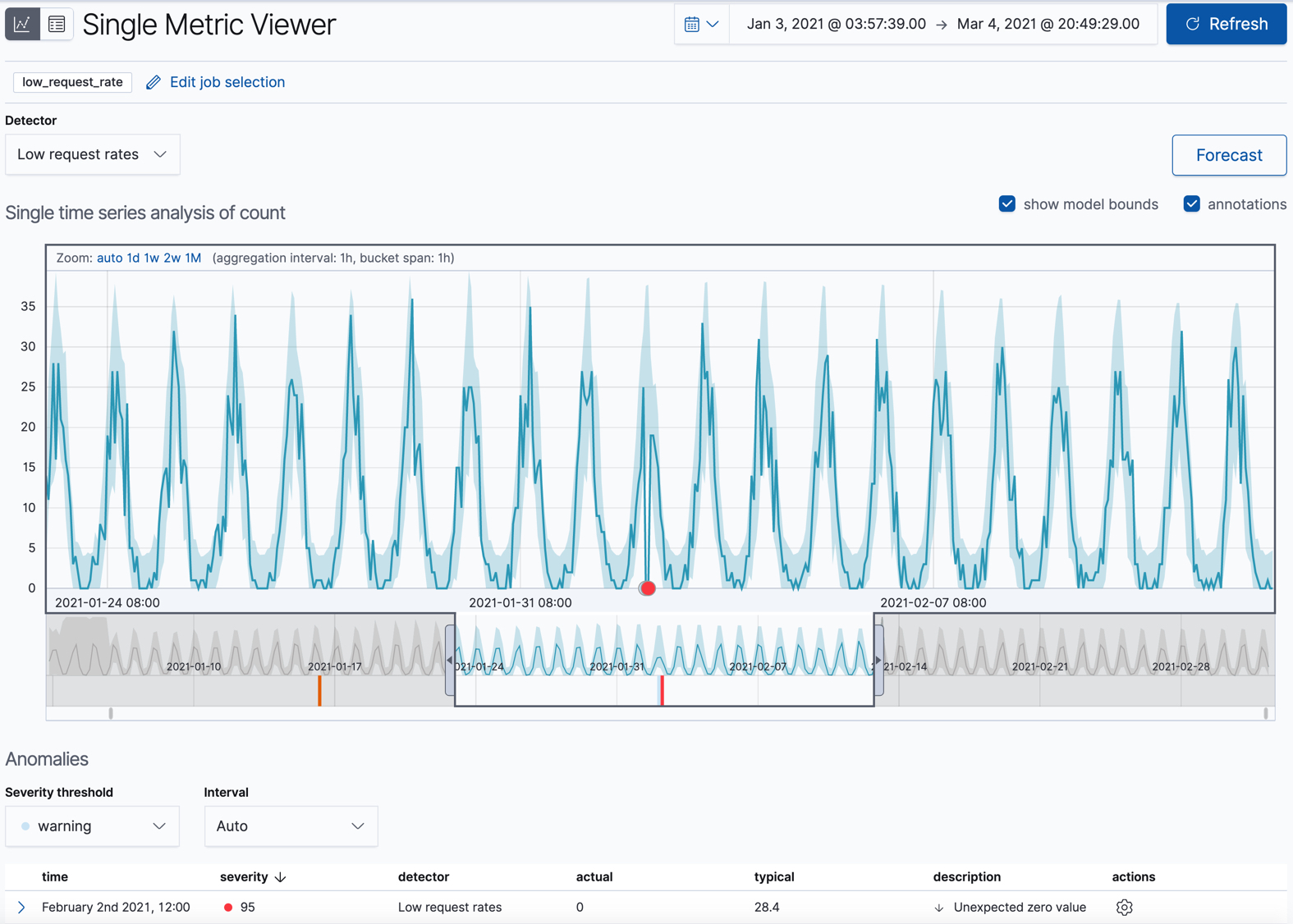
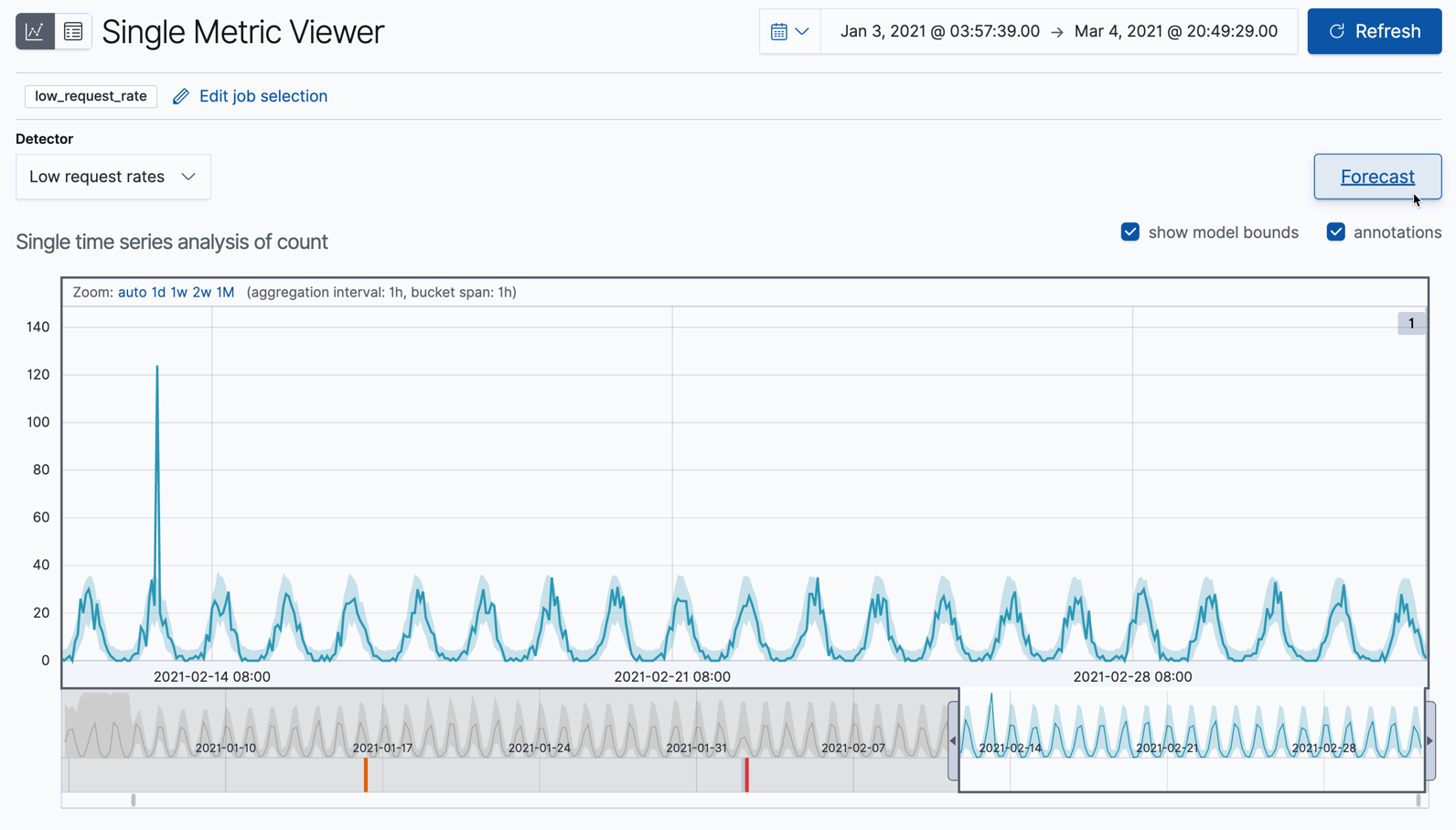
此视图包含一个图表,用于显示一段时间内的实际值和预期值。只有在作业启用了model_plot_config时才可用。它只能显示单个时间序列。
图表中的蓝线代表实际数据值。阴影蓝色区域代表预期值的范围。上界和下界之间的区域是模型最可能的值,使用 95% 的置信水平。也就是说,实际值落在这些界限内的概率为 95%。如果某个值超出此区域,则通常会被识别为异常值。
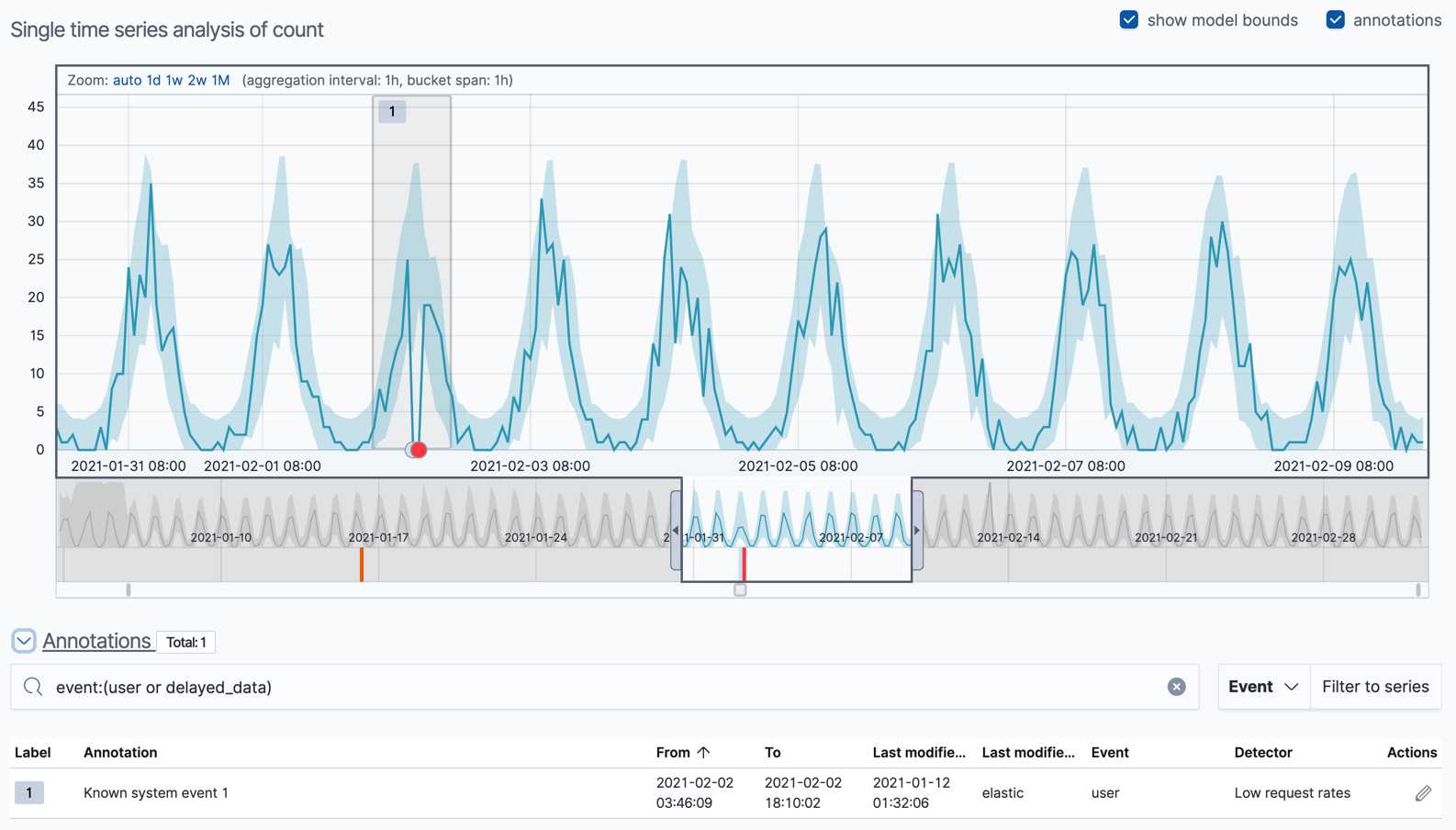
如果将时间选择器从数据的开头滑动到结尾,您可以看到模型在处理更多数据时是如何改进的。一开始,预期值的范围相当宽泛,模型并未捕捉到数据中的周期性。但它很快就学习并开始反映您数据中的模式。
将时间选择器滑动到包含红色异常数据点的时间序列部分。如果将鼠标悬停在该点上,您可以查看更多信息。
您可能会注意到时间序列中出现高峰值。但是,它没有被突出显示为异常值,因为此作业仅查找低计数。
对于每个异常值,您可以在查看器的异常部分查看关键详细信息,例如时间、实际值和预期值(“典型”值)及其概率。例如
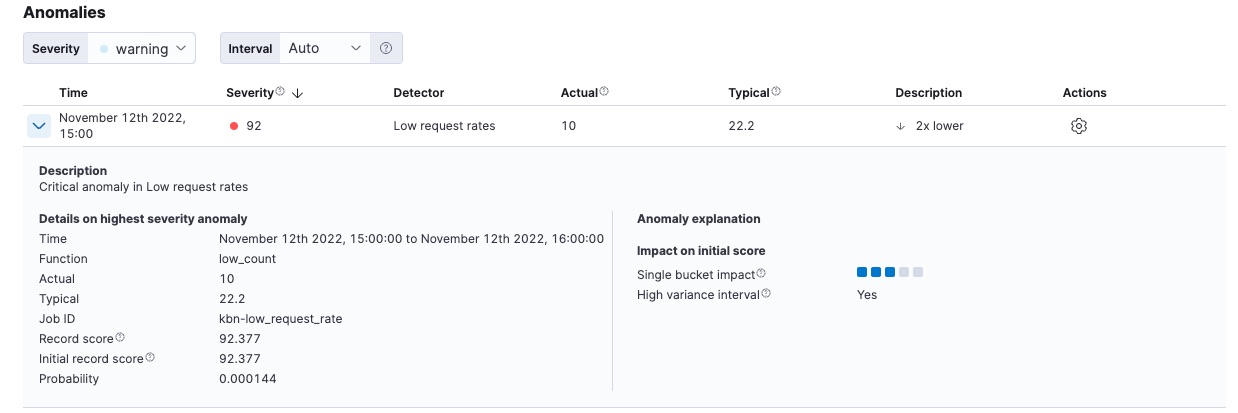
在操作列中,还有其他选项,例如原始数据,它会生成Discover中相关文档的查询。您可以使用自定义 URL在操作菜单中添加更多链接。
默认情况下,该表包含在所选时间线部分中严重性为“警告”或更高的所有异常值。例如,如果您只对严重异常值感兴趣,则可以更改此表的严重性阈值。
异常解释部分为您提供有关每个异常的更多见解,例如其类型和影响,以便更容易解释作业结果。
您可以选择通过在单指标查看器中拖动选择一段时间并添加描述来注释作业结果。注释是引用特定时间段内事件的备注。它们可以由用户创建,也可以由异常检测作业自动生成,以反映模型更改和值得注意的事件。
在识别异常后,下一步通常是尝试确定这些情况的上下文。例如,是否有其他因素导致了这个问题?异常是否仅限于特定的应用程序或服务器?您可以通过分层添加作业或创建多指标作业来开始对这些情况进行故障排除。
高级或多指标作业结果
编辑从概念上讲,您可以将多指标异常检测作业视为运行多个独立的单指标作业。但是,通过将它们捆绑在多指标作业中,您可以看到所有指标和作业中所有实体的总体分数和共享影响因素。因此,多指标作业比许多独立的单指标作业具有更好的可扩展性。当您拥有跨检测器共享的影响因素时,它们还可以提供更好的结果。
您还可以将异常检测作业配置为根据分类字段将单个时间序列拆分为多个时间序列。例如,response_code_rates作业具有一个检测器,它根据response.keyword拆分数据,然后使用count函数来确定事件数量何时异常。如果您想查看按响应代码划分的请求高低速率,则可以使用这样的作业。
让我们首先查看异常资源管理器中的response_code_rates作业
- 在 机器学习 中选择 异常检测 选项卡,以查看您的异常检测作业列表。
- 通过单击作业行中的相应图标,在异常资源管理器中打开
response_code_rates作业以查看其结果。
对于此特定作业,您可以选择为每个客户端 IP 或响应代码查看单独的泳道。例如
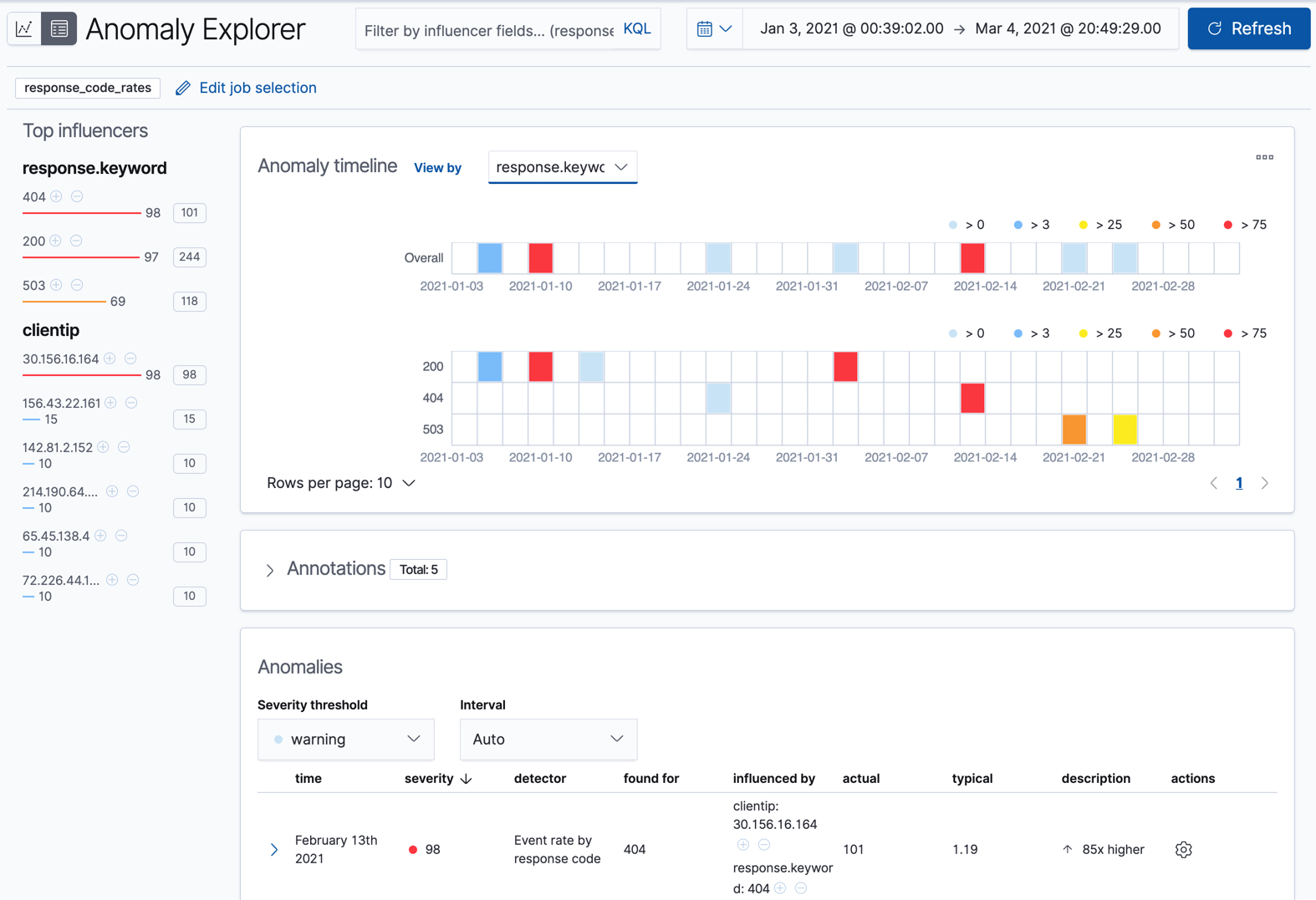
由于该作业使用response.keyword作为其分区字段,因此分析被分割,以便您对该字段的每个不同值都有完全不同的基线。通过查看每个实体的时间模式,您可能会发现一些在合并视图中可能被隐藏的内容。
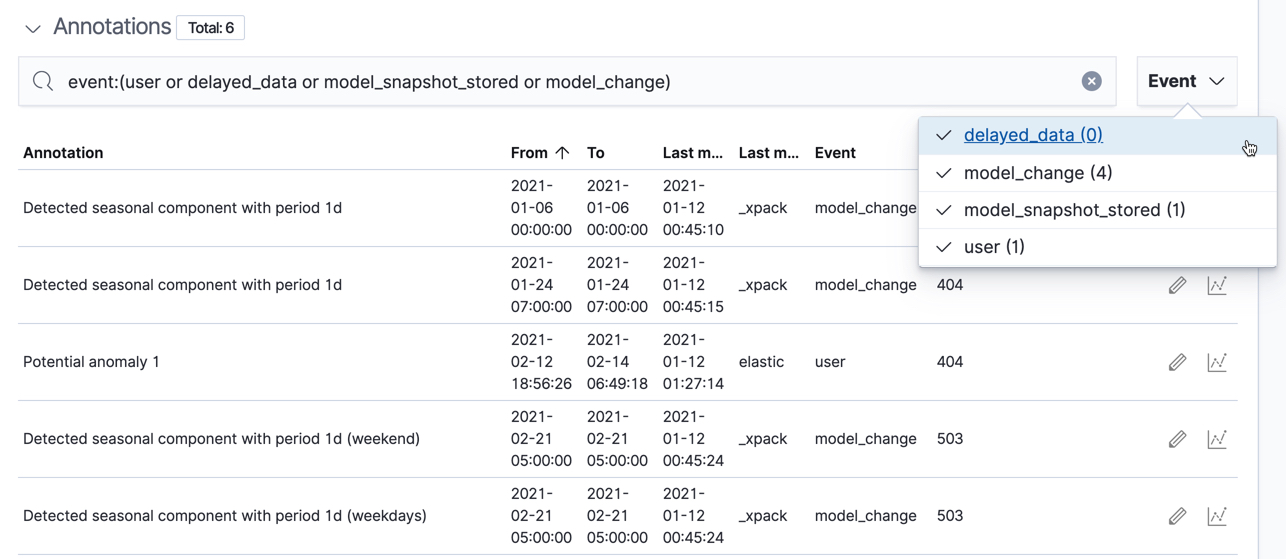
在异常时间轴下方,有一个包含注释的部分。您可以使用注释部分右侧的选择器过滤事件类型。
在异常资源管理器的左侧,列出了同一时间段内所有检测到的异常的前五大影响因素。该列表包括最大异常分数(在本例中,是为每个影响因素、每个桶和所有检测器聚合的),以及每个影响因素的异常分数总和。您可以使用此列表来帮助您缩小贡献因素的范围,并关注最异常的实体。
单击泳道中的某个部分,以获取有关该时间段内异常的更多信息。例如,单击response.keyword值为404的泳道中的红色部分
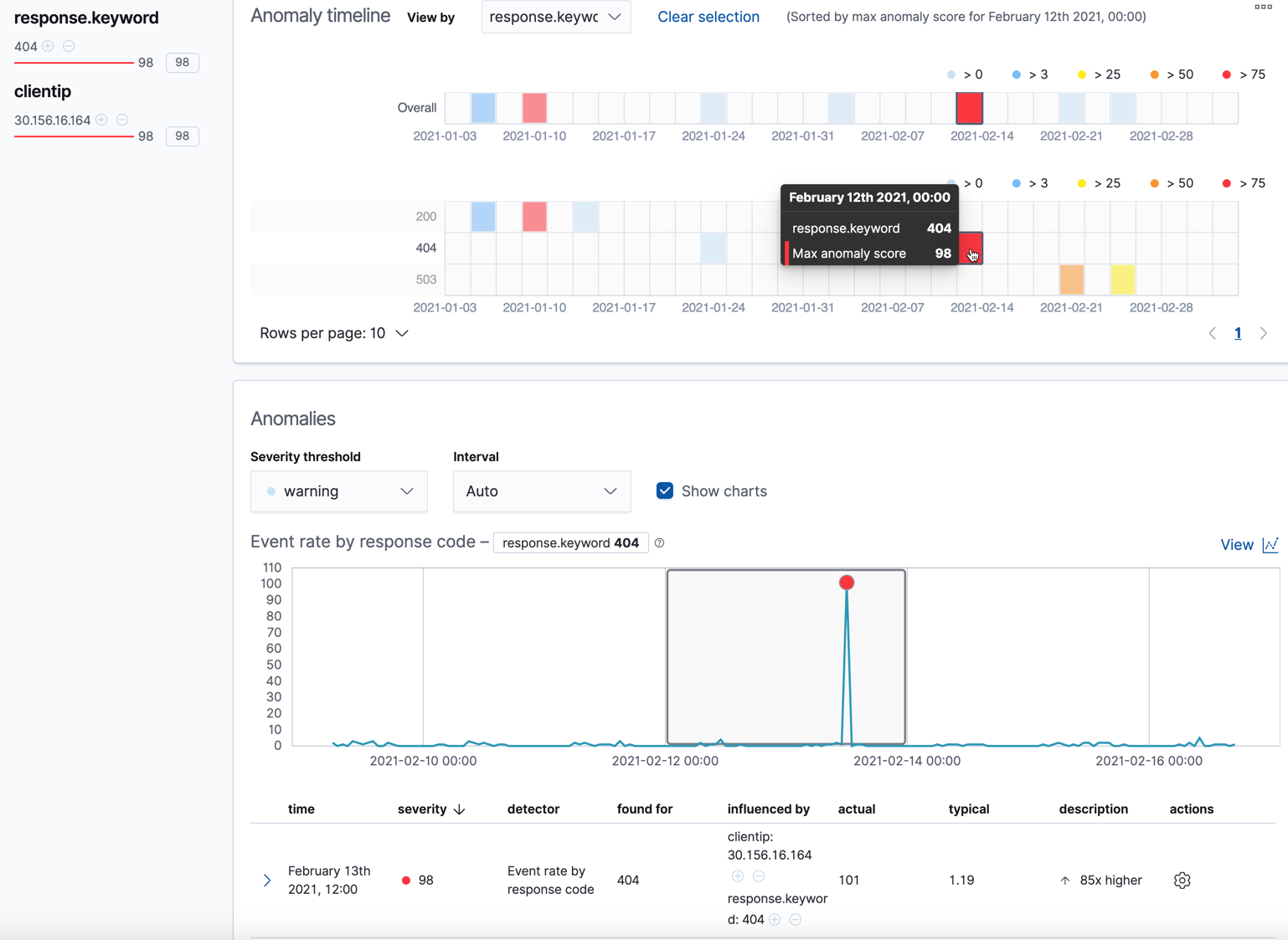
您可以查看异常发生的确切时间。如果作业中有多个检测器或指标,您可以查看哪个检测器捕获了异常。您还可以通过单击操作菜单中的查看序列按钮,切换到在单指标查看器中查看此时间序列。
图表下方有一个表,提供更多信息,例如典型值和实际值以及导致异常的影响因素。例如
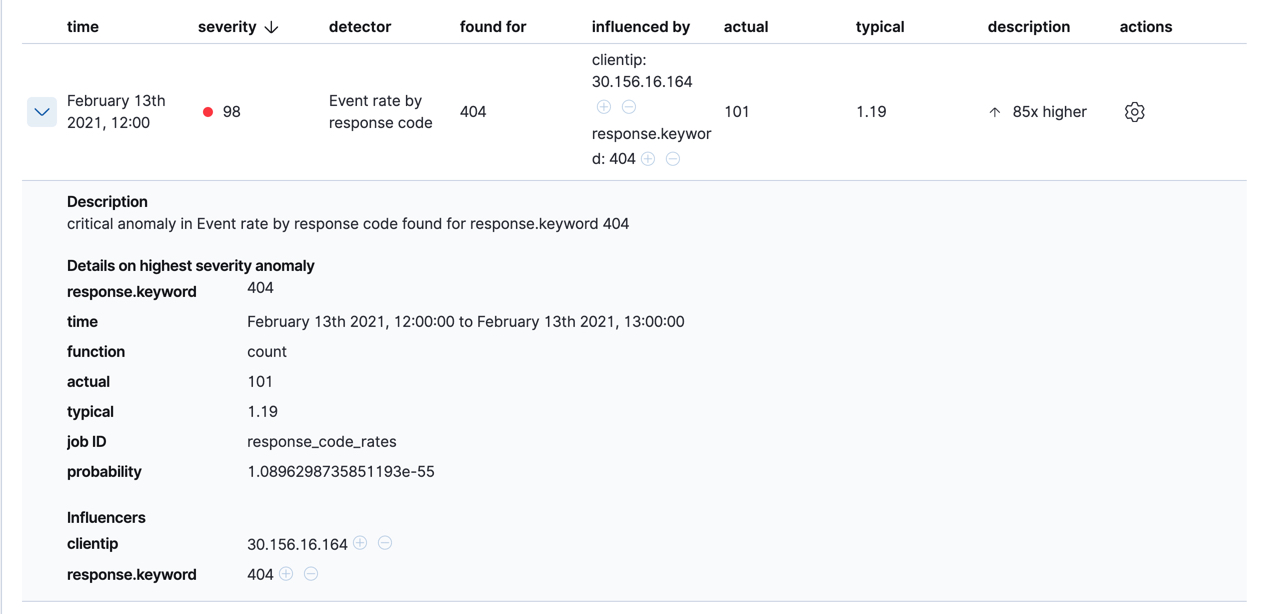
如果您的作业有多个检测器,则该表会聚合异常以显示每个检测器和实体的最高严重性异常,该实体是在发现于列中显示的字段值。要查看所有异常而无需任何聚合,请将间隔设置为显示全部。
在此示例数据中,404 响应代码的峰值受特定客户端的影响。这种情况可能表明客户端正在访问异常页面或扫描您的站点以查看他们是否可以访问异常 URL。这种异常行为值得进一步调查。
异常资源管理器每个部分中显示的异常分数可能略有不同。这种差异是由于每个作业都有桶结果、影响因素结果和记录结果。为每种类型的结果生成异常分数。异常时间轴使用桶级异常分数。前五大影响因素列表使用影响因素级异常分数。异常列表使用记录级异常分数。
总体作业结果
编辑最终样本作业(url_scanning)是一个总体异常检测作业。正如我们在response_code_rates作业结果中看到的那样,有些客户端似乎正在访问异常高的 URL 数量。url_scanning样本作业提供了另一种调查此类问题的方法。它有一个检测器,它使用url.keyword上的high_distinct_count函数来检测该字段中异常高的不同值数量。然后,它分析这种行为在客户端总体(由clientip字段定义)上的差异。
如果您在异常资源管理器中检查url_scanning异常检测作业的结果,您会注意到其图表格式不同。例如
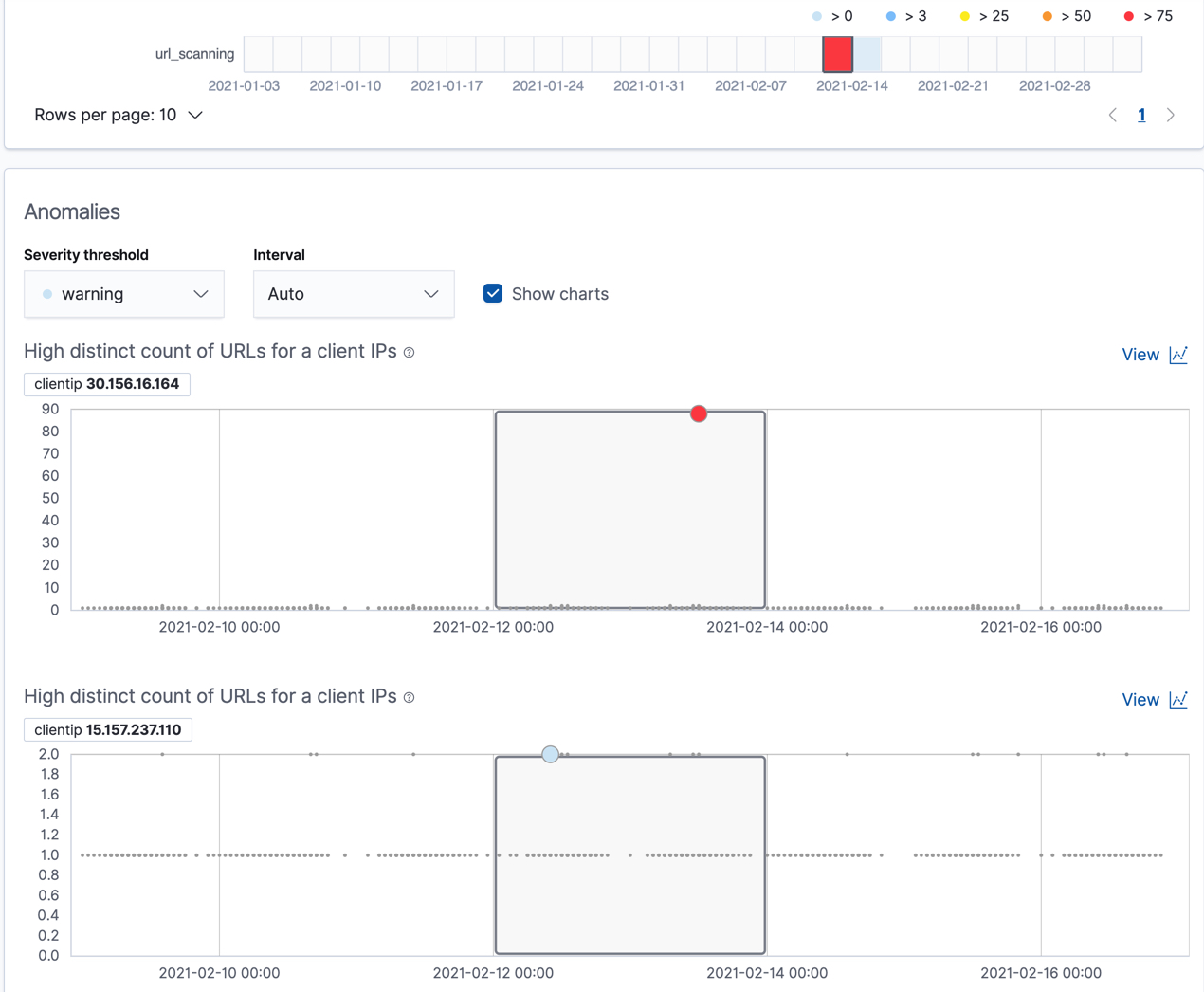
在这种情况下,每个客户端 IP 的指标相对于每个桶中的其他客户端 IP 进行分析,我们再次可以看到30.156.16.164客户端 IP 的行为异常。
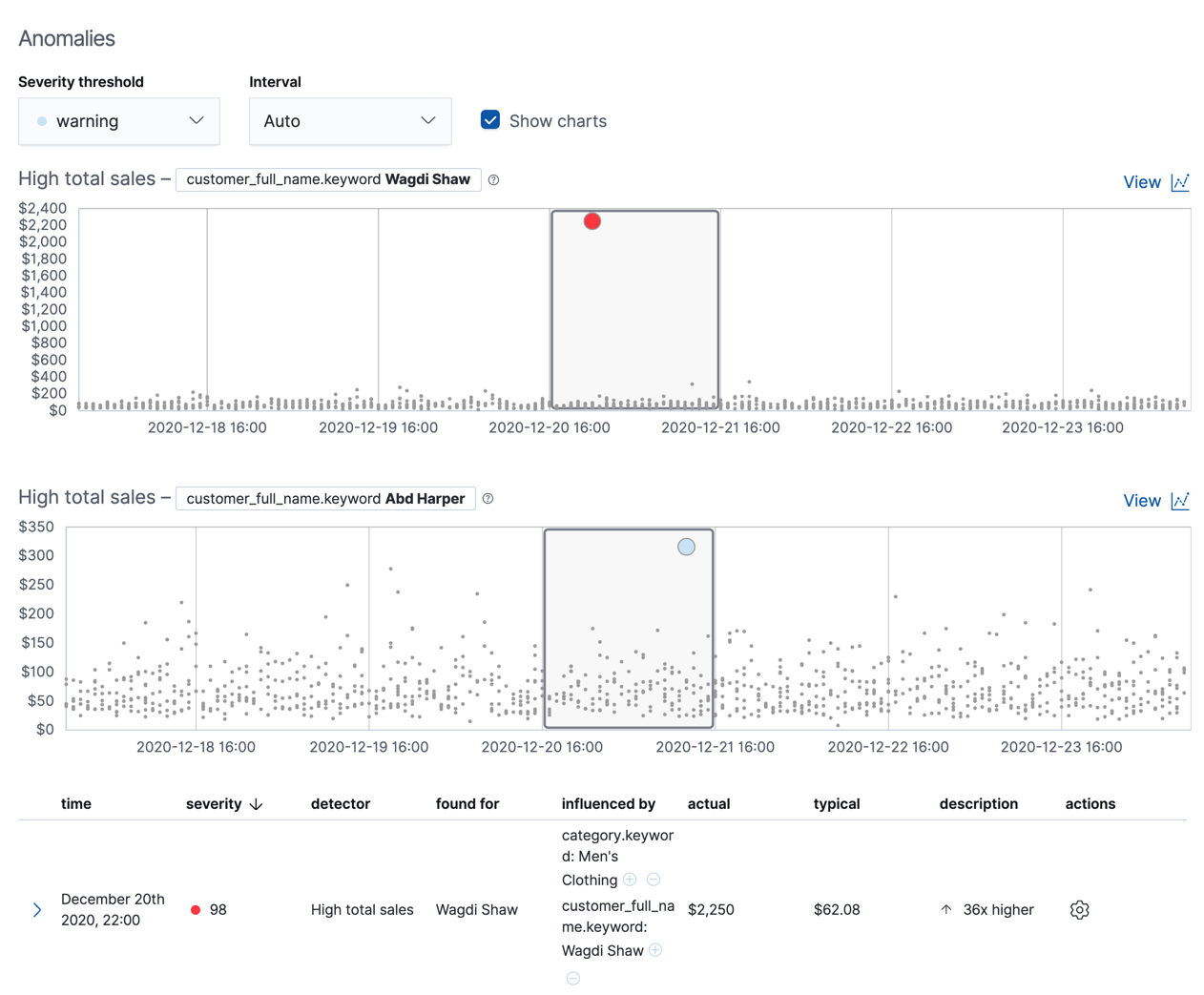
如果您想尝试另一个总体异常检测作业示例,请添加示例电子商务订单数据集。其high_sum_total_sales作业确定哪些客户的购买量相对于每个时间段中的其他客户而言异常高。在此示例中,为两位客户发现了异常事件
创建预测
编辑除了检测数据中的异常行为外,您还可以使用机器学习功能来预测未来的行为。
在 Kibana 中创建预测
- 在单指标查看器中查看作业结果(例如,对于
low_request_rate作业)。要查找该视图,请单击异常检测页面上的操作列中的查看序列按钮。 -
单击预测。
-
指定预测的持续时间。此值指示超出处理的最后一条记录的推断范围。必须使用时间单位。在此示例中,持续时间为一周(
1w)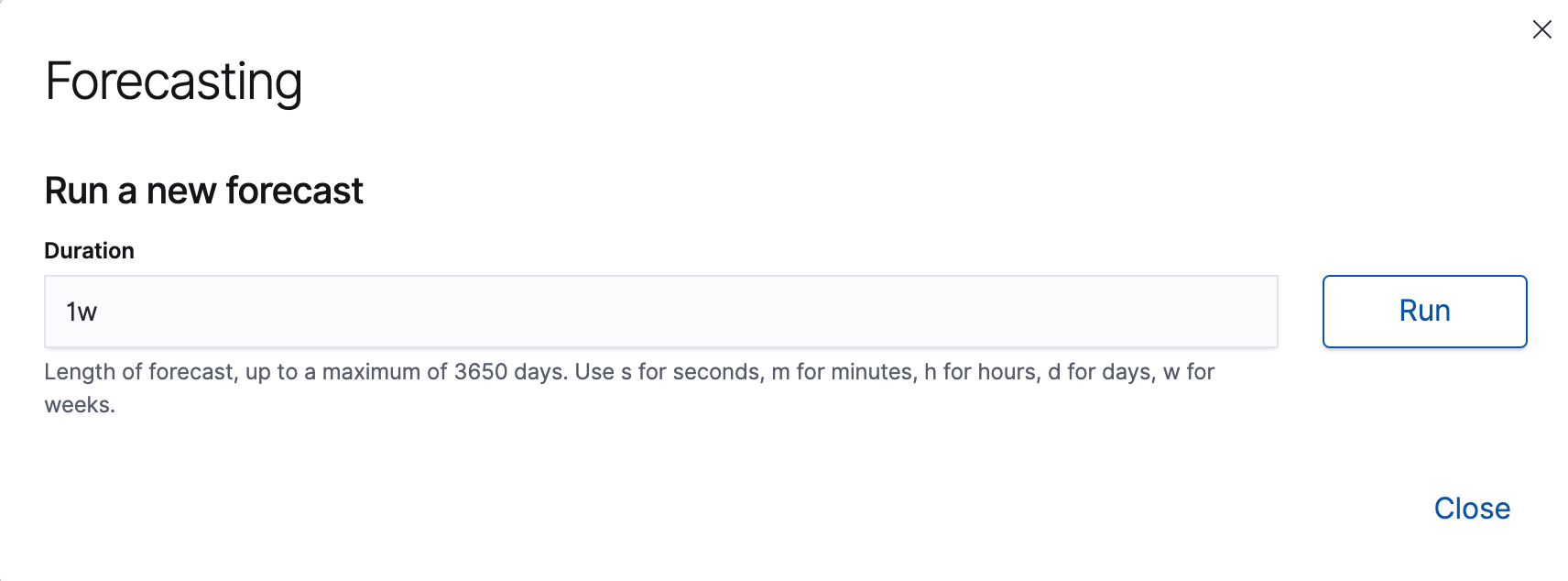
-
在单指标查看器中查看预测
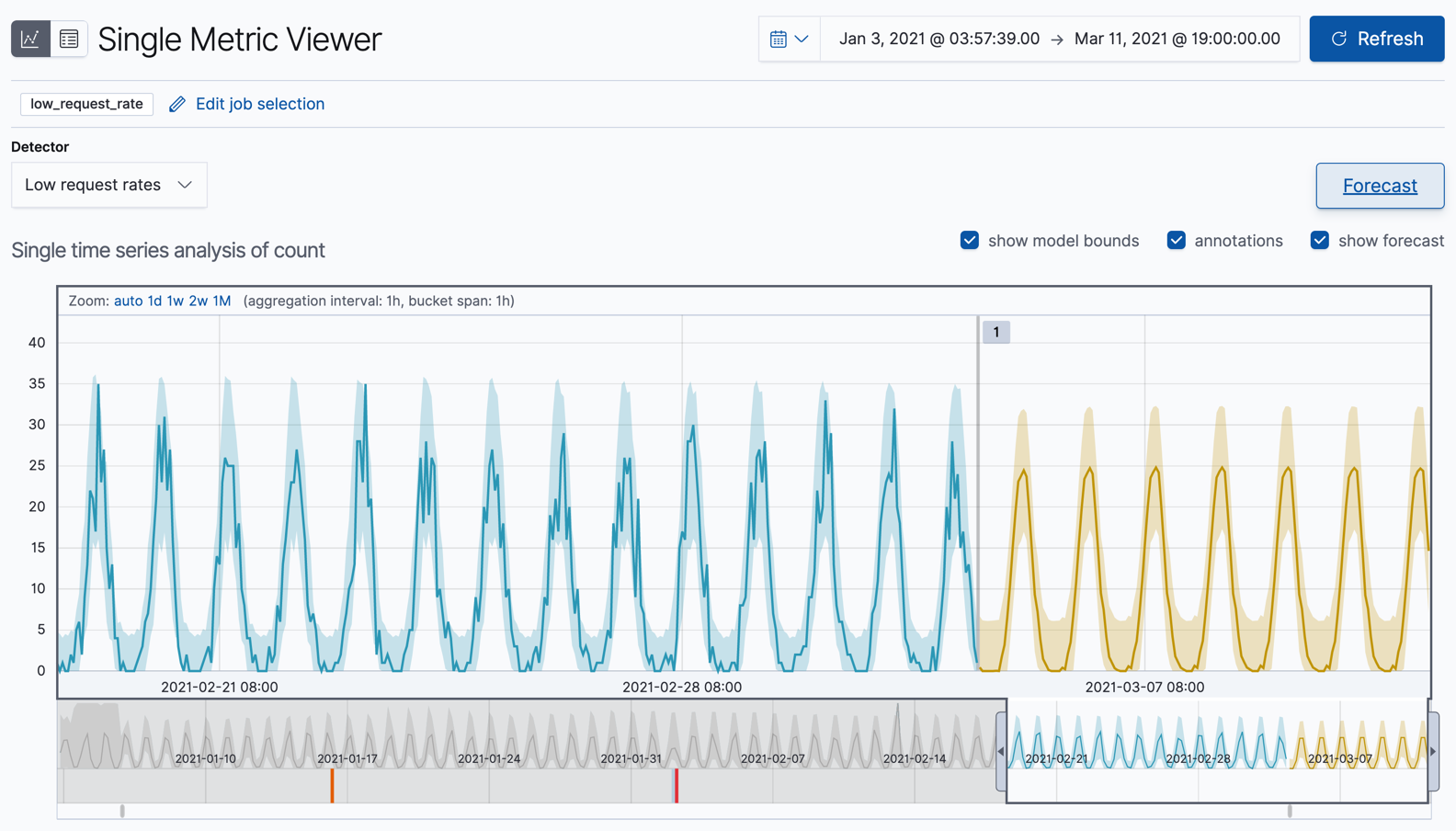
图表中的黄线代表预测的数据值。阴影黄区域代表预测值的范围,这也指示了预测的置信度。请注意,范围通常会随着时间的推移而增加(也就是说,置信度会降低),因为您正在预测更远的未来。最终,如果置信度太低,预测将停止。
-
可选:将预测与实际数据进行比较。
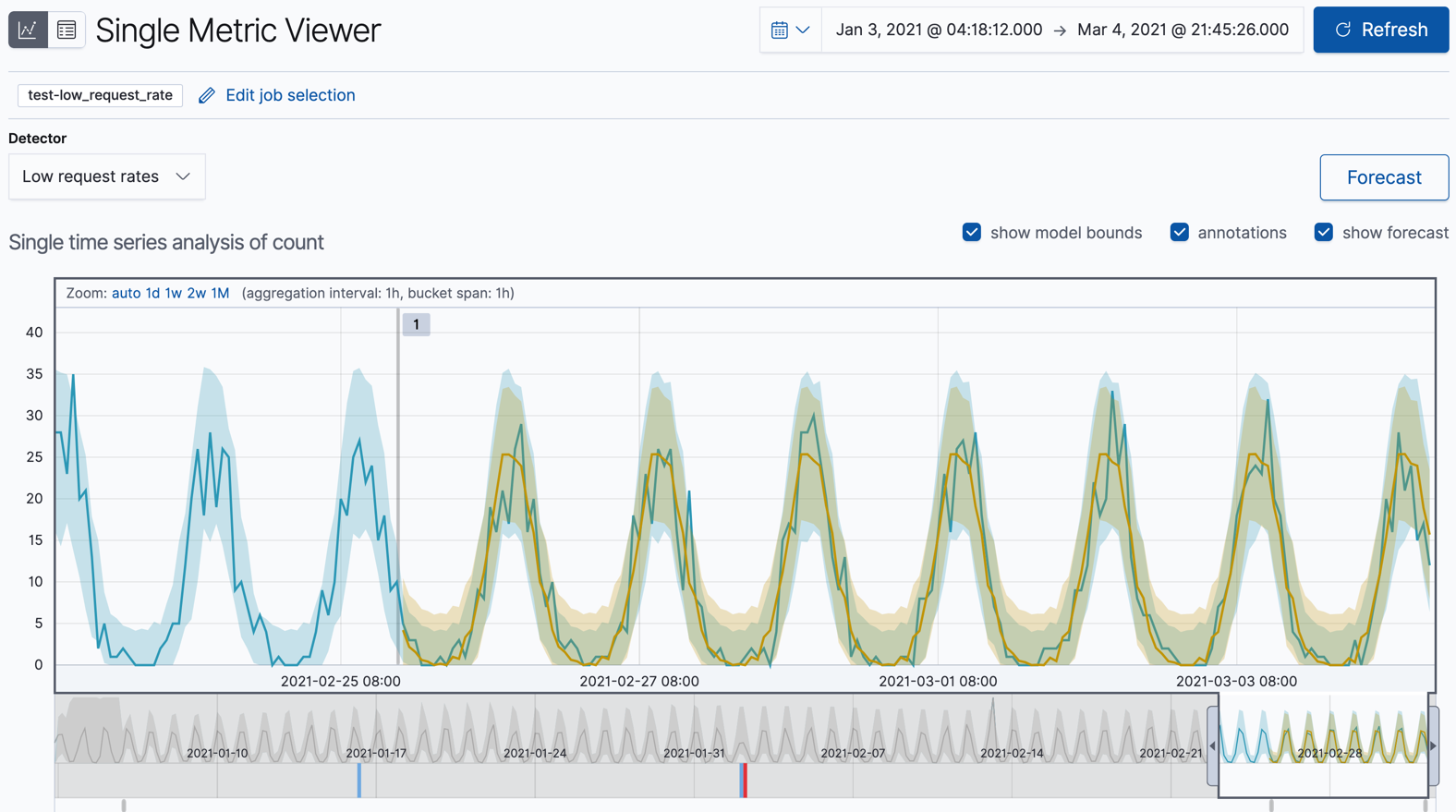
随着作业处理更多数据,您可以再次单击预测按钮,并选择查看叠加在实际数据上的预测之一。然后,图表将包含实际数据值、预期值的范围、异常值、预测数据值以及预测的范围。实际数据和预测数据的这种组合可以让您了解机器学习功能预测数据未来行为的有效性。
如果您想查看 Kibana 示例数据(文档数量有限)的此类比较,可以在创建预测之前重置作业并仅分析数据子集。例如,从 Kibana 中的作业管理页面重置其中一个异常检测作业,或使用重置异常检测作业 API。重新启动此作业的数据馈送时,选择样本数据中间部分的日期作为搜索结束日期。默认情况下,数据馈送停止,并且异常检测作业在达到该日期时关闭。创建预测。然后,您可以重新启动数据馈送以处理剩余数据并生成此处显示的结果类型。
Kibana 示例数据集的时间戳是相对于您添加数据集的时间而言的。但是,其中一些日期在未来。因此,出于本教程的目的,重新启动数据馈送时,请不要使用无结束时间(实时搜索)选项。指定适当的结束日期,以便立即处理所有数据。
既然您已经了解了使用示例数据创建预测有多么容易,请考虑您可能想要预测自己数据中的哪种类型的事件。有关更多信息和想法,请参见预测未来行为。
后续步骤
编辑通过完成本教程,您已经了解了如何在简单的示例数据集中检测异常行为。您在 Kibana 中创建了异常检测作业,它会在后台为您打开作业并创建和启动数据馈送。您在 Kibana 的单指标查看器和异常资源管理器中检查了机器学习分析的结果。您还通过创建预测来推断作业的未来行为。
如果您现在正在考虑异常检测对您自己的数据最有效的地方,则需要考虑以下三点
- 它必须是时间序列数据。
- 它应该是包含业务或系统健康状况、安全状况或成功状况的关键性能指标的信息。您对数据的了解越透彻,创建能够生成有用见解的作业的速度就越快。
- 理想情况下,数据位于 Elasticsearch 中,因此您可以创建实时检索数据的数据馈送。如果您的数据位于 Elasticsearch 之外,则不能使用 Kibana 创建作业,也不能使用数据馈送。
通常,最好从关键性能指标的单指标异常检测作业开始。检查这些简单的分析结果后,您将更好地了解影响因素可能是什么。您可以根据需要创建多指标作业并拆分数据或创建更复杂的分析函数。有关更复杂的配置选项的示例,请参见示例。
如果您想查找更多示例作业,请参见提供的配置。特别是,有一些针对Apache和Nginx的示例作业,它们与本教程中的示例非常相似。
如果您遇到问题,我们将竭诚为您提供帮助。如果您是拥有支持合同的现有 Elastic 客户,请在Elastic 支持门户中创建一个工单。或者在Elastic 论坛中发帖。