创建正常运行时间持续时长异常规则
编辑创建正常运行时间持续时长异常规则
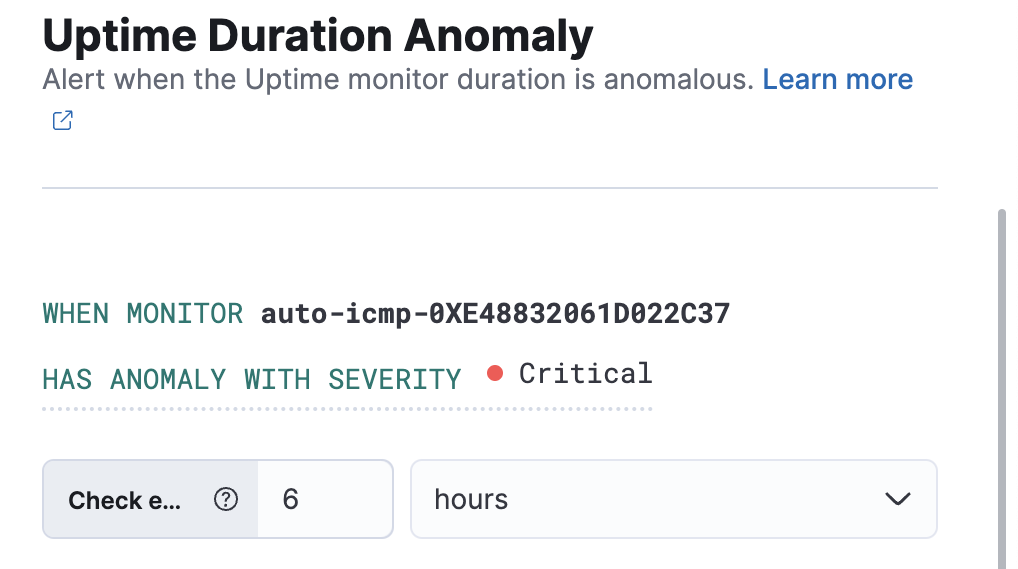
编辑在正常运行时间应用程序中,创建 正常运行时间持续时长异常 规则,以根据每个监控器所有地理位置的响应时长接收通知。当监控器在特定时间运行异常时长时,将在 监控器时长 图表上记录并突出显示异常。
条件
编辑对于每个规则,您可以配置触发警报的严重级别。默认级别为 critical。
异常分数 是一个从 0 到 100 的值,表示异常相对于先前看到的异常的重要性。高异常值以红色显示,低分值以蓝色显示。
警告 |
分数 |
次要 |
分数 |
主要 |
分数 |
严重 |
分数 |
操作类型
编辑通过将规则连接到使用以下支持的内置集成操作来扩展您的规则。操作是 Kibana 服务或与第三方系统的集成,当满足规则条件时,它们在 Kibana 服务器上作为后台任务运行。
您可以在 设置 页面上配置操作类型。
某些连接器类型是付费的商业功能,而其他类型是免费的。有关 Elastic 订阅级别的比较,请转到 订阅页面。
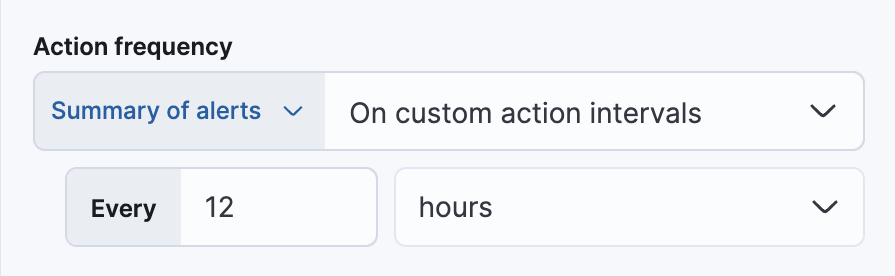
选择连接器后,必须设置操作频率。您可以选择在每次检查间隔或自定义间隔中创建警报摘要。例如,每十二小时发送电子邮件通知,总结新的、正在进行的和已恢复的警报
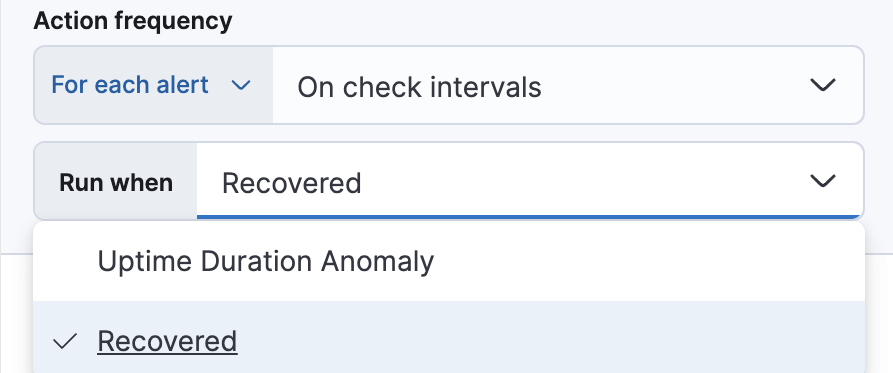
或者,您可以设置操作频率,以便选择操作运行的频率(例如,在每次检查间隔时、仅当警报状态更改时或在自定义操作间隔时)。在这种情况下,您还必须选择影响操作运行时间的特定阈值条件:正常运行时间持续时长异常 或 已恢复。
操作变量
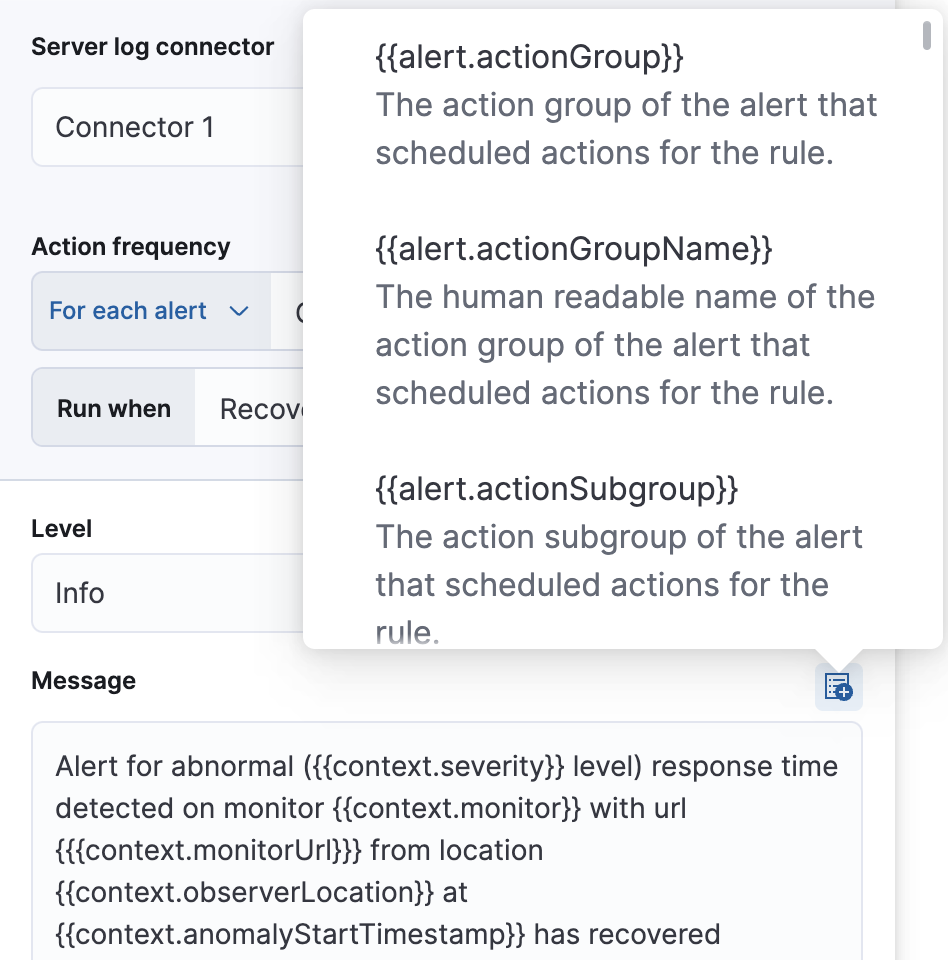
编辑使用默认通知消息或自定义消息。您可以通过单击消息文本框上方的图标并从可用变量列表中选择来向消息添加更多上下文。
警报恢复
编辑要在警报恢复时收到通知,请选择 在已恢复时运行。使用默认通知消息或自定义消息。您可以通过单击消息文本框上方的图标并从可用变量列表中选择来向消息添加更多上下文。