连接到您自己的本地 LLM
编辑连接到您自己的本地 LLM
编辑本页提供有关使用 LM Studio 设置连接器以连接您选择的大型语言模型 (LLM) 的说明。这使您可以在 Elastic Security 中使用您选择的模型。您首先需要设置一个反向代理以与 Elastic Security 通信,然后在服务器上设置 LM Studio,最后在您的 Elastic 部署中配置连接器。了解有关使用本地 LLM 的好处的更多信息。
此示例使用在 GCP 中托管的单个服务器来运行以下组件
- 具有 Mixtral-8x7b 模型的 LM Studio
- 使用 Nginx 的反向代理,用于向 Elastic Cloud 进行身份验证
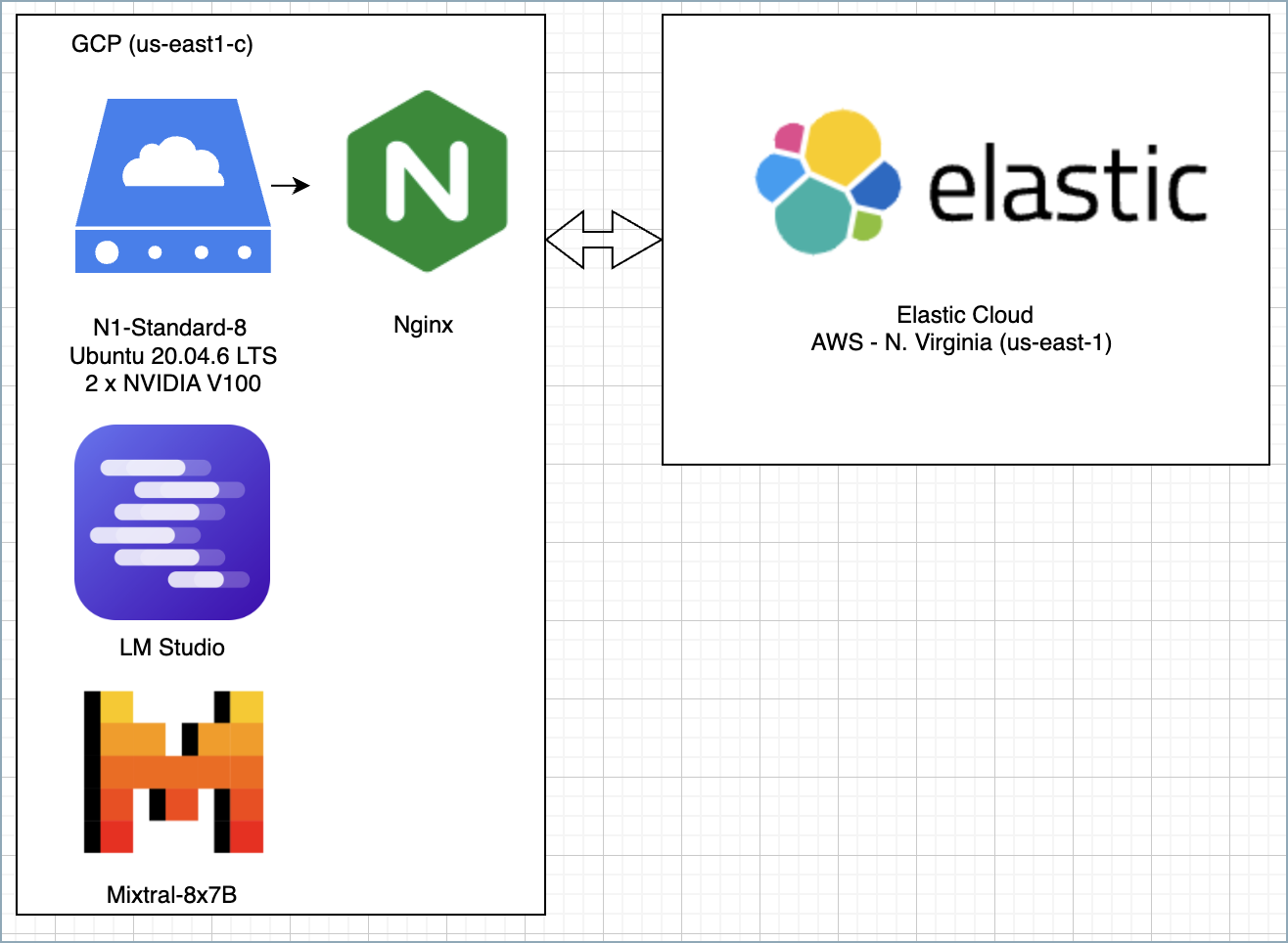
对于测试,您可以使用 Nginx 的替代方案,例如 Azure Dev Tunnels 或 Ngrok,但使用 Nginx 可以通过使用 Elastic 的原生 Nginx 集成轻松收集其他遥测数据并监控其状态。虽然此示例使用云基础设施,但也可以在没有 Internet 连接的情况下在本地复制。
配置您的反向代理
编辑如果您的 Elastic 实例与 LM Studio 在同一主机上,则可以跳过此步骤。
您需要设置一个反向代理以启用 LM Studio 和 Elastic 之间的通信。有关更完整的说明,请参阅诸如此篇的指南。
以下是 Nginx 配置文件的示例
server {
listen 80;
listen [::]:80;
server_name <yourdomainname.com>;
server_tokens off;
add_header x-xss-protection "1; mode=block" always;
add_header x-frame-options "SAMEORIGIN" always;
add_header X-Content-Type-Options "nosniff" always;
return 301 https://$server_name$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name <yourdomainname.com>;
server_tokens off;
ssl_certificate /etc/letsencrypt/live/<yourdomainname.com>/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/<yourdomainname.com>/privkey.pem;
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:50m;
ssl_session_tickets on;
ssl_ciphers 'ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256';
ssl_protocols TLSv1.3 TLSv1.2;
ssl_prefer_server_ciphers on;
add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload" always;
add_header x-xss-protection "1; mode=block" always;
add_header x-frame-options "SAMEORIGIN" always;
add_header X-Content-Type-Options "nosniff" always;
add_header Referrer-Policy "strict-origin-when-cross-origin" always;
ssl_stapling on;
ssl_stapling_verify on;
ssl_trusted_certificate /etc/letsencrypt/live/<yourdomainname.com>/fullchain.pem;
resolver 1.1.1.1;
location / {
if ($http_authorization != "Bearer <secret token>") {
return 401;
}
proxy_pass https://127.0.0.1:1234/;
}
}
如果使用上面的示例配置文件,则必须替换几个值:将 <secret token> 替换为您的实际令牌,并妥善保管,因为您需要它来设置 Elastic Security 连接器。将 <yourdomainname.com> 替换为您的实际域名。如果您决定将 LM Studio 中的端口号更改为 1234 以外的其他值,请更新配置底部的 proxy_pass 值。
(可选)为您的反向代理设置性能监控
编辑您可以使用 Elastic 的 Nginx 集成来监控性能并在 Elastic Security 应用程序中填充监控仪表板。
配置 LM Studio 并下载模型
编辑首先,安装 LM Studio。LM Studio 支持 OpenAI SDK,这使其与 Elastic 的 OpenAI 连接器兼容,允许您连接到 LM Studio 市场中提供的任何模型。
LM Studio 当前的一个限制是,当它安装在服务器上时,您必须先使用其 GUI 启动应用程序,然后再使用 CLI 启动。例如,通过将 Chrome RDP 与 X Window System 结合使用。第一次使用 GUI 打开应用程序后,您可以使用 CLI 中的 sudo lms server start 启动它。
启动 LM Studio 后
- 转到 LM Studio 的“搜索”窗口。
- 搜索 LLM(例如,
Mixtral-8x7B-instruct)。您选择的模型必须在其名称中包含instruct才能与 Elastic 一起使用。 -
过滤您的“兼容性猜测”搜索,以优化您的硬件的结果。结果将以颜色编码
- 绿色表示“可以完全 GPU 卸载”,这将产生最佳结果。
- 蓝色表示“可以部分 GPU 卸载”,这可能会起作用。
- 红色表示“对于此机器来说可能太大”,通常不起作用。
- 下载一个或多个模型。
出于安全原因,在下载模型之前,请验证它是否来自受信任的来源。查看社区对模型的反馈(例如,使用像 Hugging Face 这样的站点)可能会有所帮助。
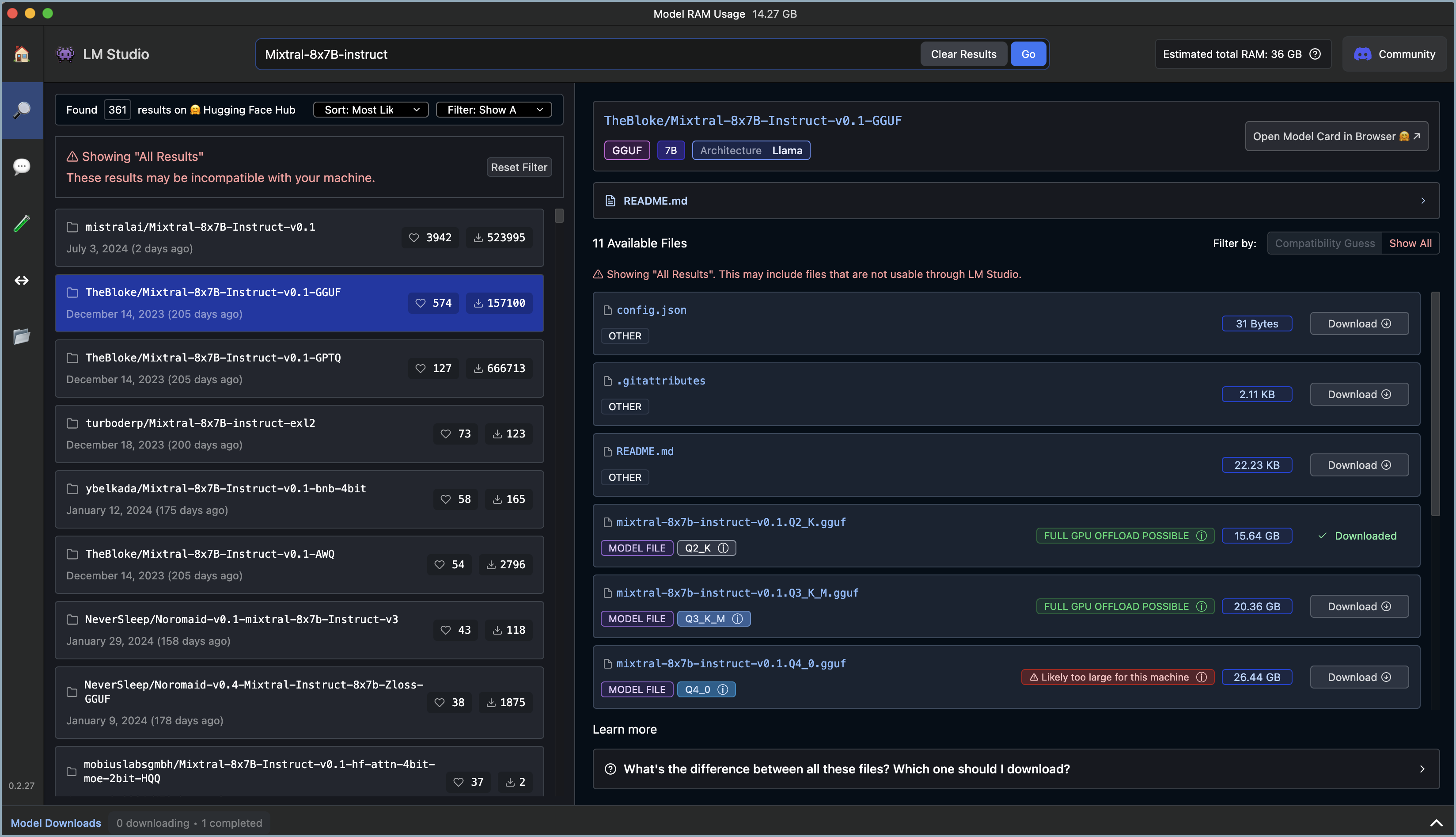
在此示例中,我们使用了 TheBloke/Mixtral-8x7B-Instruct-v0.1.Q3_K_M.gguf。它总共有 467 亿个参数、一个 32,000 个标记的上下文窗口,并使用 GGUF 量化。有关模型名称和格式信息的更多信息,请参阅下表。
| 模型名称 | 参数大小 | 标记/上下文窗口 | 量化格式 |
|---|---|---|---|
模型名称,有时带有版本号。 |
LLM 通常按其参数数量进行比较 - 数字越大,表示模型越强大。 |
标记是输入信息的小块。标记不一定与字符对应。您可以使用 分词器来查看给定提示可能包含多少个标记。 |
量化会减少总体参数并帮助模型更快地运行,但会降低准确性。 |
示例:Llama、Mistral、Phi-3、Falcon。 |
参数数量是衡量模型大小和复杂性的指标。模型拥有的参数越多,它可以处理、学习、生成和预测的数据就越多。 |
上下文窗口定义了模型一次可以处理多少信息。如果输入标记的数量超过此限制,输入将被截断。 |
量化的特定格式各不相同,现在大多数模型都支持 GPU 而不是 CPU 卸载。 |
在 LM Studio 中加载模型
编辑下载模型后,使用 GUI 或 LM Studio 的 CLI 工具在 LM Studio 中加载模型。
选项 1:使用 CLI 加载模型(推荐)
编辑最佳实践是使用 GUI 从市场下载模型,然后使用 CLI 加载或卸载它们。GUI 允许您搜索模型,而 CLI 只允许您导入特定路径,但 CLI 为加载和卸载提供了良好的界面。
在您的 CLI 中使用以下命令
- 验证是否已安装 LM Studio:
lms - 检查 LM Studio 的状态:
lms status - 列出所有下载的模型:
lms ls - 加载模型:
lms load
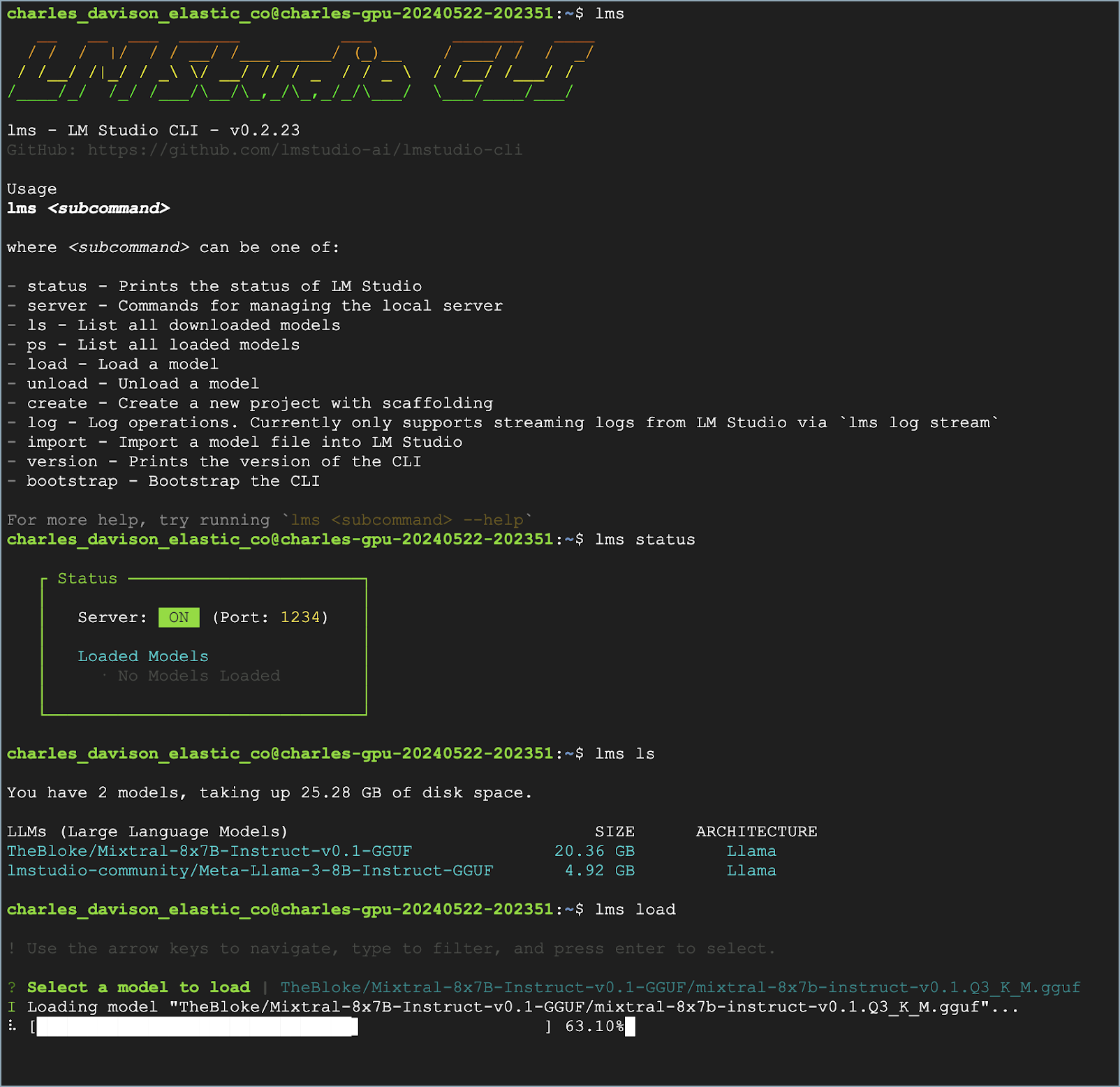
模型加载后,您应该在 CLI 中看到 Model loaded successfully 消息。

要验证加载了哪个模型,请使用 lms ps 命令。

如果您的模型使用 NVIDIA 驱动程序,您可以使用 sudo nvidia-smi 命令检查 GPU 性能。
选项 2:使用 GUI 加载模型
编辑请参阅以下视频,了解如何使用 LM Studio 的 GUI 加载模型。您可以更改 端口 设置,该设置在 Nginx 配置文件中引用。请注意,GPU 卸载设置为 最大。

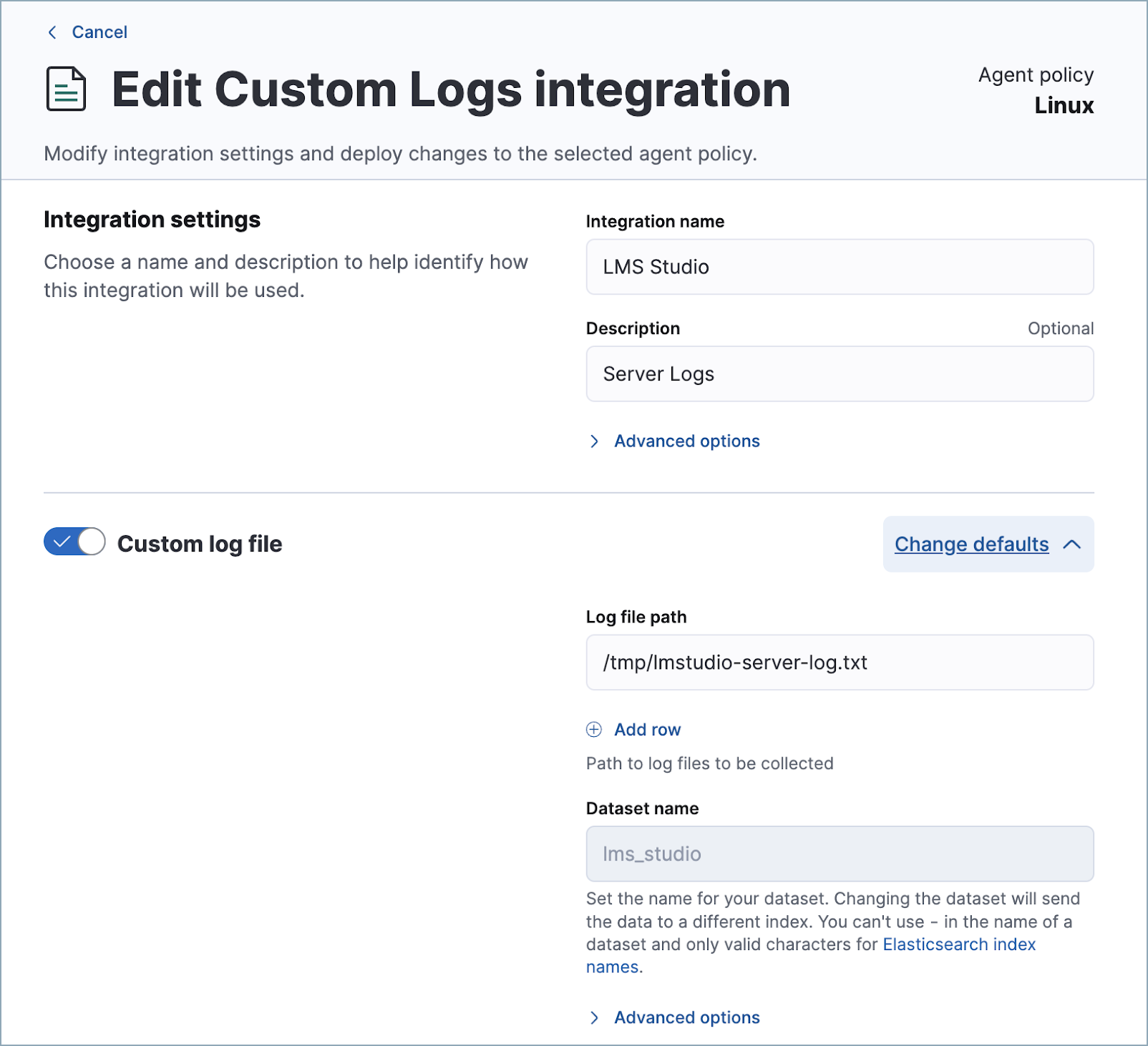
(可选)使用 Elastic 的自定义日志集成收集日志
编辑您可以使用 Elastic 的 自定义日志集成来监控运行 LM Studio 的主机的性能。这也有助于进行故障排除。请注意,LM Studio 日志的默认路径是 /tmp/lmstudio-server-log.txt,如下面的屏幕截图所示
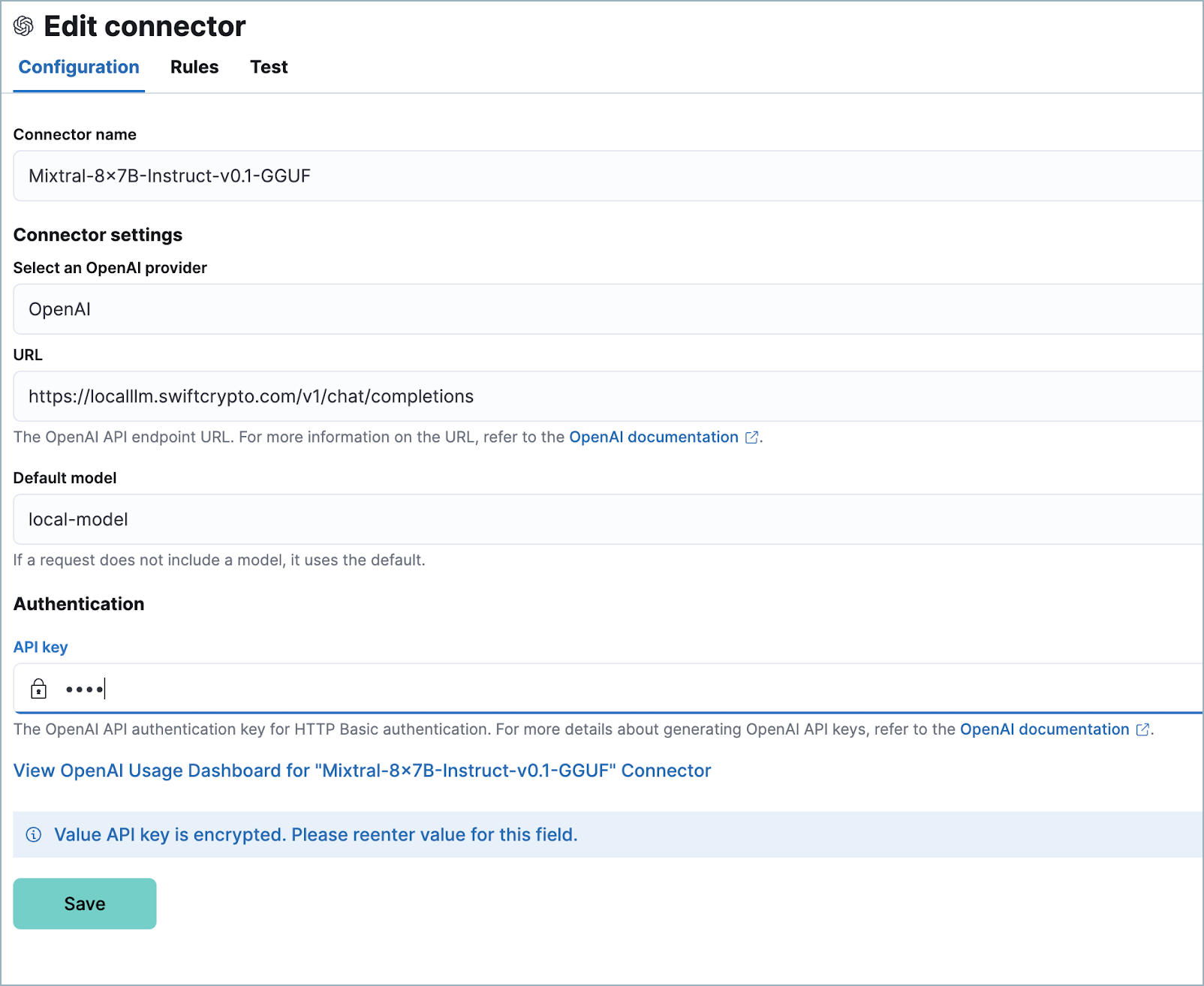
在您的 Elastic 部署中配置连接器
编辑最后,配置连接器
- 登录到您的 Elastic 部署。
- 在导航菜单中找到 连接器 页面或使用 全局搜索字段。然后单击 创建连接器,并选择 OpenAI。OpenAI 连接器启用此用例,因为 LM Studio 使用 OpenAI SDK。
- 命名您的连接器,以帮助您跟踪您正在使用的模型版本。
- 在 选择 OpenAI 提供程序 下,选择 其他(OpenAI 兼容服务)。
- 在 URL 下,输入您的 Nginx 配置文件中指定的域名,后跟
/v1/chat/completions。 - 在 默认模型 下,输入
local-model。 - 在 API 密钥 下,输入您的 Nginx 配置文件中指定的密钥令牌。
- 单击 保存。
设置现在完成。您可以使用您在 LM Studio 中加载的模型来支持 Elastic 的生成式 AI 功能。当您与 AI 助手交互时,您可以测试各种模型,以查看哪种模型效果最佳,而无需更新您的连接器。