HTTP JSON 输入
编辑HTTP JSON 输入
编辑使用 httpjson 输入读取具有 JSON 负载的 HTTP API 的消息。
如果您正在开始开发新的自定义 HTTP API 输入,我们建议您使用 通用表达式语言输入,它提供了更大的灵活性和改进的开发体验。
此输入支持
-
身份验证
- 基本认证
- OAuth2
- 以可配置的间隔检索
- 分页
- 重试
- 速率限制
- 代理
- 请求转换
- 响应转换
示例配置
filebeat.inputs:
# Fetch your public IP every minute.
- type: httpjson
interval: 1m
request.url: https://api.ipify.org/?format=json
processors:
- decode_json_fields:
fields: ["message"]
target: "json"
filebeat.inputs:
- type: httpjson
request.url: https://127.0.0.1:9200/_search?scroll=5m
request.method: POST
response.split:
target: body.hits.hits
response.pagination:
- set:
target: url.value
value: https://127.0.0.1:9200/_search/scroll
- set:
target: url.params.scroll_id
value: '[[.last_response.body._scroll_id]]'
- set:
target: body.scroll
value: 5m
此外,它还支持通过基本身份验证、HTTP 标头或 OAuth2 进行身份验证。
带有身份验证的示例配置
filebeat.inputs:
- type: httpjson
request.url: https://127.0.0.1
request.transforms:
- set:
target: header.Authorization
value: 'Basic aGVsbG86d29ybGQ='
filebeat.inputs:
- type: httpjson
auth.oauth2:
client.id: 12345678901234567890abcdef
client.secret: abcdef12345678901234567890
token_url: https://127.0.0.1/oauth2/token
request.url: https://127.0.0.1
filebeat.inputs:
- type: httpjson
auth.oauth2:
client.id: 12345678901234567890abcdef
client.secret: abcdef12345678901234567890
token_url: https://127.0.0.1/oauth2/token
user: [email protected]
password: P@$$W0₹D
request.url: https://127.0.0.1
输入状态
编辑httpjson 输入在请求之间保持运行时状态。此状态可以通过某些配置选项和转换来访问。
该状态具有以下元素
-
last_response.url.value:来自具有成功响应的最后一个请求的完整 URL(包含参数和片段)。 -
last_response.url.params:last_response.url.value中 URL 参数的url.Values。可以使用Get函数查询。 -
last_response.header:包含来自上次成功响应的标头的映射。 -
last_response.body:包含来自上次成功响应的已解析 JSON 主体的映射。这是来自远程服务器的响应。 -
last_response.page:指示上次响应的页码的数字。它在每个间隔开始时值为0。 -
first_event:表示发送到输出的第一个事件的映射(将转换应用于last_response.body的结果)。 -
last_event:表示请求链中当前请求的最后一个事件的映射(将转换应用于last_response.body的结果)。 -
url:作为原始url.URLGo 类型的上次请求的 URL。 -
header:包含标头的映射。在request.rate_limit.early_limit或response.pagination配置部分中使用时,引用下一个请求标头;在response.transforms、response.split或request.rate_limit.limit配置部分中使用时,引用最后一个响应标头。 -
body:包含主体的映射。在request.rate_limit.early_limit或response.pagination配置部分中使用时,引用下一个请求主体;在response.transforms或response.split配置部分中使用时,引用最后一个响应主体。 -
cursor:包含用户配置的要在重启之间存储的任何数据的映射(参见cursor)。
除了 cursor(其值在定期请求和重启之间持久化)之外,所有提到的对象仅在定期请求执行期间的运行时存储。
转换
编辑转换是一个操作,允许用户修改 输入状态。根据转换的定义位置,它将能够读取或写入 状态的不同元素。
访问限制在相应的配置部分中进行了描述。
append
编辑将值追加到数组。如果字段不存在,第一个条目将创建一个新数组。如果字段存在,则将值追加到现有字段并将其转换为列表。
- append:
target: body.foo.bar
value: '[[.cursor.baz]]'
default: "a default value"
-
target定义存储值的目标字段。 -
value定义将要存储的值,它是一个 值模板。 -
default定义每当value为空或模板解析失败时的回退值。默认模板无法访问任何状态,只能访问函数。 -
value_type定义结果值的类型。可能的值为:string、json和int。默认为string。 -
fail_on_template_error如果设置为true,则当模板评估失败时,将返回错误并且请求将中止。默认为false。 -
do_not_log_failure如果设置为 true,则不会记录fail_on_template_error,除非在 DEBUG 级别。当模板失败在正常操作中作为控制流预期时,应使用此选项。
delete
编辑删除目标字段。
- delete:
target: body.foo.bar
-
target定义要删除的目标字段。如果target是列表而不是单个元素,则将删除整个列表。
set
编辑设置值。
- set:
target: body.foo.bar
value: '[[.cursor.baz]]'
default: "a default value"
-
target定义存储值的目标字段。 -
value定义将要存储的值,它是一个 值模板。 -
default定义每当value为空或模板解析失败时的回退值。默认模板无法访问任何状态,只能访问函数。 -
value_type定义如何处理结果值。可能的值为:string、json和int。默认为string。 -
fail_on_template_error如果设置为true,则当模板评估失败时,将返回错误并且请求将中止。默认为false。 -
do_not_log_failure如果设置为 true,则不会记录fail_on_template_error,除非在 DEBUG 级别。当模板失败在正常操作中作为控制流预期时,应使用此选项。
值模板
编辑某些配置选项和转换可以使用值模板。值模板是具有访问输入状态和某些内置函数功能的 Go 模板。请注意,分隔符已从默认的 {{ }} 更改为 [[ ]],以提高与其他模板机制的互操作性。
要查看哪些 状态元素 和操作可用,请参阅您要在其中使用值模板的选项或 转换 的文档。
值模板如下所示
- set:
target: body.foo.bar
value: '[[.cursor.baz]] more data'
default: "a default value"
方括号 [[ ]] 内的内容将被评估。有关 Go 模板的更多信息,请参阅 Go 文档。
提供了一些内置辅助函数来处理值模板中的输入状态
-
add:添加整数列表并返回它们的和。 -
base64DecodeNoPad:解码不带填充的 base64 字符串。任何二进制输出都将转换为 UTF8 字符串。 -
base64Decode:解码 base64 字符串。任何二进制输出都将转换为 UTF8 字符串。 -
base64EncodeNoPad:连接并对所有提供的字符串进行 base64 编码(不带填充)。示例[[base64EncodeNoPad "string1" "string2"]] -
base64Encode:连接并对所有提供的字符串进行 base64 编码。示例[[base64Encode "string1" "string2"]] -
beatInfo:返回包含有关 Beat 的信息的映射。映射中的可用键为goos(运行的操作系统)、goarch(运行的系统架构)、commit(当前构建的 git 提交)、buildtime(当前构建的编译时间)、version(当前构建的版本)。示例:[[ beatInfo.version ]]返回{version}。 -
div:执行两个整数值的整数除法。 -
formatDate:格式化time.Time。默认格式布局为RFC3339,但可以选择接受任何 Golang 预定义布局或自定义布局。格式化时将默认为 UTC 时区,但您可以指定不同的时区。如果时区不正确,则将默认为 UTC。示例:[[ formatDate (now) "UnixDate" ]]、[[ formatDate (now) "UnixDate" "America/New_York" ]]。 -
getRFC5988Link:从 RFC5988 链接列表中提取特定关系。在解析分页的标头值时非常有用。示例:[[ getRFC5988Link "next" .last_response.header.Link ]]。 -
hashBase64:计算连接在一起的字符串列表的哈希值。返回 base64 编码的哈希值。支持 sha1 或 sha256。示例[[hash "sha256" "string1" "string2" (formatDate (now) "RFC1123")]] -
hash:计算连接在一起的字符串列表的哈希值。返回十六进制编码的哈希值。支持 sha1 或 sha256。示例[[hash "sha256" "string1" "string2" (formatDate (now) "RFC1123")]] -
hexDecode:解码十六进制字符串。任何十六进制字符串都将转换为其字节表示形式。示例[[hexDecode "b0a92a08a9b4883aa3aa2d0957be12a678cbdbb32dc5db09fe68239a09872f96"]];预期输出:"\xb0\xa9*\b\xa9\xb4\x88:\xa3\xaa-\tW\xbe\x12\xa6x\xcb۳-\xc5\xdb\t\xfeh#\x9a\t\x87/\x96" -
hmacBase64:计算连接在一起的字符串列表的 hmac 签名。返回 base64 编码的签名。支持 sha1 或 sha256。示例[[hmac "sha256" "secret" "string1" "string2" (formatDate (now) "RFC1123")]] -
hmac:计算连接在一起的字符串列表的 hmac 签名。返回十六进制编码的签名。支持 sha1 或 sha256。示例[[hmac "sha256" "secret" "string1" "string2" (formatDate (now) "RFC1123")]] -
join:使用指定的分割符连接列表。示例:[[join .body.arr ","]] -
max:返回两个值中的最大值。 -
min:返回两个值中的最小值。 -
mul:将两个整数相乘。 -
now:返回 UTC 中的当前time.Time对象。可以选择接收time.Duration作为参数。示例:[[now (parseDuration "-1h")]]返回现在之前 1 小时的日期时间。 -
parseDate:解析日期字符串并返回 UTC 时间的time.Time对象。默认情况下,预期布局为RFC3339,但也可以选择使用任何 Go 预定义的布局或自定义布局。注意:解析时区缩写可能会导致歧义。建议使用parseDateInTZ进行明确的时区处理。示例:[[ parseDate "2020-11-05T12:25:32Z" ]],[[ parseDate "2020-11-05T12:25:32.1234567Z" "RFC3339Nano" ]],[[ (parseDate "Thu Nov 5 12:25:32 +0000 2020" "Mon Jan _2 15:04:05 -0700 2006").UTC ]]。 -
parseDateInTZ:在指定的时区 (TZ) 内解析日期字符串,返回 UTC 时间的time.Time对象。指定的时区将覆盖输入日期中的隐式时区。接受时区偏移量(“-07:00”、“-0700”、“-07”)或 IANA 时区名称(“America/New_York”)。如果 TZ 无效,则默认为 UTC。可选布局参数与 parseDate 中相同。示例:[[ parseDateInTZ "2020-11-05T12:25:32" "America/New_York" ]],[[ parseDateInTZ "2020-11-05T12:25:32" "-07:00" "RFC3339" ]]。 -
parseDuration:解析持续时间字符串并返回time.Duration。示例:[[parseDuration "1h"]]。 -
parseTimestampMilli:解析以毫秒为单位的时间戳并返回 UTC 时间的time.Time对象。示例:[[parseTimestamp 1604582732000]]返回2020-11-05 13:25:32 +0000 UTC。 -
parseTimestampNano:解析以纳秒为单位的时间戳并返回 UTC 时间的time.Time对象。示例:[[parseTimestamp 1604582732000000000]]返回2020-11-05 13:25:32 +0000 UTC。 -
parseTimestamp:解析以秒为单位的时间戳并返回 UTC 时间的time.Time对象。示例:[[parseTimestamp 1604582732]]返回2020-11-05 13:25:32 +0000 UTC。 -
replaceAll(old, new, s):将s中所有不重叠的old实例替换为new。示例:[[ replaceAll "some" "my" "some value" ]]返回my value。 -
sprintf:根据格式说明符进行格式化并返回生成的字符串。有关用法,请参阅 Go 文档。示例:[[sprintf "%d:%q" 34 "quote this"]] -
toInt:尽可能将任何类型的数值转换为整数。如果转换失败,则返回 0。 -
toJSON:将值转换为 JSON 字符串。这可以与value_type: json一起使用,以根据模板创建对象。示例:[[ toJSON .last_response.body.pagingIdentifiers ]]。 -
urlEncode:对提供的字符串进行 URL 编码。示例[[urlEncode "string1"]]。示例[[urlEncode "<string1>"]]将返回%3Cstring1%3E。 -
userAgent:生成用户代理,并包含可选的附加值。如果没有提供参数,它将生成默认的用户代理,该代理默认添加到所有请求中。建议在设置新的 User-Agent 标头之前删除现有的标头。示例:[[ userAgent "integration/1.2.3" ]]将生成Elastic-Filebeat/8.1.0 (darwin; amd64; 9b893e88cfe109e64638d65c58fd75c2ff695402; 2021-12-15 13:20:00 +0000 UTC; integration_name/1.2.3) -
uuid:返回一个随机 UUID,例如a11e8780-e3e7-46d0-8e76-f66e75acf019。示例:[[ uuid ]]
除了提供的函数外,还可以对相应的对象使用 time.Time、http.Header 和 url.Values 类型的任何原生函数。示例:[[(now).Day]],[[.last_response.header.Get "key"]]
配置选项
编辑httpjson 输入支持以下配置选项以及稍后描述的 常用选项。
interval
编辑重复请求之间的持续时间。如果启用了分页,它可能会根据初始请求响应发出其他分页请求。默认值:60s。
auth.basic.enabled
编辑设置为 false 时,将禁用基本身份验证配置。默认值:true。
如果 enabled 设置为 false 或缺少 auth.basic 部分,则基本身份验证设置将被禁用。
auth.basic.user
编辑用于身份验证的用户。
auth.basic.password
编辑使用的密码。
auth.oauth2.enabled
编辑设置为 false 时,将禁用 oauth2 配置。默认值:true。
如果 enabled 设置为 false 或缺少 auth.oauth2 部分,则 OAuth2 设置将被禁用。
auth.oauth2.provider
编辑用于配置受支持的 oauth2 提供程序。每个受支持的提供程序都需要特定的设置。默认情况下未设置。支持的提供程序包括:azure、google、okta。
auth.oauth2.client.id
编辑用作身份验证流程一部分的客户端 ID。除了使用 google 作为提供程序外,它始终是必需的。对于以下提供程序是必需的:default、azure、okta。
auth.oauth2.client.secret
编辑用作身份验证流程一部分的客户端密钥。除了使用 google 或 okta 作为提供程序外,它始终是必需的。对于以下提供程序是必需的:default、azure。
auth.oauth2.user
编辑用作身份验证流程一部分的用户。对于身份验证 - grant type password 是必需的。仅适用于 default 提供程序。
auth.oauth2.password
编辑用作身份验证流程一部分的密码。对于身份验证 - grant type password 是必需的。仅适用于 default 提供程序。
grant_type password 需要用户名和密码。如果不使用用户名和密码,它将自动使用 token_url 和 client credential 方法。
auth.oauth2.scopes
编辑在 oauth2 流程期间将请求的一系列作用域。对于所有提供程序都是可选的。
auth.oauth2.token_url
编辑将在 oauth2 流程期间用于生成令牌的端点。如果未指定提供程序,则这是必需的。
对于 azure 提供程序,需要 token_url 或 azure.tenant_id。
auth.oauth2.endpoint_params
编辑将发送到 token_url 的每个请求的一组值。每个参数键可以有多个值。可以为除 google 之外的所有提供程序设置。
- type: httpjson
auth.oauth2:
endpoint_params:
Param1:
- ValueA
- ValueB
Param2:
- Value
auth.oauth2.azure.tenant_id
编辑在使用 azure 提供程序时用于身份验证。由于它用于生成 token_url 的过程中,因此不能与之结合使用。这不是必需的。
有关在哪里查找它的信息,您可以参考 https://docs.microsoft.com/en-us/azure/active-directory/develop/howto-create-service-principal-portal。
auth.oauth2.azure.resource
编辑使用 azure 提供程序时访问的 WebAPI 资源。这不是必需的。
auth.oauth2.google.credentials_file
编辑Google 的凭据文件。
一次只能设置一个凭据设置。如果没有提供任何凭据,则将尝试通过 ADC 从环境加载默认凭据。有关如何提供 Google 凭据的更多信息,请参阅 https://cloud.google.com/docs/authentication。
auth.oauth2.google.credentials_json
编辑您的凭据信息(原始 JSON)。
一次只能设置一个凭据设置。如果没有提供任何凭据,则将尝试通过 ADC 从环境加载默认凭据。有关如何提供 Google 凭据的更多信息,请参阅 https://cloud.google.com/docs/authentication。
auth.oauth2.google.jwt_file
编辑Google 的 JWT 帐户密钥文件。
一次只能设置一个凭据设置。如果没有提供任何凭据,则将尝试通过 ADC 从环境加载默认凭据。有关如何提供 Google 凭据的更多信息,请参阅 https://cloud.google.com/docs/authentication。
auth.oauth2.google.jwt_json
编辑JWT 帐户密钥文件(原始 JSON)。
一次只能设置一个凭据设置。如果没有提供任何凭据,则将尝试通过 ADC 从环境加载默认凭据。有关如何提供 Google 凭据的更多信息,请参阅 https://cloud.google.com/docs/authentication。
auth.oauth2.okta.jwk_file
编辑您的 Okta 服务应用程序的 RSA JWK 私钥文件,用于与 Okta Org Auth 服务器交互以使用 okta.* 作用域铸造令牌。
一次只能设置一个凭据设置。有关更多信息,请参阅 https://developer.okta.com/docs/guides/implement-oauth-for-okta-serviceapp/main/
auth.oauth2.okta.jwk_json
编辑您的 Okta 服务应用程序的 RSA JWK 私钥 JSON,用于与 Okta Org Auth 服务器交互以使用 okta.* 作用域铸造令牌。
auth.oauth2.okta.jwk_pem
编辑您的 Okta 服务应用程序的 RSA JWK 私钥 PEM 块,用于与 Okta Org Auth 服务器交互以使用 okta.* 作用域铸造令牌。
一次只能设置一个凭据设置。有关更多信息,请参阅 https://developer.okta.com/docs/guides/implement-oauth-for-okta-serviceapp/main/
auth.oauth2.google.delegated_account
编辑用于创建凭据的委托帐户的电子邮件(通常是管理员)。与 auth.oauth2.google.jwt_file、auth.oauth2.google.jwt_json 一起使用,以及在默认为使用 ADC 时使用。
request.url
编辑HTTP API 的 URL。必需。
可以通过将 +unix 或 +npipe 添加到 URL 方案来通过 Unix 套接字和 Windows 命名管道访问 API 端点,例如 http+unix:///var/socket/。
request.method
编辑发出请求时使用的 HTTP 方法。GET 或 POST 是选项。默认值:GET。
request.encode_as
编辑用于编码请求正文的 ContentType。如果设置了它,它将强制以指定的格式进行编码,而不管 Content-Type 标头值如何,否则它将尽可能遵守它或回退到 application/json。默认情况下,请求使用 Content-Type: application/json 发送。支持的值:application/json 和 application/x-www-form-urlencoded。application/x-www-form-urlencoded 将对 url.params 进行 URL 编码并将其设置为正文。默认情况下未设置。
request.body
编辑可选的 HTTP POST 正文。配置值必须是一个对象,它将被编码为 JSON。这只在 request.method 为 POST 时有效。默认为 null(无 HTTP 正文)。
- type: httpjson
request.method: POST
request.body:
query:
bool:
filter:
term:
type: authentication
request.timeout
编辑声明 HTTP 客户端连接超时之前的持续时间。有效的时单位是 ns、us、ms、s、m、h。默认值:30s。
request.ssl
编辑这指定了 SSL/TLS 配置。如果缺少 ssl 部分,则 HTTPS 连接将使用主机 CA。有关更多信息,请参阅 SSL。
request.proxy_url
编辑这以 http[s]://<user>:<password>@<server name/ip>:<port> 的形式指定代理配置。
filebeat.inputs: # Fetch your public IP every minute. - type: httpjson interval: 1m request.url: https://api.ipify.org/?format=json request.proxy_url: http://proxy.example:8080
request.keep_alive.disable
编辑此选项指定是否禁用 HTTP 端点的 keep-alive 功能。默认值:true。
request.keep_alive.max_idle_connections
编辑所有主机上的空闲连接最大数量。零表示无限制。默认值:0。
request.keep_alive.max_idle_connections_per_host
编辑每个主机保持的空闲连接最大数量。如果为零,则默认为二。默认值:0。
request.keep_alive.idle_connection_timeout
编辑空闲连接在关闭自身之前保持空闲的最大时间。有效的时间单位是 ns、us、ms、s、m、h。零表示无限制。默认值:0s。
request.retry.max_attempts
编辑HTTP 客户端最大重试次数。默认值:5。
request.retry.wait_min
编辑尝试重试之前等待的最小时间。默认值:1s。
request.retry.wait_max
编辑尝试重试之前等待的最大时间。默认值:60s。
request.redirect.forward_headers
编辑设置为 true 时,重定向时会转发请求头。默认值:false。
request.redirect.headers_ban_list
编辑当 redirect.forward_headers 设置为 true 时,将转发此列表中未定义的所有标头。默认值:[]。
request.redirect.max_redirects
编辑请求最多可以跟随的重定向次数。默认值:10。
request.rate_limit.limit
编辑指定总限制的响应值。它使用 Go 模板值定义。可以读取以下状态:[.last_response.header]
request.rate_limit.remaining
编辑指定速率限制剩余配额的响应值。它使用 Go 模板值定义。可以读取以下状态:[.last_response.header] 如果响应中缺少 remaining 标头,则不会发生速率限制。
request.rate_limit.reset
编辑指定速率限制将重置的纪元时间的响应值。它使用 Go 模板值定义。可以读取以下状态:[.last_response.header]
request.rate_limit.early_limit
编辑可以选择在响应中指定的值之前开始速率限制。
在默认行为下,当 remaining 值非零时,请求将继续。指定 early_limit 将意味着在达到 0 之前就会发生速率限制。
- 如果
early_limit的指定值小于1,则该值将被视为响应提供的limit的百分比。例如,指定0.9意味着请求将持续到达到速率限制的 90%——对于limit值为120,当remaining达到12时,速率限制开始。如果响应中缺少limit标头,则将发生默认速率限制(当remaining达到0时)。 - 如果
early_limit的指定值大于或等于1,则该值将被视为remaining的目标值。例如,速率限制不是在remaining达到0时发生,而是在remaining达到指定值时发生。
默认情况下未设置此值(默认情况下,遵循响应中指定的速率限制)。
request.transforms
编辑每次执行前应用于请求的转换列表。
可用于请求的转换:[append、delete、set]。
可以读取以下状态:[.first_response.*、.last_response.*、.parent_last_response.* .last_event.*、.cursor.*、.header.*、.url.*、.body.*]。
可以将状态写入:[body.*、header.*、url.*]。
filebeat.inputs:
- type: httpjson
request.url: https://127.0.0.1:9200/_search?scroll=5m
request.method: POST
request.transforms:
- set:
target: body.from
value: '[[now (parseDuration "-1h")]]'
.parent_last_response. 子句仅应在链步骤内以及根请求级别存在分页时使用。如果根级别不存在分页,请使用 .first_response. 子句从链中访问父响应对象。您可以查看下面的示例以更好地了解。
示例配置
filebeat.inputs:
- type: httpjson
enabled: true
id: my-httpjson-id
request.url: http://xyz.com/services/data/v1.0/export_ids/page
request.method: POST
interval: 1h
request.retry.max_attempts: 2
request.retry.wait_min: 5s
request.transforms:
- set:
target: body.page
value: 0
response.request_body_on_pagination: true
response.pagination:
- set:
target: body.page
value: '[[ .last_response.body.page ]]'
fail_on_template_error: true
do_not_log_failure: true
chain:
- step:
request.url: http://xyz.com/services/data/v1.0/$.exportId/export_ids/$.files[:].id/info
request.method: POST
request.transforms:
- set:
target: body.exportId
value: '[[ .parent_last_response.body.exportId ]]'
replace: $.files[:].id
replace_with: '$.exportId,.parent_last_response.body.exportId'
在这里,我们可以看到链步骤仅使用 .parent_last_response.body.exportId 是因为父(根)请求中存在 response.pagination。但是,如果父(根)请求中不存在 response.pagination,则 replace_with 子句应该使用 .first_response.body.exportId。这是因为当父级不存在分页时,出于性能原因,parent_last_response 对象不会填充所需的值,但 first_response 对象始终存储进程链中的第一个响应。
first_response 对象目前只能存储扁平的 JSON 结构(即不支持根级别具有数组的 JSON、NDJSON 或 Gzip 压缩的 JSON),因此它应该仅在满足此条件的情况下使用。不能对 first_response 执行拆分操作。需要通过在 httpjson 配置中将标志 response.save_first_response 设置为 true 来显式启用它。
request.tracer.enable
编辑可以将 HTTP 请求和响应记录到本地文件系统以调试配置。通过将 request.tracer.enabled 设置为 true 并设置 request.tracer.filename 值来启用此选项。其他选项可用于调整日志轮转行为。要删除现有日志,请将 request.tracer.enabled 设置为 false,而无需取消设置文件名选项。
启用此选项会影响安全性,应仅用于调试。
request.tracer.filename
编辑为了区分从不同输入实例生成的跟踪文件,可以在文件名中添加占位符 *,它将被替换为输入实例 ID。例如,http-request-trace-*.ndjson。
request.tracer.maxsize
编辑此值设置日志文件在轮转之前将达到的最大大小(以兆字节为单位)。默认情况下,日志允许达到 1MB 才会轮转。
request.tracer.maxage
编辑这指定保留轮转日志文件的日期数。如果未设置,则无限期保留日志文件。
request.tracer.maxbackups
编辑要保留的旧日志数量。如果未设置,则所有旧日志都将根据 request.tracer.maxage 设置进行保留。
request.tracer.localtime
编辑是否使用主机的本地时间而不是 UTC 来为轮转日志文件名加时间戳。
request.tracer.compress
编辑这决定是否应压缩轮转的日志。
response.decode_as
编辑用于解码响应正文的 ContentType。如果设置了此选项,它将强制以指定的格式进行解码,而不管 Content-Type 标头值如何,否则如果可能,它将遵循此值,或回退到 application/json。支持的值:application/json, application/x-ndjson、text/csv、application/zip、application/xml 和 text/xml。默认情况下未设置。
对于 text/csv,将为每一行创建一个事件,使用标头值作为对象键。因此,总是假设存在标头。
对于 application/zip,zip 文件应包含一个或多个 .json 或 .ndjson 文件。所有文件的内容都将合并到单个 JSON 对象列表中。
对于 application/xml 和 text/xml,可以通过 response.xsd 选项提供用于解码 XML 文档的类型信息。
response.xsd
编辑XML 文档可能需要其他类型信息才能启用正确的解析和提取。可以使用 response.xsd 选项为文档提供 XML 架构定义 (XSD) 作为此信息。
response.transforms
编辑接收响应后应用于响应的转换列表。
可用于响应的转换:[append、delete、set]。
可以读取以下状态:[.last_response.*、.last_event.*、.cursor.*、.header.*、.url.*]。
可以将状态写入:[body.*]。
filebeat.inputs:
- type: httpjson
request.url: https://127.0.0.1:9200/_search?scroll=5m
request.method: POST
response.transforms:
- delete:
target: body.very_confidential
response.split:
target: body.hits.hits
response.pagination:
- set:
target: url.value
value: https://127.0.0.1:9200/_search/scroll
- set:
target: url.params.scroll_id
value: '[[.last_response.body._scroll_id]]'
- set:
target: body.scroll
value: 5m
response.split
编辑应用于接收响应后的拆分操作。拆分可以将映射、数组或字符串转换为多个事件。如果拆分目标为空,则将保留父文档。如果应删除具有空拆分的文档,则应将 ignore_empty_value 选项设置为 true。
response.split[].target
编辑定义将执行拆分操作的目标字段。
response.split[].type
编辑定义目标的字段类型。允许的值:array、map、string。string 需要使用 delimiter 选项来指定要拆分字符串的字符。delimiter 的行为始终如同 keep_parent 设置为 true。默认值:array。
response.split[].transforms
编辑可以定义一组转换。此列表将在 response.transforms 之后以及根据 response.split[].keep_parent 和 response.split[].key_field 修改对象之后应用。
可用于响应的转换:[append、delete、set]。
可以读取以下状态:[.last_response.*、.first_event.*、.last_event.*、.cursor.*、.header.*、.url.*]。
可以将状态写入:[body.*]。
在此上下文中,body.* 将是所有先前转换的结果。
response.split[].keep_parent
编辑如果设置为 true,则将保留父文档中的字段(与 target 相同级别)。否则,将使用 target 作为根创建一个新文档。默认值:false。
response.split[].delimiter
编辑如果使用 string 的 split 类型,则需要此参数。这是用于分割字符串的子字符串。例如,如果 delimiter 为 "\n",字符串为 "line 1\nline 2",则分割结果为 "line 1" 和 "line 2"。
response.split[].key_field
编辑在与 type: map 一起使用时有效。如果非空,则定义一个新字段,用于存储原始键值。
response.split[].ignore_empty_value
编辑如果设置为 true,则忽略空值或缺失值,并继续处理下一个嵌套的 split 操作,而不是报错。默认值:false。
请注意,如果 ignore_empty_value 为 true 且最终结果为空,则不会发布任何事件,也不会进行游标更新。如果必须对所有响应进行游标更新,则应将其设置为 false,并且必须将摄取管道配置为容忍空事件集。
response.split[].split
编辑嵌套 split 操作。split 操作可以随意嵌套。只有应用最深层的 split 操作后,才会创建事件。
response.request_body_on_pagination
编辑如果设置为 true,则在分页请求中发送 request.body 中的值。默认值:false。
response.pagination
编辑将应用于响应以响应每个新页面请求的转换列表。将执行 request.transform 中的所有转换,然后添加 response.pagination 以根据需要修改下一个请求。对于后续响应,通常会执行 response.transforms 和 response.split。
可用的分页转换:[append,delete,set]。
可以读取以下状态:[.last_response.*,.first_event.*,.last_event.*,.cursor.*,.header.*,.url.*,.body.*]。
可以将状态写入:[body.*、header.*、url.*]。
使用 split 的示例
-
我们有一个包含两个嵌套数组的响应,我们希望为内部数组的每个元素创建一个文档。
{ "this": "is kept", "alerts": [ { "this_is": "also kept", "entities": [ { "something": "something" }, { "else": "else" } ] }, { "this_is": "also kept 2", "entities": [ { "something": "something 2" }, { "else": "else 2" } ] } ] }配置如下所示
filebeat.inputs: - type: httpjson interval: 1m request.url: https://example.com response.split: target: body.alerts type: array keep_parent: true split: # paths in nested splits need to represent the state of body, not only their current level of nesting target: body.alerts.entities type: array keep_parent: true这将输出
[ { "this": "is kept", "alerts": { "this_is": "also kept", "entities": { "something": "something" } } }, { "this": "is kept", "alerts": { "this_is": "also kept", "entities": { "else": "else" } } }, { "this": "is kept", "alerts": { "this_is": "also kept 2", "entities": { "something": "something 2" } } }, { "this": "is kept", "alerts": { "this_is": "also kept 2", "entities": { "else": "else 2" } } } ] -
我们有一个包含两个对象的数组的响应,我们希望为每个对象的键创建一个文档,同时保留键值。
{ "this": "is not kept", "alerts": [ { "this_is": "kept", "entities": { "id1": { "something": "something" } } }, { "this_is": "kept 2", "entities": { "id2": { "something": "something 2" } } } ] }配置如下所示
filebeat.inputs: - type: httpjson interval: 1m request.url: https://example.com response.split: target: body.alerts type: array keep_parent: false split: # this time alerts will not exist because previous keep_parent is false target: body.entities type: map keep_parent: true key_field: id这将输出
[ { "this_is": "kept", "entities": { "id": "id1", "something": "something" } }, { "this_is": "kept 2", "entities": { "id": "id2", "something": "something 2" } } ] -
我们有一个包含两个对象的数组的响应,我们希望为每个对象的键创建一个文档,同时对每个键应用转换。
{ "this": "is not kept", "alerts": [ { "this_is": "also not kept", "entities": { "id1": { "something": "something" } } }, { "this_is": "also not kept", "entities": { "id2": { "something": "something 2" } } } ] }配置如下所示
filebeat.inputs: - type: httpjson interval: 1m request.url: https://example.com response.split: target: body.alerts type: array split: transforms: - set: target: body.new value: will be added to each target: body.entities type: map这将输出
[ { "something": "something", "new": "will be added for each" }, { "something": "something 2", "new": "will be added for each" } ] -
我们有一个键的值为字符串的响应。我们希望根据分隔符分割字符串,并为每个子字符串创建一个文档。
{ "this": "is kept", "lines": "Line 1\nLine 2\nLine 3" }配置如下所示
filebeat.inputs: - type: httpjson interval: 1m request.url: https://example.com response.split: target: body.lines type: string delimiter: "\n"这将输出
[ { "this": "is kept", "lines": "Line 1" }, { "this": "is kept", "lines": "Line 2" }, { "this": "is kept", "lines": "Line 3" } ]
chain
编辑链是一系列在第一个请求之后要发出的请求。
chain[].step
编辑包含链式调用的基本请求和响应配置。
chain[].step.request
编辑参见 请求参数。必需。
示例
第一次调用:https://example.com/services/data/v1.0/
第二次调用:https://example.com/services/data/v1.0/1/export_ids
第三次调用:https://example.com/services/data/v1.0/export_ids/file_1/info
chain[].step.response.split
编辑+
chain[].step.replace
编辑用于从先前链式步骤中收集的响应 JSON 中解析值的 JSONPath 字符串。将相同的替换字符串放在应放置先前调用中收集的值的 URL 中。必需。
示例
filebeat.inputs:
- type: httpjson
enabled: true
# first call
request.url: https://example.com/services/data/v1.0/records
interval: 1h
chain:
# second call
- step:
request.url: https://example.com/services/data/v1.0/$.records[:].id/export_ids
request.method: GET
replace: $.records[:].id
# third call
- step:
request.url: https://example.com/services/data/v1.0/export_ids/$.file_name/info
request.method: GET
replace: $.file_name
示例
-
第一次调用以收集记录 ID
request_url:https://example.com/services/data/v1.0/records
response_json
{ "records": [ { "id": 1, }, { "id": 2, }, { "id": 3, }, ] } -
第二次调用使用从第一次调用中收集的 ID 来收集
file_name。使用 ID 为 *1* 的 request_url:https://example.com/services/data/v1.0/1/export_ids
使用 ID 为 *1* 的 response_json
{ "file_name": "file_1" }使用 ID 为 *2* 的 request_url:https://example.com/services/data/v1.0/2/export_ids
使用 ID 为 *2* 的 response_json
{ "file_name": "file_2" } -
第三次调用使用从第二次调用中收集的
file_name来收集files。使用 file_name 为 *file_1* 的 request_url:https://example.com/services/data/v1.0/export_ids/file_1/info
使用 file_name 为 *file_2* 的 request_url:https://example.com/services/data/v1.0/export_ids/file_2/info
收集并创建所有调用中 httpjson 支持的任何格式的响应中的事件。
请注意,由于
request.url必须是有效的 URL,如果 API 返回的是标识符(如上例所示)而不是完整的 URL,则无法使用 JSON Path 语法。在这种情况下,要达到预期的结果,可以使用不透明 URI 语法。不透明 URI 具有任意方案和冒号分隔的不透明文本。完成替换后,在替换之前会从 URI 中去除方案和冒号,其余的不透明文本将用作替换目标。在以下示例中,方案为“placeholder”。
filebeat.inputs:
- type: httpjson
enabled: true
# first call
request.url: https://example.com/services/data/v1.0/records
interval: 1h
chain:
# second call
- step:
request.url: placeholder:$.records[:]
request.method: GET
replace: $.records[:]
# third call
- step:
request.url: placeholder:$.file_name
request.method: GET
replace: $.file_name
+
chain[].step.replace_with
编辑replace_with: "pattern,value" 子句用于将 request.url 中定义的固定模式字符串替换为给定的值。固定模式必须具有 $. 前缀,例如:$.xyz。value 可以是硬编码的,也可以从上下文变量中提取,例如 [.last_response.*,.first_response.*,.parent_last_response.*] 等。replace_with 子句可以与 replace 子句结合使用,从而在链式请求的逻辑中提供很大的灵活性。
示例
filebeat.inputs:
- type: httpjson
enabled: true
# first call
request.url: https://example.com/services/data/v1.0/exports
interval: 1h
chain:
# second call
- step:
request.url: https://example.com/services/data/v1.0/$.exportId/files
request.method: GET
replace_with: '$.exportId,.first_response.body.exportId'
示例
-
第一次调用以获取 exportId
request_url:https://example.com/services/data/v1.0/exports
response_json
{ "exportId" : "2212" } -
第二次调用使用从第一次调用中获取的 exportId 来获取
file ids。使用 exportId 为 *2212* 的 request_url:https://example.com/services/data/v1.0/2212/files
使用 exportId 为 *2212* 的 response_json
{ "files": [ { "id": 1, }, { "id": 2, }, { "id": 3, }, ] }这种在 url 中进行目标固定模式替换的行为有助于解决各种用例。
一些有用的要点:-
- 如果希望
value被视为要评估的表达式以从上下文变量中提取数据,则它应该始终具有 单个 .(点)前缀。示例:replace_with: '$.exportId,.first_response.body.exportId'。多于或少于此将使内部处理器将其视为硬编码值,replace_with: '$.exportId,..first_response.body.exportId'(多于一个 .(点)作为前缀)或replace_with:'$.exportId,first_response.body.exportId'(没有 . 点作为前缀) - 不完整的
value 表达式将在处理时导致错误。示例:replace_with: '$.exportId,.first_response.',replace_with: '$.exportId,.last_response.'等。这些表达式不完整,因为它们不会向下评估到可以从上下文变量中提取的有效键。值表达式:.first_response.,在处理时,将产生一个数组[first_response ""],其中要提取的键变为""(空字符串),这在任何上下文变量中都没有定义。
固定模式在其定义中不能包含逗号。字符串替换模式由 replace_with 处理器使用精确字符串匹配进行匹配。first_response 对象目前只能存储扁平的 JSON 结构(即不支持根级别有数组的 JSON、NDJSON 或 Gzipped JSON),因此它应该只用于这种情况。不能对 first_response 执行分割。需要通过在 httpjson 配置中将标志 response.save_first_response 设置为 true 来显式启用它。
chain[].while
编辑包含链式 while 调用的基本请求和响应配置。链式 while 调用将继续发出给定次数的请求,直到满足条件或达到最大尝试次数。While 链具有一个属性 until,它保存要评估的表达式。理想情况下,until 字段应始终与属性 request.retry.max_attempts 和 request.retry.wait_min 一起使用,它们分别指定在放弃之前评估 until 的最大尝试次数和这些请求之间的最大等待时间。如果未指定 request.retry.max_attempts,它将只尝试评估一次表达式,如果失败则放弃。如果未指定 request.retry.wait_min,则默认等待时间将始终为 0,因为将立即进行连续调用。
chain[].while.request
编辑参见 请求参数。
示例
第一次调用:http://example.com/services/data/v1.0/exports
第二次调用:http://example.com/services/data/v1.0/9ef0e6a5/export_ids/status
第三次调用:http://example.com/services/data/v1.0/export_ids/1/info
chain[].while.response.split
编辑chain[].while.replace
编辑示例
filebeat.inputs:
- type: httpjson
enabled: true
# first call
id: my-httpjson-id
request.url: http://example.com/services/data/v1.0/exports
interval: 1h
chain:
# second call
- while:
request.url: http://example.com/services/data/v1.0/$.exportId/export_ids/status
request.method: GET
replace: $.exportId
until: '[[ eq .last_response.body.status "completed" ]]'
request.retry.max_attempts: 5
request.retry.wait_min: 5s
# third call
- step:
request.url: http://example.com/services/data/v1.0/export_ids/$.files[:].id/info
request.method: GET
replace: $.files[:].id
示例
-
第一次调用以收集导出 ID
request_url:https://example.com/services/data/v1.0/exports
response_json
{ "exportId": "9ef0e6a5" } -
当
response.body.sataus == "completed"时,第二次调用使用从第一次调用中收集的 ID 来收集file_ids。此调用将持续进行,直到满足条件或达到最大尝试次数。使用 ID 为 *9ef0e6a5* 的 request_url:https://example.com/services/data/v1.0/9ef0e6a5/export_ids/status
使用 ID 为 *9ef0e6a5* 的 response_json
{ "status": "completed", "files": [ { "id": 1 }, { "id": 2 }, { "id": 3 } ] } -
第三次调用使用从第二次调用中收集的
file_id来收集files。使用 file_id 为 *1* 的 request_url:https://example.com/services/data/v1.0/export_ids/1/info
使用 file_id 为 *2* 的 request_url:https://example.com/services/data/v1.0/export_ids/2/info
使用 ID 为 *1* 的 response_json
{ "file_name": "file_1", "file_data": "some data" }使用 ID 为 *2* 的 response_json
{ "file_name": "file_2", "file_data": "some data" }收集并创建所有调用中 httpjson 支持的任何格式的响应中的事件。
请注意,由于
request.url必须是有效的 URL,如果 API 返回的是标识符(如上例所示)而不是完整的 URL,则无法使用 JSON Path 语法。在这种情况下,要达到预期的结果,可以使用不透明 URI 语法。不透明 URI 具有任意方案和冒号分隔的不透明文本。完成替换后,在替换之前会从 URI 中去除方案和冒号,其余的不透明文本将用作替换目标。在以下示例中,方案为“placeholder”。
filebeat.inputs:
- type: httpjson
enabled: true
# first call
id: my-httpjson-id
request.url: http://example.com/services/data/v1.0/exports
interval: 1h
chain:
# second call
- while:
request.url: placeholder:$.exportId
request.method: GET
replace: $.exportId
until: '[[ eq .last_response.body.status "completed" ]]'
request.retry.max_attempts: 5
request.retry.wait_min: 5s
# third call
- step:
request.url: placeholder:$.files[:]
request.method: GET
replace: $.files[:]
httpjson 链只会从链式配置的最后一次调用创建和摄取事件。此外,当前链只支持以下内容:所有 请求参数、response.transforms 和 response.split。
chain[].while.replace_with
编辑cursor
编辑Cursor 是一个键值对象列表,其中定义了任意值。这些值被解释为 值模板,并且可以设置默认模板。Cursor 状态在输入重启之间保持不变,并在所有针对请求的事件发布后更新。
如果没有发布事件,则不会进行 Cursor 更新。这可能会影响目标 API 返回空响应集时应如何执行 Cursor 更新。
每个 Cursor 条目由以下部分组成:
- 一个
value模板,它将定义评估时要存储的值。 - 一个
default模板,当值模板失败或为空时,它将定义要存储的值。 - 一个
ignore_empty_value标志。当设置为true时,将不存储空值,保留之前的任何值。默认值:true。
可以从以下位置读取状态:[.last_response.*,.first_event.*,.last_event.*]。
默认模板无法访问任何状态,只能访问函数。
filebeat.inputs:
- type: httpjson
interval: 1m
request.url: https://api.ipify.org/?format=json
response.transforms:
- set:
target: body.last_requested_at
value: '[[.cursor.last_requested_at]]'
default: "[[now]]"
cursor:
last_requested_at:
value: '[[now]]'
processors:
- decode_json_fields:
fields: ["message"]
target: "json"
请求生命周期
编辑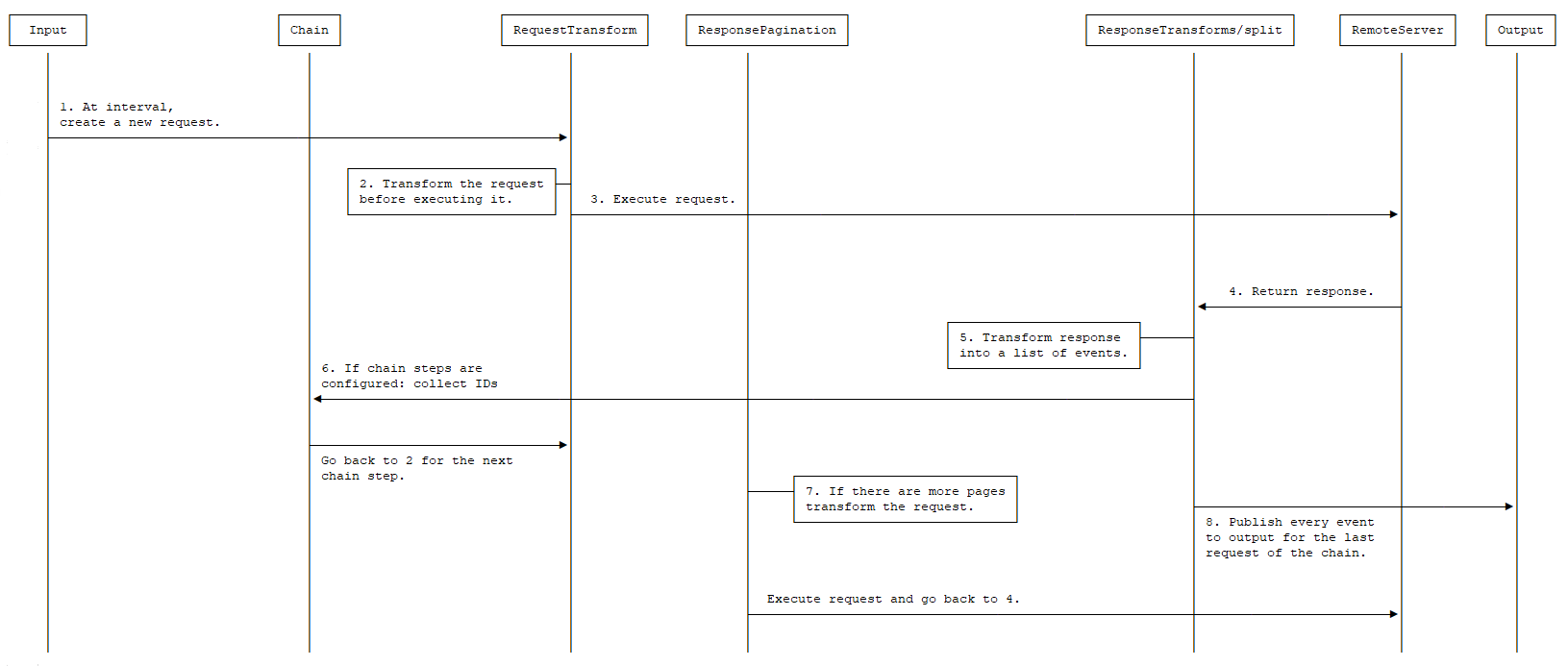
- 在每个定义的间隔内,都会创建一个新的请求。
- 使用配置的 request.transforms 转换请求。
- 执行生成的转换后的请求。
- 服务器响应(在配置时,任何重试或速率限制策略都将在此处发生)。
- 使用配置的 response.transforms 和 response.split 转换响应。
- 如果配置了链步骤。每个步骤将根据从响应中收集的 ID 生成新的请求。这些请求将使用配置的 request.transforms 进行转换,然后执行生成的转换后的请求。此过程将针对链中提到的所有步骤发生。
- 每个生成的事件都会发布到输出。
- 如果配置了
response.pagination并且还有更多页面,则将使用它创建一个新的请求,否则该过程将持续到下一个间隔。
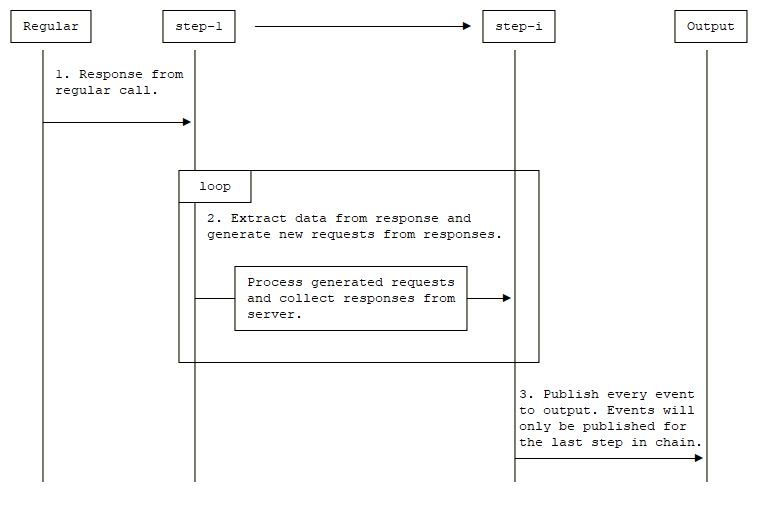
- 将处理来自常规调用的响应。
- 从响应中提取数据并根据响应生成新的请求。
- 处理生成的请求并从服务器收集响应。
- 返回步骤 2,进行下一步。
- 发布从最后一个链步骤收集的响应。
指标
编辑此输入在 HTTP 监控端点 下公开指标。这些指标在 /inputs 路径下公开。它们可以用于观察输入的活动。
| 指标 | 描述 |
|---|---|
|
已处理请求的总数。 |
|
请求错误的总数。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
请求正文大小的总和。 |
|
请求正文大小的直方图。 |
|
收到的响应总数。 |
|
响应错误的总数。 |
|
|
|
|
|
|
|
|
|
|
|
响应正文大小的总和。 |
|
响应正文大小的直方图。 |
|
往返时间的直方图。 |
|
已执行的间隔总数。 |
|
间隔错误的总数。 |
|
间隔执行时间的直方图。 |
|
每个间隔的总页面数的直方图。 |
|
间隔页面执行时间的直方图。 |
通用选项
编辑所有输入都支持以下配置选项。
enabled
编辑使用 enabled 选项启用和禁用输入。默认情况下,enabled 设置为 true。
tags
编辑Filebeat 在每个发布事件的 tags 字段中包含的一系列标签。标签使在 Kibana 中选择特定事件或在 Logstash 中应用条件过滤变得容易。这些标签将附加到在常规配置中指定的标签列表中。
示例
filebeat.inputs: - type: httpjson . . . tags: ["json"]
fields
编辑您可以指定的可选字段,以向输出添加其他信息。例如,您可以添加可用于过滤日志数据的字段。字段可以是标量值、数组、字典或这些的任何嵌套组合。默认情况下,您在此处指定的字段将在输出文档中的 fields 子字典下分组。要将自定义字段存储为顶级字段,请将 fields_under_root 选项设置为 true。如果在常规配置中声明了重复字段,则其值将被此处声明的值覆盖。
filebeat.inputs:
- type: httpjson
. . .
fields:
app_id: query_engine_12
fields_under_root
编辑如果将此选项设置为 true,则自定义 fields 将存储为输出文档中的顶级字段,而不是分组在 fields 子字典下。如果自定义字段名称与 Filebeat 添加的其他字段名称冲突,则自定义字段会覆盖其他字段。
processors
编辑要应用于输入数据的处理器列表。
有关在配置中指定处理器的信息,请参见 处理器。
pipeline
编辑为此输入生成的事件设置的摄取管道 ID。
也可以在 Elasticsearch 输出中配置管道 ID,但这通常会导致更简单的配置文件。如果在输入和输出中都配置了管道,则使用输入中的选项。
keep_null
编辑如果将此选项设置为 true,则输出文档中将发布具有 null 值的字段。默认情况下,keep_null 设置为 false。
index
编辑如果存在,此格式化字符串将覆盖此输入的事件索引(对于 elasticsearch 输出),或设置事件元数据的 raw_index 字段(对于其他输出)。此字符串只能引用代理名称和版本以及事件时间戳;要访问动态字段,请使用 output.elasticsearch.index 或处理器。
示例值:"%{[agent.name]}-myindex-%{+yyyy.MM.dd}" 可能会扩展为 "filebeat-myindex-2019.11.01"。
publisher_pipeline.disable_host
编辑默认情况下,所有事件都包含 host.name。此选项可以设置为 true 以禁用将此字段添加到所有事件中。默认值为 false。