ES|QL 命令
编辑ES|QL 命令
编辑
处理命令
编辑ES|QL 处理命令通过添加、删除或更改行和列来更改输入表。

ES|QL 支持以下处理命令
FROM
编辑FROM 源命令返回一个表,其中包含来自数据流、索引或别名的数据。
语法
FROM index_pattern [METADATA fields]
参数
-
index_pattern - 索引、数据流或别名的列表。支持通配符和日期数学。
-
fields - 要检索的 元数据字段 的逗号分隔列表。
描述
FROM 源命令返回一个表,其中包含来自数据流、索引或别名的数据。结果表中的每一行都表示一个文档。每一列对应一个字段,可以通过该字段的名称访问。
默认情况下,没有显式 LIMIT 的 ES|QL 查询使用隐式限制 1000。这也适用于 FROM。没有 LIMIT 的 FROM 命令
FROM employees
将执行为
FROM employees | LIMIT 1000
示例
FROM employees
您可以使用 日期数学 来引用索引、别名和数据流。这对于时间序列数据很有用,例如访问今天的索引
FROM <logs-{now/d}>
使用逗号分隔列表或通配符来 查询多个数据流、索引或别名
FROM employees-00001,other-employees-*
使用格式 <remote_cluster_name>:<target> 来 查询远程集群上的数据流和索引
FROM cluster_one:employees-00001,cluster_two:other-employees-*
使用可选的 METADATA 指令来启用 元数据字段
FROM employees METADATA _id
使用包含的双引号 (") 或三个包含的双引号 (""") 来转义包含特殊字符的索引名称
FROM "this=that", """this[that"""
ROW
编辑ROW 源命令生成一行,其中包含一个或多个具有您指定值的列。这对于测试很有用。
语法
ROW column1 = value1[, ..., columnN = valueN]
参数
-
columnX - 列名。如果列名重复,则只有最右边的重复项创建列。
-
valueX - 列的值。可以是文字、表达式或 函数。
示例
ROW a = 1, b = "two", c = null
| a:integer | b:keyword | c:null |
|---|---|---|
1 |
"two" |
null |
使用方括号创建多值列
ROW a = [2, 1]
ROW 支持使用 函数
ROW a = ROUND(1.23, 0)
SHOW
编辑SHOW 源命令返回有关部署及其功能的信息。
语法
SHOW item
参数
-
item - 只能是
INFO。
示例
使用 SHOW INFO 返回部署的版本、构建日期和哈希值。
SHOW INFO
| version | date | hash |
|---|---|---|
8.13.0 |
2024-02-23T10:04:18.123117961Z |
04ba8c8db2507501c88f215e475de7b0798cb3b3 |
DISSECT
编辑DISSECT 使您能够 从字符串中提取结构化数据。
语法
DISSECT input "pattern" [APPEND_SEPARATOR="<separator>"]
参数
描述
DISSECT 使您能够 从字符串中提取结构化数据。 DISSECT 将字符串与基于分隔符的模式匹配,并将指定的键提取为列。
有关分解模式语法的参考,请参阅 使用 DISSECT 处理数据。
示例
以下示例解析包含时间戳、一些文本和 IP 地址的字符串
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a """%{date} - %{msg} - %{ip}"""
| KEEP date, msg, ip
| date:keyword | msg:keyword | ip:keyword |
|---|---|---|
2023-01-23T12:15:00.000Z |
some text |
127.0.0.1 |
默认情况下,DISSECT 输出关键字字符串列。要转换为其他类型,请使用 类型转换函数
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a """%{date} - %{msg} - %{ip}"""
| KEEP date, msg, ip
| EVAL date = TO_DATETIME(date)
| msg:keyword | ip:keyword | date:date |
|---|---|---|
some text |
127.0.0.1 |
2023-01-23T12:15:00.000Z |
DROP
编辑DROP 处理命令删除一个或多个列。
语法
DROP columns
参数
-
columns - 要删除的列的逗号分隔列表。支持通配符。
示例
FROM employees | DROP height
您可以使用通配符删除名称与模式匹配的所有列,而不是按名称指定每个列
FROM employees | DROP height*
ENRICH
编辑ENRICH 使您能够使用丰富策略将来自现有索引的数据作为新列添加。
语法
ENRICH policy [ON match_field] [WITH [new_name1 = ]field1, [new_name2 = ]field2, ...]
参数
-
policy - 丰富策略的名称。您需要先 创建 和 执行 丰富策略。
-
mode - 跨集群 ES|QL 中丰富命令的模式。请参阅 跨集群丰富。
-
match_field - 匹配字段。
ENRICH使用其值在丰富索引中查找记录。如果未指定,则匹配将在与 丰富策略 中定义的match_field名称相同的列上执行。 -
fieldX - 来自丰富索引的丰富字段,作为新列添加到结果中。如果与丰富字段名称相同的列已存在,则现有列将被新列替换。如果未指定,则添加策略中定义的每个丰富字段。除非重命名丰富字段,否则名称与丰富字段相同的列将被删除。
-
new_nameX - 使您能够更改为每个丰富字段添加的列的名称。默认为丰富字段名称。如果某列与新名称同名,则该列将被丢弃。如果名称(新名称或原始名称)出现多次,则只有最右边的重复项创建新列。
描述
ENRICH 使您能够使用丰富策略将来自现有索引的数据作为新列添加。有关设置策略的信息,请参阅 数据丰富。
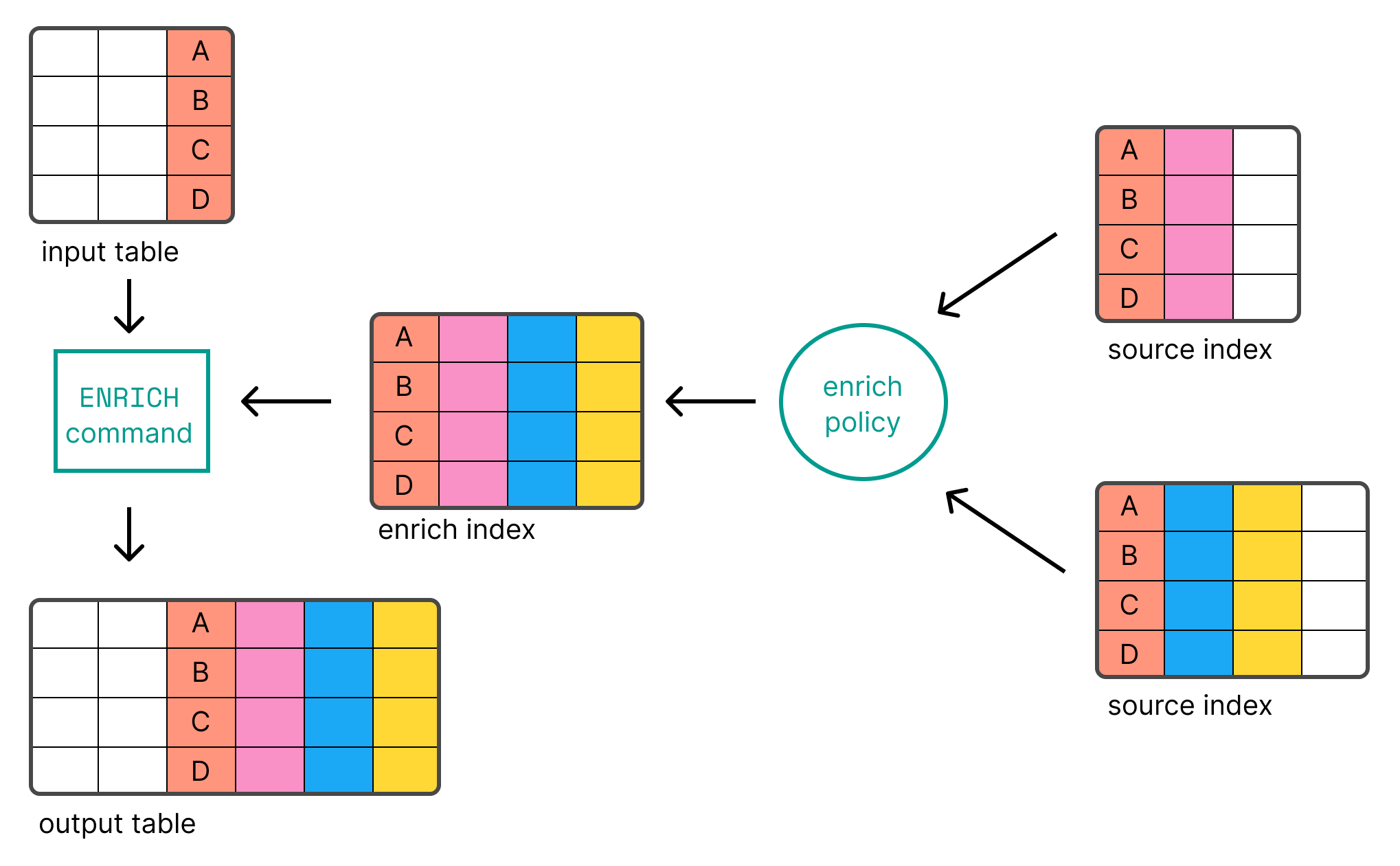
在使用 ENRICH 之前,您需要 创建并执行丰富策略。
示例
以下示例使用 languages_policy 丰富策略为策略中定义的每个丰富字段添加新列。匹配使用 丰富策略 中定义的 match_field 执行,并要求输入表具有相同名称的列(在本例中为 language_code)。 ENRICH 将根据匹配字段值在 丰富索引 中查找记录。
ROW language_code = "1" | ENRICH languages_policy
| language_code:keyword | language_name:keyword |
|---|---|
1 |
English |
要使用与策略中定义的 match_field 不同的名称的列作为匹配字段,请使用 ON <column-name>
ROW a = "1" | ENRICH languages_policy ON a
| a:keyword | language_name:keyword |
|---|---|
1 |
English |
默认情况下,策略中定义的每个丰富字段都作为列添加。要显式选择添加的丰富字段,请使用 WITH <field1>, <field2>, ...
ROW a = "1" | ENRICH languages_policy ON a WITH language_name
| a:keyword | language_name:keyword |
|---|---|
1 |
English |
您可以使用 WITH new_name=<field1> 重命名添加的列
ROW a = "1" | ENRICH languages_policy ON a WITH name = language_name
| a:keyword | name:keyword |
|---|---|
1 |
English |
如果发生名称冲突,则新创建的列将覆盖现有列。
EVAL
编辑EVAL 处理命令使您能够使用计算值追加新列。
语法
EVAL [column1 =] value1[, ..., [columnN =] valueN]
参数
-
columnX - 列名。如果已存在同名的列,则删除现有列。如果列名重复使用多次,则只有最右边的重复项会创建列。
-
valueX - 列的值。可以是字面量、表达式或函数。可以使用在此列左侧定义的列。
描述
EVAL 处理命令使您能够使用计算值追加新列。EVAL 支持各种用于计算值的函数。有关更多信息,请参阅函数。
示例
FROM employees | SORT emp_no | KEEP first_name, last_name, height | EVAL height_feet = height * 3.281, height_cm = height * 100
| first_name:keyword | last_name:keyword | height:double | height_feet:double | height_cm:double |
|---|---|---|---|---|
Georgi |
Facello |
2.03 |
6.66043 |
202.99999999999997 |
Bezalel |
Simmel |
2.08 |
6.82448 |
208.0 |
Parto |
Bamford |
1.83 |
6.004230000000001 |
183.0 |
如果指定的列已存在,则将删除现有列,并将新列追加到表中
FROM employees | SORT emp_no | KEEP first_name, last_name, height | EVAL height = height * 3.281
| first_name:keyword | last_name:keyword | height:double |
|---|---|---|
Georgi |
Facello |
6.66043 |
Bezalel |
Simmel |
6.82448 |
Parto |
Bamford |
6.004230000000001 |
指定输出列名是可选的。如果未指定,则新列名等于表达式。以下查询添加了一个名为height*3.281的列
FROM employees | SORT emp_no | KEEP first_name, last_name, height | EVAL height * 3.281
| first_name:keyword | last_name:keyword | height:double | height * 3.281:double |
|---|---|---|---|
Georgi |
Facello |
2.03 |
6.66043 |
Bezalel |
Simmel |
2.08 |
6.82448 |
Parto |
Bamford |
1.83 |
6.004230000000001 |
由于此名称包含特殊字符,因此在后续命令中使用它时,需要使用反引号(`)将其括起来
FROM employees | EVAL height * 3.281 | STATS avg_height_feet = AVG(`height * 3.281`)
| avg_height_feet:double |
|---|
5.801464200000001 |
GROK
编辑GROK 使您能够从字符串中提取结构化数据。
语法
GROK input "pattern"
参数
-
input - 包含要结构化的字符串的列。如果该列有多个值,则
GROK将处理每个值。 -
pattern - Grok 模式。如果字段名称与现有列冲突,则丢弃现有列。如果字段名称重复使用多次,则将创建一个多值列,每个字段名称的每次出现对应一个值。
描述
GROK 使您能够从字符串中提取结构化数据。GROK 根据正则表达式将字符串与模式匹配,并将指定的模式提取为列。
有关 Grok 模式的语法,请参阅GROK 处理数据。
示例
以下示例解析包含时间戳、IP 地址、电子邮件地址和数字的字符串
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 [email protected] 42" | GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num}""" | KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:keyword |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
默认情况下,GROK 输出关键字字符串列。int 和 float 类型可以通过在模式中的语义后附加 :type 来转换。例如 {NUMBER:num:int}
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 [email protected] 42" | GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}""" | KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:integer |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
对于其他类型转换,请使用类型转换函数
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 [email protected] 42" | GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}""" | KEEP date, ip, email, num | EVAL date = TO_DATETIME(date)
| ip:keyword | email:keyword | num:integer | date:date |
|---|---|---|---|
127.0.0.1 |
42 |
2023-01-23T12:15:00.000Z |
如果字段名称重复使用多次,则 GROK 会创建一个多值列
FROM addresses
| KEEP city.name, zip_code
| GROK zip_code """%{WORD:zip_parts} %{WORD:zip_parts}"""
| city.name:keyword | zip_code:keyword | zip_parts:keyword |
|---|---|---|
Amsterdam |
1016 ED |
["1016", "ED"] |
San Francisco |
CA 94108 |
["CA", "94108"] |
Tokyo |
100-7014 |
null |
KEEP
编辑KEEP 处理命令使您能够指定返回哪些列以及返回它们的顺序。
语法
KEEP columns
参数
-
columns - 要保留的列的逗号分隔列表。支持通配符。请参见下文了解现有列与多个给定通配符或列名匹配时的行为。
描述
KEEP 处理命令使您能够指定返回哪些列以及返回它们的顺序。
当字段名称与多个表达式匹配时,将应用优先级规则。字段将按照它们出现的顺序添加。如果一个字段匹配多个表达式,则将应用以下优先级规则(从最高到最低):
- 完整字段名称(无通配符)
- 部分通配符表达式(例如:
fieldNam*) - 仅通配符(
*)
如果一个字段匹配两个具有相同优先级的表达式,则最右边的表达式获胜。
请参阅示例以了解这些优先级规则的说明。
示例
列将按照指定的顺序返回
FROM employees | KEEP emp_no, first_name, last_name, height
| emp_no:integer | first_name:keyword | last_name:keyword | height:double |
|---|---|---|---|
10001 |
Georgi |
Facello |
2.03 |
10002 |
Bezalel |
Simmel |
2.08 |
10003 |
Parto |
Bamford |
1.83 |
10004 |
Chirstian |
Koblick |
1.78 |
10005 |
Kyoichi |
Maliniak |
2.05 |
您可以使用通配符返回所有名称与模式匹配的列,而不是按名称指定每个列
FROM employees | KEEP h*
| height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date |
|---|
星号通配符(*) 本身转换为不匹配其他参数的所有列。
此查询将首先返回所有名称以 h 开头的列,然后返回所有其他列
FROM employees | KEEP h*, *
| height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date | avg_worked_seconds:long | birth_date:date | emp_no:integer | first_name:keyword | gender:keyword | is_rehired:boolean | job_positions:keyword | languages:integer | languages.byte:integer | languages.long:long | languages.short:integer | last_name:keyword | salary:integer | salary_change:double | salary_change.int:integer | salary_change.keyword:keyword | salary_change.long:long | still_hired:boolean |
|---|
以下示例显示了当字段名称与多个表达式匹配时优先级规则是如何工作的。
完整字段名称优先于通配符表达式
FROM employees | KEEP first_name, last_name, first_name*
| first_name:keyword | last_name:keyword |
|---|
通配符表达式具有相同的优先级,但最后一个表达式获胜(尽管不太具体)
FROM employees | KEEP first_name*, last_name, first_na*
| last_name:keyword | first_name:keyword |
|---|
简单的通配符表达式*优先级最低。输出顺序由其他参数决定
FROM employees | KEEP *, first_name
| avg_worked_seconds:long | birth_date:date | emp_no:integer | gender:keyword | height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date | is_rehired:boolean | job_positions:keyword | languages:integer | languages.byte:integer | languages.long:long | languages.short:integer | last_name:keyword | salary:integer | salary_change:double | salary_change.int:integer | salary_change.keyword:keyword | salary_change.long:long | still_hired:boolean | first_name:keyword |
|---|
LIMIT
编辑LIMIT 处理命令使您能够限制返回的行数。
语法
LIMIT max_number_of_rows
参数
-
max_number_of_rows - 要返回的最大行数。
描述
LIMIT 处理命令使您能够限制返回的行数。无论 LIMIT 命令的值是多少,查询都不会返回超过 10,000 行。
此限制仅适用于查询检索到的行数。查询和聚合在完整的数据集上运行。
要克服此限制
- 通过修改查询以仅返回相关数据来减小结果集大小。使用
WHERE选择较小的数据子集。 - 将任何查询后处理转移到查询本身。您可以使用 ES|QL
STATS ... BY命令在查询中聚合数据。
可以使用以下动态集群设置更改默认限制和最大限制
-
esql.query.result_truncation_default_size -
esql.query.result_truncation_max_size
示例
FROM employees | SORT emp_no ASC | LIMIT 5
MV_EXPAND
编辑此功能处于技术预览阶段,可能会在将来的版本中更改或删除。Elastic 将致力于修复任何问题,但技术预览中的功能不受官方 GA 功能的支持 SLA 的约束。
MV_EXPAND 处理命令将多值列扩展为每个值一行,并复制其他列。
语法
MV_EXPAND column
参数
-
column - 要扩展的多值列。
示例
ROW a=[1,2,3], b="b", j=["a","b"] | MV_EXPAND a
| a:integer | b:keyword | j:keyword |
|---|---|---|
1 |
b |
["a", "b"] |
2 |
b |
["a", "b"] |
3 |
b |
["a", "b"] |
RENAME
编辑RENAME 处理命令重命名一个或多个列。
语法
RENAME old_name1 AS new_name1[, ..., old_nameN AS new_nameN]
参数
-
old_nameX - 要重命名的列的名称。
-
new_nameX - 列的新名称。如果它与现有列名冲突,则删除现有列。如果多个列重命名为相同的名称,则除了最右边的具有相同新名称的列之外,所有其他列都将被删除。
描述
RENAME 处理命令重命名一个或多个列。如果已存在具有新名称的列,则它将被新列替换。
示例
FROM employees | KEEP first_name, last_name, still_hired | RENAME still_hired AS employed
可以使用单个 RENAME 命令重命名多个列
FROM employees | KEEP first_name, last_name | RENAME first_name AS fn, last_name AS ln
SORT
编辑SORT 处理命令根据一个或多个列对表进行排序。
语法
SORT column1 [ASC/DESC][NULLS FIRST/NULLS LAST][, ..., columnN [ASC/DESC][NULLS FIRST/NULLS LAST]]
参数
-
columnX - 要排序的列。
描述
SORT 处理命令根据一个或多个列对表进行排序。
默认排序顺序为升序。使用 ASC 或 DESC 指定显式排序顺序。
具有相同排序键的两行被视为相等。您可以提供其他排序表达式作为决胜符。
对多值列进行排序时,在升序排序时使用最低值,在降序排序时使用最高值。
默认情况下,null 值被视为大于任何其他值。在升序排序中,null 值排序在最后,在降序排序中,null 值排序在最前。您可以通过提供 NULLS FIRST 或 NULLS LAST 来更改它。
示例
FROM employees | KEEP first_name, last_name, height | SORT height
使用 ASC 显式地按升序排序
FROM employees | KEEP first_name, last_name, height | SORT height DESC
提供其他排序表达式作为决胜符
FROM employees | KEEP first_name, last_name, height | SORT height DESC, first_name ASC
使用 NULLS FIRST 将 null 值排序在最前
FROM employees | KEEP first_name, last_name, height | SORT first_name ASC NULLS FIRST
STATS ... BY
编辑STATS ... BY 处理命令根据公共值对行进行分组,并在分组的行上计算一个或多个聚合值。
语法
STATS [column1 =] expression1[, ..., [columnN =] expressionN] [BY grouping_expression1[, ..., grouping_expressionN]]
参数
-
columnX - 返回聚合值的名称。如果省略,则名称等于相应的表达式(
expressionX)。如果多个列具有相同的名称,则除了最右边的具有此名称的列之外,所有其他列都将被忽略。 -
expressionX - 计算聚合值的表达式。
-
grouping_expressionX - 输出要分组的值的表达式。如果其名称与计算列之一重合,则将忽略该列。
计算聚合时,将跳过各个 null 值。
描述
STATS ... BY 处理命令根据公共值对行进行分组,并在分组的行上计算一个或多个聚合值。如果省略 BY,则输出表将只包含一行,其中包含应用于整个数据集的聚合。
支持以下聚合函数
-
AVG -
COUNT -
COUNT_DISTINCT -
MAX -
MEDIAN -
MEDIAN_ABSOLUTE_DEVIATION -
MIN -
PERCENTILE -
[预览] 此功能处于技术预览阶段,可能会在将来的版本中更改或删除。Elastic 将致力于修复任何问题,但技术预览中的功能不受官方 GA 功能的支持 SLA 的约束。
ST_CENTROID_AGG -
SUM -
TOP -
VALUES -
[预览] 此功能处于技术预览阶段,可能会在将来的版本中更改或删除。Elastic 将致力于修复任何问题,但技术预览版的功能不受官方 GA 功能的支持 SLA 的约束。
WEIGHTED_AVG
支持以下分组函数
STATS 在没有任何分组的情况下,比添加分组要快得多。
对单个表达式的分组目前比对多个表达式的分组优化得多。在一些测试中,我们发现对单个keyword列进行分组的速度是 对两个keyword列进行分组速度的五倍。不要尝试使用类似CONCAT的方法将两列组合在一起,然后进行分组来解决此问题 - 这样做不会更快。
示例
计算统计信息并按另一列的值进行分组
FROM employees | STATS count = COUNT(emp_no) BY languages | SORT languages
| count:long | languages:integer |
|---|---|
15 |
1 |
19 |
2 |
17 |
3 |
18 |
4 |
21 |
5 |
10 |
null |
省略BY将返回一行,其中包含应用于整个数据集的聚合结果
FROM employees | STATS avg_lang = AVG(languages)
| avg_lang:double |
|---|
3.1222222222222222 |
可以计算多个值
FROM employees | STATS avg_lang = AVG(languages), max_lang = MAX(languages)
| avg_lang:double | max_lang:integer |
|---|---|
3.1222222222222222 |
5 |
ROW i=1, a=["a", "b"] | STATS MIN(i) BY a | SORT a ASC
| MIN(i):integer | a:keyword |
|---|---|
1 |
a |
1 |
b |
也可以按多个值进行分组
FROM employees
| EVAL hired = DATE_FORMAT("yyyy", hire_date)
| STATS avg_salary = AVG(salary) BY hired, languages.long
| EVAL avg_salary = ROUND(avg_salary)
| SORT hired, languages.long
如果所有分组键都是多值,则输入行位于所有组中
ROW i=1, a=["a", "b"], b=[2, 3] | STATS MIN(i) BY a, b | SORT a ASC, b ASC
| MIN(i):integer | a:keyword | b:integer |
|---|---|---|
1 |
a |
2 |
1 |
a |
3 |
1 |
b |
2 |
1 |
b |
3 |
聚合函数和分组表达式都接受其他函数。这对于在多值列上使用STATS...BY很有用。例如,要计算平均工资变化,可以使用MV_AVG先对每个员工的多个值求平均值,然后使用结果与AVG函数一起使用
FROM employees | STATS avg_salary_change = ROUND(AVG(MV_AVG(salary_change)), 10)
| avg_salary_change:double |
|---|
1.3904535865 |
按表达式分组的一个示例是按员工姓氏的首字母对员工进行分组
FROM employees | STATS my_count = COUNT() BY LEFT(last_name, 1) | SORT `LEFT(last_name, 1)`
| my_count:long | LEFT(last_name, 1):keyword |
|---|---|
2 |
A |
11 |
B |
5 |
C |
5 |
D |
2 |
E |
4 |
F |
4 |
G |
6 |
H |
2 |
J |
3 |
K |
5 |
L |
12 |
M |
4 |
N |
1 |
O |
7 |
P |
5 |
R |
13 |
S |
4 |
T |
2 |
W |
3 |
Z |
指定输出列名是可选的。如果未指定,则新列名等于表达式。以下查询返回名为AVG(salary)的列
FROM employees | STATS AVG(salary)
| AVG(salary):double |
|---|
48248.55 |
由于此名称包含特殊字符,因此在后续命令中使用它时,需要使用反引号(`)将其括起来
FROM employees | STATS AVG(salary) | EVAL avg_salary_rounded = ROUND(`AVG(salary)`)
| AVG(salary):double | avg_salary_rounded:double |
|---|---|
48248.55 |
48249.0 |
WHERE
编辑WHERE处理命令生成一个表,该表包含输入表中所有满足提供的条件(结果为true)的行。
语法
WHERE expression
参数
-
expression - 布尔表达式。
示例
FROM employees | KEEP first_name, last_name, still_hired | WHERE still_hired == true
如果still_hired是布尔字段,则可以简化为
FROM employees | KEEP first_name, last_name, still_hired | WHERE still_hired
使用日期数学从特定时间范围检索数据。例如,要检索最近一小时的日志
FROM sample_data | WHERE @timestamp > NOW() - 1 hour
FROM employees | KEEP first_name, last_name, height | WHERE LENGTH(first_name) < 4
有关所有函数的完整列表,请参阅函数概述。
对于 NULL 比较,使用IS NULL和IS NOT NULL谓词
FROM employees | WHERE birth_date IS NULL | KEEP first_name, last_name | SORT first_name | LIMIT 3
| first_name:keyword | last_name:keyword |
|---|---|
Basil |
Tramer |
Florian |
Syrotiuk |
Lucien |
Rosenbaum |
FROM employees | WHERE is_rehired IS NOT NULL | STATS COUNT(emp_no)
| COUNT(emp_no):long |
|---|
84 |
使用LIKE根据使用通配符的字符串模式过滤数据。LIKE通常作用于放在运算符左侧的字段,但它也可以作用于常量(文字)表达式。运算符的右侧表示模式。
支持以下通配符
-
*匹配零个或多个字符。 -
?匹配一个字符。
支持的类型
| str | pattern | result |
|---|---|---|
keyword |
keyword |
boolean |
text |
text |
boolean |
FROM employees | WHERE first_name LIKE """?b*""" | KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
Ebbe |
Callaway |
Eberhardt |
Terkki |
匹配确切的字符*和.需要转义。转义字符是反斜杠\。由于反斜杠也是字符串文字中的特殊字符,因此需要进一步转义。
ROW message = "foo * bar" | WHERE message LIKE "foo \\* bar"
为了减少转义的开销,我们建议使用三引号字符串"""
ROW message = "foo * bar" | WHERE message LIKE """foo \* bar"""
使用RLIKE根据使用正则表达式的字符串模式过滤数据。RLIKE通常作用于放在运算符左侧的字段,但它也可以作用于常量(文字)表达式。运算符的右侧表示模式。
支持的类型
| str | pattern | result |
|---|---|---|
keyword |
keyword |
boolean |
text |
text |
boolean |
FROM employees | WHERE first_name RLIKE """.leja.*""" | KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
Alejandro |
McAlpine |
匹配特殊字符(例如.、*、(…)需要转义。转义字符是反斜杠\。由于反斜杠也是字符串文字中的特殊字符,因此需要进一步转义。
ROW message = "foo ( bar" | WHERE message RLIKE "foo \\( bar"
为了减少转义的开销,我们建议使用三引号字符串"""
ROW message = "foo ( bar" | WHERE message RLIKE """foo \( bar"""
IN运算符允许测试字段或表达式是否等于文字、字段或表达式列表中的元素
ROW a = 1, b = 4, c = 3 | WHERE c-a IN (3, b / 2, a)
| a:integer | b:integer | c:integer |
|---|---|---|
1 |
4 |
3 |
有关所有运算符的完整列表,请参阅运算符。