摄取管道
编辑摄取管道
编辑摄取管道允许您在索引数据之前对其执行常见的转换操作。例如,您可以使用管道删除字段、从文本中提取值以及丰富您的数据。
管道由一系列称为处理器的可配置任务组成。每个处理器依次运行,对传入的文档进行特定更改。处理器运行完成后,Elasticsearch 会将转换后的文档添加到您的数据流或索引中。

您可以使用 Kibana 的摄取管道功能或摄取 API创建和管理摄取管道。Elasticsearch 将管道存储在集群状态中。
先决条件
编辑创建和管理管道
编辑在 Kibana 中,打开主菜单并点击堆栈管理 > 摄取管道。在列表视图中,您可以
- 查看管道列表并深入了解详细信息
- 编辑或克隆现有管道
- 删除管道

要创建管道,请点击创建管道 > 新建管道。有关示例教程,请参阅示例:解析日志。
从 CSV 创建管道选项允许您使用 CSV 创建一个摄取管道,该管道将自定义数据映射到Elastic 通用架构 (ECS)。将您的自定义数据映射到 ECS 使数据更易于搜索,并允许您重用来自其他数据集的可视化效果。要开始使用,请查看将自定义数据映射到 ECS。
您还可以使用摄取 API创建和管理管道。以下创建管道 API请求创建了一个管道,其中包含两个set处理器,然后是一个lowercase处理器。处理器按指定的顺序依次运行。
resp = client.ingest.put_pipeline(
id="my-pipeline",
description="My optional pipeline description",
processors=[
{
"set": {
"description": "My optional processor description",
"field": "my-long-field",
"value": 10
}
},
{
"set": {
"description": "Set 'my-boolean-field' to true",
"field": "my-boolean-field",
"value": True
}
},
{
"lowercase": {
"field": "my-keyword-field"
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
description: 'My optional pipeline description',
processors: [
{
set: {
description: 'My optional processor description',
field: 'my-long-field',
value: 10
}
},
{
set: {
description: "Set 'my-boolean-field' to true",
field: 'my-boolean-field',
value: true
}
},
{
lowercase: {
field: 'my-keyword-field'
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
description: "My optional pipeline description",
processors: [
{
set: {
description: "My optional processor description",
field: "my-long-field",
value: 10,
},
},
{
set: {
description: "Set 'my-boolean-field' to true",
field: "my-boolean-field",
value: true,
},
},
{
lowercase: {
field: "my-keyword-field",
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"description": "My optional pipeline description",
"processors": [
{
"set": {
"description": "My optional processor description",
"field": "my-long-field",
"value": 10
}
},
{
"set": {
"description": "Set 'my-boolean-field' to true",
"field": "my-boolean-field",
"value": true
}
},
{
"lowercase": {
"field": "my-keyword-field"
}
}
]
}
管理管道版本
编辑创建或更新管道时,您可以指定一个可选的version整数。您可以将此版本号与if_version参数一起使用来有条件地更新管道。当指定if_version参数时,成功的更新会递增管道的版本。
PUT _ingest/pipeline/my-pipeline-id
{
"version": 1,
"processors": [ ... ]
}
要使用 API 取消设置version编号,请在不指定version参数的情况下替换或更新管道。
测试管道
编辑在生产环境中使用管道之前,我们建议您使用示例文档对其进行测试。在 Kibana 中创建或编辑管道时,请点击添加文档。在文档选项卡中,提供示例文档并点击运行管道。
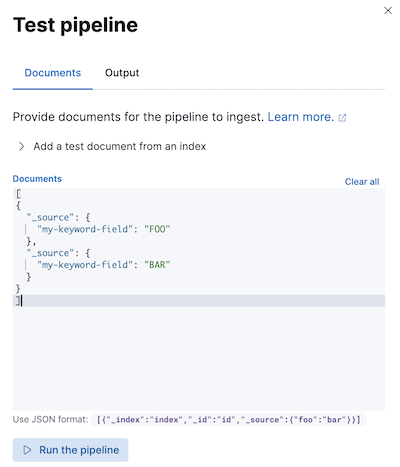
您还可以使用模拟管道 API测试管道。您可以在请求路径中指定一个已配置的管道。例如,以下请求测试my-pipeline。
resp = client.ingest.simulate(
id="my-pipeline",
docs=[
{
"_source": {
"my-keyword-field": "FOO"
}
},
{
"_source": {
"my-keyword-field": "BAR"
}
}
],
)
print(resp)
response = client.ingest.simulate(
id: 'my-pipeline',
body: {
docs: [
{
_source: {
"my-keyword-field": 'FOO'
}
},
{
_source: {
"my-keyword-field": 'BAR'
}
}
]
}
)
puts response
const response = await client.ingest.simulate({
id: "my-pipeline",
docs: [
{
_source: {
"my-keyword-field": "FOO",
},
},
{
_source: {
"my-keyword-field": "BAR",
},
},
],
});
console.log(response);
POST _ingest/pipeline/my-pipeline/_simulate
{
"docs": [
{
"_source": {
"my-keyword-field": "FOO"
}
},
{
"_source": {
"my-keyword-field": "BAR"
}
}
]
}
或者,您可以在请求正文中指定管道及其处理器。
resp = client.ingest.simulate(
pipeline={
"processors": [
{
"lowercase": {
"field": "my-keyword-field"
}
}
]
},
docs=[
{
"_source": {
"my-keyword-field": "FOO"
}
},
{
"_source": {
"my-keyword-field": "BAR"
}
}
],
)
print(resp)
response = client.ingest.simulate(
body: {
pipeline: {
processors: [
{
lowercase: {
field: 'my-keyword-field'
}
}
]
},
docs: [
{
_source: {
"my-keyword-field": 'FOO'
}
},
{
_source: {
"my-keyword-field": 'BAR'
}
}
]
}
)
puts response
const response = await client.ingest.simulate({
pipeline: {
processors: [
{
lowercase: {
field: "my-keyword-field",
},
},
],
},
docs: [
{
_source: {
"my-keyword-field": "FOO",
},
},
{
_source: {
"my-keyword-field": "BAR",
},
},
],
});
console.log(response);
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"lowercase": {
"field": "my-keyword-field"
}
}
]
},
"docs": [
{
"_source": {
"my-keyword-field": "FOO"
}
},
{
"_source": {
"my-keyword-field": "BAR"
}
}
]
}
API 返回转换后的文档
{
"docs": [
{
"doc": {
"_index": "_index",
"_id": "_id",
"_version": "-3",
"_source": {
"my-keyword-field": "foo"
},
"_ingest": {
"timestamp": "2099-03-07T11:04:03.000Z"
}
}
},
{
"doc": {
"_index": "_index",
"_id": "_id",
"_version": "-3",
"_source": {
"my-keyword-field": "bar"
},
"_ingest": {
"timestamp": "2099-03-07T11:04:04.000Z"
}
}
}
]
}
将管道添加到索引请求
编辑使用pipeline查询参数将管道应用于单个或批量索引请求中的文档。
resp = client.index(
index="my-data-stream",
pipeline="my-pipeline",
document={
"@timestamp": "2099-03-07T11:04:05.000Z",
"my-keyword-field": "foo"
},
)
print(resp)
resp1 = client.bulk(
index="my-data-stream",
pipeline="my-pipeline",
operations=[
{
"create": {}
},
{
"@timestamp": "2099-03-07T11:04:06.000Z",
"my-keyword-field": "foo"
},
{
"create": {}
},
{
"@timestamp": "2099-03-07T11:04:07.000Z",
"my-keyword-field": "bar"
}
],
)
print(resp1)
response = client.index(
index: 'my-data-stream',
pipeline: 'my-pipeline',
body: {
"@timestamp": '2099-03-07T11:04:05.000Z',
"my-keyword-field": 'foo'
}
)
puts response
response = client.bulk(
index: 'my-data-stream',
pipeline: 'my-pipeline',
body: [
{
create: {}
},
{
"@timestamp": '2099-03-07T11:04:06.000Z',
"my-keyword-field": 'foo'
},
{
create: {}
},
{
"@timestamp": '2099-03-07T11:04:07.000Z',
"my-keyword-field": 'bar'
}
]
)
puts response
const response = await client.index({
index: "my-data-stream",
pipeline: "my-pipeline",
document: {
"@timestamp": "2099-03-07T11:04:05.000Z",
"my-keyword-field": "foo",
},
});
console.log(response);
const response1 = await client.bulk({
index: "my-data-stream",
pipeline: "my-pipeline",
operations: [
{
create: {},
},
{
"@timestamp": "2099-03-07T11:04:06.000Z",
"my-keyword-field": "foo",
},
{
create: {},
},
{
"@timestamp": "2099-03-07T11:04:07.000Z",
"my-keyword-field": "bar",
},
],
});
console.log(response1);
POST my-data-stream/_doc?pipeline=my-pipeline
{
"@timestamp": "2099-03-07T11:04:05.000Z",
"my-keyword-field": "foo"
}
PUT my-data-stream/_bulk?pipeline=my-pipeline
{ "create":{ } }
{ "@timestamp": "2099-03-07T11:04:06.000Z", "my-keyword-field": "foo" }
{ "create":{ } }
{ "@timestamp": "2099-03-07T11:04:07.000Z", "my-keyword-field": "bar" }
您还可以将pipeline参数与按查询更新或重新索引 API 一起使用。
resp = client.update_by_query(
index="my-data-stream",
pipeline="my-pipeline",
)
print(resp)
resp1 = client.reindex(
source={
"index": "my-data-stream"
},
dest={
"index": "my-new-data-stream",
"op_type": "create",
"pipeline": "my-pipeline"
},
)
print(resp1)
response = client.update_by_query(
index: 'my-data-stream',
pipeline: 'my-pipeline'
)
puts response
response = client.reindex(
body: {
source: {
index: 'my-data-stream'
},
dest: {
index: 'my-new-data-stream',
op_type: 'create',
pipeline: 'my-pipeline'
}
}
)
puts response
const response = await client.updateByQuery({
index: "my-data-stream",
pipeline: "my-pipeline",
});
console.log(response);
const response1 = await client.reindex({
source: {
index: "my-data-stream",
},
dest: {
index: "my-new-data-stream",
op_type: "create",
pipeline: "my-pipeline",
},
});
console.log(response1);
POST my-data-stream/_update_by_query?pipeline=my-pipeline
POST _reindex
{
"source": {
"index": "my-data-stream"
},
"dest": {
"index": "my-new-data-stream",
"op_type": "create",
"pipeline": "my-pipeline"
}
}
设置默认管道
编辑使用index.default_pipeline索引设置来设置默认管道。如果未指定pipeline参数,Elasticsearch 会将此管道应用于索引请求。
设置最终管道
编辑使用index.final_pipeline索引设置来设置最终管道。Elasticsearch 会在请求或默认管道之后应用此管道,即使两者均未指定。
Beats 的管道
编辑要将摄取管道添加到 Elastic Beat,请在<BEAT_NAME>.yml中的output.elasticsearch下指定pipeline参数。例如,对于 Filebeat,您将在filebeat.yml中指定pipeline。
output.elasticsearch: hosts: ["localhost:9200"] pipeline: my-pipeline
Fleet 和 Elastic Agent 的管道
编辑Elastic Agent 集成附带默认的摄取管道,这些管道在索引之前预处理和丰富数据。Fleet 使用包含管道索引设置的索引模板应用这些管道。Elasticsearch 根据流的命名方案将这些模板与您的 Fleet 数据流匹配。
每个默认集成管道都会调用一个不存在的、未版本化的*@custom摄取管道。如果未更改,此管道调用对您的数据没有影响。但是,您可以修改此调用以创建跨升级持续存在的集成自定义管道。请参阅教程:使用自定义摄取管道转换数据以了解更多信息。
Fleet 不会为自定义日志集成提供默认的摄取管道,但您可以使用索引模板或自定义配置为此集成指定管道。
-
创建并测试您的摄取管道。将您的管道命名为
logs-<dataset-name>-default。这使得跟踪集成管道变得更容易。例如,以下请求为
my-app数据集创建了一个管道。管道的名称为logs-my_app-default。PUT _ingest/pipeline/logs-my_app-default { "description": "Pipeline for `my_app` dataset", "processors": [ ... ] } -
创建一个索引模板,该模板在
index.default_pipeline或index.final_pipeline索引设置中包含您的管道。确保模板启用了数据流。模板的索引模式应与logs-<dataset-name>-*匹配。您可以使用 Kibana 的索引管理功能或创建索引模板 API创建此模板。
例如,以下请求创建了一个与
logs-my_app-*匹配的模板。该模板使用一个组件模板,其中包含index.default_pipeline索引设置。resp = client.cluster.put_component_template( name="logs-my_app-settings", template={ "settings": { "index.default_pipeline": "logs-my_app-default", "index.lifecycle.name": "logs" } }, ) print(resp) resp1 = client.indices.put_index_template( name="logs-my_app-template", index_patterns=[ "logs-my_app-*" ], data_stream={}, priority=500, composed_of=[ "logs-my_app-settings", "logs-my_app-mappings" ], ) print(resp1)const response = await client.cluster.putComponentTemplate({ name: "logs-my_app-settings", template: { settings: { "index.default_pipeline": "logs-my_app-default", "index.lifecycle.name": "logs", }, }, }); console.log(response); const response1 = await client.indices.putIndexTemplate({ name: "logs-my_app-template", index_patterns: ["logs-my_app-*"], data_stream: {}, priority: 500, composed_of: ["logs-my_app-settings", "logs-my_app-mappings"], }); console.log(response1);# Creates a component template for index settings PUT _component_template/logs-my_app-settings { "template": { "settings": { "index.default_pipeline": "logs-my_app-default", "index.lifecycle.name": "logs" } } } # Creates an index template matching `logs-my_app-*` PUT _index_template/logs-my_app-template { "index_patterns": ["logs-my_app-*"], "data_stream": { }, "priority": 500, "composed_of": ["logs-my_app-settings", "logs-my_app-mappings"] } - 在 Fleet 中添加或编辑您的自定义日志集成时,请点击配置集成 > 自定义日志文件 > 高级选项。
-
在数据集名称中,指定数据集的名称。Fleet 会将集成的新的数据添加到生成的
logs-<dataset-name>-default数据流中。例如,如果您的数据集名称为
my_app,则 Fleet 会将新的数据添加到logs-my_app-default数据流中。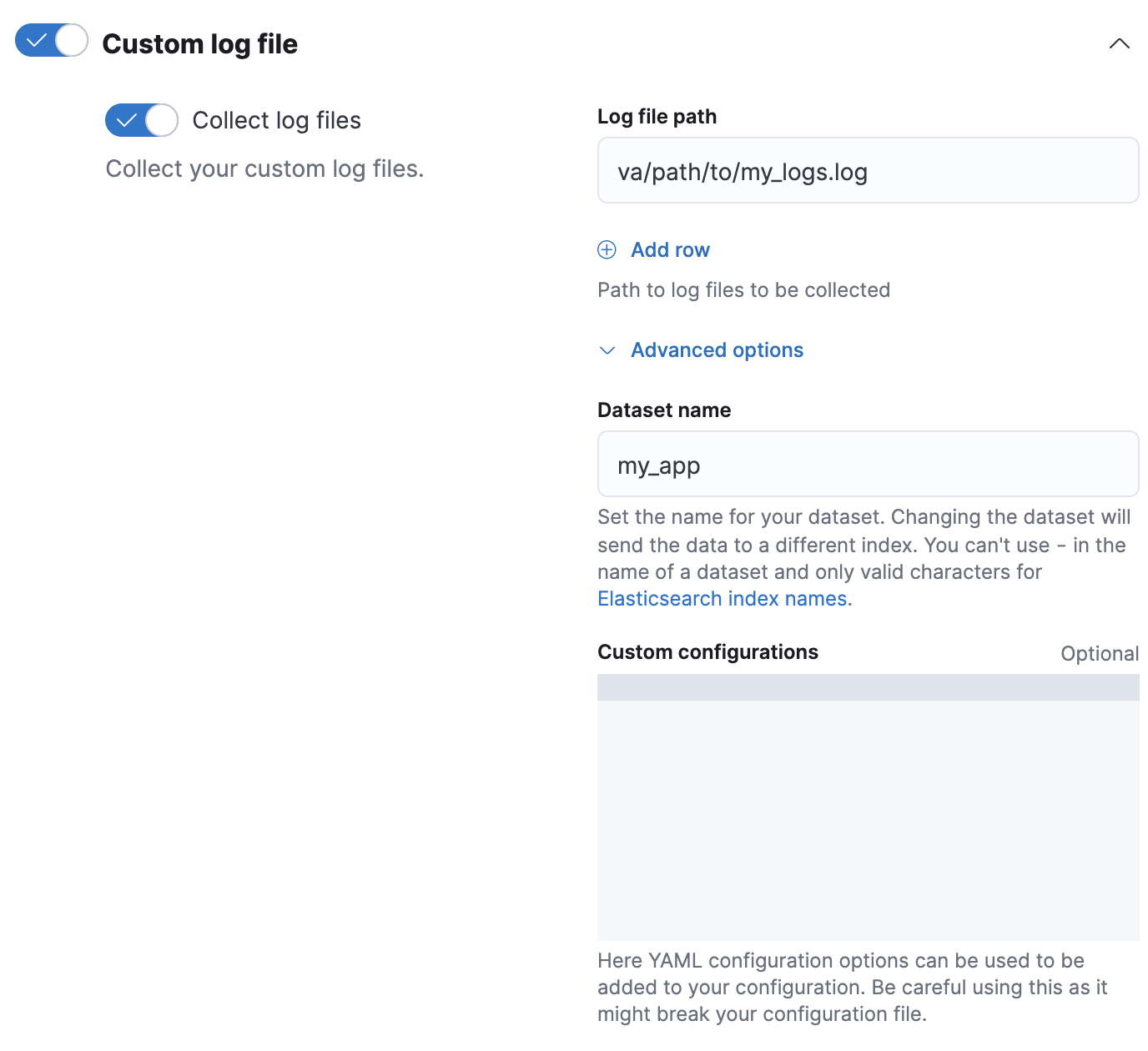
-
使用滚动 API滚动您的数据流。这可确保 Elasticsearch 将索引模板及其管道设置应用于集成的任何新数据。
resp = client.indices.rollover( alias="logs-my_app-default", ) print(resp)response = client.indices.rollover( alias: 'logs-my_app-default' ) puts response
const response = await client.indices.rollover({ alias: "logs-my_app-default", }); console.log(response);POST logs-my_app-default/_rollover/
-
创建并测试您的摄取管道。将您的管道命名为
logs-<dataset-name>-default。这使得跟踪集成管道变得更容易。例如,以下请求为
my-app数据集创建了一个管道。管道的名称为logs-my_app-default。PUT _ingest/pipeline/logs-my_app-default { "description": "Pipeline for `my_app` dataset", "processors": [ ... ] } - 在 Fleet 中添加或编辑您的自定义日志集成时,请点击配置集成 > 自定义日志文件 > 高级选项。
-
在数据集名称中,指定数据集的名称。Fleet 会将集成的新的数据添加到生成的
logs-<dataset-name>-default数据流中。例如,如果您的数据集名称为
my_app,则 Fleet 会将新的数据添加到logs-my_app-default数据流中。 -
在自定义配置中,在
pipeline策略设置中指定您的管道。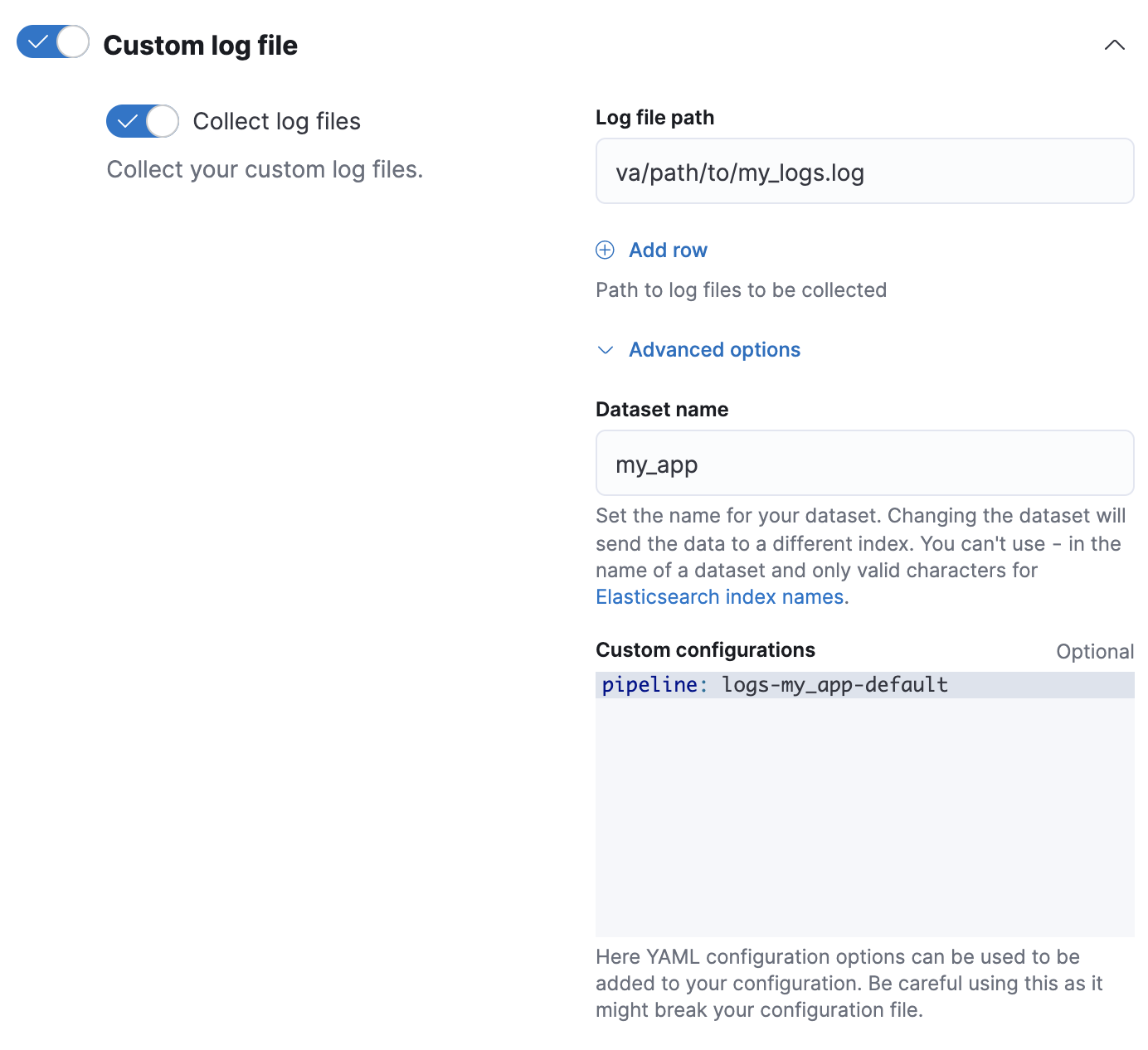
Elastic Agent 独立版
如果您运行 Elastic Agent 独立版,则可以使用包含index.default_pipeline或index.final_pipeline索引设置的索引模板应用管道。或者,您可以在elastic-agent.yml配置中指定pipeline策略设置。请参阅安装独立 Elastic Agent。
搜索索引的管道
编辑当您为搜索用例创建 Elasticsearch 索引时,例如,使用Web 爬虫或连接器,这些索引会自动设置特定的摄取管道。这些处理器有助于优化您的内容以进行搜索。请参阅搜索中的摄取管道以获取更多信息。
在处理器中访问源字段
编辑处理器具有对传入文档的源字段的读写访问权限。要在处理器中访问字段键,请使用其字段名称。以下set处理器访问my-long-field。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"set": {
"field": "my-long-field",
"value": 10
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
set: {
field: 'my-long-field',
value: 10
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
set: {
field: "my-long-field",
value: 10,
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"field": "my-long-field",
"value": 10
}
}
]
}
您也可以添加_source前缀。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"set": {
"field": "_source.my-long-field",
"value": 10
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
set: {
field: '_source.my-long-field',
value: 10
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
set: {
field: "_source.my-long-field",
value: 10,
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"field": "_source.my-long-field",
"value": 10
}
}
]
}
使用点表示法访问对象字段。
如果您的文档包含扁平化的对象,请使用dot_expander处理器先展开它们。其他摄取处理器无法访问扁平化的对象。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"dot_expander": {
"description": "Expand 'my-object-field.my-property'",
"field": "my-object-field.my-property"
}
},
{
"set": {
"description": "Set 'my-object-field.my-property' to 10",
"field": "my-object-field.my-property",
"value": 10
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
dot_expander: {
description: "Expand 'my-object-field.my-property'",
field: 'my-object-field.my-property'
}
},
{
set: {
description: "Set 'my-object-field.my-property' to 10",
field: 'my-object-field.my-property',
value: 10
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
dot_expander: {
description: "Expand 'my-object-field.my-property'",
field: "my-object-field.my-property",
},
},
{
set: {
description: "Set 'my-object-field.my-property' to 10",
field: "my-object-field.my-property",
value: 10,
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"dot_expander": {
"description": "Expand 'my-object-field.my-property'",
"field": "my-object-field.my-property"
}
},
{
"set": {
"description": "Set 'my-object-field.my-property' to 10",
"field": "my-object-field.my-property",
"value": 10
}
}
]
}
一些处理器参数支持Mustache模板片段。要在模板片段中访问字段值,请将字段名称括在三个花括号中:{{{field-name}}}。您可以使用模板片段动态设置字段名称。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"set": {
"description": "Set dynamic '<service>' field to 'code' value",
"field": "{{{service}}}",
"value": "{{{code}}}"
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
set: {
description: "Set dynamic '<service>' field to 'code' value",
field: '{{{service}}}',
value: '{{{code}}}'
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
set: {
description: "Set dynamic '<service>' field to 'code' value",
field: "{{{service}}}",
value: "{{{code}}}",
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"description": "Set dynamic '<service>' field to 'code' value",
"field": "{{{service}}}",
"value": "{{{code}}}"
}
}
]
}
在处理器中访问元数据字段
编辑处理器可以通过名称访问以下元数据字段
-
_index -
_id -
_routing -
_dynamic_templates
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"set": {
"description": "Set '_routing' to 'geoip.country_iso_code' value",
"field": "_routing",
"value": "{{{geoip.country_iso_code}}}"
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
set: {
description: "Set '_routing' to 'geoip.country_iso_code' value",
field: '_routing',
value: '{{{geoip.country_iso_code}}}'
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
set: {
description: "Set '_routing' to 'geoip.country_iso_code' value",
field: "_routing",
value: "{{{geoip.country_iso_code}}}",
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"description": "Set '_routing' to 'geoip.country_iso_code' value",
"field": "_routing",
"value": "{{{geoip.country_iso_code}}}"
}
}
]
}
使用 Mustache 模板片段访问元数据字段值。例如,{{{_routing}}} 检索文档的路由值。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"set": {
"description": "Use geo_point dynamic template for address field",
"field": "_dynamic_templates",
"value": {
"address": "geo_point"
}
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
set: {
description: 'Use geo_point dynamic template for address field',
field: '_dynamic_templates',
value: {
address: 'geo_point'
}
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
set: {
description: "Use geo_point dynamic template for address field",
field: "_dynamic_templates",
value: {
address: "geo_point",
},
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"description": "Use geo_point dynamic template for address field",
"field": "_dynamic_templates",
"value": {
"address": "geo_point"
}
}
}
]
}
上面的 set 处理器告诉 ES,如果字段 address 尚未在索引的映射中定义,则对该字段使用名为 geo_point 的动态模板。如果在批量请求中已定义了该字段的动态模板,则此处理器会覆盖 address 字段的动态模板,但对批量请求中定义的其他动态模板没有影响。
如果自动生成 文档 ID,则不能在处理器中使用 {{{_id}}}。Elasticsearch 在摄取后分配自动生成的 _id 值。
在处理器中访问摄取元数据
编辑摄取处理器可以使用 _ingest 键添加和访问摄取元数据。
与源字段和元数据字段不同,Elasticsearch 默认不会索引摄取元数据字段。Elasticsearch 也允许源字段以 _ingest 键开头。如果您的数据包含此类源字段,请使用 _source._ingest 访问它们。
默认情况下,管道仅创建 _ingest.timestamp 摄取元数据字段。此字段包含 Elasticsearch 接收文档索引请求的时间戳。要索引 _ingest.timestamp 或其他摄取元数据字段,请使用 set 处理器。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"set": {
"description": "Index the ingest timestamp as 'event.ingested'",
"field": "event.ingested",
"value": "{{{_ingest.timestamp}}}"
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
set: {
description: "Index the ingest timestamp as 'event.ingested'",
field: 'event.ingested',
value: '{{{_ingest.timestamp}}}'
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
set: {
description: "Index the ingest timestamp as 'event.ingested'",
field: "event.ingested",
value: "{{{_ingest.timestamp}}}",
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"description": "Index the ingest timestamp as 'event.ingested'",
"field": "event.ingested",
"value": "{{{_ingest.timestamp}}}"
}
}
]
}
处理管道故障
编辑管道的处理器按顺序运行。默认情况下,当其中一个处理器失败或遇到错误时,管道处理将停止。
要忽略处理器故障并运行管道剩余的处理器,请将 ignore_failure 设置为 true。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"rename": {
"description": "Rename 'provider' to 'cloud.provider'",
"field": "provider",
"target_field": "cloud.provider",
"ignore_failure": True
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
rename: {
description: "Rename 'provider' to 'cloud.provider'",
field: 'provider',
target_field: 'cloud.provider',
ignore_failure: true
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
rename: {
description: "Rename 'provider' to 'cloud.provider'",
field: "provider",
target_field: "cloud.provider",
ignore_failure: true,
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"rename": {
"description": "Rename 'provider' to 'cloud.provider'",
"field": "provider",
"target_field": "cloud.provider",
"ignore_failure": true
}
}
]
}
使用 on_failure 参数指定要在处理器失败后立即运行的处理器列表。如果指定了 on_failure,则 Elasticsearch 随后会运行管道剩余的处理器,即使 on_failure 配置为空也是如此。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"rename": {
"description": "Rename 'provider' to 'cloud.provider'",
"field": "provider",
"target_field": "cloud.provider",
"on_failure": [
{
"set": {
"description": "Set 'error.message'",
"field": "error.message",
"value": "Field 'provider' does not exist. Cannot rename to 'cloud.provider'",
"override": False
}
}
]
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
rename: {
description: "Rename 'provider' to 'cloud.provider'",
field: 'provider',
target_field: 'cloud.provider',
on_failure: [
{
set: {
description: "Set 'error.message'",
field: 'error.message',
value: "Field 'provider' does not exist. Cannot rename to 'cloud.provider'",
override: false
}
}
]
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
rename: {
description: "Rename 'provider' to 'cloud.provider'",
field: "provider",
target_field: "cloud.provider",
on_failure: [
{
set: {
description: "Set 'error.message'",
field: "error.message",
value:
"Field 'provider' does not exist. Cannot rename to 'cloud.provider'",
override: false,
},
},
],
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"rename": {
"description": "Rename 'provider' to 'cloud.provider'",
"field": "provider",
"target_field": "cloud.provider",
"on_failure": [
{
"set": {
"description": "Set 'error.message'",
"field": "error.message",
"value": "Field 'provider' does not exist. Cannot rename to 'cloud.provider'",
"override": false
}
}
]
}
}
]
}
嵌套一个 on_failure 处理器列表以进行嵌套错误处理。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"rename": {
"description": "Rename 'provider' to 'cloud.provider'",
"field": "provider",
"target_field": "cloud.provider",
"on_failure": [
{
"set": {
"description": "Set 'error.message'",
"field": "error.message",
"value": "Field 'provider' does not exist. Cannot rename to 'cloud.provider'",
"override": False,
"on_failure": [
{
"set": {
"description": "Set 'error.message.multi'",
"field": "error.message.multi",
"value": "Document encountered multiple ingest errors",
"override": True
}
}
]
}
}
]
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
rename: {
description: "Rename 'provider' to 'cloud.provider'",
field: 'provider',
target_field: 'cloud.provider',
on_failure: [
{
set: {
description: "Set 'error.message'",
field: 'error.message',
value: "Field 'provider' does not exist. Cannot rename to 'cloud.provider'",
override: false,
on_failure: [
{
set: {
description: "Set 'error.message.multi'",
field: 'error.message.multi',
value: 'Document encountered multiple ingest errors',
override: true
}
}
]
}
}
]
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
rename: {
description: "Rename 'provider' to 'cloud.provider'",
field: "provider",
target_field: "cloud.provider",
on_failure: [
{
set: {
description: "Set 'error.message'",
field: "error.message",
value:
"Field 'provider' does not exist. Cannot rename to 'cloud.provider'",
override: false,
on_failure: [
{
set: {
description: "Set 'error.message.multi'",
field: "error.message.multi",
value: "Document encountered multiple ingest errors",
override: true,
},
},
],
},
},
],
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"rename": {
"description": "Rename 'provider' to 'cloud.provider'",
"field": "provider",
"target_field": "cloud.provider",
"on_failure": [
{
"set": {
"description": "Set 'error.message'",
"field": "error.message",
"value": "Field 'provider' does not exist. Cannot rename to 'cloud.provider'",
"override": false,
"on_failure": [
{
"set": {
"description": "Set 'error.message.multi'",
"field": "error.message.multi",
"value": "Document encountered multiple ingest errors",
"override": true
}
}
]
}
}
]
}
}
]
}
您还可以为管道指定 on_failure。如果一个没有 on_failure 值的处理器失败,Elasticsearch 会将此管道级参数用作后备。Elasticsearch 不会尝试运行管道剩余的处理器。
PUT _ingest/pipeline/my-pipeline
{
"processors": [ ... ],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
}
]
}
有关管道故障的其他信息可能在文档元数据字段 on_failure_message、on_failure_processor_type、on_failure_processor_tag 和 on_failure_pipeline 中可用。这些字段只能从 on_failure 块内访问。
以下示例使用元数据字段在文档中包含有关管道故障的信息。
PUT _ingest/pipeline/my-pipeline
{
"processors": [ ... ],
"on_failure": [
{
"set": {
"description": "Record error information",
"field": "error_information",
"value": "Processor {{ _ingest.on_failure_processor_type }} with tag {{ _ingest.on_failure_processor_tag }} in pipeline {{ _ingest.on_failure_pipeline }} failed with message {{ _ingest.on_failure_message }}"
}
}
]
}
有条件地运行处理器
编辑每个处理器都支持一个可选的 if 条件,它写为一个Painless 脚本。如果提供,则只有当 if 条件为 true 时,处理器才会运行。
if 条件脚本在 Painless 的摄取处理器上下文中运行。在 if 条件中,ctx 值是只读的。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"drop": {
"description": "Drop documents with 'network.name' of 'Guest'",
"if": "ctx?.network?.name == 'Guest'"
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
drop: {
description: "Drop documents with 'network.name' of 'Guest'",
if: "ctx?.network?.name == 'Guest'"
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
drop: {
description: "Drop documents with 'network.name' of 'Guest'",
if: "ctx?.network?.name == 'Guest'",
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"drop": {
"description": "Drop documents with 'network.name' of 'Guest'",
"if": "ctx?.network?.name == 'Guest'"
}
}
]
}
如果script.painless.regex.enabled 集群设置已启用,则可以在 if 条件脚本中使用正则表达式。有关支持的语法,请参阅Painless 正则表达式。
如果可能,请避免使用正则表达式。昂贵的正则表达式会降低索引速度。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"set": {
"description": "If 'url.scheme' is 'http', set 'url.insecure' to true",
"if": "ctx.url?.scheme =~ /^http[^s]/",
"field": "url.insecure",
"value": True
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'my-pipeline',
body: {
processors: [
{
set: {
description: "If 'url.scheme' is 'http', set 'url.insecure' to true",
if: 'ctx.url?.scheme =~ /^http[^s]/',
field: 'url.insecure',
value: true
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
set: {
description: "If 'url.scheme' is 'http', set 'url.insecure' to true",
if: "ctx.url?.scheme =~ /^http[^s]/",
field: "url.insecure",
value: true,
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"description": "If 'url.scheme' is 'http', set 'url.insecure' to true",
"if": "ctx.url?.scheme =~ /^http[^s]/",
"field": "url.insecure",
"value": true
}
}
]
}
必须在单行上将 if 条件指定为有效的 JSON。但是,您可以使用Kibana 控制台的三重引号语法来编写和调试更大的脚本。
如果可能,请避免使用复杂或昂贵的 if 条件脚本。昂贵的条件脚本会降低索引速度。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"drop": {
"description": "Drop documents that don't contain 'prod' tag",
"if": "\n Collection tags = ctx.tags;\n if(tags != null){\n for (String tag : tags) {\n if (tag.toLowerCase().contains('prod')) {\n return false;\n }\n }\n }\n return true;\n "
}
}
],
)
print(resp)
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
drop: {
description: "Drop documents that don't contain 'prod' tag",
if: "\n Collection tags = ctx.tags;\n if(tags != null){\n for (String tag : tags) {\n if (tag.toLowerCase().contains('prod')) {\n return false;\n }\n }\n }\n return true;\n ",
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"drop": {
"description": "Drop documents that don't contain 'prod' tag",
"if": """
Collection tags = ctx.tags;
if(tags != null){
for (String tag : tags) {
if (tag.toLowerCase().contains('prod')) {
return false;
}
}
}
return true;
"""
}
}
]
}
您还可以将存储的脚本指定为 if 条件。
resp = client.put_script(
id="my-prod-tag-script",
script={
"lang": "painless",
"source": "\n Collection tags = ctx.tags;\n if(tags != null){\n for (String tag : tags) {\n if (tag.toLowerCase().contains('prod')) {\n return false;\n }\n }\n }\n return true;\n "
},
)
print(resp)
resp1 = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"drop": {
"description": "Drop documents that don't contain 'prod' tag",
"if": {
"id": "my-prod-tag-script"
}
}
}
],
)
print(resp1)
const response = await client.putScript({
id: "my-prod-tag-script",
script: {
lang: "painless",
source:
"\n Collection tags = ctx.tags;\n if(tags != null){\n for (String tag : tags) {\n if (tag.toLowerCase().contains('prod')) {\n return false;\n }\n }\n }\n return true;\n ",
},
});
console.log(response);
const response1 = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
drop: {
description: "Drop documents that don't contain 'prod' tag",
if: {
id: "my-prod-tag-script",
},
},
},
],
});
console.log(response1);
PUT _scripts/my-prod-tag-script
{
"script": {
"lang": "painless",
"source": """
Collection tags = ctx.tags;
if(tags != null){
for (String tag : tags) {
if (tag.toLowerCase().contains('prod')) {
return false;
}
}
}
return true;
"""
}
}
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"drop": {
"description": "Drop documents that don't contain 'prod' tag",
"if": { "id": "my-prod-tag-script" }
}
}
]
}
传入的文档通常包含对象字段。如果处理器脚本尝试访问其父对象不存在的字段,则 Elasticsearch 会返回 NullPointerException。为了避免这些异常,请使用空安全运算符(如 ?.)并编写空安全的脚本。
例如,ctx.network?.name.equalsIgnoreCase('Guest') 不是空安全的。ctx.network?.name 可能返回 null。将脚本重写为 'Guest'.equalsIgnoreCase(ctx.network?.name),这在空安全方面是安全的,因为 Guest 始终非空。
如果无法将脚本重写为空安全的,请包含显式的空检查。
resp = client.ingest.put_pipeline(
id="my-pipeline",
processors=[
{
"drop": {
"description": "Drop documents that contain 'network.name' of 'Guest'",
"if": "ctx.network?.name != null && ctx.network.name.contains('Guest')"
}
}
],
)
print(resp)
const response = await client.ingest.putPipeline({
id: "my-pipeline",
processors: [
{
drop: {
description: "Drop documents that contain 'network.name' of 'Guest'",
if: "ctx.network?.name != null && ctx.network.name.contains('Guest')",
},
},
],
});
console.log(response);
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"drop": {
"description": "Drop documents that contain 'network.name' of 'Guest'",
"if": "ctx.network?.name != null && ctx.network.name.contains('Guest')"
}
}
]
}
有条件地应用管道
编辑将 if 条件与pipeline 处理器结合使用,可以根据您的条件将其他管道应用于文档。您可以将此管道用作默认管道,在索引模板中用于配置多个数据流或索引。
resp = client.ingest.put_pipeline(
id="one-pipeline-to-rule-them-all",
processors=[
{
"pipeline": {
"description": "If 'service.name' is 'apache_httpd', use 'httpd_pipeline'",
"if": "ctx.service?.name == 'apache_httpd'",
"name": "httpd_pipeline"
}
},
{
"pipeline": {
"description": "If 'service.name' is 'syslog', use 'syslog_pipeline'",
"if": "ctx.service?.name == 'syslog'",
"name": "syslog_pipeline"
}
},
{
"fail": {
"description": "If 'service.name' is not 'apache_httpd' or 'syslog', return a failure message",
"if": "ctx.service?.name != 'apache_httpd' && ctx.service?.name != 'syslog'",
"message": "This pipeline requires service.name to be either `syslog` or `apache_httpd`"
}
}
],
)
print(resp)
response = client.ingest.put_pipeline(
id: 'one-pipeline-to-rule-them-all',
body: {
processors: [
{
pipeline: {
description: "If 'service.name' is 'apache_httpd', use 'httpd_pipeline'",
if: "ctx.service?.name == 'apache_httpd'",
name: 'httpd_pipeline'
}
},
{
pipeline: {
description: "If 'service.name' is 'syslog', use 'syslog_pipeline'",
if: "ctx.service?.name == 'syslog'",
name: 'syslog_pipeline'
}
},
{
fail: {
description: "If 'service.name' is not 'apache_httpd' or 'syslog', return a failure message",
if: "ctx.service?.name != 'apache_httpd' && ctx.service?.name != 'syslog'",
message: 'This pipeline requires service.name to be either `syslog` or `apache_httpd`'
}
}
]
}
)
puts response
const response = await client.ingest.putPipeline({
id: "one-pipeline-to-rule-them-all",
processors: [
{
pipeline: {
description:
"If 'service.name' is 'apache_httpd', use 'httpd_pipeline'",
if: "ctx.service?.name == 'apache_httpd'",
name: "httpd_pipeline",
},
},
{
pipeline: {
description: "If 'service.name' is 'syslog', use 'syslog_pipeline'",
if: "ctx.service?.name == 'syslog'",
name: "syslog_pipeline",
},
},
{
fail: {
description:
"If 'service.name' is not 'apache_httpd' or 'syslog', return a failure message",
if: "ctx.service?.name != 'apache_httpd' && ctx.service?.name != 'syslog'",
message:
"This pipeline requires service.name to be either `syslog` or `apache_httpd`",
},
},
],
});
console.log(response);
PUT _ingest/pipeline/one-pipeline-to-rule-them-all
{
"processors": [
{
"pipeline": {
"description": "If 'service.name' is 'apache_httpd', use 'httpd_pipeline'",
"if": "ctx.service?.name == 'apache_httpd'",
"name": "httpd_pipeline"
}
},
{
"pipeline": {
"description": "If 'service.name' is 'syslog', use 'syslog_pipeline'",
"if": "ctx.service?.name == 'syslog'",
"name": "syslog_pipeline"
}
},
{
"fail": {
"description": "If 'service.name' is not 'apache_httpd' or 'syslog', return a failure message",
"if": "ctx.service?.name != 'apache_httpd' && ctx.service?.name != 'syslog'",
"message": "This pipeline requires service.name to be either `syslog` or `apache_httpd`"
}
}
]
}
获取管道使用情况统计信息
编辑使用节点统计信息 API 获取全局和每个管道的摄取统计信息。使用这些统计信息来确定哪些管道运行频率最高或处理时间最长。
resp = client.nodes.stats(
metric="ingest",
filter_path="nodes.*.ingest",
)
print(resp)
response = client.nodes.stats( metric: 'ingest', filter_path: 'nodes.*.ingest' ) puts response
const response = await client.nodes.stats({
metric: "ingest",
filter_path: "nodes.*.ingest",
});
console.log(response);
GET _nodes/stats/ingest?filter_path=nodes.*.ingest