近实时搜索
编辑近实时搜索
编辑当文档存储在 Elasticsearch 中时,它会被索引并在近实时(1 秒内)内完全可搜索。什么是近实时搜索?
Lucene(Elasticsearch 基于的 Java 库)引入了每个分段搜索的概念。分段类似于倒排索引,但在 Lucene 中,索引的意思是“多个分段加上一个提交点”。提交后,一个新的分段会被添加到提交点,缓冲区会被清空。
文件系统缓存位于 Elasticsearch 和磁盘之间。内存索引缓冲区中的文档(图 3)会被写入到一个新的分段(图 4)。新分段首先会被写入到文件系统缓存(这很便宜),之后才会刷新到磁盘(这很昂贵)。但是,文件一旦进入缓存,就可以像任何其他文件一样打开和读取。
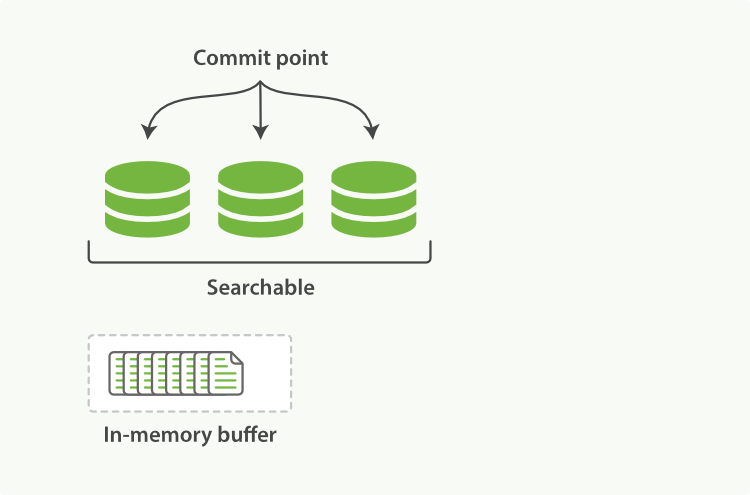
图 3. 包含新文档的内存缓冲区的 Lucene 索引
Lucene 允许写入和打开新的分段,使其中包含的文档对搜索可见,而无需执行完整的提交。这比写入磁盘的提交过程要轻量级得多,并且可以频繁执行而不会降低性能。
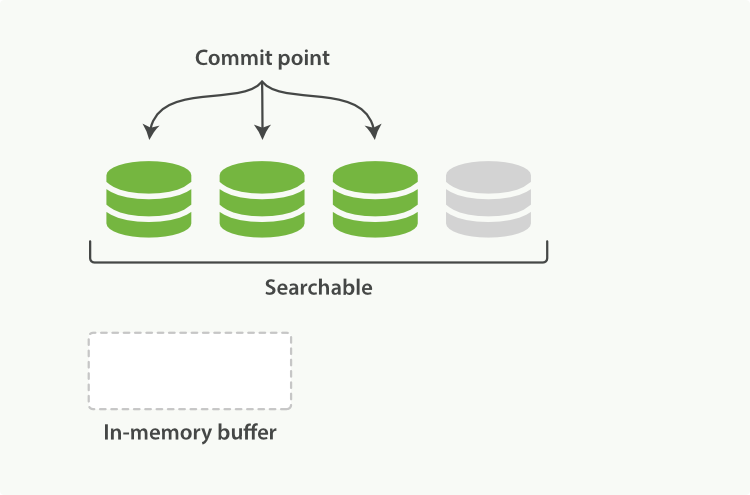
图 4. 缓冲区内容被写入到一个分段,该分段可搜索,但尚未提交
在 Elasticsearch 中,写入和打开新分段的过程称为刷新。刷新使自上次刷新以来对索引执行的所有操作都可用于搜索。您可以通过以下方式控制刷新
默认情况下,Elasticsearch 每秒定期刷新一次索引,但仅刷新在过去 30 秒内至少收到过一个搜索请求的索引。这就是我们说 Elasticsearch 具有近实时搜索的原因:文档更改不会立即对搜索可见,但会在此时间范围内变得可见。