数据层
编辑数据层
编辑数据层是集群内共享相同节点的数据节点角色以及大小适合该角色的硬件配置的节点集合。Elastic 建议同一层中的节点共享相同的硬件配置,以避免热点。
您使用的数据层以及使用方式取决于数据的类别。
以下数据层可用于每个数据类别
内容数据
- 内容层节点处理非时间序列索引(例如产品目录)的索引和查询负载。
时间序列数据
Elasticsearch 通常期望数据层内的节点共享相同的硬件配置。未遵循此建议的变体应仔细设计,以避免热点。
数据层的使用方式通常取决于数据的类别
可用数据层
编辑了解有关每个数据层的更多信息,包括何时以及如何使用它。
内容层
编辑内容层中存储的数据通常是商品目录或文章存档等项目集合。与时间序列数据不同,内容的值随时间推移保持相对恒定,因此将其移动到随着老化具有不同性能特征的层是没有意义的。内容数据通常具有较长的数据保留要求,并且无论它们有多旧,您都希望能够快速检索项目。
内容层节点通常针对查询性能进行了优化 — 它们优先考虑处理能力而不是 IO 吞吐量,以便它们可以处理复杂的搜索和聚合并快速返回结果。虽然它们也负责索引,但内容数据的摄取速度通常不如日志和指标等时间序列数据高。从弹性的角度来看,此层中的索引应配置为使用一个或多个副本。
内容层是必需的,并且通常与热层部署在相同的节点组中。系统索引和其他不属于数据流的索引会自动分配到内容层。
热层
编辑热层是时间序列数据的 Elasticsearch 入口点,并保存您最新、搜索最频繁的时间序列数据。热层中的节点需要在读取和写入方面都很快,这需要更多的硬件资源和更快的存储 (SSD)。为了弹性,热层中的索引应配置为使用一个或多个副本。
热层是必需的。属于数据流的新索引会自动分配到热层。
温层
编辑一旦查询时间序列数据的频率低于热层中最近索引的数据,时间序列数据可以移动到温层。温层通常保存最近几周的数据。仍然允许更新,但可能不频繁。温层中的节点通常不需要像热层中的节点那么快。为了弹性,温层中的索引应配置为使用一个或多个副本。
冷层
编辑当您不再需要定期搜索时间序列数据时,它可以从温层移动到冷层。虽然仍然可以搜索,但此层通常针对较低的存储成本而不是搜索速度进行了优化。
为了更好地节省存储空间,您可以在冷层上保留完全挂载的索引的可搜索快照。与常规索引不同,这些完全挂载的索引不需要副本来实现可靠性。如果发生故障,它们可以从底层快照中恢复数据。这可能会使数据所需的本地存储减少一半。需要在冷层中使用完全挂载的索引,就需要快照存储库。完全挂载的索引是只读的。
或者,您可以使用冷层来存储带有副本的常规索引,而不是使用可搜索快照。这使您可以在成本较低的硬件上存储较旧的数据,但不会像温层那样减少所需的磁盘空间。
冻结层
编辑一旦数据不再被查询或很少被查询,它可能会从冷层移动到冻结层,并在那里度过剩余的生命周期。
冻结层需要快照存储库。冻结层使用部分挂载的索引来存储和从快照存储库加载数据。这降低了本地存储和运营成本,同时仍然允许您搜索冻结的数据。由于 Elasticsearch 有时必须从快照存储库中获取冻结的数据,因此在冻结层上的搜索通常比在冷层上慢。
配置数据层
编辑按照您的部署类型的说明配置数据层。
Elasticsearch Service 或 Elastic Cloud Enterprise
编辑Elastic Cloud 部署的默认配置包括一个用于热数据和内容数据的共享层。此层是必需的,不能删除。
在创建部署时添加温层、冷层或冻结层
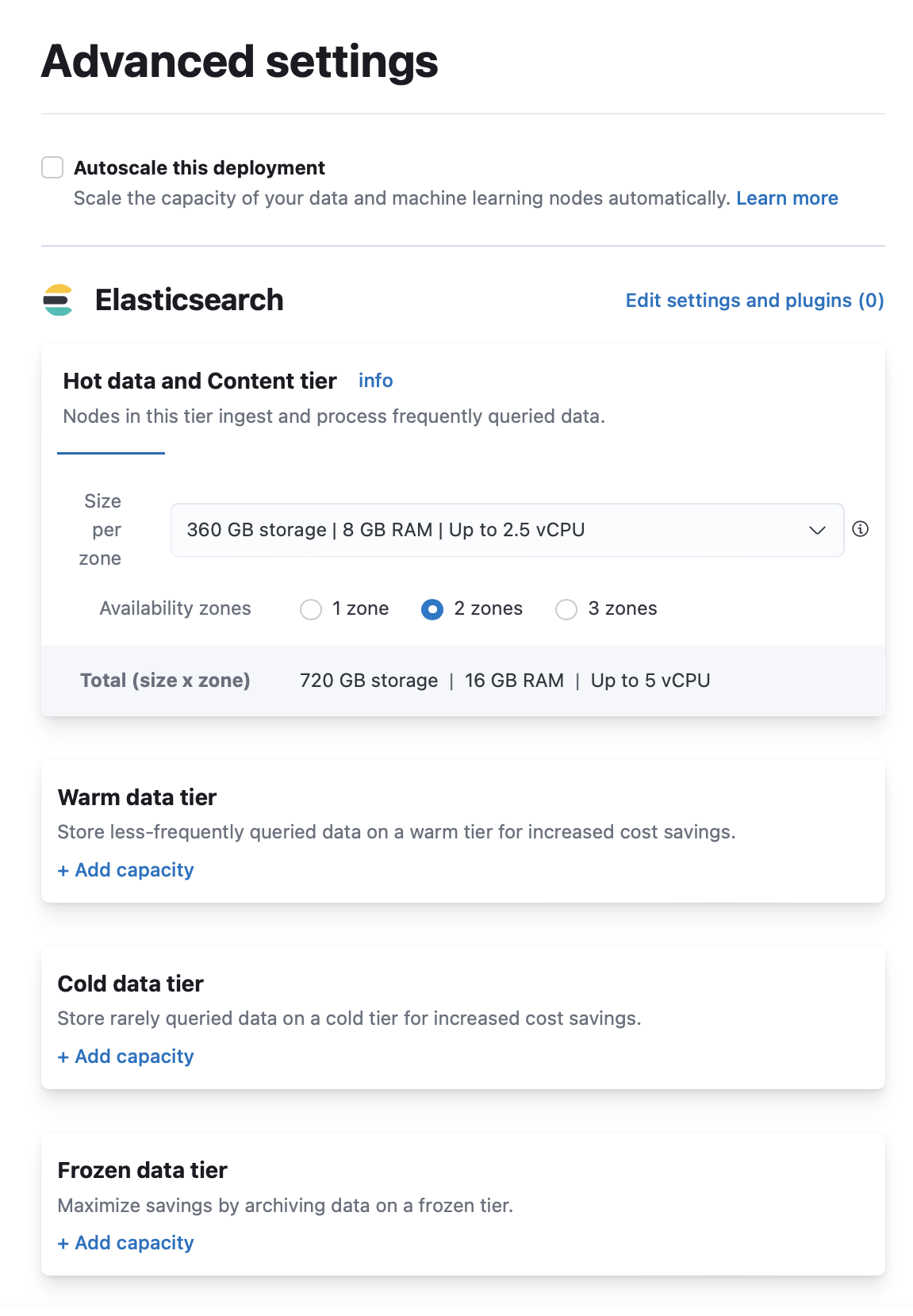
- 在 创建部署 页面上,单击 高级设置。
- 单击任何数据层的 + 添加容量 以添加。
- 单击页面底部的 创建部署 以保存更改。
向现有部署添加数据层
- 登录到 Elastic Cloud 控制台。
- 在 部署 页面上,选择您的部署。
- 在您的部署菜单中,选择 编辑。
- 单击任何数据层的 + 添加容量 以添加。
- 单击页面底部的 保存 以保存更改。
要删除数据层,请参阅 禁用数据层。
自托管部署
编辑对于自托管部署,每个节点的数据角色在 elasticsearch.yml 中配置。例如,集群中性能最高的节点可能会分配到热层和内容层
node.roles: ["data_hot", "data_content"]
我们建议您在冻结层中使用专用节点。
数据层索引分配
编辑index.routing.allocation.include._tier_preference 设置确定索引应分配到哪个层。
创建索引时,默认情况下,Elasticsearch 将 _tier_preference 设置为 data_content,以自动将索引分片分配到内容层。
当 Elasticsearch 创建作为数据流一部分的索引时,默认情况下,Elasticsearch 将 _tier_preference 设置为 data_hot,以自动将索引分片分配到热层。
在创建索引时,您可以通过以下两种方式之一显式设置首选值来覆盖默认设置
- 使用索引模板。有关详细信息,请参阅使用 ILM 自动化滚动。
- 在 创建索引 请求主体中。
您可以通过将索引设置更新为首选值,在创建索引后覆盖此设置。
此设置还按优先级顺序接受多个层。如果首选层中没有可用节点,则可以防止索引保持未分配状态。例如,当索引生命周期管理将索引迁移到冷阶段时,它会将索引 _tier_preference 设置为 data_cold,data_warm,data_hot。
要删除数据层首选项设置,请将 _tier_preference 值设置为 null。这允许索引分配到集群中的任何数据节点。将 _tier_preference 设置为 null 不会恢复默认值。请注意,在托管索引的情况下,迁移操作可能会在其位置应用新值。
确定当前数据层偏好
编辑您可以通过轮询其设置,查找 index.routing.allocation.include._tier_preference 来检查现有索引的数据层偏好。
resp = client.indices.get_settings(
index="my-index-000001",
filter_path="*.settings.index.routing.allocation.include._tier_preference",
)
print(resp)
const response = await client.indices.getSettings({
index: "my-index-000001",
filter_path: "*.settings.index.routing.allocation.include._tier_preference",
});
console.log(response);
GET /my-index-000001/_settings?filter_path=*.settings.index.routing.allocation.include._tier_preference
问题排查
编辑_tier_preference 设置可能会与其他分配设置冲突。此冲突可能会阻止分片分配。当集群尚未完全迁移到数据层时,可能会发生冲突。
此设置不会取消分配当前已分配的分片,但可能会阻止其从当前位置迁移到其指定的数据层。要进行故障排除,请调用 集群分配解释 API 并指定可疑的问题分片。
自动数据层迁移
编辑ILM 使用 migrate 操作自动将托管索引转换为可用的数据层。默认情况下,此操作会自动注入到每个阶段。您可以使用 "enabled": false 显式指定 migrate 操作以禁用自动迁移,例如,如果您使用 allocate 操作 来手动指定分配规则。