推理处理
编辑推理处理
编辑当您通过 内容 UI 创建索引时,还会创建一组默认的摄取管道,其中包括 ML 推理管道。ML 推理管道 使用推理处理器来分析字段并使用输出来丰富文档。推理处理器使用 ML 训练模型,因此您需要使用内置模型或 在您的集群中部署训练模型 才能使用此功能。
本指南重点介绍 ML 推理管道、其用途以及如何管理它。
此功能并非在所有 Elastic 订阅级别都可用。有关 Elastic Cloud 和 自管理 部署,请参阅 Elastic 订阅页面。
NLP 用例
编辑自然语言处理 (NLP) 允许开发人员创建超出词法搜索标准的丰富搜索体验。以下是通过使用 NLP 模型来改进搜索体验的一些示例
ELSER 文本扩展
编辑使用 Elastic 的 ELSER 机器学习模型,您可以轻松地为查询添加文本扩展。其工作原理是在摄取时使用 ELSER 为文档提供语义增强,并结合 Elastic 搜索应用程序模板 的强大功能,在查询时提供自动文本扩展。
命名实体识别 (NER)
编辑最常用于从文本中检测诸如人、地点和组织信息等实体,NER 可以用于从文本中提取关键信息,并根据该信息对结果进行分组。体育新闻媒体网站可以使用 NER 自动提取其文章中专业运动员、体育场和运动队的名字,并链接到赛季统计数据或时间表。
文本分类
编辑文本分类 通常用于情感分析,也可用于类似的任务,例如将公共论坛中的内容标记为包含仇恨言论,或者对支持请求进行分流和标记,使其自动达到正确的升级级别。
文本嵌入
编辑使用 文本嵌入 模型分析文本字段将生成文本的 密集向量 表示形式。这个数值数组编码了文本的语义含义。将相同的模型与用户的搜索查询一起使用将生成一个向量,然后该向量可用于搜索,根据向量相似性(语义相似性)而不是传统的词或文本相似性对结果进行排名。
一个常见的用例是用户搜索常见问题解答,或支持代理搜索知识库,其中语义相似的内容可能会以措辞上的相似性很少的方式进行索引。
内容 UI 中的 NLP
编辑ML 推理管道概述
编辑下图显示了文档在摄取期间的处理方式。
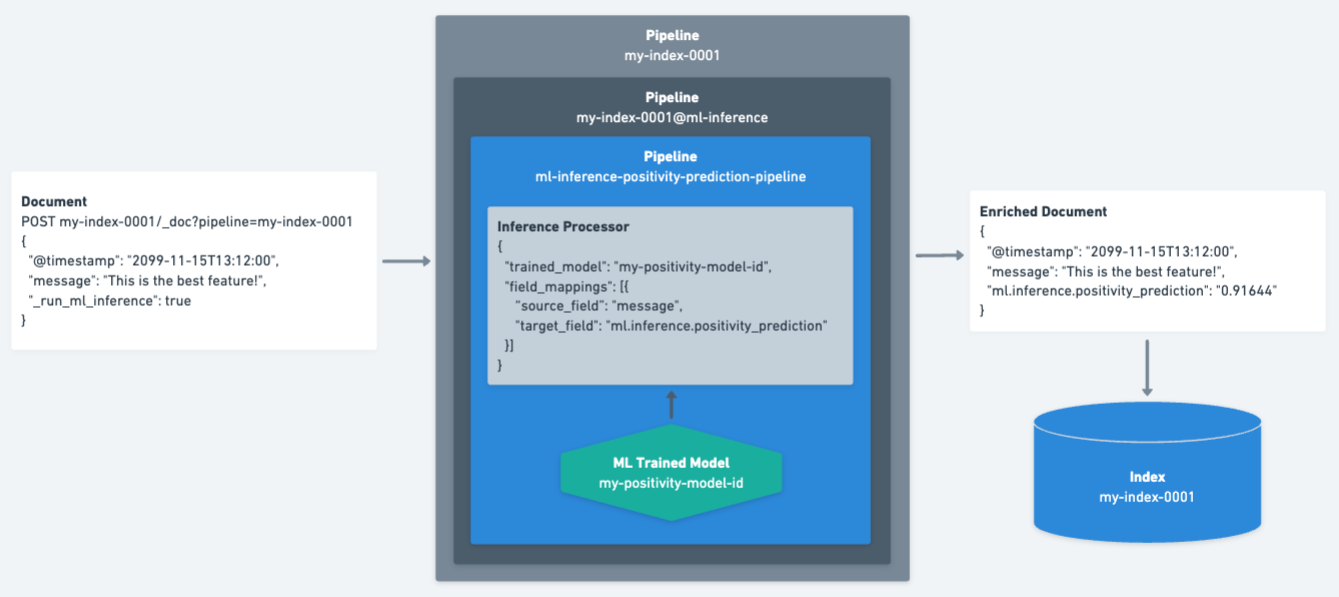
- 文档由
my-index-0001管道处理,当通过 Elastic 连接器或爬网程序进行索引时会自动执行此操作。 - 将
_run_ml_inference字段设置为true以确保执行 ML 推理管道 (my-index-0001@ml-inference)。在摄取过程中会删除此字段。 - 推理处理器使用
my-positivity-model-id训练模型分析文档中的message字段。推理输出存储在ml.inference.positivity_prediction字段中。 - 然后,将生成的增强文档索引到
my-index-0001索引中。 - 现在可以在查询时使用
ml.inference.positivity_prediction字段来搜索高于或低于特定阈值的文档。
查找、部署和管理训练模型
编辑此功能旨在使您更容易使用 ML 训练模型。首先,您需要确定哪个模型最适合您的数据。请确保使用 兼容的第三方 NLP 模型。由于这些模型是公开可用的,因此在 部署它们 之前无法对模型进行微调。
训练模型必须在当前的 Kibana 空间中可用并运行才能使用它们。默认情况下,模型应该在所有启用了 分析 > 机器学习 功能的 Kibana 空间中可用。要管理您的训练模型,请使用 Kibana UI 并导航到 Stack Management → Machine Learning → 训练模型。可以在 空间 列中控制空间。要停止或启动模型,请转到 Kibana 的 分析 菜单中的 机器学习 选项卡,然后单击 模型管理 部分中的 训练模型。
需要 monitor_ml Elasticsearch 集群权限 才能管理 ML 模型和使用这些模型的 ML 推理管道。
向 ML 推理管道添加推理处理器
编辑要创建特定于索引的 ML 推理管道,请转到 Kibana UI 中的 搜索 → 内容 → 索引 → <您的索引> → 管道。
如果只看到 ent-search-generic-ingestion 管道,则需要单击 复制并自定义 来创建特定于索引的管道。这将创建 {index_name}@ml-inference 管道。
一旦您的特定于索引的 ML 推理管道准备就绪,您就可以添加使用 ML 训练模型的推理处理器。要向 ML 推理管道添加推理处理器,请单击 机器学习推理管道 卡中的 添加推理管道 按钮。

在这里,您可以
-
为您的管道选择一个名称。
- 此名称需要在整个部署中是唯一的。如果您希望此管道特定于索引,我们建议在管道名称中包含索引名称。
- 如果您未设置管道名称,则在选择训练模型后会提供默认的唯一名称。
-
选择您要使用的 ML 训练模型。
- 您必须先部署模型才能选择它。要开始部署模型,请单击 部署 按钮。
-
选择一个或多个源字段作为推理处理器的输入。
- 如果没有可用的源字段,则您的索引将需要 字段映射。
- (可选)为您的目标字段选择一个名称。这是存储推理模型输出的位置。仅当您选择单个源字段时,才可以更改默认名称。
- 通过单击 添加 按钮将源-目标字段映射添加到配置中。
- 对您要添加的每个字段映射重复步骤 3-5。
- (可选)使用示例文档测试管道。
- (可选)使用 创建管道 按钮在创建管道之前查看管道定义。
管理和删除 ML 推理管道中的推理处理器
编辑添加到特定于索引的 ML 推理管道的推理处理器是普通的 Elasticsearch 管道。创建后,每个处理器都将具有 在 Stack Management 中查看 和 删除管道 的选项。从 内容 UI 中删除推理处理器会删除管道,并也会将其从特定于索引的 ML 推理管道中删除。
也可以通过 Stack Management → 摄取管道 在 Kibana 中查看、编辑和删除这些管道,就像所有其他 Elasticsearch 摄取管道一样。您也可以使用 摄取管道 API。如果您在 Kibana 的 内容 UI 之外删除任何这些管道,请确保编辑引用它们的 ML 推理管道。
测试您的 ML 推理管道
编辑您可以在 测试 选项卡下创建机器学习推理管道时,在索引任何文档之前验证推理输出的预期结构。提供一个示例文档,单击 模拟,然后在结果中查找 ml.inference 对象。
为了确保在摄取文档时将运行 ML 推理管道,您必须确保您正在摄取的文档具有名为 _run_ml_inference 且设置为 true 的字段,并且您必须将管道设置为 {index_name}。对于连接器和爬网程序索引,如果您已为管道名称 {index_name} 正确配置了设置,则会自动发生这种情况。要管理这些设置
- 转到 搜索 > 内容 > 索引 > <您的索引> > 管道。
- 点击 {index_name} 管道的 Ingest Pipelines(摄取管道) 卡片中的 Settings(设置) 链接。
- 确保已选择 ML inference pipelines(ML 推理管道)。如果未选择,请选择它并保存更改。
了解更多
编辑- 有关创建的各种管道的信息,请参阅概述。
- 了解 ELSER,Elastic 用于语义搜索的专有检索模型,该模型使用稀疏向量。
- NER HuggingFace 模型
- 文本分类 HuggingFace 模型
- 文本嵌入 HuggingFace 模型