ELSER – Elastic Learned Sparse EncodeR
编辑ELSER – Elastic Learned Sparse EncodeR
编辑Elastic Learned Sparse EncodeR(简称 ELSER)是由 Elastic 训练的检索模型,使您能够执行语义搜索,以检索更相关的搜索结果。这种搜索类型基于上下文含义和用户意图提供搜索结果,而不是完全匹配关键字。
ELSER 是一种域外模型,这意味着它不需要在您自己的数据上进行微调,使其能够开箱即用地适应各种用例。
此模型建议用于英文文档和查询。如果要在非英文文档上执行语义搜索,请使用 E5 模型。
虽然 ELSER V2 已正式发布,但 ELSER V1 处于 [预览] 此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能的支持 SLA 的约束。 ,并且将保持在技术预览阶段。
词元 - 而不是同义词
编辑ELSER 将索引和搜索的段落扩展为词汇集合,这些词汇在各种训练数据集中被学习为频繁共同出现。模型将文本扩展成的词汇不是搜索词的同义词;它们是捕捉相关性的学习关联。这些扩展的词汇被加权,因为它们中的一些比其他词汇更重要。然后,Elasticsearch 稀疏向量(或排名特征)字段类型用于在索引时存储词汇和权重,并在以后进行搜索。
与向量嵌入相比,这种方法提供了更易于理解的搜索体验。但是,尝试直接解释词元和权重可能会产生误导,因为扩展本质上会导致高维空间中的向量。因此,某些词元,尤其是那些权重较低的词元,包含与其他低权重词元交织在一起的信息。在这方面,它们的功能类似于密集的向量表示,使得难以分离它们的各自贡献。如果在分析过程中不仔细考虑,这种复杂性可能会导致误解。
要求
编辑要使用 ELSER,您必须具有用于语义搜索的适当的订阅级别或激活试用期。
如果部署自动缩放已关闭,则部署和使用 ELSER 模型的最小专用 ML 节点大小在 Elasticsearch Service 中为 4 GB。建议启用自动缩放,因为它允许您的部署根据需求动态调整资源。通过使用更多分配或每个分配更多线程可以实现更好的性能,这需要更大的 ML 节点。自动缩放会在需要时提供更大的节点。如果关闭自动缩放,则必须自行提供大小合适的节点。
建议为您的 ELSER 部署启用训练模型自动缩放。请参阅训练模型自动缩放以了解更多信息。
ELSER v2
编辑与模型的初始版本相比,ELSER v2 提供了更高的检索准确性和更高效的索引。此增强归因于训练数据集的扩展,其中包括高质量的问答对以及改进的 FLOPS 正则化器,后者降低了计算查询和文档之间相似性的成本。
ELSER v2 有两个版本:一个跨平台版本,可在任何硬件上运行,以及一个针对 Intel® 芯片优化的版本。模型管理 > 训练模型页面会根据您集群的硬件显示建议部署的 ELSER v2 版本。但是,使用 ELSER 的推荐方式是通过推理 API作为服务,这使得下载和部署模型更容易,而且您无需从不同版本中选择。
如果您想了解有关 ELSER V2 改进的更多信息,请参阅此博客文章。
升级到 ELSER v2
编辑ELSER v2 不向后兼容。如果您使用 ELSER v1 对数据进行了索引,则需要使用引用 ELSER v2 的摄取管道重新索引数据,才能使用 v2 进行搜索。本教程演示了如何使用使用 ELSER v2 的推理处理器创建摄取管道,以及如何通过管道重新索引数据。
此外,elasticearch-labs GitHub 存储库包含一个交互式Python 笔记本,该笔记本逐步介绍了如何将索引升级到 ELSER V2。
下载并部署 ELSER
编辑下载和部署 ELSER 最简单且推荐的方法是使用推理 API。
- 在 Kibana 中,导航到Dev Console。
-
通过运行以下 API 请求使用 ELSER 服务创建推理端点
PUT _inference/sparse_embedding/my-elser-model { "service": "elser", "service_settings": { "adaptive_allocations": { "enabled": true, "min_number_of_allocations": 1, "max_number_of_allocations": 10 }, "num_threads": 1, } }API 请求会自动启动模型下载,然后部署模型。此示例通过自适应分配使用自动缩放。
请参阅ELSER 推理服务文档,以了解有关可用设置的更多信息。
创建 ELSER 推理端点后,即可用于语义搜索。在 Elastic Stack 中执行语义搜索的最简单方法是遵循 semantic_text 工作流。
下载和部署 ELSER 的替代方法
编辑您还可以从机器学习 > 训练模型、从搜索 > 索引或通过在 Dev Console 中使用训练模型 API 下载和部署 ELSER。
- 对于大多数情况,首选版本是Intel 和 Linux 优化模型,建议下载并部署该版本。
- 您可以通过在启动部署时分配唯一的部署 ID 来多次部署模型。这使您可以为不同的目的(例如搜索和摄取)拥有专用部署。通过这样做,您可以确保搜索速度不会受到摄取工作负载的影响,反之亦然。为搜索和摄取设置单独的部署可以缓解两者之间交互导致的性能问题,这些问题可能很难诊断。
使用训练模型页面
使用训练模型页面
编辑- 在 Kibana 中,导航到机器学习 > 训练模型。ELSER 可以在训练模型列表中找到。有两个版本可用:一个可在任何硬件上运行的可移植版本和一个针对 Intel® 芯片优化的版本。您可以查看根据您的硬件配置建议使用的模型。
-
单击添加训练模型按钮。在打开的模态窗口中选择您要使用的 ELSER 模型版本。根据您的硬件配置建议给您的模型会突出显示。单击下载。您可以在通知页面上查看下载状态。
或者,单击训练模型列表中的操作下的下载模型按钮。
- 下载完成后,单击启动部署按钮开始部署。
-
提供部署 ID,选择优先级,并设置每个分配的分配数和线程数的值。
- 单击启动。
使用搜索索引 UI
使用搜索索引 UI
编辑或者,您可以使用搜索索引 UI 将 ELSER 下载并部署到推理管道。
- 在 Kibana 中,导航到搜索 > 索引。
- 从列表中选择您要在其中使用 ELSER 的推理管道的索引。
- 导航到管道选项卡。
-
在机器学习推理管道下,单击部署按钮开始下载 ELSER 模型。这可能需要几分钟时间,具体取决于您的网络。
-
下载模型后,单击启动单线程按钮以使用基本配置启动模型,或选择微调性能选项以导航到训练模型页面,您可以在其中配置模型部署。

在 Dev Console 中使用训练模型 API
在 Dev Console 中使用训练模型 API
编辑- 在 Kibana 中,导航到Dev Console。
-
通过运行以下 API 调用来创建 ELSER 模型配置
PUT _ml/trained_models/.elser_model_2 { "input": { "field_names": ["text_field"] } }如果模型尚未下载,则 API 调用会自动启动模型下载。
-
使用带有部署 ID 的启动训练模型部署 API部署模型
POST _ml/trained_models/.elser_model_2/deployment/_start?deployment_id=for_search
您可以使用不同的部署 ID 多次部署模型。
在气隙环境中部署 ELSER
编辑如果您想在受限或封闭网络中部署 ELSER,您有两个选择
- 使用模型工件在其上创建您自己的 HTTP/HTTPS 端点,
- 将模型工件放入所有主节点上 config 目录内的目录中。
模型工件文件
编辑对于跨平台版本,您需要在系统中包含以下文件
https://ml-models.elastic.co/elser_model_2.metadata.json https://ml-models.elastic.co/elser_model_2.pt https://ml-models.elastic.co/elser_model_2.vocab.json
对于优化版本,您的系统中需要以下文件
https://ml-models.elastic.co/elser_model_2_linux-x86_64.metadata.json https://ml-models.elastic.co/elser_model_2_linux-x86_64.pt https://ml-models.elastic.co/elser_model_2_linux-x86_64.vocab.json
使用 HTTP 服务器
编辑信息:如果您使用现有的 HTTP 服务器,请注意模型下载器仅支持无密码的 HTTP 服务器。
您可以使用任何 HTTP 服务来部署 ELSER。此示例使用官方 Nginx Docker 镜像来设置新的 HTTP 下载服务。
- 下载模型工件文件。
- 将文件放入您选择的子目录中。
-
运行以下命令
export ELASTIC_ML_MODELS="/path/to/models" docker run --rm -d -p 8080:80 --name ml-models -v ${ELASTIC_ML_MODELS}:/usr/share/nginx/html nginx不要忘记将
/path/to/models更改为模型工件文件所在的子目录的路径。这些命令使用包含模型文件的子目录启动本地 Docker 镜像上的 Nginx 服务器。由于必须下载和构建 Docker 镜像,因此第一次启动可能需要较长时间。后续运行会更快启动。
-
通过在浏览器中访问以下 URL 来验证 Nginx 是否正常运行
http://{IP_ADDRESS_OR_HOSTNAME}:8080/elser_model_2.metadata.json如果 Nginx 正常运行,您将看到模型的元数据文件的内容。
-
通过将以下行添加到
config/elasticsearch.yml文件,将您的 Elasticsearch 部署指向 HTTP 服务器上的模型工件xpack.ml.model_repository: http://{IP_ADDRESS_OR_HOSTNAME}:8080如果您使用自己的 HTTP 或 HTTPS 服务器,请相应地更改地址。重要的是要指定协议(“http://”或“https://”)。确保所有主节点都可以访问您指定的服务器。
- 在所有主节点上重复步骤 5。
- 逐个重启主节点。
- 导航到 Kibana 中的训练模型页面,ELSER 可以在训练模型列表中找到。
- 单击添加训练模型按钮,选择您在步骤 1 中下载并要部署的 ELSER 模型版本,然后单击下载。选定的模型将从您配置的 HTTP/HTTPS 服务器下载。
- 下载完成后,单击启动部署按钮开始部署。
- 提供部署 ID,选择优先级,并设置每个分配的分配数和线程数的值。
- 单击启动。
HTTP 服务器仅用于下载模型。下载完成后,您可以停止并删除该服务。您可以通过运行以下命令停止本示例中使用的 Docker 镜像
docker stop ml-models
使用基于文件的访问
编辑对于基于文件的访问,请按照以下步骤操作
- 下载模型工件文件。
- 将文件放入 Elasticsearch 部署的
config目录内的models子目录中。 -
通过将以下行添加到
config/elasticsearch.yml文件,将您的 Elasticsearch 部署指向模型目录xpack.ml.model_repository: file://${path.home}/config/models/` - 在所有主节点上重复步骤 2 和步骤 3。
- 逐个重启主节点。
- 导航到 Kibana 中的训练模型页面,ELSER 可以在训练模型列表中找到。
- 单击添加训练模型按钮,选择您在步骤 1 中下载并要部署的 ELSER 模型版本,然后单击下载。选定的模型将从您在步骤 2 中放入的模型目录下载。
- 下载完成后,单击启动部署按钮开始部署。
- 提供部署 ID,选择优先级,并设置每个分配的分配数和线程数的值。
- 单击启动。
测试 ELSER
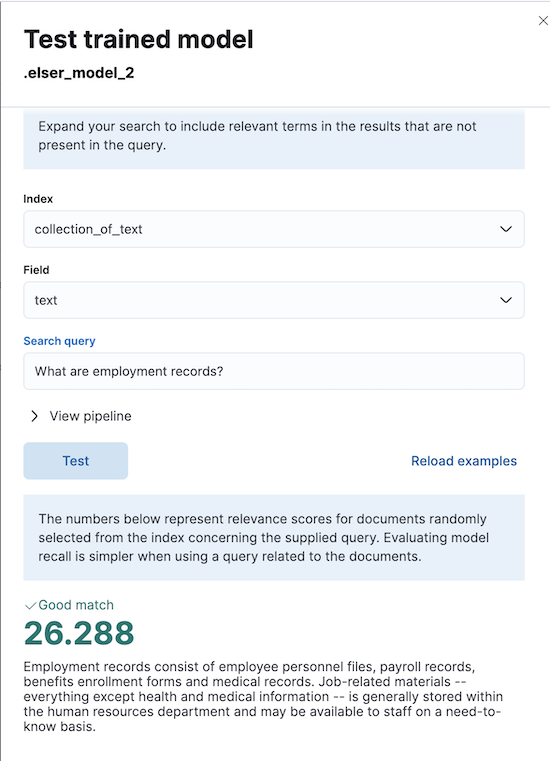
编辑您可以在 Kibana 中测试部署的模型。导航到模型管理 > 训练模型,在训练模型列表中找到已部署的 ELSER 模型,然后从“操作”菜单中选择测试模型。
您可以使用现有索引中的数据来测试模型。选择索引,然后选择要测试 ELSER 的索引字段。提供搜索查询并单击测试。当使用与文档相关的查询时,评估模型召回率会更简单。
结果包含所选字段的十个随机值列表,以及显示每个文档与查询的相关性的分数。分数越高,文档的相关性越高。您可以通过单击重新加载示例来重新加载示例文档。
性能注意事项
编辑- ELSER 在包含自然语言的中小型字段上效果最佳。对于连接器或 Web 爬虫用例,这与诸如标题、描述、摘要或摘要之类的字段最为一致。由于 ELSER 对字段的前 512 个标记进行编码,因此它可能无法为大型字段提供相关性最高的结果。例如,Web 爬虫文档上的
body_content,或通过连接器从 Office 文档中提取文本而产生的正文字段。对于此类较大的字段,请考虑将内容“分块”为多个值,其中每个块可以小于 512 个标记。 - 较大的文档在摄取时需要更长的时间,并且每个文档的推理时间也会随着需要处理的文档中的字段数量的增加而增加。
- 您的管道必须对其执行推理的字段越多,每个文档的摄取时间就越长。
要了解有关 ELSER 性能的更多信息,请参阅基准信息。
预先清理输入文本
编辑输入文本的质量会严重影响嵌入的质量。为了获得最佳结果,建议在生成嵌入之前清理输入文本。您可能需要执行的确切预处理很大程度上取决于您的文本。例如,如果您的文本包含 HTML 标签,请在摄取管道中使用HTML 剥离处理器以删除不必要的元素。始终在摄取之前检查并清理您的输入文本,以消除任何可能影响结果的无关实体。
使用 ELSER 的建议
编辑为了从 ELSER 训练模型中获得最大的价值,请考虑遵循此建议列表。
- 如果快速响应时间对您的用例很重要,请通过将
min_allocations设置为1来始终保持机器学习资源可用。 - 将
min_allocations设置为0可以为非关键用例或测试环境节省成本。 - 通过自适应分配或自适应资源启用自动缩放,使 Elasticsearch 可以根据进程的负载扩展或缩小 ELSER 部署的可用资源。
-
对摄取和搜索用例使用专用的优化 ELSER 推理端点。
- 在 Kibana 中部署训练模型时,您可以选择要为哪个用例优化 ELSER 部署。
- 如果您使用训练模型或推理 API 并希望为摄取优化 ELSER 训练模型部署或推理端点,请将线程数设置为
1("num_threads": 1)。 - 如果您使用训练模型或推理 API 并希望为搜索优化 ELSER 训练模型部署或推理端点,请将线程数设置为大于
1。
延伸阅读
编辑基准信息
编辑使用 ELSER 的推荐方法是通过 推理 API 作为服务。
以下部分提供有关 ELSER 在不同硬件上的性能以及将模型性能与 Elasticsearch BM25 和其他强大基准进行比较的信息。
版本概述
编辑ELSER V2 有一个优化版本,该版本设计为仅在具有 x86-64 CPU 架构的 Linux 上运行,以及一个可以在任何平台上运行的跨平台版本。
ELSER V2
编辑除了性能改进之外,ELSER V2 中最大的变化是引入了第一个平台特定的 ELSER 模型 - 即,针对仅在具有 x86-64 CPU 架构的 Linux 上运行而优化的模型。优化模型旨在在新一代 Intel CPU 上实现最佳性能,但它也可以在 AMD CPU 上运行。建议所有 ELSER 新用户使用新的优化 Linux-x86-64 模型,因为它比可以在任何平台上运行的跨平台模型快得多。ELSER V2 生成的嵌入质量明显高于 ELSER V1。无论您使用哪种 ELSER V2 模型(优化版或跨平台版),生成的特定嵌入都是相同的。
定性基准
编辑用于评估 ELSER 排名能力的指标是归一化折损累积增益 (NDCG),它可以处理多个相关文档和细粒度的文档评级。该指标应用于固定大小的检索文档列表,在本例中为前 10 个文档 (NDCG@10)。
下表显示了 ELSER V2 与 BM 25 的性能比较。ELSER V2 有 10 次获胜,1 次平局,1 次失败,并且 NDCG@10 的平均改进率为 18%。

BM25 和 ELSER V2 的 BEIR 数据集 NDCG@10 - 值越高越好)
硬件基准
编辑虽然目标是创建一个尽可能高性能的模型,但检索精度始终优先于速度,这是 ELSER 的设计原则之一。请参阅下表,了解有关预期模型性能的更多信息。这些值是指在两个数据集和不同的硬件配置上执行的操作。您的数据集会对模型性能产生影响。在您自己的数据上运行测试,以更实际地了解您的用例的模型性能。
ELSER V2
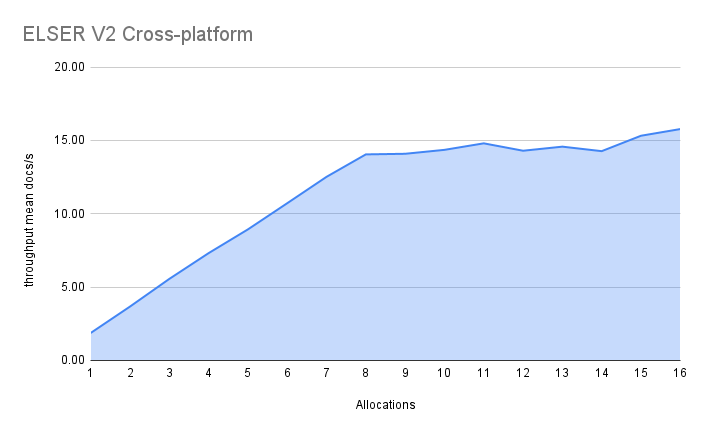
编辑总的来说,优化后的 V2 模型的最大摄取速率为 26 个文档/秒,而 ELSER V1 基准的 ELSER V1 最大速率为 14 个文档/秒,吞吐量提高了 90%。
虚拟内核(即,当分配的数量大于 vCPU 的一半时)的性能有所提高。以前,8 到 16 个分配之间的性能提升约为 7%。它已提高到 17%(8.11 上的 ELSER V1)和 20%(对于优化的 ELSER V2)。这些测试是在 16vCPU 机器上进行的,所有文档都包含 256 个标记。
您特定数据集中的文档长度会对您的吞吐量数字产生重大影响。
请参阅这篇博客文章,以了解有关 ELSER V2 性能改进的更多信息。
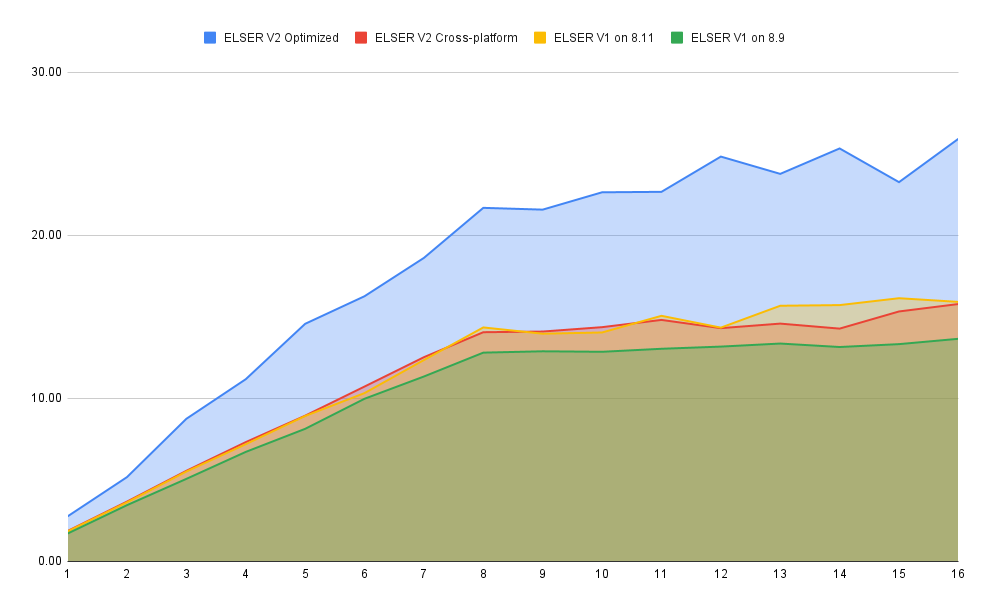
优化后的模型结果显示,在分配达到 8 个之前,性能增长几乎呈线性。之后,性能提升幅度变小。在此情况下,8 个分配时的性能为 22 文档/秒,而 16 个分配时的性能为 26 文档/秒,表明虚拟核心带来了 20% 的性能提升。
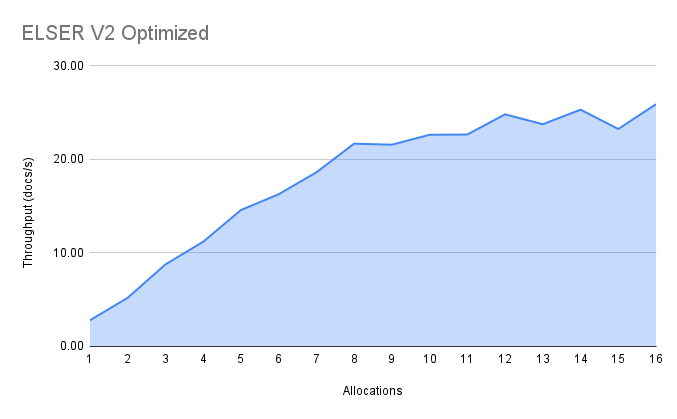
跨平台模型的 8 个和 16 个分配的性能分别为 14 文档/秒和 16 文档/秒,表明虚拟核心带来的性能提升为 12%。