推理 API
编辑推理 API
编辑推理 API 使您能够使用某些服务,例如内置的机器学习模型 (ELSER、E5)、通过 Eland 上传的模型、Cohere、OpenAI、Azure、Google AI Studio 或 Hugging Face。 对于内置模型和通过 Eland 上传的模型,推理 API 提供了一种使用和管理已训练模型的替代方法。但是,如果您不打算使用推理 API 来使用这些模型,或者如果您想使用非 NLP 模型,请使用机器学习已训练模型 API。
推理 API 使您能够创建推理端点,并将来自不同提供商(如 Amazon Bedrock、Anthropic、Azure AI Studio、Cohere、Google AI、Mistral、OpenAI 或 HuggingFace)的机器学习模型作为服务使用。使用以下 API 来管理推理模型并执行推理。
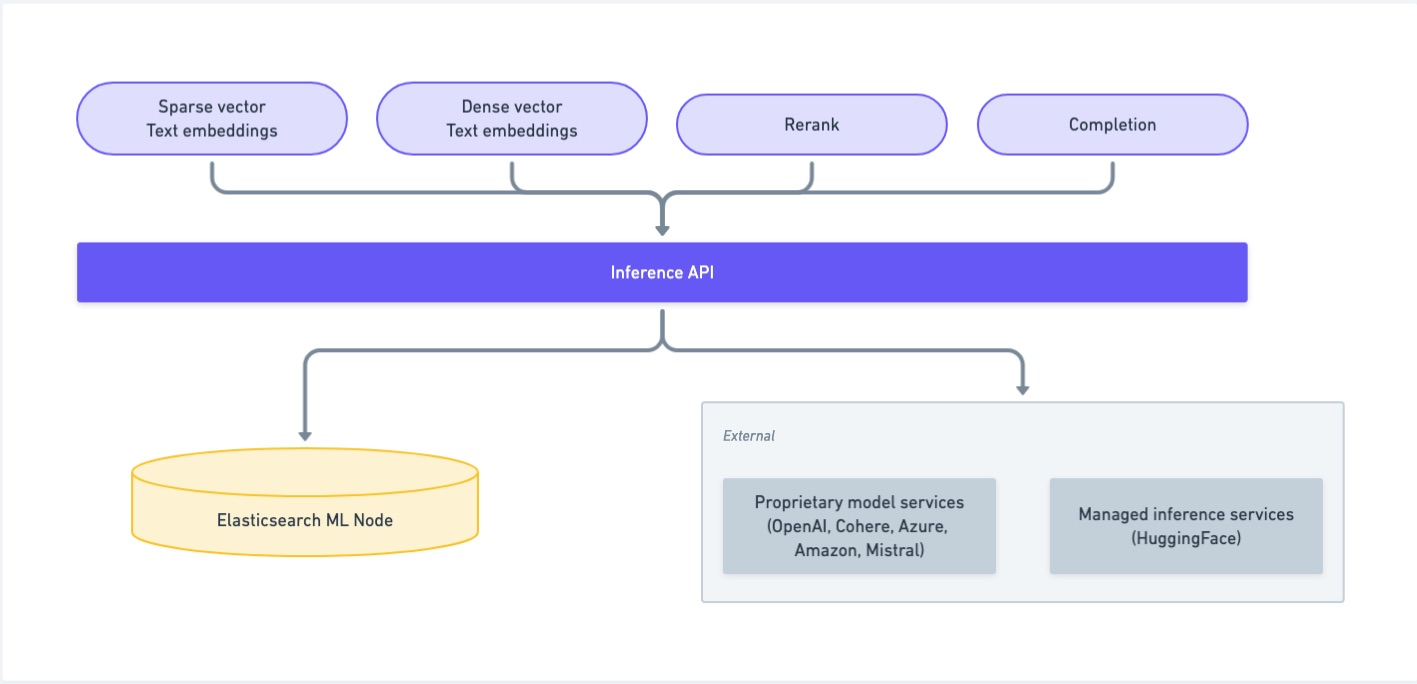
推理端点使您能够使用相应的机器学习模型,而无需手动部署,并通过 语义文本 在摄取时将其应用于您的数据。
从您的提供商选择一个模型或使用 ELSER(由 Elastic 训练的检索模型),然后通过创建推理 API创建一个推理端点。现在,使用语义文本在您的数据上执行语义搜索。
自适应分配
编辑自适应分配允许推理服务根据当前负载动态调整模型分配的数量。
启用自适应分配后
-
当负载增加时,分配数量会自动增加。
- 当负载减少时,分配会缩减到最小值 0,从而节省资源。
有关自适应分配和资源的更多信息,请参阅 已训练模型自动缩放 文档。
默认推理端点
编辑您的 Elasticsearch 部署包含预配置的推理端点,这使得在定义 semantic_text 字段或使用推理处理器时更容易使用它们。以下列表包含按 inference_id 列出的默认推理端点
在semantic_text字段定义中或在创建推理处理器时,使用端点的 inference_id。 API 调用将自动下载和部署模型,这可能需要几分钟。默认推理端点已启用自适应分配。对于这些模型,最小分配数量为 0。如果没有使用该端点的推理活动,分配数量将在 15 分钟后自动缩减为 0。
配置分块
编辑推理端点对它们可以一次处理的文本量有限制,这取决于模型的输入容量。分块是将输入文本拆分成保持在这些限制内的片段的过程。它发生在将文档摄取到semantic_text 字段中时。分块还有助于生成对人类易于理解的部分。在搜索结果中返回长文档不如提供最相关的文本块有用。
每个块将包括文本子段和从中生成的相应嵌入。
默认情况下,文档被拆分为句子,并以最多 250 个单词的段落进行分组,并有 1 个句子的重叠,以便每个块与前一个块共享一个句子。重叠确保了连续性,并防止输入文本中的重要上下文信息因硬性中断而丢失。
Elasticsearch 使用 ICU4J 库来检测分块的单词和句子边界。 单词边界是通过遵循一系列规则来识别的,而不仅仅是存在空格字符。对于使用空格的书写语言(如中文或日语),使用字典查找来检测单词边界。
分块策略
编辑有两种分块策略可用:sentence 和 word。
sentence 策略在句子边界处分割输入文本。每个块包含一个或多个完整的句子,确保句子级上下文的完整性得以保留,除非句子导致块超过 max_chunk_size 的字数,在这种情况下,它将被拆分到不同的块中。sentence_overlap 选项定义要包含在当前块中的前一个块的句子数,该数目为 0 或 1。
word 策略在单个单词上拆分输入文本,直到达到 max_chunk_size 限制。overlap 选项是要包含在当前块中的前一个块的单词数。
默认分块策略为 sentence。
在 8.16 之前创建的推理端点的默认分块策略为 word。
配置分块行为的示例
编辑以下示例创建一个使用 elasticsearch 服务的推理端点,该服务默认部署 ELSER 模型并配置分块行为。
resp = client.inference.put(
task_type="sparse_embedding",
inference_id="small_chunk_size",
inference_config={
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 100,
"sentence_overlap": 0
}
},
)
print(resp)
const response = await client.inference.put({
task_type: "sparse_embedding",
inference_id: "small_chunk_size",
inference_config: {
service: "elasticsearch",
service_settings: {
num_allocations: 1,
num_threads: 1,
},
chunking_settings: {
strategy: "sentence",
max_chunk_size: 100,
sentence_overlap: 0,
},
},
});
console.log(response);
PUT _inference/sparse_embedding/small_chunk_size
{
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 100,
"sentence_overlap": 0
}
}