稀有词项聚合
编辑稀有词项聚合
编辑一个基于多桶值源的聚合,用于查找“稀有”词项——那些处于分布长尾且不频繁出现的词项。从概念上讲,这就像一个按 _count 升序排序的 terms 聚合。正如 terms 聚合文档中指出的那样,实际上按计数升序对 terms 聚合进行排序会产生无界误差。相反,您应该使用 rare_terms 聚合。
语法
编辑一个独立的 rare_terms 聚合如下所示:
{
"rare_terms": {
"field": "the_field",
"max_doc_count": 1
}
}
表 52. rare_terms 参数
参数名称 |
描述 |
必需 |
默认值 |
|
我们希望在其中查找稀有词项的字段 |
必需 |
|
|
一个词项应该出现的最大文档数量。 |
可选 |
|
|
内部 CuckooFilters 的精度。精度越小,近似效果越好,但内存使用量越高。不能小于 |
可选 |
|
|
应该包含在聚合中的词项 |
可选 |
|
|
应该从聚合中排除的词项 |
可选 |
|
|
如果文档缺少正在聚合的字段,则应使用的值 |
可选 |
示例
resp = client.search(
aggs={
"genres": {
"rare_terms": {
"field": "genre"
}
}
},
)
print(resp)
response = client.search(
body: {
aggregations: {
genres: {
rare_terms: {
field: 'genre'
}
}
}
}
)
puts response
const response = await client.search({
aggs: {
genres: {
rare_terms: {
field: "genre",
},
},
},
});
console.log(response);
GET /_search
{
"aggs": {
"genres": {
"rare_terms": {
"field": "genre"
}
}
}
}
响应
{
...
"aggregations": {
"genres": {
"buckets": [
{
"key": "swing",
"doc_count": 1
}
]
}
}
}
在这个例子中,我们看到的唯一桶是 “swing” 桶,因为它是在一个文档中出现的唯一词项。如果我们把 max_doc_count 增加到 2,我们会看到更多的桶
resp = client.search(
aggs={
"genres": {
"rare_terms": {
"field": "genre",
"max_doc_count": 2
}
}
},
)
print(resp)
response = client.search(
body: {
aggregations: {
genres: {
rare_terms: {
field: 'genre',
max_doc_count: 2
}
}
}
}
)
puts response
const response = await client.search({
aggs: {
genres: {
rare_terms: {
field: "genre",
max_doc_count: 2,
},
},
},
});
console.log(response);
GET /_search
{
"aggs": {
"genres": {
"rare_terms": {
"field": "genre",
"max_doc_count": 2
}
}
}
}
现在显示了 “jazz” 词项,它的 doc_count 是 2"
{
...
"aggregations": {
"genres": {
"buckets": [
{
"key": "swing",
"doc_count": 1
},
{
"key": "jazz",
"doc_count": 2
}
]
}
}
}
最大文档计数
编辑max_doc_count 参数用于控制词项可以拥有的文档计数的上限。与 terms 聚合不同,rare_terms 聚合没有大小限制。这意味着将返回符合 max_doc_count 标准的词项。该聚合以这种方式运作是为了避免困扰 terms 聚合的按升序排序问题。
但是,这确实意味着如果选择不当,可能会返回大量结果。为了限制此设置的风险,最大 max_doc_count 为 100。
最大桶限制
编辑由于其工作方式,稀有词项聚合比其他聚合更容易触发 search.max_buckets 软限制。在聚合收集结果时,会在每个分片的基础上评估 max_bucket 软限制。一个词项在一个分片上可能是 “稀有的”,但一旦所有分片结果合并在一起,它可能会变得 “不稀有”。这意味着各个分片倾向于收集比真正稀有的桶更多的桶,因为它们只有自己的本地视图。这个列表最终会在协调节点上被修剪为正确的、较小的稀有词项列表……但是一个分片可能已经触发了 max_buckets 软限制并中止了请求。
当在可能有很多 “稀有” 词项的字段上进行聚合时,您可能需要增加 max_buckets 软限制。或者,您可能需要找到一种方法来过滤结果以返回更少的稀有值(较小的时间跨度、按类别过滤等),或者重新评估您对 “稀有” 的定义(例如,如果某个东西出现了 100,000 次,它真的 “稀有” 吗?)
文档计数是近似值
编辑确定数据集中 “稀有” 词项的天真方法是将所有值放入一个映射中,在访问每个文档时递增计数,然后返回底部 n 行。这无法扩展到即使是中等大小的数据集。一种分片方法,其中仅保留来自每个分片的 “top n” 值(类似于 terms 聚合),会失败,因为问题的长尾性质意味着不可能找到 “top n” 的底部值,而不必简单地收集所有分片的所有值。
相反,稀有词项聚合使用不同的近似算法
- 值在第一次被看到时被放入一个映射中。
- 该词项的每次添加的出现都会增加映射中的计数器
- 如果计数器 >
max_doc_count阈值,则将该词项从映射中删除并放入 CuckooFilter 中 - 每次查询词项时都会咨询 CuckooFilter。如果该值在过滤器内,则已知其已高于阈值并被跳过。
执行后,值映射是 max_doc_count 阈值下 “稀有” 词项的映射。然后将此映射和 CuckooFilter 与所有其他分片合并。如果存在大于阈值(或出现在不同分片的 CuckooFilter 中)的词项,则将该词项从合并的列表中删除。最终的值映射将作为 “稀有” 词项返回给用户。
CuckooFilters 有可能返回误报(它们可以说一个值实际上不存在于它们的集合中,但它却存在)。由于 CuckooFilter 被用于查看词项是否超过阈值,这意味着来自 CuckooFilter 的误报会错误地认为一个值是常见的,而实际上不是(因此将其从最终的桶列表中排除)。实际上,这意味着聚合表现出假阴性行为,因为该过滤器以与人们通常认为的近似集合成员资格草图 “相反” 的方式使用。
CuckooFilters 在论文中有更详细的描述
Fan, Bin, et al. “Cuckoo filter: Practically better than bloom.” Proceedings of the 10th ACM International on Conference on emerging Networking Experiments and Technologies. ACM, 2014.
精度
编辑虽然内部 CuckooFilter 本质上是近似的,但可以使用 precision 参数控制假阴性率。这允许用户用更多的运行时内存来换取更准确的结果。
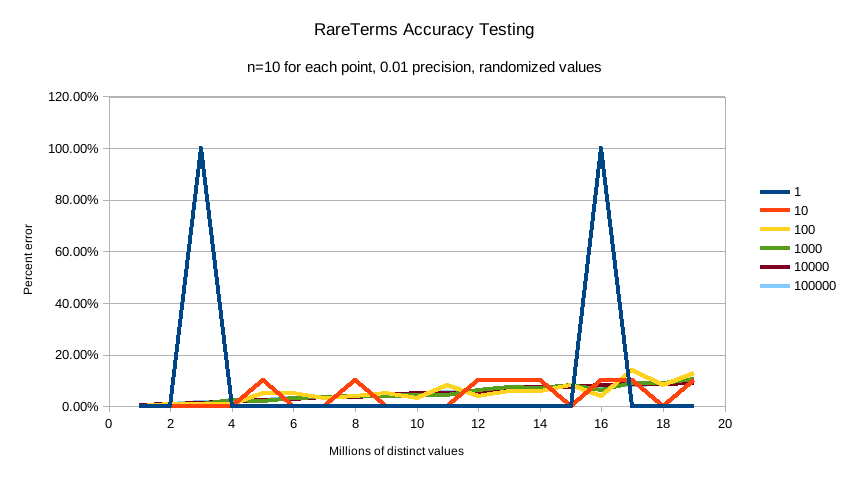
默认精度为 0.001,最小精度(例如,最准确且内存开销最大)为 0.00001。以下是一些图表,演示了聚合的准确性如何受到精度和不同词项数量的影响。
X 轴显示聚合已看到的不同值的数量,Y 轴显示误差百分比。每个线系列代表一个 “稀有性” 条件(从一个稀有项到 100,000 个稀有项)。例如,橙色的 “10” 线表示在 1-2000 万个不同的值中,有十个值是 “稀有的”(doc_count == 1)(其中其余的值的 doc_count > 1)
第一个图表显示精度 0.01
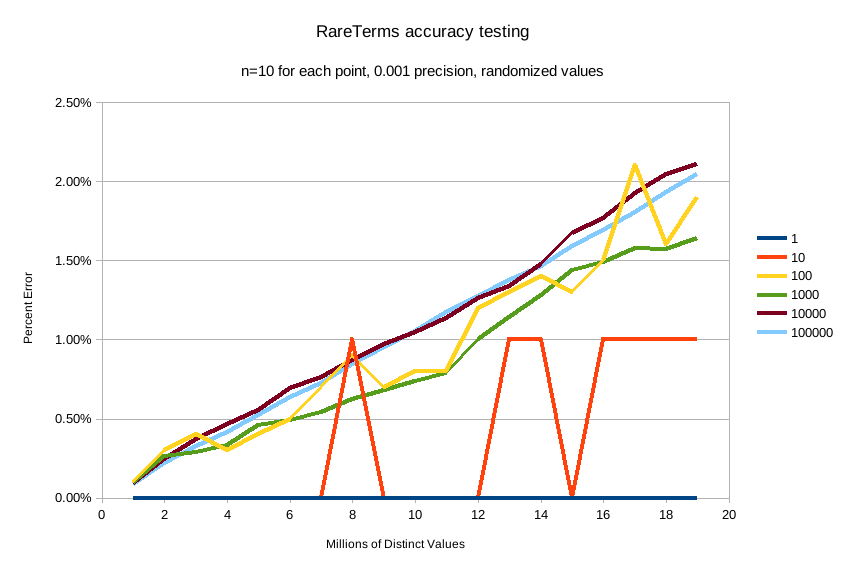
精度 0.001(默认值)
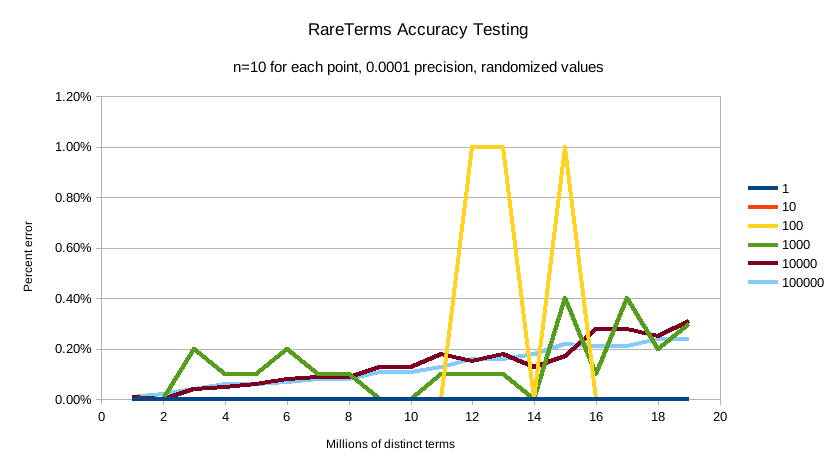
最后是 precision 0.0001
对于测试的条件,默认精度 0.001 保持小于 2.5% 的精度,并且随着不同值的数量增加,精度以受控的线性方式缓慢降低。
默认精度 0.001 的内存配置文件为 1.748⁻⁶ * n 字节,其中 n 是聚合已看到的不同值的数量(也可以大致估算,例如,2000 万个唯一值约为 30mb 的内存)。无论选择哪种精度,内存使用量都与不同值的数量成线性关系,精度只会影响内存配置文件的斜率,如此图所示
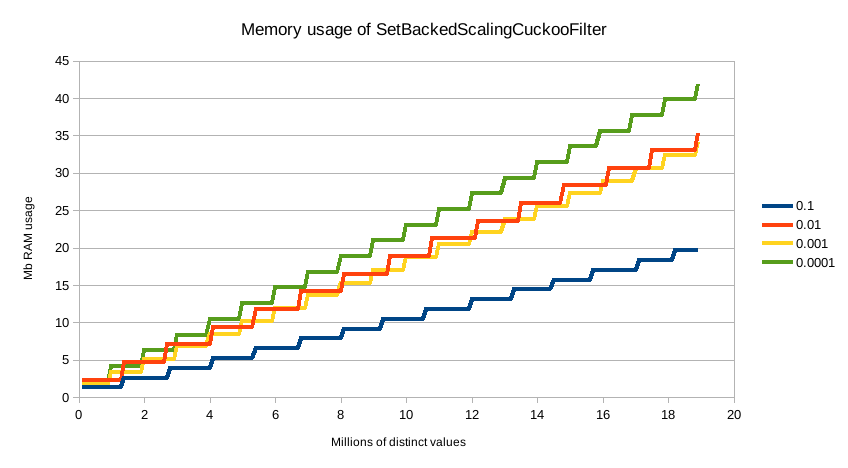
为了进行比较,在 2000 万个桶的情况下,等效的 terms 聚合大约为 20m * 69b == ~1.38gb(69 字节是非常乐观的空桶成本估计,远低于断路器所考虑的成本)。因此,尽管 rare_terms 聚合相对较重,但它仍然比等效的 terms 聚合小几个数量级
过滤值
编辑可以过滤将为其创建桶的值。这可以使用基于正则表达式字符串或精确值数组的 include 和 exclude 参数来完成。此外,include 子句可以使用 partition 表达式进行过滤。
使用正则表达式过滤值
编辑resp = client.search(
aggs={
"genres": {
"rare_terms": {
"field": "genre",
"include": "swi*",
"exclude": "electro*"
}
}
},
)
print(resp)
response = client.search(
body: {
aggregations: {
genres: {
rare_terms: {
field: 'genre',
include: 'swi*',
exclude: 'electro*'
}
}
}
}
)
puts response
const response = await client.search({
aggs: {
genres: {
rare_terms: {
field: "genre",
include: "swi*",
exclude: "electro*",
},
},
},
});
console.log(response);
GET /_search
{
"aggs": {
"genres": {
"rare_terms": {
"field": "genre",
"include": "swi*",
"exclude": "electro*"
}
}
}
}
在上面的示例中,将为所有以 swi 开头的标签创建桶,但不包括以 electro 开头的标签(因此,将聚合标签 swing,但不聚合 electro_swing)。include 正则表达式将确定 “允许” 聚合的值,而 exclude 确定不应聚合的值。当两者都定义时,exclude 具有优先权,这意味着,先评估 include,然后再评估 exclude。
语法与 regexp 查询相同。
使用精确值过滤值
编辑对于基于精确值的匹配,include 和 exclude 参数可以简单地采用一个字符串数组,这些字符串表示索引中找到的词项
resp = client.search(
aggs={
"genres": {
"rare_terms": {
"field": "genre",
"include": [
"swing",
"rock"
],
"exclude": [
"jazz"
]
}
}
},
)
print(resp)
response = client.search(
body: {
aggregations: {
genres: {
rare_terms: {
field: 'genre',
include: [
'swing',
'rock'
],
exclude: [
'jazz'
]
}
}
}
}
)
puts response
const response = await client.search({
aggs: {
genres: {
rare_terms: {
field: "genre",
include: ["swing", "rock"],
exclude: ["jazz"],
},
},
},
});
console.log(response);
GET /_search
{
"aggs": {
"genres": {
"rare_terms": {
"field": "genre",
"include": [ "swing", "rock" ],
"exclude": [ "jazz" ]
}
}
}
}
缺失值
编辑missing 参数定义了应如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有一个值。
resp = client.search(
aggs={
"genres": {
"rare_terms": {
"field": "genre",
"missing": "N/A"
}
}
},
)
print(resp)
response = client.search(
body: {
aggregations: {
genres: {
rare_terms: {
field: 'genre',
missing: 'N/A'
}
}
}
}
)
puts response
const response = await client.search({
aggs: {
genres: {
rare_terms: {
field: "genre",
missing: "N/A",
},
},
},
});
console.log(response);
嵌套、RareTerms 和评分子聚合
编辑RareTerms 聚合必须以 breadth_first 模式运行,因为它需要在超出文档计数阈值时修剪词项。此要求意味着 RareTerms 聚合与需要 depth_first 的某些聚合组合不兼容。特别是,位于 nested 内的评分子聚合会强制整个聚合树以 depth_first 模式运行。这将抛出异常,因为 RareTerms 无法处理 depth_first。
作为一个具体的例子,如果 rare_terms 聚合是 nested 聚合的子聚合,并且 rare_terms 的一个子聚合需要文档分数(如 top_hits 聚合),这将抛出异常。