教程:基于双向跨集群复制的灾难恢复
编辑教程:基于双向跨集群复制的灾难恢复
编辑了解如何基于双向跨集群复制在两个集群之间设置灾难恢复。以下教程专为支持通过查询更新和通过查询删除的数据流设计。您只能在主索引上执行这些操作。
本教程以 Logstash 作为摄取源。它利用 Logstash 的一项功能,即Logstash 到 Elasticsearch 的输出可以在指定的主机数组之间进行负载均衡。Beats 和 Elastic Agents 目前不支持多个输出。在本教程中,也可以设置代理(负载均衡器)来重定向流量,而无需使用 Logstash。
- 在
clusterA和clusterB上设置远程集群。 - 使用排除模式设置双向跨集群复制。
- 设置具有多个主机的 Logstash,以便在灾难期间实现自动负载均衡和切换。
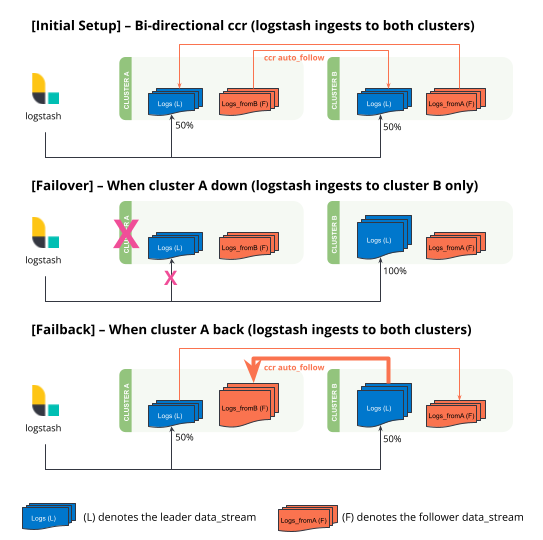
初始设置
编辑-
在两个集群上设置远程集群。
resp = client.cluster.put_settings( persistent={ "cluster": { "remote": { "clusterB": { "mode": "proxy", "skip_unavailable": True, "server_name": "clusterb.es.region-b.gcp.elastic-cloud.com", "proxy_socket_connections": 18, "proxy_address": "clusterb.es.region-b.gcp.elastic-cloud.com:9400" } } } }, ) print(resp) resp1 = client.cluster.put_settings( persistent={ "cluster": { "remote": { "clusterA": { "mode": "proxy", "skip_unavailable": True, "server_name": "clustera.es.region-a.gcp.elastic-cloud.com", "proxy_socket_connections": 18, "proxy_address": "clustera.es.region-a.gcp.elastic-cloud.com:9400" } } } }, ) print(resp1)response = client.cluster.put_settings( body: { persistent: { cluster: { remote: { "clusterB": { mode: 'proxy', skip_unavailable: true, server_name: 'clusterb.es.region-b.gcp.elastic-cloud.com', proxy_socket_connections: 18, proxy_address: 'clusterb.es.region-b.gcp.elastic-cloud.com:9400' } } } } } ) puts response response = client.cluster.put_settings( body: { persistent: { cluster: { remote: { "clusterA": { mode: 'proxy', skip_unavailable: true, server_name: 'clustera.es.region-a.gcp.elastic-cloud.com', proxy_socket_connections: 18, proxy_address: 'clustera.es.region-a.gcp.elastic-cloud.com:9400' } } } } } ) puts responseconst response = await client.cluster.putSettings({ persistent: { cluster: { remote: { clusterB: { mode: "proxy", skip_unavailable: true, server_name: "clusterb.es.region-b.gcp.elastic-cloud.com", proxy_socket_connections: 18, proxy_address: "clusterb.es.region-b.gcp.elastic-cloud.com:9400", }, }, }, }, }); console.log(response); const response1 = await client.cluster.putSettings({ persistent: { cluster: { remote: { clusterA: { mode: "proxy", skip_unavailable: true, server_name: "clustera.es.region-a.gcp.elastic-cloud.com", proxy_socket_connections: 18, proxy_address: "clustera.es.region-a.gcp.elastic-cloud.com:9400", }, }, }, }, }); console.log(response1);### On cluster A ### PUT _cluster/settings { "persistent": { "cluster": { "remote": { "clusterB": { "mode": "proxy", "skip_unavailable": true, "server_name": "clusterb.es.region-b.gcp.elastic-cloud.com", "proxy_socket_connections": 18, "proxy_address": "clusterb.es.region-b.gcp.elastic-cloud.com:9400" } } } } } ### On cluster B ### PUT _cluster/settings { "persistent": { "cluster": { "remote": { "clusterA": { "mode": "proxy", "skip_unavailable": true, "server_name": "clustera.es.region-a.gcp.elastic-cloud.com", "proxy_socket_connections": 18, "proxy_address": "clustera.es.region-a.gcp.elastic-cloud.com:9400" } } } } } -
设置双向跨集群复制。
resp = client.ccr.put_auto_follow_pattern( name="logs-generic-default", remote_cluster="clusterB", leader_index_patterns=[ ".ds-logs-generic-default-20*" ], leader_index_exclusion_patterns="*-replicated_from_clustera", follow_index_pattern="{{leader_index}}-replicated_from_clusterb", ) print(resp) resp1 = client.ccr.put_auto_follow_pattern( name="logs-generic-default", remote_cluster="clusterA", leader_index_patterns=[ ".ds-logs-generic-default-20*" ], leader_index_exclusion_patterns="*-replicated_from_clusterb", follow_index_pattern="{{leader_index}}-replicated_from_clustera", ) print(resp1)const response = await client.ccr.putAutoFollowPattern({ name: "logs-generic-default", remote_cluster: "clusterB", leader_index_patterns: [".ds-logs-generic-default-20*"], leader_index_exclusion_patterns: "*-replicated_from_clustera", follow_index_pattern: "{{leader_index}}-replicated_from_clusterb", }); console.log(response); const response1 = await client.ccr.putAutoFollowPattern({ name: "logs-generic-default", remote_cluster: "clusterA", leader_index_patterns: [".ds-logs-generic-default-20*"], leader_index_exclusion_patterns: "*-replicated_from_clusterb", follow_index_pattern: "{{leader_index}}-replicated_from_clustera", }); console.log(response1);### On cluster A ### PUT /_ccr/auto_follow/logs-generic-default { "remote_cluster": "clusterB", "leader_index_patterns": [ ".ds-logs-generic-default-20*" ], "leader_index_exclusion_patterns":"*-replicated_from_clustera", "follow_index_pattern": "{{leader_index}}-replicated_from_clusterb" } ### On cluster B ### PUT /_ccr/auto_follow/logs-generic-default { "remote_cluster": "clusterA", "leader_index_patterns": [ ".ds-logs-generic-default-20*" ], "leader_index_exclusion_patterns":"*-replicated_from_clusterb", "follow_index_pattern": "{{leader_index}}-replicated_from_clustera" }集群上的现有数据不会被
_ccr/auto_follow复制,即使模式可能匹配。此功能只会复制新创建的后备索引(作为数据流的一部分)。使用
leader_index_exclusion_patterns以避免递归。follow_index_pattern仅允许小写字符。由于 UI 中缺少排除模式,此步骤无法通过 Kibana UI 执行。请在此步骤中使用 API。
-
设置 Logstash 配置文件。
本示例使用输入生成器来演示集群中的文档计数。重新配置此部分以适应您自己的用例。
### On Logstash server ### ### This is a logstash config file ### input { generator{ message => 'Hello World' count => 100 } } output { elasticsearch { hosts => ["https://clustera.es.region-a.gcp.elastic-cloud.com:9243","https://clusterb.es.region-b.gcp.elastic-cloud.com:9243"] user => "logstash-user" password => "same_password_for_both_clusters" } }关键点是,当
cluster A宕机时,所有流量将自动重定向到cluster B。一旦cluster A恢复,流量将自动重定向回cluster A。这是通过选项hosts实现的,其中在数组[clusterA, clusterB]中指定了多个 ES 集群端点。在两个集群上为同一用户设置相同的密码,以使用此负载均衡功能。
-
使用之前的配置文件启动 Logstash。
### On Logstash server ### bin/logstash -f multiple_hosts.conf
-
观察数据流中的文档计数。
此设置会在每个集群上创建一个名为
logs-generic-default的数据流。当两个集群都启动时,Logstash 会将 50% 的文档写入cluster A,并将 50% 的文档写入cluster B。双向跨集群复制将在每个集群上创建一个附加的数据流,其后缀为
-replication_from_cluster{a|b}。在此步骤结束时-
cluster A 上的数据流包含
logs-generic-default-replicated_from_clusterb中的 50 个文档logs-generic-default中的 50 个文档
-
cluster B 上的数据流包含
logs-generic-default-replicated_from_clustera中的 50 个文档logs-generic-default中的 50 个文档
-
-
应设置查询以搜索两个数据流。在任何一个集群上对
logs*的查询总共返回 100 个命中。resp = client.search( index="logs*", size="0", ) print(resp)response = client.search( index: 'logs*', size: 0 ) puts response
const response = await client.search({ index: "logs*", size: 0, }); console.log(response);GET logs*/_search?size=0
当 clusterA 宕机时的故障转移
编辑- 您可以通过关闭其中一个集群来模拟这种情况。在本教程中,让我们关闭
cluster A。 -
使用相同的配置文件启动 Logstash。(在 Logstash 持续摄取的实际用例中,此步骤不是必需的。)
### On Logstash server ### bin/logstash -f multiple_hosts.conf
-
观察所有 Logstash 流量将自动重定向到
cluster B。您还应该在此期间将所有搜索流量重定向到
clusterB集群。 -
cluster B上的两个数据流现在包含不同数量的文档。-
cluster A (宕机)上的数据流
logs-generic-default-replicated_from_clusterb中的 50 个文档logs-generic-default中的 50 个文档
-
cluster B (启动)上的数据流
logs-generic-default-replicated_from_clustera中的 50 个文档logs-generic-default中的 150 个文档
-
当 clusterA 恢复时的故障恢复
编辑- 您可以通过重新启动
cluster A来模拟这种情况。 -
在
cluster A停机期间摄取到cluster B的数据将自动复制。-
cluster A 上的数据流
logs-generic-default-replicated_from_clusterb中的 150 个文档logs-generic-default中的 50 个文档
-
cluster B 上的数据流
logs-generic-default-replicated_from_clustera中的 50 个文档logs-generic-default中的 150 个文档
-
- 如果您此时正在运行 Logstash,您还会观察到流量被发送到两个集群。
通过查询执行更新或删除
编辑可以更新或删除文档,但您只能在主索引上执行这些操作。
-
首先确定哪个后备索引包含您要更新的文档。
resp = client.search( index="logs-generic-default*", filter_path="hits.hits._index", query={ "match": { "event.sequence": "97" } }, ) print(resp)response = client.search( index: 'logs-generic-default*', filter_path: 'hits.hits._index', body: { query: { match: { 'event.sequence' => '97' } } } ) puts responseconst response = await client.search({ index: "logs-generic-default*", filter_path: "hits.hits._index", query: { match: { "event.sequence": "97", }, }, }); console.log(response);### On either of the cluster ### GET logs-generic-default*/_search?filter_path=hits.hits._index { "query": { "match": { "event.sequence": "97" } } }- 如果命中返回
"_index": ".ds-logs-generic-default-replicated_from_clustera-<yyyy.MM.dd>-*",那么您需要在cluster A上继续执行下一步。 - 如果命中返回
"_index": ".ds-logs-generic-default-replicated_from_clusterb-<yyyy.MM.dd>-*",那么您需要在cluster B上继续执行下一步。 - 如果命中返回
"_index": ".ds-logs-generic-default-<yyyy.MM.dd>-*",那么您需要在执行搜索查询的同一集群上继续执行下一步。
- 如果命中返回
-
通过查询执行更新(或删除)
resp = client.update_by_query( index="logs-generic-default", query={ "match": { "event.sequence": "97" } }, script={ "source": "ctx._source.event.original = params.new_event", "lang": "painless", "params": { "new_event": "FOOBAR" } }, ) print(resp)response = client.update_by_query( index: 'logs-generic-default', body: { query: { match: { 'event.sequence' => '97' } }, script: { source: 'ctx._source.event.original = params.new_event', lang: 'painless', params: { new_event: 'FOOBAR' } } } ) puts responseconst response = await client.updateByQuery({ index: "logs-generic-default", query: { match: { "event.sequence": "97", }, }, script: { source: "ctx._source.event.original = params.new_event", lang: "painless", params: { new_event: "FOOBAR", }, }, }); console.log(response);### On the cluster identified from the previous step ### POST logs-generic-default/_update_by_query { "query": { "match": { "event.sequence": "97" } }, "script": { "source": "ctx._source.event.original = params.new_event", "lang": "painless", "params": { "new_event": "FOOBAR" } } }如果软删除在可以复制到关注者之前被合并掉,则由于领导者上的不完整历史记录,以下过程将失败,有关详细信息,请参阅index.soft_deletes.retention_lease.period。