跨集群复制
编辑跨集群复制
编辑通过跨集群复制,您可以跨集群复制索引,以实现以下目的:
- 在数据中心中断时继续处理搜索请求
- 防止搜索量影响索引吞吐量
- 通过在地理位置上靠近用户的位置处理搜索请求来减少搜索延迟
跨集群复制使用主动-被动模型。您将索引写入领导者索引,并且数据被复制到一个或多个只读的追随者索引。在将追随者索引添加到集群之前,您必须配置包含领导者索引的远程集群。
当领导者索引接收到写入时,追随者索引会从远程集群上的领导者索引拉取更改。您可以手动创建追随者索引,或配置自动追随模式,以自动为新的时间序列索引创建追随者索引。
您可以在单向或双向设置中配置跨集群复制集群
- 在单向配置中,一个集群仅包含领导者索引,而另一个集群仅包含追随者索引。
- 在双向配置中,每个集群都包含领导者索引和追随者索引。
在单向配置中,包含追随者索引的集群必须运行与远程集群相同或更新版本的 Elasticsearch。如果更新,则版本还必须按照以下矩阵中的概述兼容。
版本兼容性矩阵
本地集群 |
|||||||||
远程集群 |
5.0–5.5 |
5.6 |
6.0–6.6 |
6.7 |
6.8 |
7.0 |
7.1–7.16 |
7.17 |
8.0–8.17 |
5.0–5.5 |
|
|
|
|
|
|
|
|
|
5.6 |
|
|
|
|
|
|
|
|
|
6.0–6.6 |
|
|
|
|
|
|
|
|
|
6.7 |
|
|
|
|
|
|
|
|
|
6.8 |
|
|
|
|
|
|
|
|
|
7.0 |
|
|
|
|
|
|
|
|
|
7.1–7.16 |
|
|
|
|
|
|
|
|
|
7.17 |
|
|
|
|
|
|
|
|
|
8.0–8.17 |
|
|
|
|
|
|
|
|
|
多集群架构
编辑使用跨集群复制在 Elastic Stack 中构建多个多集群架构
观看跨集群复制网络研讨会,了解有关以下用例的更多信息。然后,在本地机器上设置跨集群复制,并完成网络研讨会中的演示。
灾难恢复和高可用性
编辑灾难恢复为您的关键任务应用程序提供了承受数据中心或区域中断的容错能力。此用例是跨集群复制最常见的部署。您可以在不同的架构中配置集群,以支持灾难恢复和高可用性
单个灾难恢复数据中心
编辑在此配置中,数据从生产数据中心复制到灾难恢复数据中心。由于追随者索引复制领导者索引,如果生产数据中心不可用,您的应用程序可以使用灾难恢复数据中心。

多个灾难恢复数据中心
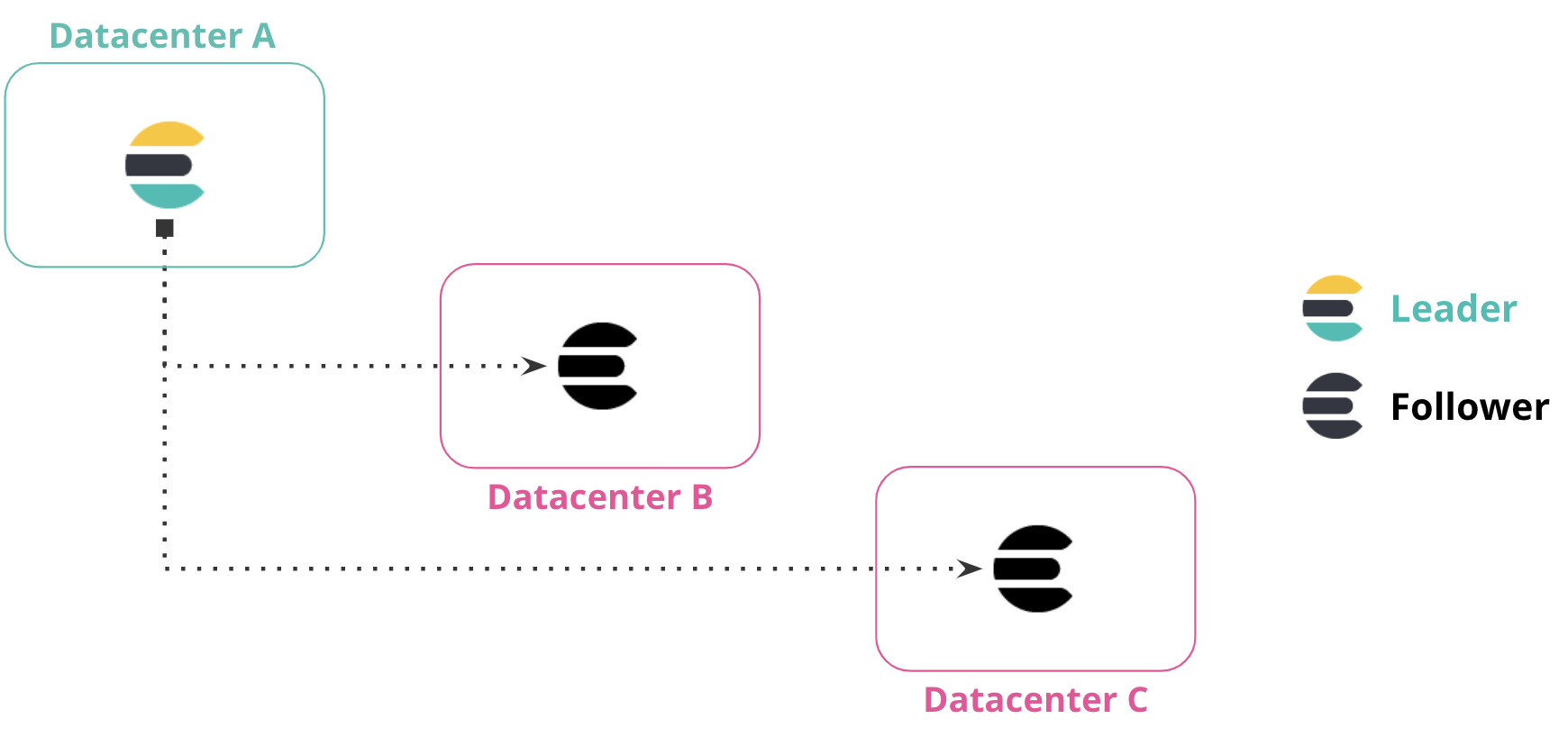
编辑您可以将数据从一个数据中心复制到多个数据中心。此配置同时提供灾难恢复和高可用性,确保在主数据中心关闭或不可用时,数据复制到两个数据中心。
在下图中,来自数据中心 A 的数据被复制到数据中心 B 和数据中心 C,这两个数据中心都具有来自数据中心 A 的领导者索引的只读副本。
链式复制
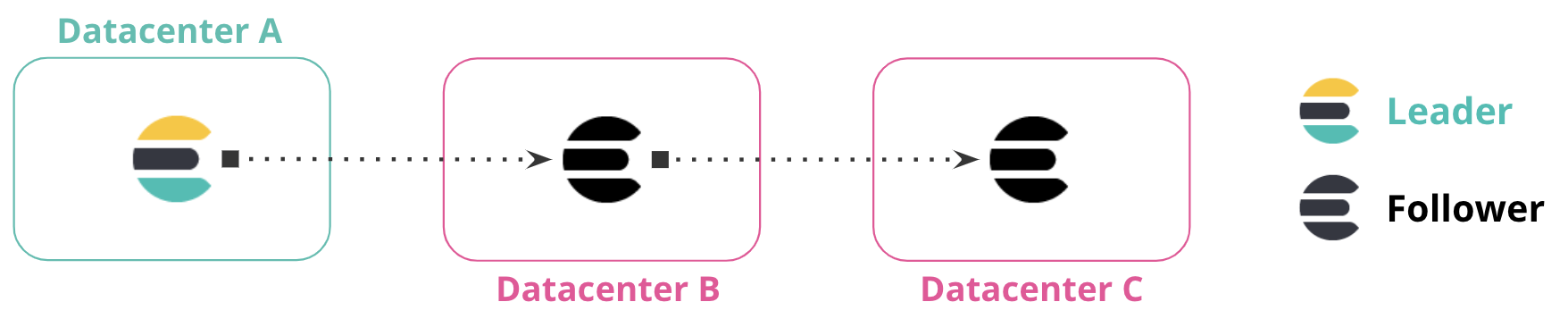
编辑您可以跨多个数据中心复制数据以形成复制链。在下图中,数据中心 A 包含领导者索引。数据中心 B 从数据中心 A 复制数据,而数据中心 C 从数据中心 B 中的追随者索引复制数据。这些数据中心之间的连接形成链式复制模式。
双向复制
编辑在双向复制设置中,所有集群都有权查看所有数据,并且所有集群都有一个用于写入的索引,而无需手动实现故障转移。应用程序可以写入每个数据中心内的本地索引,并跨多个索引读取以获得所有信息的全局视图。
当集群或数据中心不可用时,此配置不需要手动干预。在下图中,如果数据中心 A 不可用,您可以继续使用数据中心 B 而无需手动故障转移。当数据中心 A 上线时,集群之间的复制将恢复。
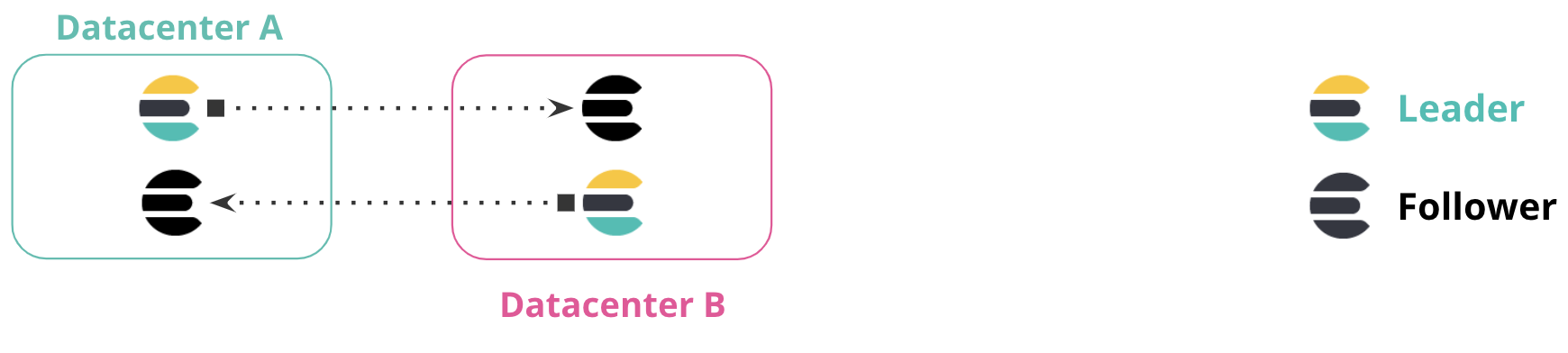
此配置对于仅索引的工作负载特别有用,其中不会发生对文档值的更新。在此配置中,Elasticsearch 索引的文档是不可变的。客户端与 Elasticsearch 集群一起位于每个数据中心中,并且不与不同数据中心中的集群通信。
数据本地性
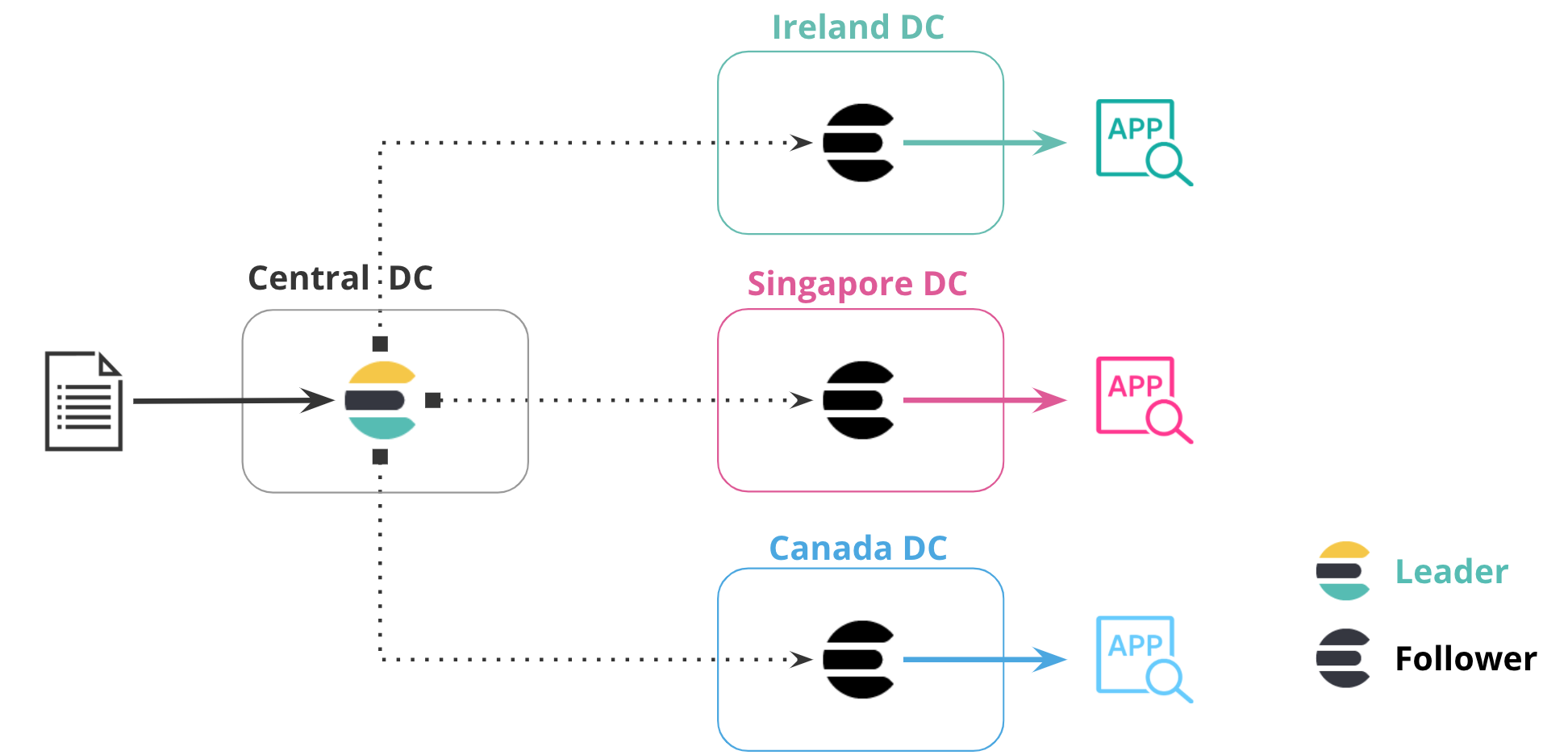
编辑使数据更靠近您的用户或应用程序服务器可以减少延迟和响应时间。此方法也适用于在 Elasticsearch 中复制数据。例如,您可以将产品目录或参考数据集复制到全球 20 个或更多数据中心,以最大限度地缩短数据与应用程序服务器之间的距离。
在下图中,数据从一个数据中心复制到其他三个数据中心,每个数据中心都位于自己的区域中。中心数据中心包含领导者索引,其他数据中心包含追随者索引,该索引复制该特定区域中的数据。此配置使数据更靠近访问它的应用程序。
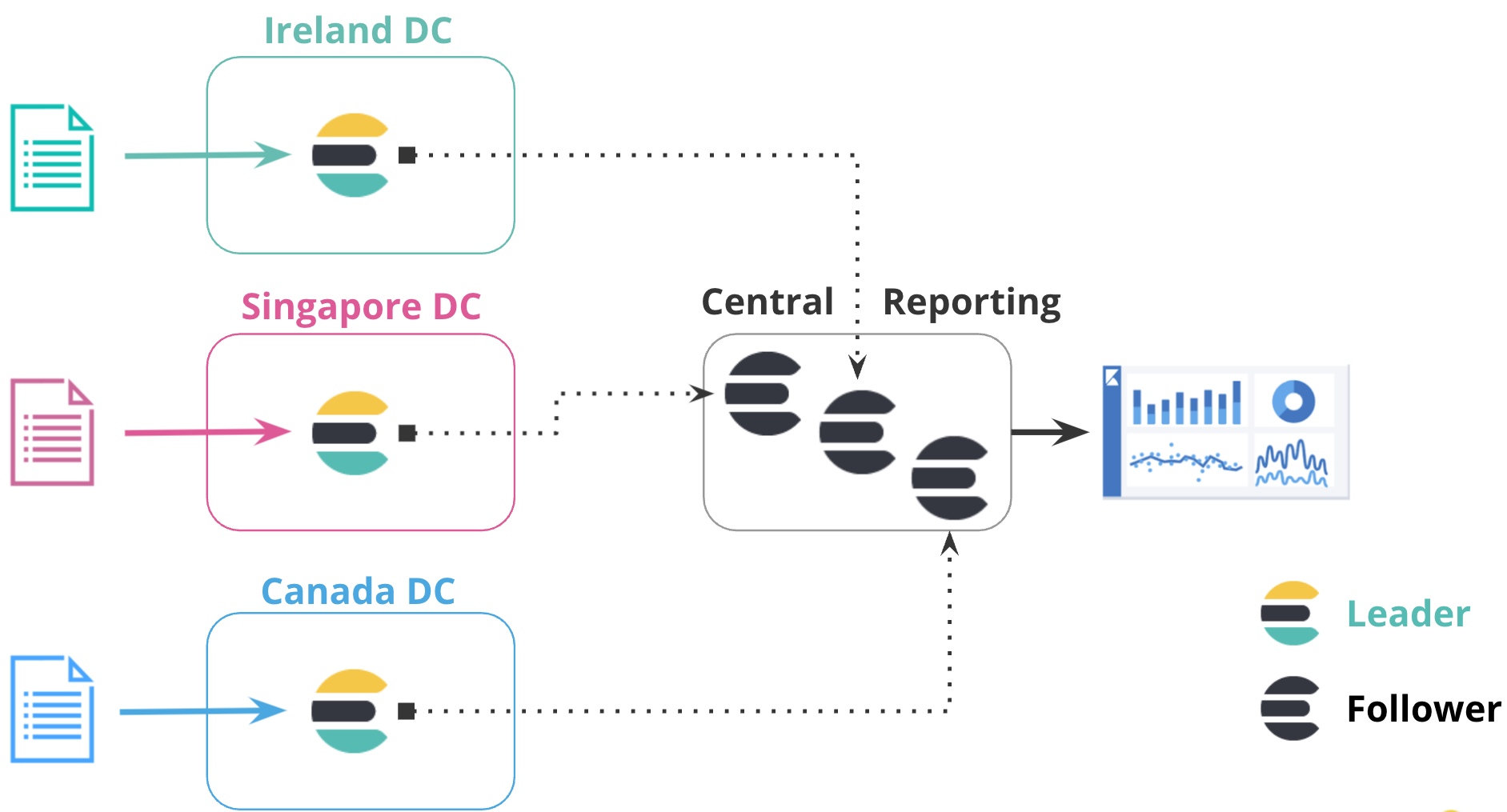
集中式报告
编辑当跨大型网络查询效率低下时,使用集中式报告集群非常有用。在此配置中,您可以将数据从许多较小的集群复制到集中式报告集群。
例如,一家大型全球银行可能在全球拥有 100 个 Elasticsearch 集群,这些集群分布在每个银行分行的不同区域。使用跨集群复制,银行可以将所有 100 家银行的事件复制到中心集群,以在本地分析和聚合事件以进行报告。银行可以使用跨集群复制来复制特定索引,而不是维护镜像集群。
在下图中,来自不同区域中三个数据中心的数据被复制到集中式报告集群。此配置使您可以将数据从区域中心复制到中心集群,您可以在其中本地运行所有报告。
复制机制
编辑虽然您可以在索引级别设置跨集群复制,但 Elasticsearch 是在分片级别实现复制的。创建追随者索引时,该索引中的每个分片都会从领导者索引中其对应的分片拉取更改,这意味着追随者索引具有与其领导者索引相同数量的分片。领导者上的所有操作都由追随者复制,例如创建、更新或删除文档的操作。这些请求可以从领导者分片的任何副本(主分片或副本)提供。
当追随者分片发送读取请求时,领导者分片会响应任何新的操作,但受您在配置追随者索引时建立的读取参数限制。如果没有新的操作可用,领导者分片将等待最长配置的超时时间以获取新的操作。如果超时时间过去,领导者分片将响应追随者分片,表明没有新的操作。追随者分片会更新分片统计信息,并立即向领导者分片发送另一个读取请求。此通信模型可确保远程集群和本地集群之间的网络连接持续使用,从而避免外部源(如防火墙)强制终止。
如果读取请求失败,则会检查失败的原因。如果确定失败的原因是可以恢复的(例如网络故障),则追随者分片将进入重试循环。否则,追随者分片将暂停,直到您恢复它。
处理更新
编辑您不能手动修改追随者索引的映射或别名。要进行更改,您必须更新领导者索引。由于它们是只读的,因此追随者索引在所有配置中都拒绝写入。
虽然对领导者索引上的别名的更改会复制到追随者索引,但写入索引会被忽略。追随者索引不能接受直接写入,因此如果任何领导者别名将 is_write_index 设置为 true,则该值将被强制设置为 false。
例如,您在数据中心 A 中索引了一个名为 doc_1 的文档,该文档复制到数据中心 B。如果客户端连接到数据中心 B 并尝试更新 doc_1,则请求将失败。要更新 doc_1,客户端必须连接到数据中心 A 并更新领导者索引中的文档。
当追随者分片从领导者分片接收操作时,它会将这些操作放入写入缓冲区。追随者分片使用写入缓冲区中的操作提交批量写入请求。如果写入缓冲区超过其配置的限制,则不会发送其他读取请求。此配置提供了针对读取请求的背压,允许追随者分片在写入缓冲区不再满时恢复发送读取请求。
要管理如何从领导者索引复制操作,您可以在创建追随者索引时配置设置。
领导者索引上索引映射的更改会尽快复制到追随者索引。对于索引设置也是如此,除了某些本地于领导者索引的设置。例如,更改领导者索引上的副本数不会由追随者索引复制,因此可能无法检索该设置。
如果您将追随者索引需要的非动态设置更改应用于领导者索引,则追随者索引将自行关闭、应用设置更新,然后重新打开自身。在此循环期间,追随者索引不可用于读取,并且无法复制写入。
使用远程恢复初始化追随者
编辑创建追随者索引时,您必须等到它完全初始化才能使用它。远程恢复过程通过从领导者集群中的主分片复制数据,在追随者节点上构建分片的新副本。
Elasticsearch 使用此远程恢复过程,利用主索引中的数据来引导从属索引。即使由于 Lucene 段合并导致主索引上无法获得完整的更改历史记录,此过程也会为从属索引提供主索引当前状态的副本。
远程恢复是一个网络密集型过程,它将所有 Lucene 段文件从主集群传输到从属集群。从属集群请求在主集群中的主分片上启动恢复会话。然后,从属集群同时从主集群请求文件块。默认情况下,该过程会同时请求五个 1MB 的文件块。此默认行为旨在支持主集群和从属集群之间具有高网络延迟的情况。
您可以修改动态的远程恢复设置,以限制传输的数据速率并管理远程恢复消耗的资源。
使用包含从属索引的集群上的恢复 API 来获取有关正在进行的远程恢复的信息。由于 Elasticsearch 使用快照和还原基础架构来实现远程恢复,因此在恢复 API 中,正在运行的远程恢复被标记为 snapshot 类型。
复制主索引需要软删除
编辑跨集群复制的工作原理是重放对主索引分片执行的单个写入操作的历史记录。Elasticsearch 需要在主分片上保留这些操作的历史记录,以便从属分片任务可以提取它们。用于保留这些操作的底层机制是软删除。
每当删除或更新现有文档时,就会发生软删除。通过将这些软删除保留到可配置的限制,操作的历史记录可以保留在主分片上,并提供给从属分片任务,以便重放操作的历史记录。
index.soft_deletes.retention_lease.period 设置定义了在分片历史记录保留租约被视为过期之前的最大保留时间。此设置决定了包含从属索引的集群可以离线的时间,默认情况下为 12 小时。如果分片副本在其保留租约过期后恢复,但主索引上仍然可以获得丢失的操作,则 Elasticsearch 将建立新的租约并复制丢失的操作。但是,Elasticsearch 不保证保留未租用的操作,因此也有可能主索引已丢弃了一些丢失的操作,并且现在完全不可用。如果发生这种情况,则从属索引无法自动恢复,因此您必须重新创建它。
对于要用作主索引的索引,必须启用软删除。默认情况下,在 Elasticsearch 7.0.0 或更高版本上创建的新索引上启用软删除。
跨集群复制不能用于使用 Elasticsearch 7.0.0 或更早版本创建的现有索引,在这些索引中,软删除被禁用。您必须将数据重新索引到启用了软删除的新索引中。
使用跨集群复制
编辑以下部分提供了有关如何配置和使用跨集群复制的更多信息
跨集群复制的限制
编辑跨集群复制旨在仅复制用户生成的索引,并且目前不复制以下任何内容
如果要复制任何这些数据,则必须手动将其复制到远程集群。
可搜索快照索引的数据存储在快照存储库中。跨集群复制不会完全复制这些索引,即使它们在 Elasticsearch 节点上部分或完全缓存。为了在远程集群中实现可搜索的快照,请在远程集群上配置快照存储库,并使用本地集群中相同的索引生命周期管理策略将数据移动到远程集群中的冷层或冻结层。