

基础设施监控
全面且现代的基础设施监控
无缝监控您的基础设施,支持 200 多个集成,包括 AWS、Microsoft Azure 和 Google Cloud 等云平台。高效存储高基数的日志和指标,通过直观的可视化和快速分析,并在开箱即用的机器学习和预配置的仪表板的支持下,更快地进行故障排除。
简化大规模基础设施监控
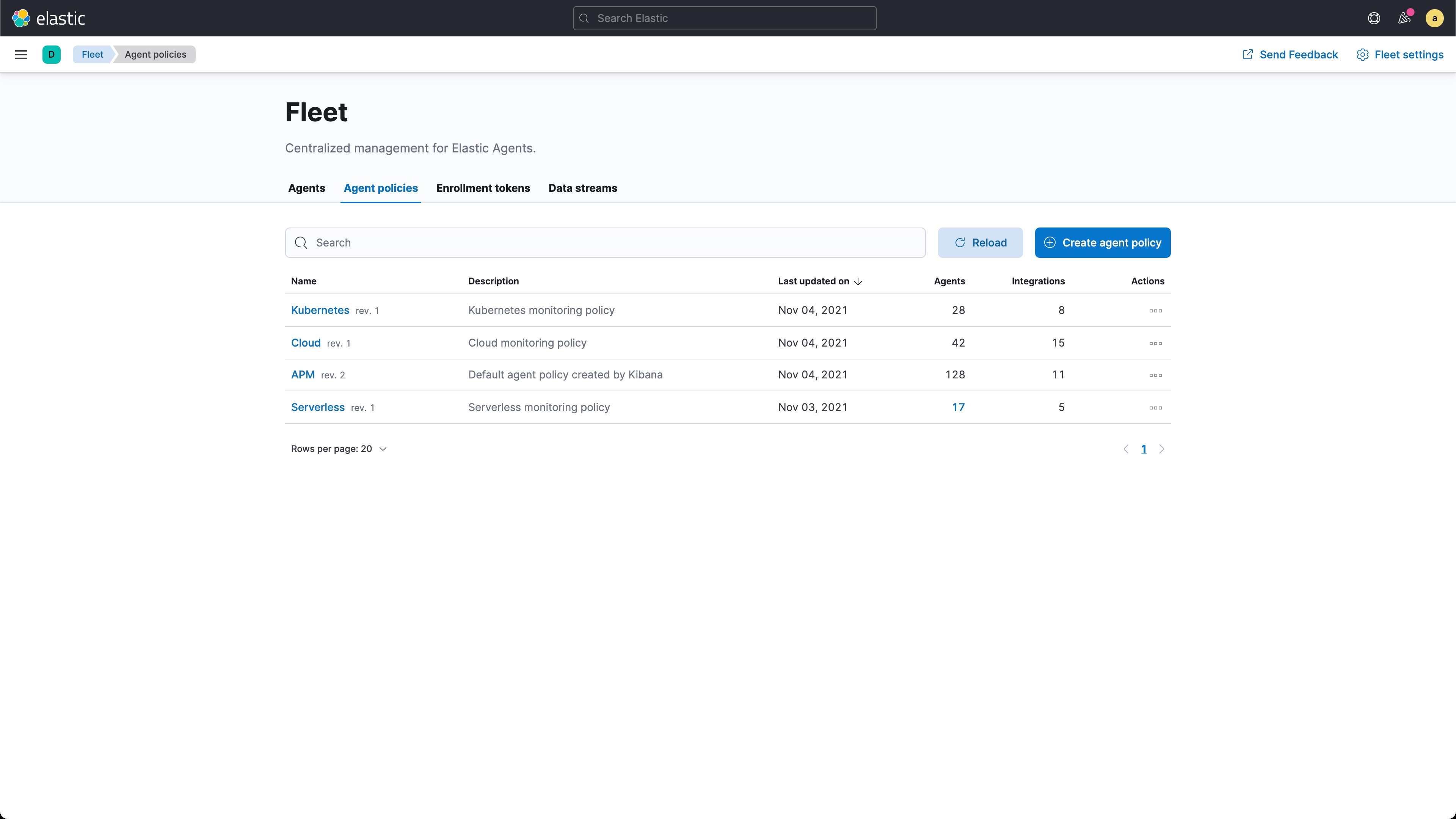
具有集中管理 (Fleet) 的统一 Elastic Agent 简化了日志、指标和所有其他监控数据的收集和管理。只需单击一下,即可部署代理、更新代理配置以及为新数据源添加集成。
全面了解所有基础设施性能
基于强大的 Elasticsearch 构建,通过原生 Elastic 集成或 Fluentd 等常见数据发送器,从您的系统、云、网络和其他基础设施来源(如 AWS、Azure、GCP、Kafka 和 NGINX)流式传输和扩展基础设施指标。将来自 Prometheus 的基础设施指标与您的日志、跟踪和最终用户监控数据统一起来,以实现完整的端到端可见性。
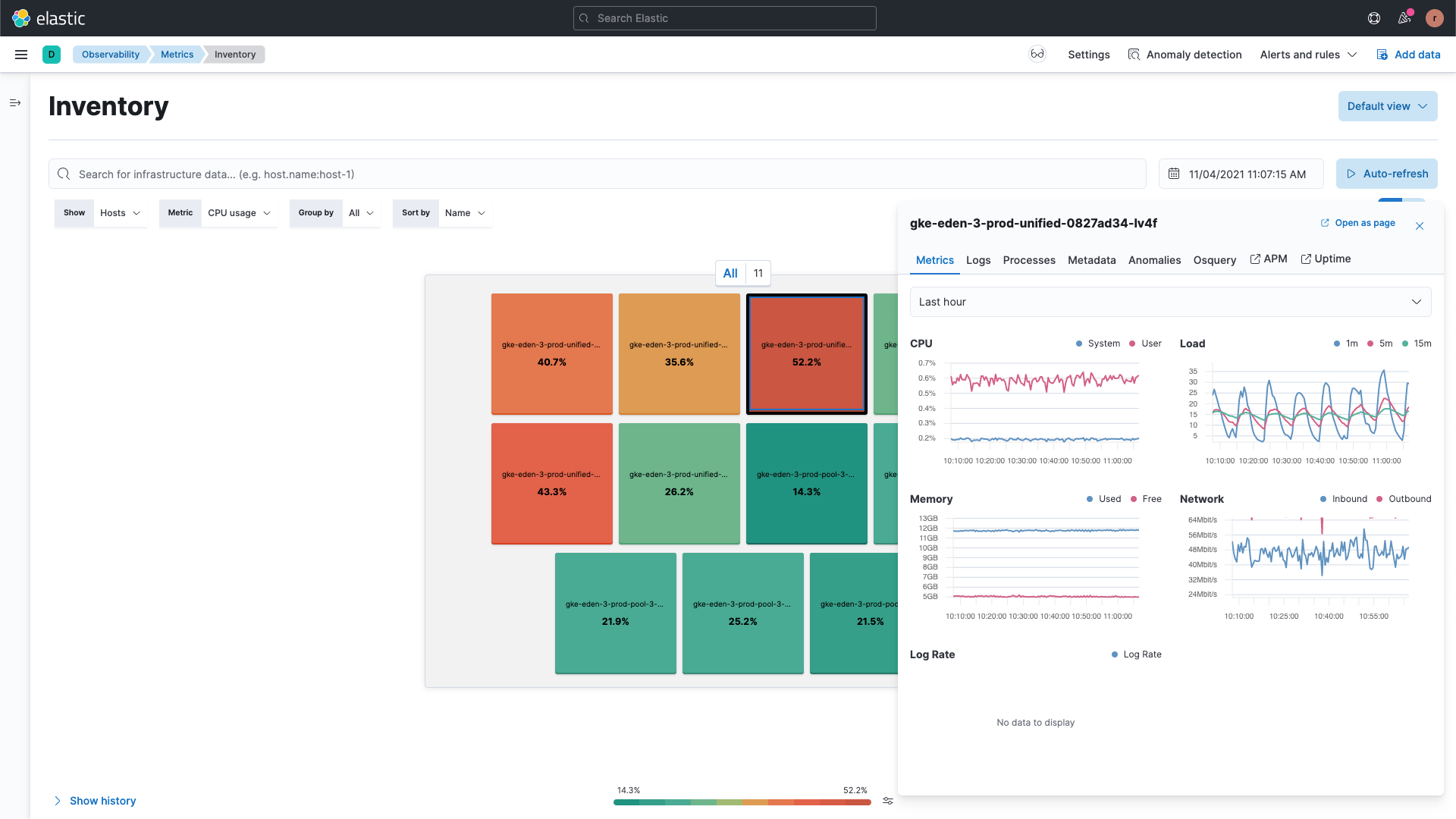
使用高级可视化精确定位全栈问题
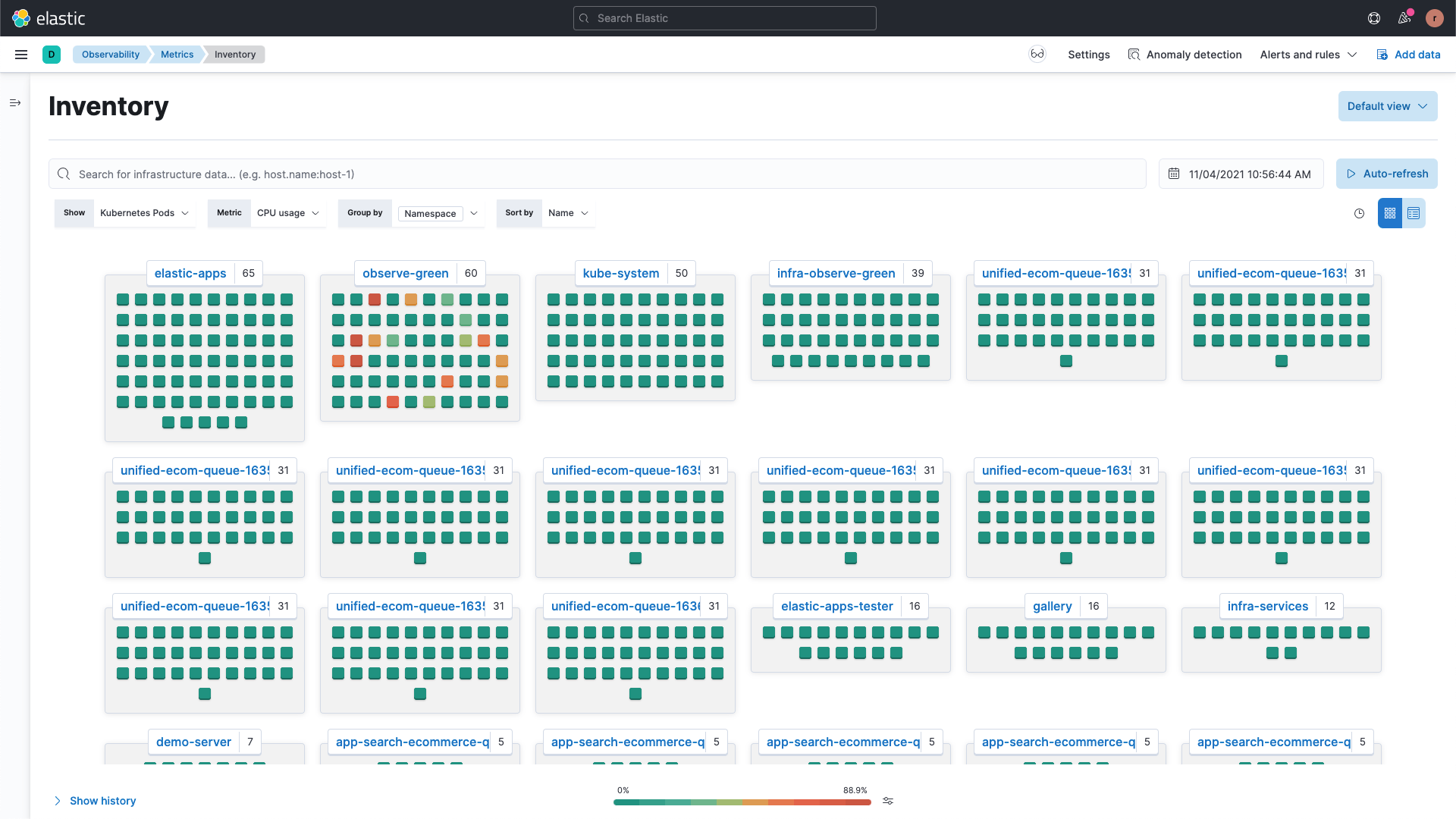
获取基础设施拓扑的逻辑和物理视图。分析每个基础设施组件的当前和历史性能趋势,包括上下文中的日志、进程、应用程序性能、异常和元数据。
找到“未知的未知”
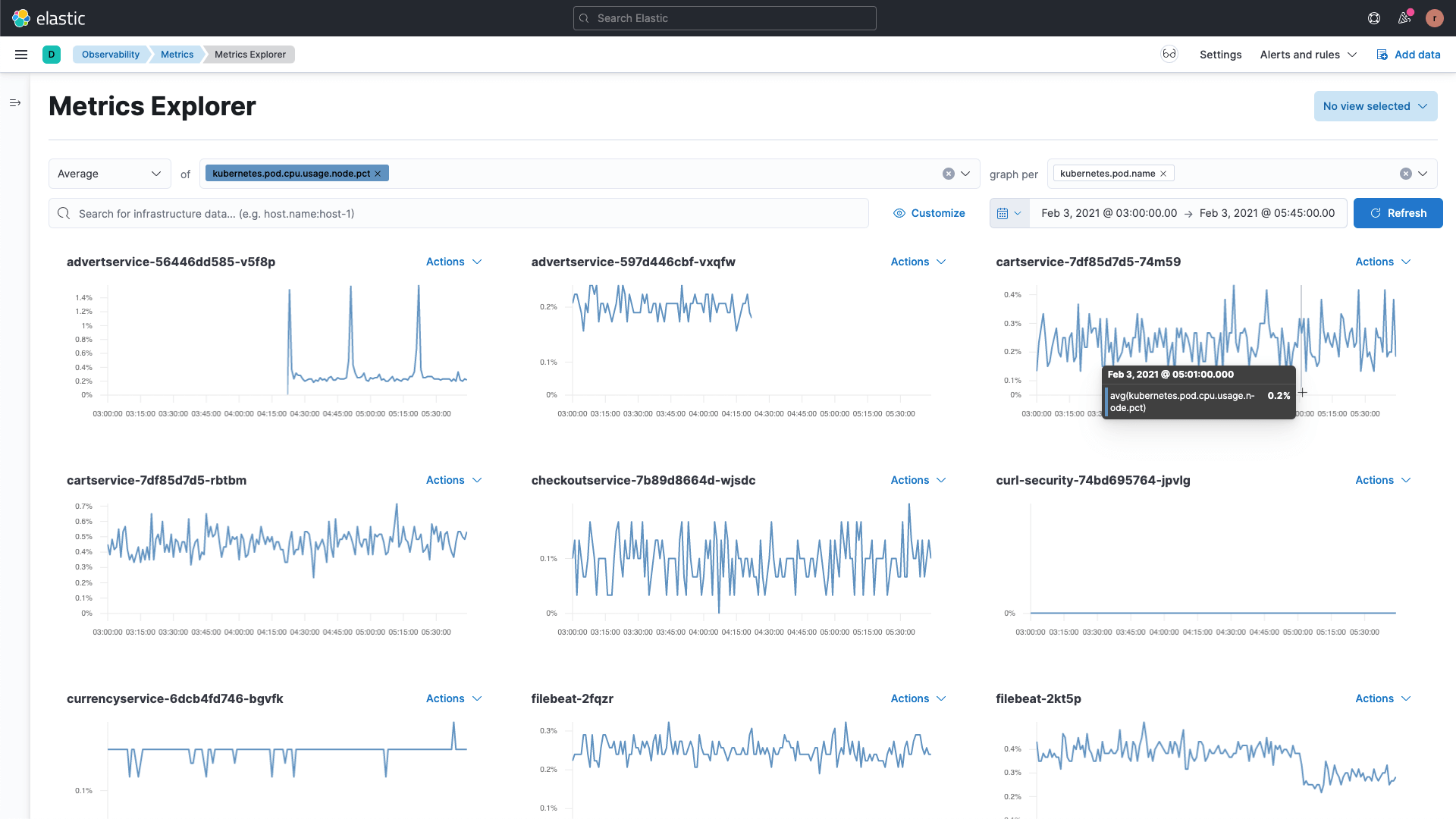
使用无限的维度和基数,在 Elastic 强大的搜索平台中探索所有监控数据,以加快故障排除速度。通过主机名、IP 地址和标签快速浏览属性。以您喜欢的任何方式自定义结果和可视化效果,以帮助您调查性能问题。
打破应用程序和基础设施孤岛,更快地检测根本原因
使用元数据丰富日志条目,以便您可以根据上下文探索问题。识别基础设施数据中的有意义的趋势,并将其与其他来源(如日志和跟踪)相关联。通过加快问题解决时间,推动协作并提高团队效率。
基础设施监控只是观察应用程序的一种方式
在单一解决方案 - Elastic Observability 中监控您的应用程序、日志和用户。

