

试用此自定进度的动手学习,了解如何构建 RAG 应用程序。
试用动手学习将 RAG 构建到您的应用程序中,并使用向量数据库尝试不同的 LLM。
在 Elasticsearch 实验室中发现更多了解如何使用 Elasticsearch Relevance Engine™ 构建基于 RAG 的高级应用程序。
观看快速入门视频Elastic 的优势
为企业规模生产做好准备



财富 500 强企业信赖,推动生成式 AI 创新





让您的数据为 RAG 做好准备
RAG 通过访问相关的专有数据而无需重新训练来扩展 LLM 的功能。将 RAG 与 Elastic 一起使用时,您将受益于
- 前沿的搜索技术
- 轻松的模型选择和轻松切换模型的能力
- 安全的文档和基于角色的访问,以确保您的数据保持受保护
转变搜索体验
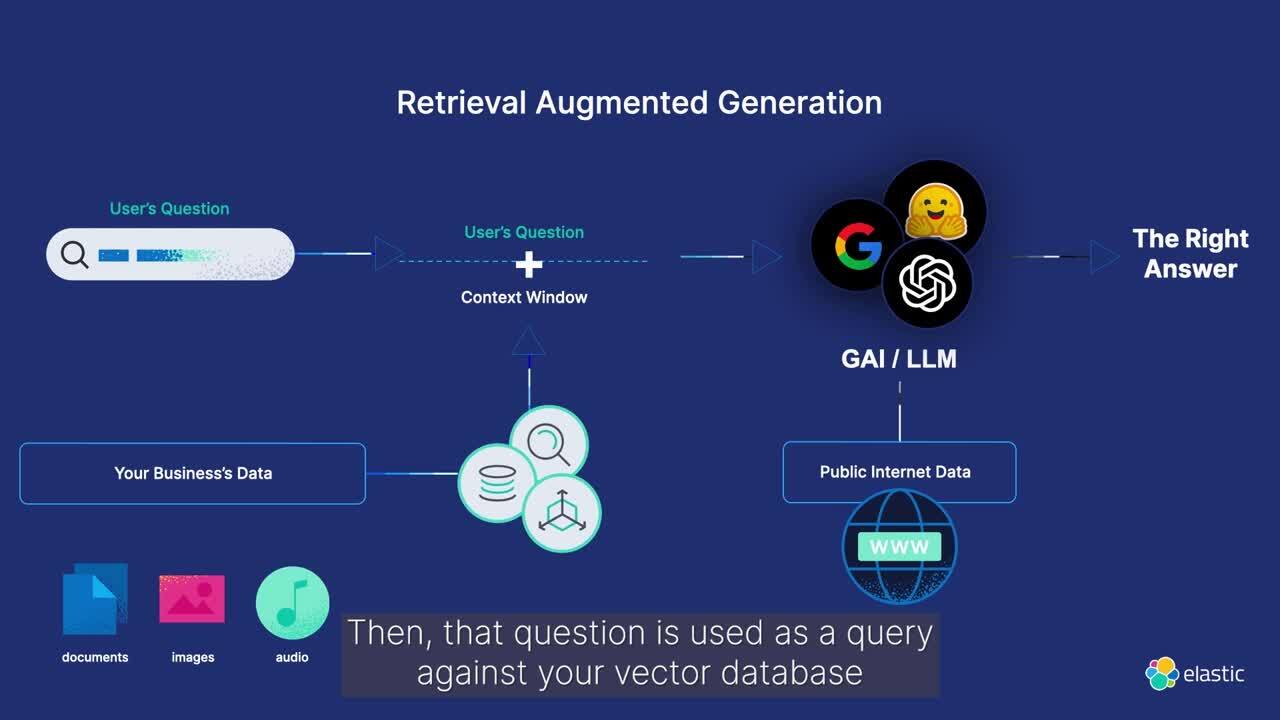
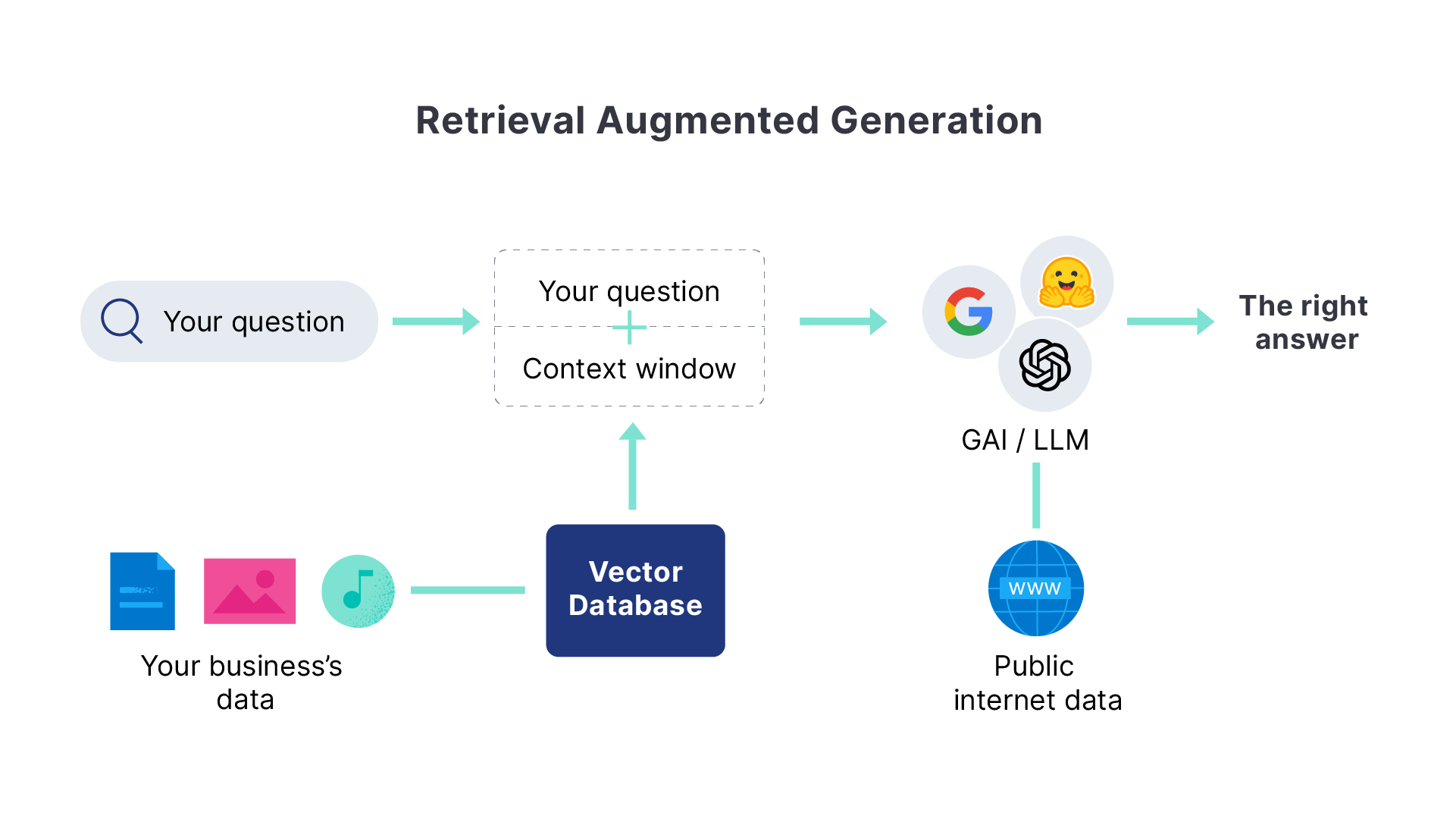
什么是检索增强生成?
检索增强生成 (RAG) 是一种模式,它通过集成来自专有数据源的相关信息来增强文本生成。通过向生成模型提供特定领域的上下文,RAG 提高了生成的文本响应的准确性和相关性。
使用 Elasticsearch 获取基于专有数据的高相关性上下文窗口,以改进 LLM 输出并在安全高效的对话体验中交付信息。
RAG 如何与 ELASTIC 协同工作
使用 Elasticsearch 增强您的 RAG 工作流程
了解如何使用 Elastic 进行 RAG 工作流程可增强生成式 AI 体验。使用专有数据源轻松同步到实时信息,以获得最佳、最相关的生成式 AI 响应。
机器学习推理管道使用 Elasticsearch 摄取处理器来有效地提取嵌入。它无缝结合了文本 (BM25 匹配) 和向量 (kNN) 搜索,检索用于上下文感知响应生成的得分最高的文档。
用例
在您的私有数据集上运行的问答服务
使用 RAG(由 Elasticsearch 作为向量数据库提供支持)实施问答体验。

AI 搜索 — 正在运行
客户聚焦

Consensus 通过 Elastic 的高级语义搜索和 AI 工具升级了学术研究平台。
客户聚焦

思科在 Google Cloud 上使用 Elastic 创建 AI 驱动的搜索体验。
客户聚焦

佐治亚州立大学增加了数据洞察力,并探索使用 AI 驱动的搜索来帮助学生申请经济援助。
常见问题
检索增强生成(通常称为 RAG)是一种自然语言处理模式,使企业能够搜索专有数据源并提供支持大型语言模型的上下文。这使得在生成式 AI 应用程序中实现更准确的实时响应。
当最佳实施时,RAG 可以实时安全地访问相关的、特定领域的专有数据。它可以减少生成式 AI 应用程序中出现幻觉的情况,并提高响应的精度。
RAG 是一项复杂的技术,它依赖于
- 输入其中的数据质量
- 搜索检索的有效性
- 数据安全
- 引用生成式 AI 响应的来源以微调结果的能力
此外,在快速发展的生态系统中选择合适的生成式 AI 或大型语言模型 (LLM) 可能对组织构成挑战。而且,与 RAG 相关的成本、性能和可扩展性可能会阻碍企业将应用程序投入生产的速度。
Elasticsearch 是一个灵活的 AI 平台和向量数据库,可以索引和存储来自任何来源的结构化和非结构化数据。它提供高效且可定制的信息检索以及跨数十亿文档的自动向量化。它还提供企业级安全性,包括角色和文档级访问控制。Elastic 还为访问不断扩展的 GenAI 生态系统中的创新提供标准接口,包括超大规模计算、模型存储库和框架。最后,Elastic 已在生产规模环境中得到验证,为超过 50% 的财富 500 强企业提供服务。了解如何使用 Playground 在 Elastic 中构建 RAG 系统。
Elastic 提供跨集群搜索 (CCS) 和跨集群复制 (CCR),帮助您管理和保护跨私有、本地和云环境的数据。通过 CCS 和 CCR,您可以
- 确保高可用性
- 遵守全球数据保护法规
- 实现数据隐私和主权
- 建立有效的灾难恢复策略
Elastic 还提供基于角色和文档级别的访问控制,授权客户和员工仅接收他们有权访问的数据的响应。我们的用户还可以通过对任何部署进行全面的可观测性和监控来获得洞察。

