读写文档
编辑读写文档
编辑简介
编辑Elasticsearch 中的每个索引都划分为分片,每个分片可以有多个副本。这些副本被称为复制组,当添加或删除文档时,必须保持同步。如果我们未能这样做,从一个副本读取的结果将与从另一个副本读取的结果大相径庭。保持分片副本同步并从它们提供读取的过程就是我们所说的数据复制模型。
Elasticsearch 的数据复制模型基于主-备模型,并且在微软研究院的 PacificA 论文 中得到了很好的描述。该模型基于复制组中有一个副本充当主分片。其他副本称为副本分片。主分片充当所有索引操作的主要入口点。它负责验证它们并确保它们正确。一旦索引操作被主分片接受,主分片还负责将操作复制到其他副本。
本节的目的是对 Elasticsearch 复制模型进行高级概述,并讨论它对写入和读取操作之间各种交互的影响。
基本写入模型
编辑Elasticsearch 中的每个索引操作首先使用 路由(通常基于文档 ID)解析为复制组。一旦确定了复制组,该操作将在内部转发到该组当前的主分片。索引的这个阶段称为协调阶段。
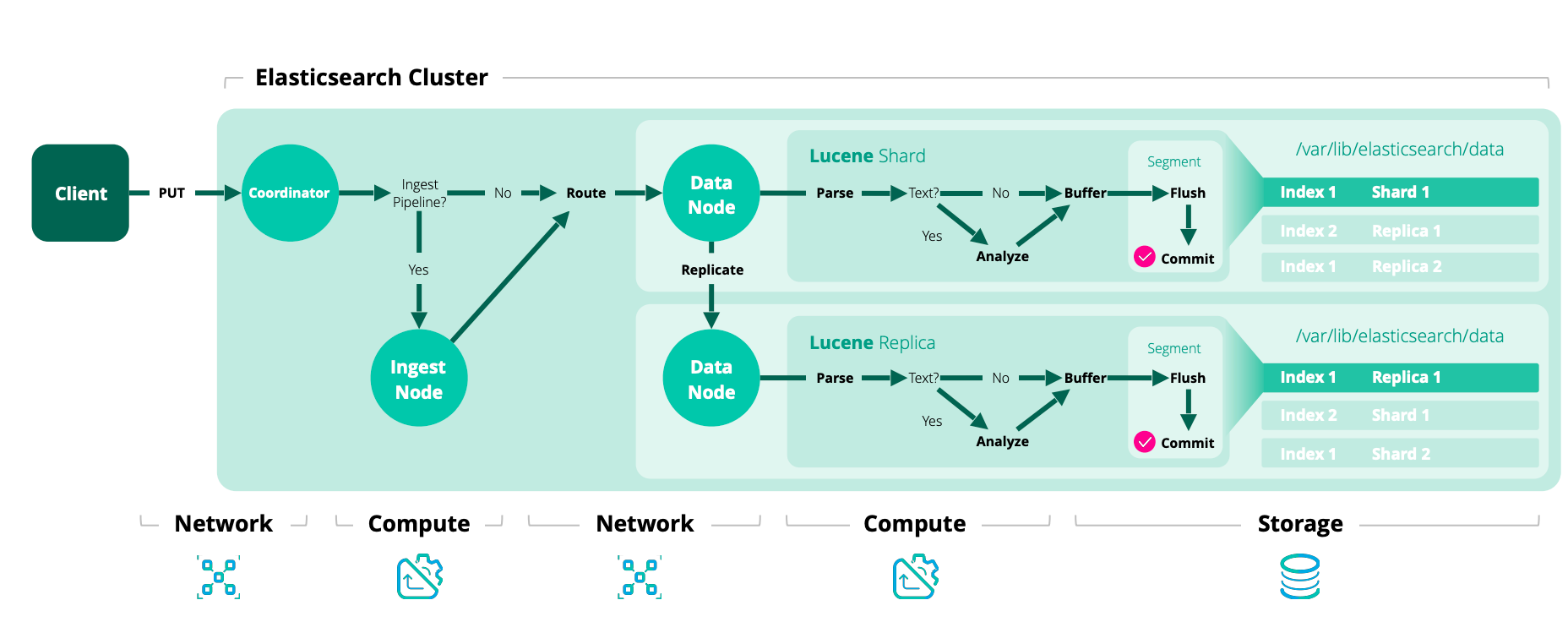
索引的下一个阶段是主阶段,在主分片上执行。主分片负责验证操作并将其转发到其他副本。由于副本可能处于脱机状态,因此不需要主分片复制到所有副本。相反,Elasticsearch 维护一个应该接收该操作的分片副本列表。此列表称为同步副本,由主节点维护。顾名思义,这些是“良好”的分片副本集,保证已经处理了已向用户确认的所有索引和删除操作。主分片负责维护此不变性,因此必须将所有操作复制到此集合中的每个副本。
主分片遵循以下基本流程
- 验证传入的操作,如果结构无效则拒绝它(示例:在预期数字的地方有一个对象字段)
- 在本地执行操作,即索引或删除相关文档。这也将验证字段的内容,并在需要时拒绝(示例:关键字值对于在 Lucene 中索引来说太长)。
- 将操作转发到当前同步副本集中的每个副本。如果有多个副本,则并行执行此操作。
- 一旦所有同步副本都成功执行了操作并响应了主分片,主分片就会向客户端确认请求已成功完成。
每个同步副本在本地执行索引操作,以便它有一个副本。索引的这个阶段是副本阶段。
这些索引阶段(协调、主和副本)是顺序的。为了启用内部重试,每个阶段的生命周期都包含每个后续阶段的生命周期。例如,只有当每个主阶段(可能分布在不同的主分片中)都完成后,协调阶段才算完成。每个主阶段只有在同步副本在本地完成文档索引并响应副本请求后才会完成。
故障处理
编辑在索引期间可能会出现很多问题——磁盘可能会损坏,节点可能会彼此断开连接,或者某些配置错误可能会导致操作在副本上失败,尽管它在主分片上是成功的。这些情况不常见,但主分片必须对其做出响应。
如果主分片本身发生故障,则托管主分片的节点会向主节点发送有关它的消息。索引操作将等待(默认为 1 分钟,通过 默认设置),以便主节点将其中一个副本提升为新的主分片。然后,该操作将被转发到新的主分片进行处理。请注意,主节点还会监控节点的运行状况,并可能决定主动降级主分片。当持有主分片的节点因网络问题与集群隔离时,通常会发生这种情况。有关更多详细信息,请参阅 此处。
一旦操作在主分片上成功执行,主分片必须处理在副本分片上执行时可能出现的故障。这可能是由于副本上的实际故障或由于网络问题导致操作无法到达副本(或阻止副本响应)。所有这些都具有相同的最终结果:作为同步副本集一部分的副本遗漏了一个即将被确认的操作。为了避免违反不变性,主分片向主节点发送一条消息,请求将有问题的分片从同步副本集中删除。只有在主节点确认删除分片后,主分片才会确认该操作。请注意,主节点还会指示另一个节点开始构建新的分片副本,以便将系统恢复到健康状态。
在将操作转发到副本时,主分片将使用副本验证它是否仍然是活动的主分片。如果主分片由于网络分区(或长时间的 GC)而隔离,它可能会在意识到自己已被降级之前继续处理传入的索引操作。来自过时主分片的操作将被副本拒绝。当主分片收到来自副本的响应,因为它不再是主分片而拒绝其请求时,它将联系主节点,并得知它已被替换。然后,该操作将路由到新的主分片。
基本读取模型
编辑Elasticsearch 中的读取可以是轻量级的按 ID 查找,也可以是具有复杂聚合的繁重搜索请求,需要大量的 CPU 功率。主备模型的优点之一是,它使所有分片副本保持相同(除了正在进行的操作)。因此,单个同步副本足以服务读取请求。
当节点收到读取请求时,该节点负责将其转发到持有相关分片的节点,整理响应并响应客户端。我们将该节点称为该请求的协调节点。基本流程如下
- 将读取请求解析为相关分片。请注意,由于大多数搜索将发送到一个或多个索引,因此它们通常需要从多个分片读取,每个分片代表不同的数据子集。
- 从分片复制组中选择每个相关分片的活动副本。这可以是主分片或副本。默认情况下,Elasticsearch 使用自适应副本选择来选择分片副本。
- 将分片级别读取请求发送到所选副本。
- 合并结果并响应。请注意,在按 ID 查找的情况下,只有一个分片是相关的,因此可以跳过此步骤。
分片故障
编辑当分片未能响应读取请求时,协调节点会将请求发送到同一复制组中的另一个分片副本。重复的故障可能会导致没有可用的分片副本。
为了确保快速响应,如果一个或多个分片失败,以下 API 将以部分结果响应
包含部分结果的响应仍然提供 200 OK HTTP 状态代码。分片故障由响应标头的 timed_out 和 _shards 字段指示。
一些简单的含义
编辑这些基本流程中的每一个都决定了 Elasticsearch 作为读写系统的行为方式。此外,由于读写请求可以并发执行,因此这两个基本流程会相互交互。这有一些固有的含义
- 高效的读取
- 在正常操作下,每个读取操作对于每个相关的复制组执行一次。只有在发生故障的情况下,同一分片的多个副本才会执行相同的搜索。
- 读取未确认
- 由于主分片先在本地建立索引,然后再复制请求,因此并发读取有可能在变更被确认之前就已看到该变更。
- 默认两份副本
- 此模型可以在仅维护两份数据副本的情况下实现容错。这与基于仲裁的系统形成对比,后者容错所需的最小副本数为 3。
故障
编辑在发生故障的情况下,可能会出现以下情况
- 单个分片可能会减慢索引速度
- 由于主分片在每次操作期间都会等待同步副本集中的所有副本,因此单个慢分片可能会减慢整个复制组的速度。这是我们为上述读取效率付出的代价。当然,单个慢分片也会减慢路由到它的不幸搜索。
- 脏读
- 隔离的主分片可能会暴露未被确认的写入。这是因为隔离的主分片只有在向其副本发送请求或联系主节点时才会意识到自己被隔离。此时,该操作已索引到主分片中,并且可以被并发读取读取。Elasticsearch 通过每秒(默认)ping 主节点,并在未知主节点时拒绝索引操作来缓解此风险。
冰山一角
编辑本文档提供了 Elasticsearch 如何处理数据的高级概述。当然,底层还有更多内容。诸如主项、集群状态发布和主节点选举之类的因素都在确保系统正常运行方面发挥作用。本文档也没有涵盖已知且重要的错误(包括已关闭和未关闭的)。我们意识到 GitHub 很难跟上。为了帮助人们及时了解这些信息,我们在我们的网站上维护了一个专门的 弹性页面。我们强烈建议您阅读它。