教程:使用 ILM 自动化滚动更新
编辑教程:使用 ILM 自动化滚动更新
编辑当您持续将带有时间戳的文档索引到 Elasticsearch 中时,通常会使用数据流,以便您可以定期滚动更新到新索引。这使您可以实现热-温-冷架构,以满足您对最新数据的性能要求,控制随着时间的推移产生的成本,执行保留策略,并充分利用您的数据。
数据流最适合仅追加用例。如果您需要更新或删除现有时间序列数据,则可以直接对数据流的后备索引执行更新或删除操作。如果您经常使用相同的 _id 发送多个文档,期望最后写入获胜,则可能需要使用带有写入索引的索引别名。您仍然可以使用 ILM 来管理和滚动更新别名的索引。请跳至在没有数据流的情况下管理时间序列数据。
使用数据流管理时间序列数据
编辑要使用 ILM 自动化数据流的滚动更新和管理,您需要:
当您为 Beats 或 Logstash Elasticsearch 输出插件启用索引生命周期管理时,会自动设置生命周期策略。您无需执行任何其他操作。您可以通过Kibana 管理或 ILM API 修改默认策略。
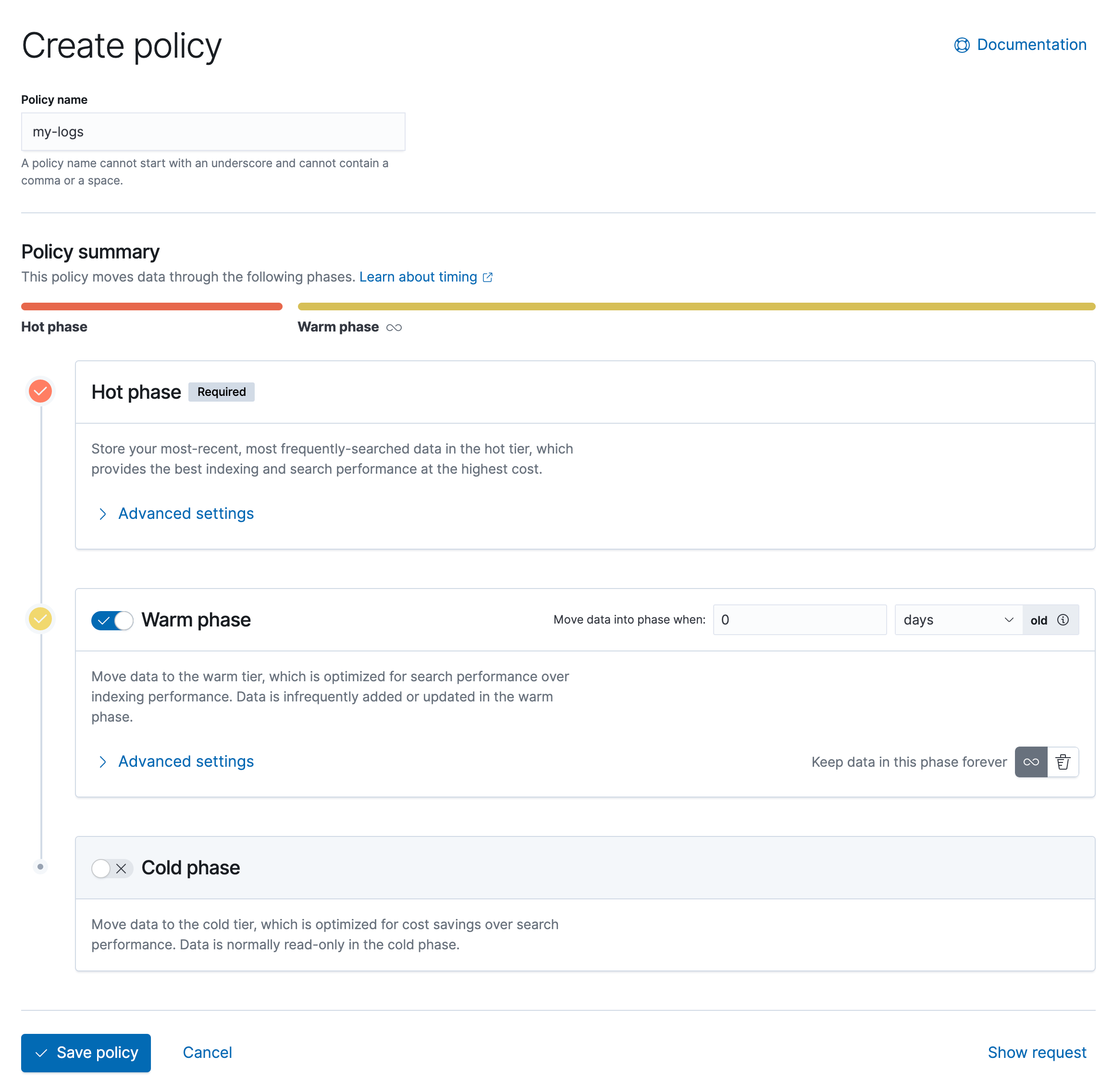
创建生命周期策略
编辑生命周期策略指定索引生命周期中的阶段以及在每个阶段中执行的操作。一个生命周期最多可以有五个阶段:hot、warm、cold、frozen 和 delete。
例如,您可以定义一个具有两个阶段的 timeseries_policy:
- 一个
hot阶段,定义一个滚动更新操作,以指定当索引达到 50 千兆字节的max_primary_shard_size或 30 天的max_age时,索引将滚动更新。 - 一个
delete阶段,将min_age设置为在滚动更新后 90 天删除索引。
min_age 值相对于滚动更新时间,而不是索引创建时间。了解更多。
您可以通过 Kibana 或使用创建或更新策略 API 来创建策略。要从 Kibana 创建策略,请打开菜单并转到 堆栈管理 > 索引生命周期策略。点击 创建策略。
API 示例
resp = client.ilm.put_lifecycle(
name="timeseries_policy",
policy={
"phases": {
"hot": {
"actions": {
"rollover": {
"max_primary_shard_size": "50GB",
"max_age": "30d"
}
}
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
},
)
print(resp)
response = client.ilm.put_lifecycle(
policy: 'timeseries_policy',
body: {
policy: {
phases: {
hot: {
actions: {
rollover: {
max_primary_shard_size: '50GB',
max_age: '30d'
}
}
},
delete: {
min_age: '90d',
actions: {
delete: {}
}
}
}
}
}
)
puts response
const response = await client.ilm.putLifecycle({
name: "timeseries_policy",
policy: {
phases: {
hot: {
actions: {
rollover: {
max_primary_shard_size: "50GB",
max_age: "30d",
},
},
},
delete: {
min_age: "90d",
actions: {
delete: {},
},
},
},
},
});
console.log(response);
创建索引模板以创建数据流并应用生命周期策略
编辑要设置数据流,首先需要创建一个索引模板来指定生命周期策略。由于该模板用于数据流,因此它还必须包含 data_stream 定义。
例如,您可以创建一个名为 timeseries_template 的模板,用于将来的名为 timeseries 的数据流。
要使 ILM 管理数据流,该模板配置了一个 ILM 设置:
-
index.lifecycle.name指定要应用于数据流的生命周期策略的名称。
您可以使用 Kibana 创建模板向导来添加模板。从 Kibana 中,打开菜单并转到 堆栈管理 > 索引管理。在 索引模板 选项卡中,点击 创建模板。
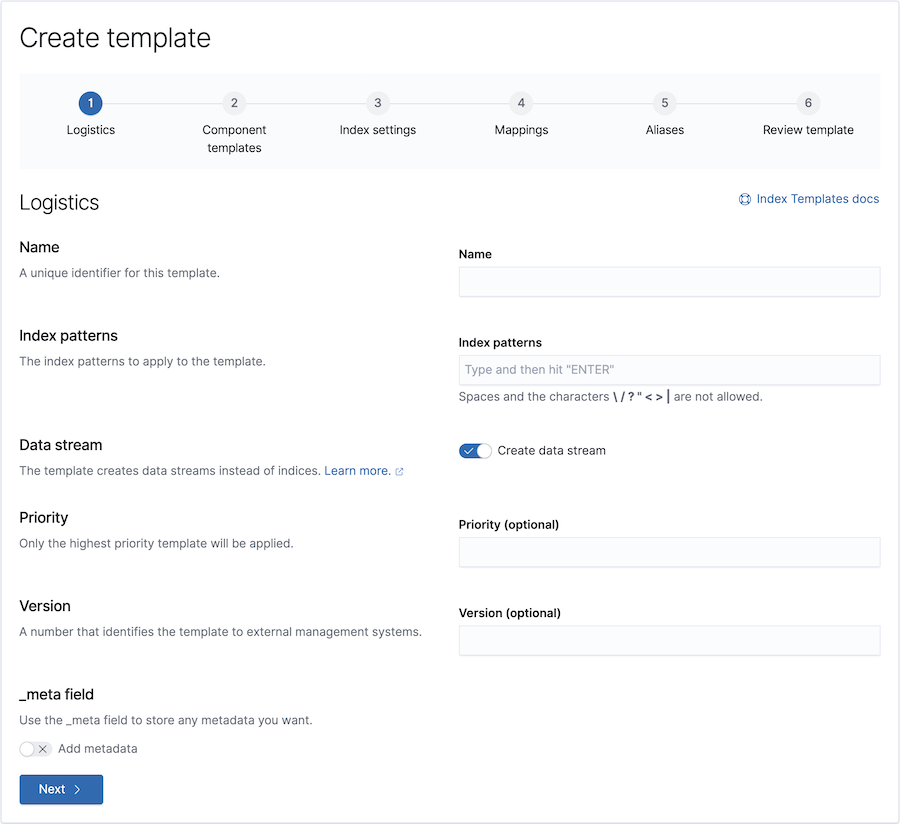
此向导会调用创建或更新索引模板 API,以使用您指定的选项创建索引模板。
API 示例
resp = client.indices.put_index_template(
name="timeseries_template",
index_patterns=[
"timeseries"
],
data_stream={},
template={
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "timeseries_policy"
}
},
)
print(resp)
response = client.indices.put_index_template(
name: 'timeseries_template',
body: {
index_patterns: [
'timeseries'
],
data_stream: {},
template: {
settings: {
number_of_shards: 1,
number_of_replicas: 1,
'index.lifecycle.name' => 'timeseries_policy'
}
}
}
)
puts response
const response = await client.indices.putIndexTemplate({
name: "timeseries_template",
index_patterns: ["timeseries"],
data_stream: {},
template: {
settings: {
number_of_shards: 1,
number_of_replicas: 1,
"index.lifecycle.name": "timeseries_policy",
},
},
});
console.log(response);
创建数据流
编辑要开始,请将文档索引到索引模板的 index_patterns 中定义的名称或通配符模式中。只要现有数据流、索引或索引别名尚未使用该名称,索引请求就会自动创建一个具有单个后备索引的相应数据流。Elasticsearch 会自动将请求的文档索引到此后备索引中,该索引也充当流的写入索引。
例如,以下请求会创建 timeseries 数据流和第一个生成的后备索引(名为 .ds-timeseries-2099.03.08-000001)。
resp = client.index(
index="timeseries",
document={
"message": "logged the request",
"@timestamp": "1591890611"
},
)
print(resp)
response = client.index(
index: 'timeseries',
body: {
message: 'logged the request',
"@timestamp": '1591890611'
}
)
puts response
const response = await client.index({
index: "timeseries",
document: {
message: "logged the request",
"@timestamp": "1591890611",
},
});
console.log(response);
POST timeseries/_doc
{
"message": "logged the request",
"@timestamp": "1591890611"
}
当满足生命周期策略中的滚动更新条件时,rollover 操作会:
- 创建第二个生成的后备索引,名为
.ds-timeseries-2099.03.08-000002。由于它是timeseries数据流的后备索引,因此会将timeseries_template索引模板中的配置应用于新索引。 - 由于它是
timeseries数据流的最新生成索引,新创建的后备索引.ds-timeseries-2099.03.08-000002将成为数据流的写入索引。
每次满足滚动更新条件时,此过程都会重复。您可以使用 timeseries 数据流名称在由 timeseries_policy 管理的所有数据流的后备索引中进行搜索。写入操作应发送到数据流名称,该名称会将它们路由到其当前的写入索引。针对数据流的读取操作将由其所有后备索引处理。
检查生命周期进度
编辑要获取托管索引的状态信息,您可以使用 ILM explain API。这使您可以了解诸如此类的信息:
- 索引所处的阶段以及何时进入该阶段。
- 当前操作以及正在执行的步骤。
- 是否发生了任何错误或进度被阻止。
例如,以下请求获取有关 timeseries 数据流的后备索引的信息:
resp = client.ilm.explain_lifecycle(
index=".ds-timeseries-*",
)
print(resp)
response = client.ilm.explain_lifecycle( index: '.ds-timeseries-*' ) puts response
const response = await client.ilm.explainLifecycle({
index: ".ds-timeseries-*",
});
console.log(response);
GET .ds-timeseries-*/_ilm/explain
以下响应显示数据流的第一个生成的后备索引正在等待 hot 阶段的 rollover 操作。它将保持此状态,并且 ILM 将继续调用 check-rollover-ready,直到满足滚动更新条件。
{
"indices": {
".ds-timeseries-2099.03.07-000001": {
"index": ".ds-timeseries-2099.03.07-000001",
"index_creation_date_millis": 1538475653281,
"time_since_index_creation": "30s",
"managed": true,
"policy": "timeseries_policy",
"lifecycle_date_millis": 1538475653281,
"age": "30s",
"phase": "hot",
"phase_time_millis": 1538475653317,
"action": "rollover",
"action_time_millis": 1538475653317,
"step": "check-rollover-ready",
"step_time_millis": 1538475653317,
"phase_execution": {
"policy": "timeseries_policy",
"phase_definition": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_primary_shard_size": "50gb",
"max_age": "30d"
}
}
},
"version": 1,
"modified_date_in_millis": 1539609701576
}
}
}
}
|
用于计算何时通过 |
|
|
用于管理索引的策略 |
|
|
用于过渡到下一阶段的索引年龄(在本例中,它与索引的年龄相同)。 |
|
|
ILM 正在索引上执行的步骤 |
|
|
当前阶段的定义( |
在没有数据流的情况下管理时间序列数据
编辑即使数据流是一种方便的方式来扩展和管理时间序列数据,但它们被设计为仅追加。我们认识到可能存在需要就地更新或删除数据的情况,并且数据流不支持直接删除和更新请求,因此需要直接在数据流的后备索引上使用索引 API。在这些情况下,我们仍然建议使用数据流。
如果您经常使用相同的 _id 发送多个文档,期望最后写入获胜,则可以使用索引别名而不是数据流来管理包含时间序列数据的索引,并定期滚动更新到新索引。
要使用索引别名通过 ILM 自动滚动更新和管理时间序列索引,您需要:
- 创建一个生命周期策略,该策略定义适当的阶段和操作。请参阅上面的创建生命周期策略。
- 创建一个索引模板,以将策略应用于每个新索引。
- 引导一个索引作为初始写入索引。
- 验证索引是否按预期在生命周期阶段中移动。
创建索引模板以应用生命周期策略
编辑要在滚动更新时自动将生命周期策略应用于新的写入索引,请在用于创建新索引的索引模板中指定该策略。
例如,您可以创建一个 timeseries_template,该模板应用于名称与 timeseries-* 索引模式匹配的新索引。
要启用自动滚动更新,该模板配置了两个 ILM 设置:
-
index.lifecycle.name指定要应用于与索引模式匹配的新索引的生命周期策略的名称。 -
index.lifecycle.rollover_alias指定当为索引触发滚动更新操作时要滚动更新的索引别名。
您可以使用 Kibana 创建模板向导来添加模板。要访问该向导,请打开菜单并转到 堆栈管理 > 索引管理。在 索引模板 选项卡中,点击 创建模板。
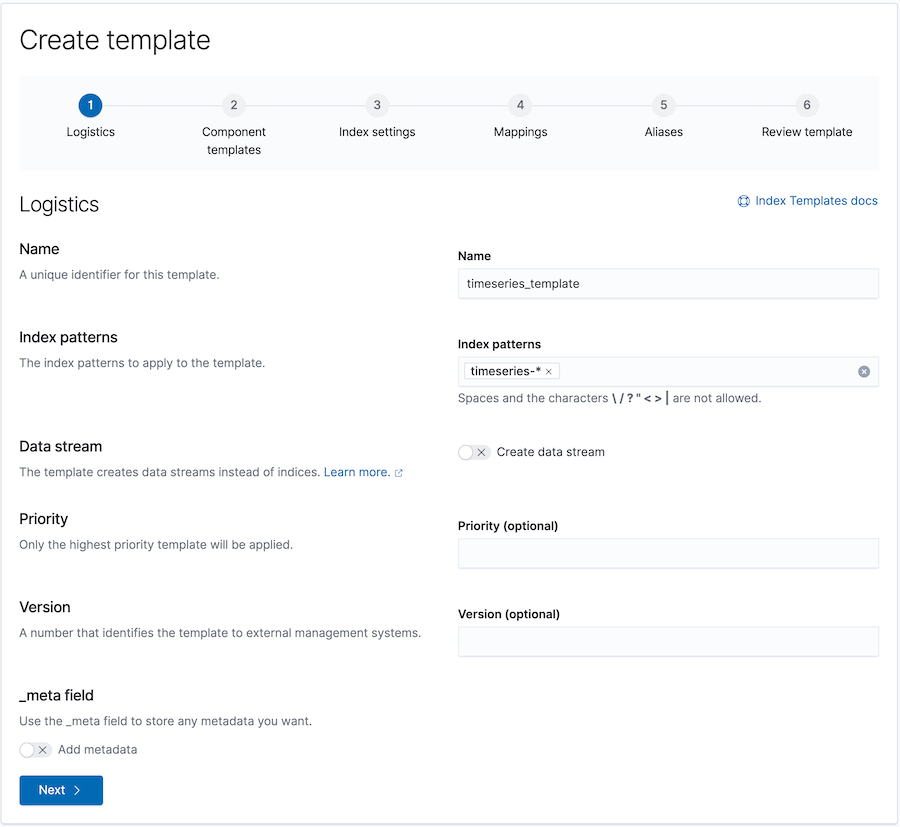
示例模板的创建模板请求如下所示:
resp = client.indices.put_index_template(
name="timeseries_template",
index_patterns=[
"timeseries-*"
],
template={
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "timeseries_policy",
"index.lifecycle.rollover_alias": "timeseries"
}
},
)
print(resp)
const response = await client.indices.putIndexTemplate({
name: "timeseries_template",
index_patterns: ["timeseries-*"],
template: {
settings: {
number_of_shards: 1,
number_of_replicas: 1,
"index.lifecycle.name": "timeseries_policy",
"index.lifecycle.rollover_alias": "timeseries",
},
},
});
console.log(response);
PUT _index_template/timeseries_template
{
"index_patterns": ["timeseries-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "timeseries_policy",
"index.lifecycle.rollover_alias": "timeseries"
}
}
}
使用写入索引别名引导初始时间序列索引
编辑要开始操作,您需要引导一个初始索引,并将其指定为索引模板中指定的滚动别名的写入索引。此索引的名称必须与模板的索引模式匹配,并以数字结尾。在滚动时,此值会递增,以生成新索引的名称。
例如,以下请求会创建一个名为 timeseries-000001 的索引,并使其成为 timeseries 别名的写入索引。
resp = client.indices.create(
index="timeseries-000001",
aliases={
"timeseries": {
"is_write_index": True
}
},
)
print(resp)
const response = await client.indices.create({
index: "timeseries-000001",
aliases: {
timeseries: {
is_write_index: true,
},
},
});
console.log(response);
PUT timeseries-000001
{
"aliases": {
"timeseries": {
"is_write_index": true
}
}
}
当满足滚动条件时,rollover 操作会
- 创建一个名为
timeseries-000002的新索引。这与timeseries-*模式匹配,因此timeseries_template中的设置将应用于新索引。 - 将新索引指定为写入索引,并使引导索引变为只读。
每次满足滚动条件时,此过程都会重复。您可以使用 timeseries 别名在 timeseries_policy 管理的所有索引中进行搜索。写入操作应发送到别名,别名会将它们路由到其当前的写入索引。
检查生命周期进度
编辑检索托管索引的状态信息与数据流的情况非常相似。有关更多信息,请参阅数据流的检查进度部分。唯一的区别是索引命名空间,因此检索进度将需要以下 API 调用
resp = client.ilm.explain_lifecycle(
index="timeseries-*",
)
print(resp)
response = client.ilm.explain_lifecycle( index: 'timeseries-*' ) puts response
const response = await client.ilm.explainLifecycle({
index: "timeseries-*",
});
console.log(response);
GET timeseries-*/_ilm/explain