百分位数聚合
编辑百分位数聚合
编辑一个 多值 指标聚合,用于计算从聚合文档中提取的数值的一个或多个百分位数。这些值可以从文档中的特定数值或 直方图字段 中提取。
百分位数显示观察值发生时达到特定百分比的点。例如,第 95 个百分位数是大于 95% 观察值的值。
百分位数通常用于查找异常值。在正态分布中,第 0.13 个和第 99.87 个百分位数表示与平均值的三个标准差。任何超出三个标准差的数据通常被认为是异常。
当检索一系列百分位数时,它们可以用于估计数据分布并确定数据是否偏斜、双峰等。
假设您的数据由网站加载时间组成。平均加载时间和中位加载时间对于管理员来说不是非常有用。最大值可能很有趣,但它很容易被单个缓慢的响应所扭曲。
让我们看一下代表加载时间的一系列百分位数
resp = client.search(
index="latency",
size=0,
aggs={
"load_time_outlier": {
"percentiles": {
"field": "load_time"
}
}
},
)
print(resp)
response = client.search(
index: 'latency',
body: {
size: 0,
aggregations: {
load_time_outlier: {
percentiles: {
field: 'load_time'
}
}
}
}
)
puts response
const response = await client.search({
index: "latency",
size: 0,
aggs: {
load_time_outlier: {
percentiles: {
field: "load_time",
},
},
},
});
console.log(response);
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time"
}
}
}
}
默认情况下,percentile 指标将生成一系列百分位数:[ 1, 5, 25, 50, 75, 95, 99 ]。响应将如下所示
{
...
"aggregations": {
"load_time_outlier": {
"values": {
"1.0": 10.0,
"5.0": 30.0,
"25.0": 170.0,
"50.0": 445.0,
"75.0": 720.0,
"95.0": 940.0,
"99.0": 980.0
}
}
}
}
如您所见,聚合将返回默认范围内每个百分位数的计算值。如果我们假设响应时间以毫秒为单位,那么很明显,网页通常在 10-720 毫秒内加载,但偶尔会飙升至 940-980 毫秒。
通常,管理员只对异常值(即极端百分位数)感兴趣。我们可以只指定我们感兴趣的百分位数(请求的百分位数必须是 0-100(含)之间的值)
resp = client.search(
index="latency",
size=0,
aggs={
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"percents": [
95,
99,
99.9
]
}
}
},
)
print(resp)
response = client.search(
index: 'latency',
body: {
size: 0,
aggregations: {
load_time_outlier: {
percentiles: {
field: 'load_time',
percents: [
95,
99,
99.9
]
}
}
}
}
)
puts response
const response = await client.search({
index: "latency",
size: 0,
aggs: {
load_time_outlier: {
percentiles: {
field: "load_time",
percents: [95, 99, 99.9],
},
},
},
});
console.log(response);
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"percents": [ 95, 99, 99.9 ]
}
}
}
}
键控响应
编辑默认情况下,keyed 标志设置为 true,它将唯一的字符串键与每个桶相关联,并将范围作为哈希而不是数组返回。将 keyed 标志设置为 false 将禁用此行为
resp = client.search(
index="latency",
size=0,
aggs={
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"keyed": False
}
}
},
)
print(resp)
response = client.search(
index: 'latency',
body: {
size: 0,
aggregations: {
load_time_outlier: {
percentiles: {
field: 'load_time',
keyed: false
}
}
}
}
)
puts response
const response = await client.search({
index: "latency",
size: 0,
aggs: {
load_time_outlier: {
percentiles: {
field: "load_time",
keyed: false,
},
},
},
});
console.log(response);
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"keyed": false
}
}
}
}
响应
{
...
"aggregations": {
"load_time_outlier": {
"values": [
{
"key": 1.0,
"value": 10.0
},
{
"key": 5.0,
"value": 30.0
},
{
"key": 25.0,
"value": 170.0
},
{
"key": 50.0,
"value": 445.0
},
{
"key": 75.0,
"value": 720.0
},
{
"key": 95.0,
"value": 940.0
},
{
"key": 99.0,
"value": 980.0
}
]
}
}
}
脚本
编辑如果您需要针对未索引的值运行聚合,请使用运行时字段。例如,如果我们的加载时间以毫秒为单位,但您希望以秒为单位计算百分位数
resp = client.search(
index="latency",
size=0,
runtime_mappings={
"load_time.seconds": {
"type": "long",
"script": {
"source": "emit(doc['load_time'].value / params.timeUnit)",
"params": {
"timeUnit": 1000
}
}
}
},
aggs={
"load_time_outlier": {
"percentiles": {
"field": "load_time.seconds"
}
}
},
)
print(resp)
response = client.search(
index: 'latency',
body: {
size: 0,
runtime_mappings: {
'load_time.seconds' => {
type: 'long',
script: {
source: "emit(doc['load_time'].value / params.timeUnit)",
params: {
"timeUnit": 1000
}
}
}
},
aggregations: {
load_time_outlier: {
percentiles: {
field: 'load_time.seconds'
}
}
}
}
)
puts response
const response = await client.search({
index: "latency",
size: 0,
runtime_mappings: {
"load_time.seconds": {
type: "long",
script: {
source: "emit(doc['load_time'].value / params.timeUnit)",
params: {
timeUnit: 1000,
},
},
},
},
aggs: {
load_time_outlier: {
percentiles: {
field: "load_time.seconds",
},
},
},
});
console.log(response);
GET latency/_search
{
"size": 0,
"runtime_mappings": {
"load_time.seconds": {
"type": "long",
"script": {
"source": "emit(doc['load_time'].value / params.timeUnit)",
"params": {
"timeUnit": 1000
}
}
}
},
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time.seconds"
}
}
}
}
百分位数(通常)是近似值
编辑有许多不同的算法可以计算百分位数。朴素的实现只是将所有值存储在排序的数组中。要找到第 50 个百分位数,您只需找到位于 my_array[count(my_array) * 0.5] 的值。
显然,朴素的实现无法扩展 —— 排序后的数组会随着数据集中值的数量线性增长。为了在 Elasticsearch 集群中计算可能数十亿个值的百分位数,将计算近似百分位数。
percentile 指标使用的算法称为 TDigest(由 Ted Dunning 在 使用 T-Digests 计算精确的分位数 中提出)。
使用此指标时,请记住以下几条准则
- 精度与
q(1-q)成正比。这意味着极端的百分位数(例如 99%)比不那么极端的百分位数(如中位数)更精确 - 对于少量值,百分位数非常精确(如果数据足够小,则可能 100% 精确)。
- 随着桶中值的数量增加,该算法开始逼近百分位数。它实际上是在用精度换取内存节省。不准确的确切程度很难概括,因为它取决于您的数据分布和聚合的数据量
下图显示了均匀分布上的相对误差,具体取决于收集的值的数量和请求的百分位数
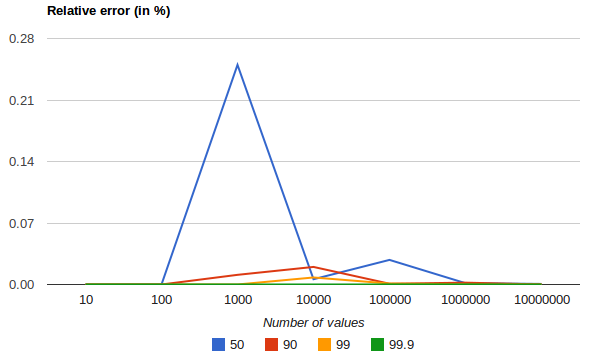
它显示了极端百分位数的精度如何更好。误差随着值的数量的增加而减少的原因是大数定律使值的分布越来越均匀,并且 t-digest 树可以更好地总结它。在更偏斜的分布中情况并非如此。
百分位数聚合也是非确定性的。这意味着您可以使用相同的数据获得略有不同的结果。
压缩
编辑近似算法必须平衡内存利用率和估计精度。可以使用 compression 参数控制这种平衡
resp = client.search(
index="latency",
size=0,
aggs={
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"tdigest": {
"compression": 200
}
}
}
},
)
print(resp)
response = client.search(
index: 'latency',
body: {
size: 0,
aggregations: {
load_time_outlier: {
percentiles: {
field: 'load_time',
tdigest: {
compression: 200
}
}
}
}
}
)
puts response
const response = await client.search({
index: "latency",
size: 0,
aggs: {
load_time_outlier: {
percentiles: {
field: "load_time",
tdigest: {
compression: 200,
},
},
},
},
});
console.log(response);
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"tdigest": {
"compression": 200
}
}
}
}
}
TDigest 算法使用许多“节点”来逼近百分位数 —— 可用的节点越多,精度越高(以及更大的内存占用),这与数据量成正比。compression 参数将节点的最大数量限制为 20 * compression。
因此,通过增加压缩值,您可以提高百分位数的精度,但代价是占用更多内存。较大的压缩值也会使算法变慢,因为底层树数据结构的大小会增加,从而导致更昂贵的操作。默认压缩值为 100。
一个“节点”大约使用 32 字节的内存,因此在最坏的情况下(大量数据以排序和有序的方式到达),默认设置将生成一个大约 64KB 大小的 TDigest。在实践中,数据往往更随机,并且 TDigest 将使用更少的内存。
执行提示
编辑TDigest 的默认实现针对性能进行了优化,可扩展到数百万甚至数十亿个样本值,同时保持可接受的精度水平(在某些情况下,数百万个样本的相对误差接近 1%)。可以选择使用针对精度优化的实现,方法是将参数 execution_hint 设置为值 high_accuracy
resp = client.search(
index="latency",
size=0,
aggs={
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"tdigest": {
"execution_hint": "high_accuracy"
}
}
}
},
)
print(resp)
response = client.search(
index: 'latency',
body: {
size: 0,
aggregations: {
load_time_outlier: {
percentiles: {
field: 'load_time',
tdigest: {
execution_hint: 'high_accuracy'
}
}
}
}
}
)
puts response
const response = await client.search({
index: "latency",
size: 0,
aggs: {
load_time_outlier: {
percentiles: {
field: "load_time",
tdigest: {
execution_hint: "high_accuracy",
},
},
},
},
});
console.log(response);
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"tdigest": {
"execution_hint": "high_accuracy"
}
}
}
}
}
此选项可以提高精度(在某些情况下,数百万个样本的相对误差接近 0.01%),但百分位数查询的完成时间会延长 2 倍到 10 倍。
HDR 直方图
编辑HDR 直方图(高动态范围直方图)是一种替代实现,在计算延迟测量的百分位数时可能很有用,因为它比 t-digest 实现更快,但代价是占用更大的内存。此实现维护固定的最坏情况百分比误差(指定为有效位数)。这意味着,如果在设置为 3 位有效数字的直方图中记录了从 1 微秒到 1 小时(3,600,000,000 微秒)的值,它将为高达 1 毫秒的值保持 1 微秒的值分辨率,并且为最大跟踪值(1 小时)保持 3.6 秒(或更好)的值分辨率。
可以通过在请求中指定 hdr 参数来使用 HDR 直方图
resp = client.search(
index="latency",
size=0,
aggs={
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"percents": [
95,
99,
99.9
],
"hdr": {
"number_of_significant_value_digits": 3
}
}
}
},
)
print(resp)
response = client.search(
index: 'latency',
body: {
size: 0,
aggregations: {
load_time_outlier: {
percentiles: {
field: 'load_time',
percents: [
95,
99,
99.9
],
hdr: {
number_of_significant_value_digits: 3
}
}
}
}
}
)
puts response
const response = await client.search({
index: "latency",
size: 0,
aggs: {
load_time_outlier: {
percentiles: {
field: "load_time",
percents: [95, 99, 99.9],
hdr: {
number_of_significant_value_digits: 3,
},
},
},
},
});
console.log(response);
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"percents": [ 95, 99, 99.9 ],
"hdr": {
"number_of_significant_value_digits": 3
}
}
}
}
}
|
|
|
|
|
HDRHistogram 仅支持正值,如果传递负值则会出错。如果值的范围未知,也不建议使用 HDRHistogram,因为这可能会导致内存使用量过高。
缺失值
编辑missing 参数定义了应如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
resp = client.search(
index="latency",
size=0,
aggs={
"grade_percentiles": {
"percentiles": {
"field": "grade",
"missing": 10
}
}
},
)
print(resp)
response = client.search(
index: 'latency',
body: {
size: 0,
aggregations: {
grade_percentiles: {
percentiles: {
field: 'grade',
missing: 10
}
}
}
}
)
puts response
const response = await client.search({
index: "latency",
size: 0,
aggs: {
grade_percentiles: {
percentiles: {
field: "grade",
missing: 10,
},
},
},
});
console.log(response);