使用自定义 Ingest Pipeline 与 Kubernetes 集成
编辑使用自定义 Ingest Pipeline 与 Kubernetes 集成
编辑本教程解释如何向 Kubernetes 集成添加自定义 Ingest Pipeline,以便为 Pod 的部署和 CronJob 添加特定的元数据字段。
自定义 Pipeline 可用于添加自定义数据处理,例如添加字段、模糊处理敏感信息等等。在我们的教程中可以找到更多信息:使用自定义 Ingest Pipeline 变换数据。
Kubernetes 元数据增强
编辑使用 Kubernetes 集成 通过 Elastic Agent 收集 Kubernetes 集群的日志和指标。在收集过程中,集成会使用额外的有用信息增强收集到的信息,用户可以将其与不同的 Kubernetes 资源相关联。添加到收集数据之上的这些附加信息,例如 Kubernetes 资源的标签、注释、祖先名称等,称为元数据。
Kubernetes 提供程序 提供 add_resource_metadata 选项来配置元数据增强选项。
对于 Elastic Agent 版本 >[8.10.4],元数据增强的默认配置为 add_resource_metadata.deployment=false 和 add_resource_metadata.cronjob=false。这意味着从属于特定部署的副本集创建的 Pod 不会使用 kubernetes.deployment.name 进行增强。此外,从属于特定 CronJob 的作业创建的 Pod 也不会使用 kubernetes.cronjob.name 进行增强。
Kubernetes 集成策略 > 从 Kube-state-metrics 收集 Kubernetes 指标 > Kubernetes Pod 指标
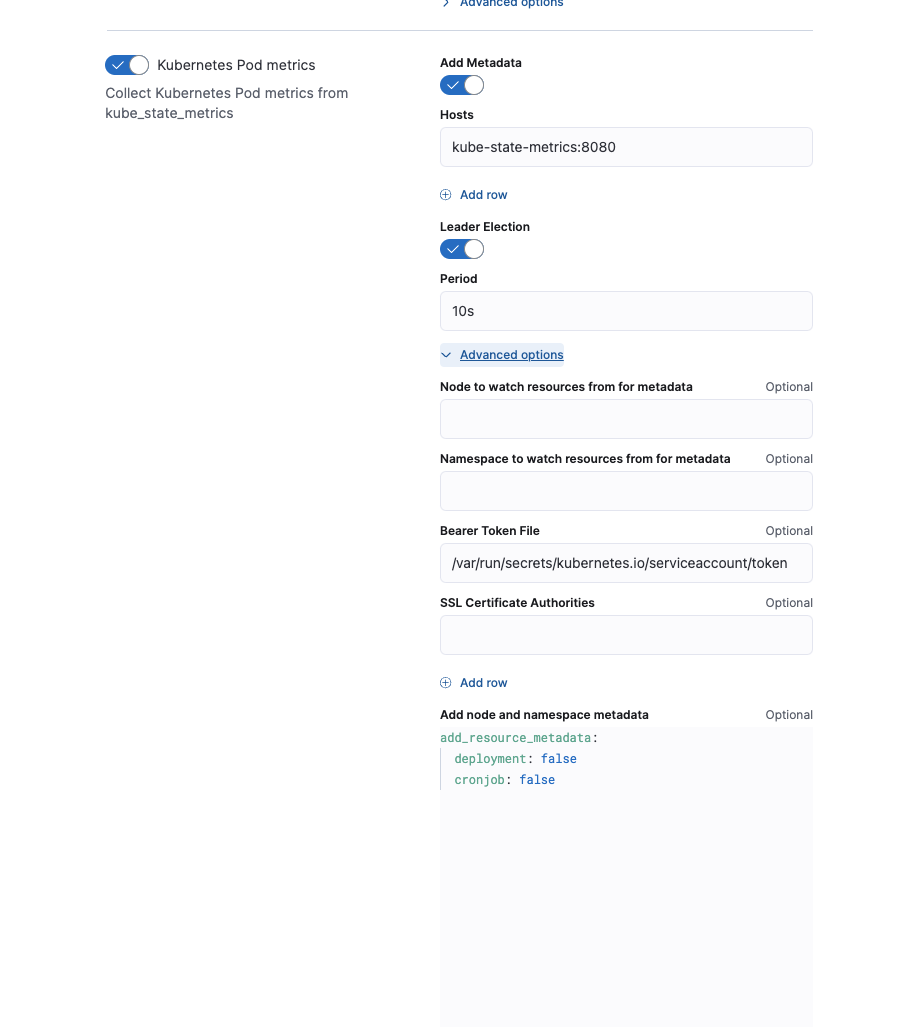
示例:在托管 Elastic Agent 策略中通过 add_resource_metadata 启用增强功能
注意:启用部署和 CronJob 元数据增强会导致 Elastic Agent 的内存消耗增加。Elastic Agent 使用本地缓存来保存已发现的 Kubernetes 资源的记录。
通过 Ingest Pipeline 为 Kubernetes Pod 添加部署和 CronJob
编辑作为保持功能启用并使用更多 Elastic Agent 内存资源的替代方法,用户可以使用 Ingest Pipeline 添加缺失的 kubernetes.deployment.name 和 kubernetes.cronjob.name 字段。
按照 使用自定义 Ingest Pipeline 变换数据 教程,导航到 state_pod 数据流,位于:Kubernetes 集成策略 > 从 Kube-state-metrics 收集 Kubernetes 指标 > Kubernetes Pod 指标。
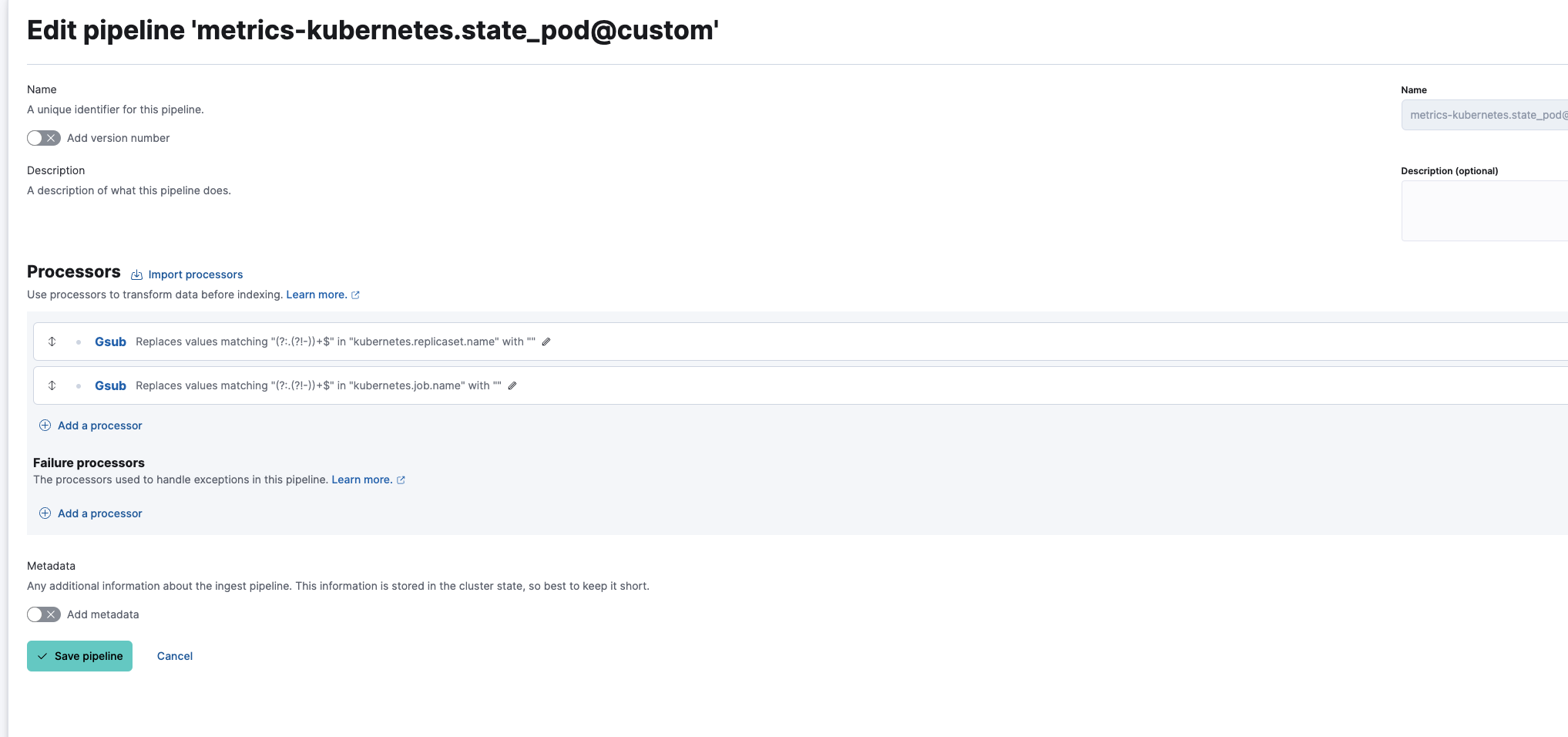
创建具有两个处理器的以下自定义 Ingest Pipeline
部署处理器
编辑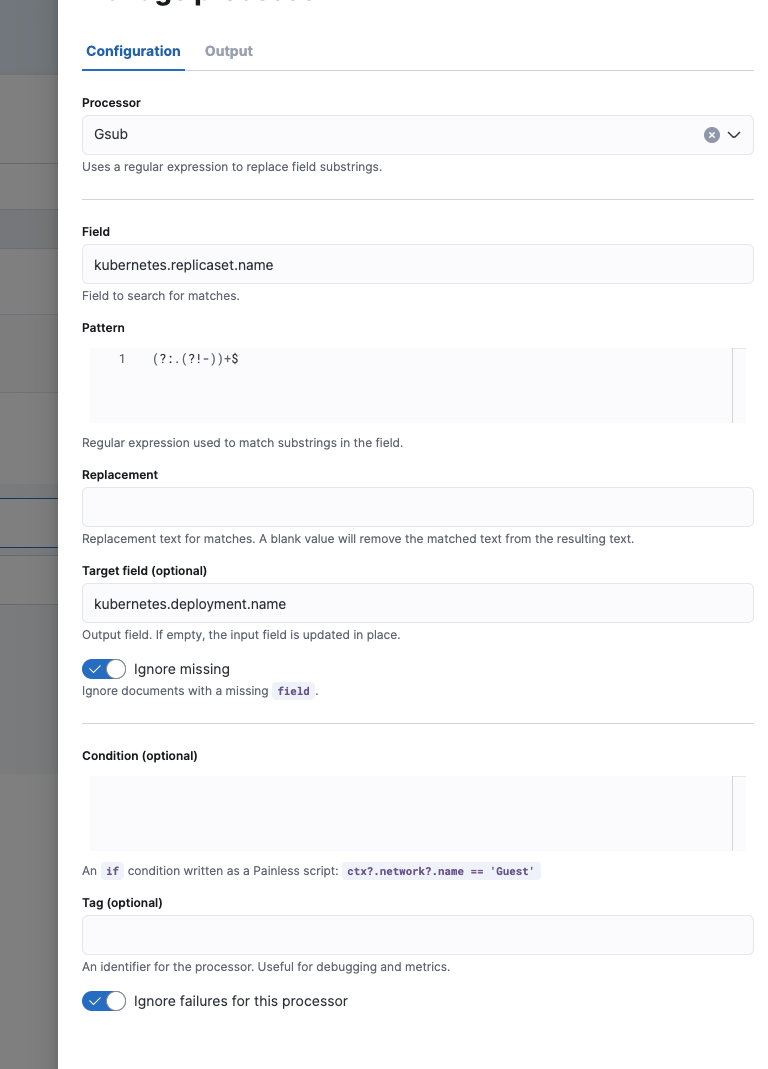
CronJob 处理器
编辑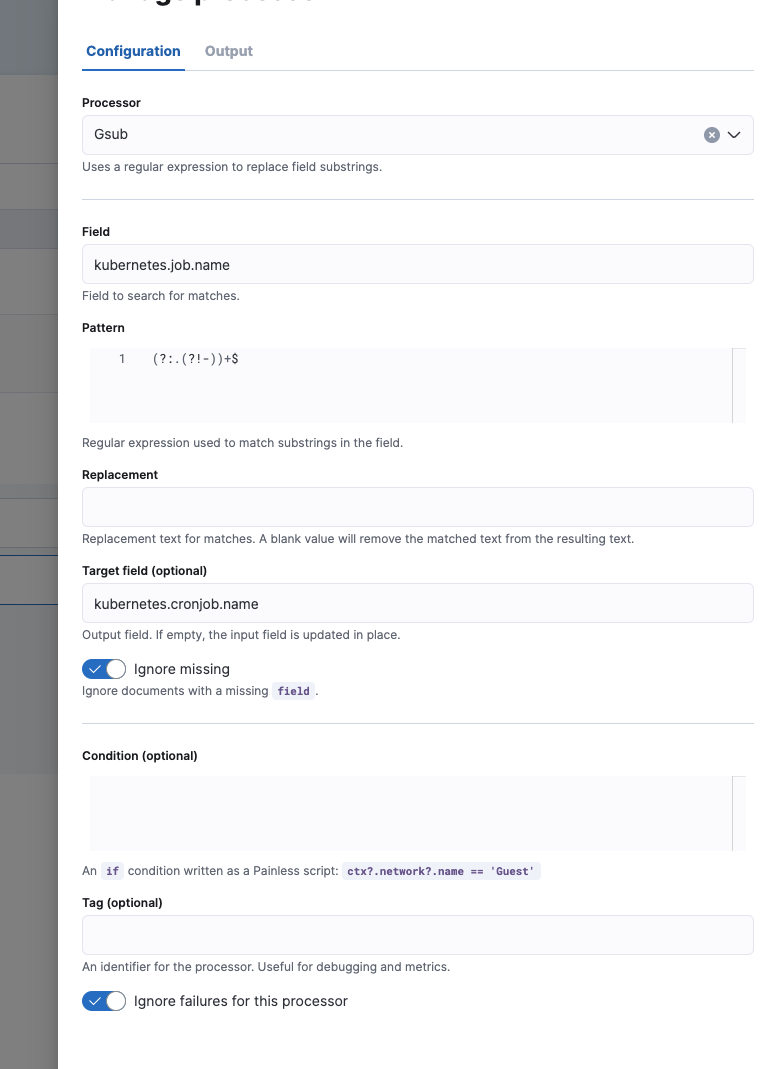
最终的 metrics-kubernetes.state_pod@custom Ingest Pipeline
[
{
"gsub": {
"field": "kubernetes.replicaset.name",
"pattern": "(?:.(?!-))+$",
"replacement": "",
"target_field": "kubernetes.deployment.name",
"ignore_missing": true,
"ignore_failure": true
}
},
{
"gsub": {
"field": "kubernetes.job.name",
"pattern": "(?:.(?!-))+$",
"replacement": "",
"target_field": "kubernetes.cronjob.name",
"ignore_missing": true,
"ignore_failure": true
}
}
]
注意:Ingest Pipeline 不会检查部署和 CronJob 祖先的实际存在,它只添加特定值。