定义处理器
编辑定义处理器
编辑Elastic Agent 处理器是轻量级的处理组件,您可以使用它们在源头解析、过滤、转换和丰富数据。例如,您可以使用处理器来
- 减少导出的字段数量
- 使用额外的元数据增强事件
- 执行额外的处理和解码
- 清理数据
每个处理器接收一个事件,将定义的操作应用于事件,然后返回该事件。如果您定义了一个处理器列表,它们将按照定义的顺序执行。
event -> processor 1 -> event1 -> processor 2 -> event2 ...
Elastic Agent 处理器在摄取管道之前执行,这意味着您的处理器配置不能引用由摄取管道或 Logstash 创建的字段。有关更多限制,请参阅 使用处理器有哪些限制?
处理器在何处有效?
编辑本节中描述的处理器在以下位置有效
-
Kibana 中集成 UI 下的集成设置中。例如,在配置 Nginx 集成时,您可以在 高级选项 下为特定数据集定义处理器。此示例中的处理器将地理元数据添加到 Elastic Agent 收集的 Nginx 访问日志中
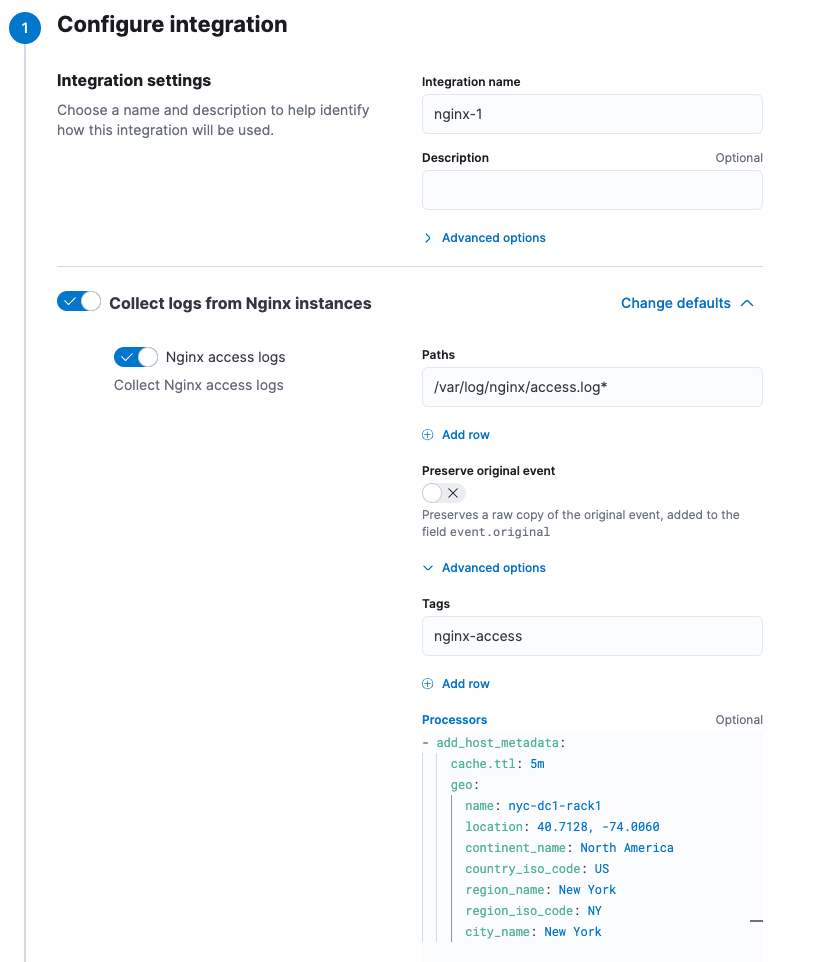
某些集成目前不支持处理器。
-
独立 Elastic Agent 的输入配置设置下。例如
inputs: - type: logfile use_output: default data_stream: namespace: default streams: - data_stream: dataset: nginx.access type: logs ignore_older: 72h paths: - /var/log/nginx/access.log* tags: - nginx-access exclude_files: - .gz$ processors: - add_host_metadata: cache.ttl: 5m geo: name: nyc-dc1-rack1 location: '40.7128, -74.0060' continent_name: North America country_iso_code: US region_name: New York region_iso_code: NY city_name: New York - add_locale: null
您可以定义适用于配置中定义的特定输入的处理器。目前不支持全局地将处理器应用于所有输入。
使用处理器有哪些限制?
编辑处理器具有以下限制。
- 无法使用来自 Elasticsearch 或其他自定义数据源的数据来丰富事件。
- 无法在数据转换为 Elastic Common Schema (ECS) 后处理数据,因为转换是由 Elasticsearch 摄取管道执行的。这意味着您的处理器配置不能引用由摄取管道或 Logstash 创建的字段,因为这些字段是在处理器运行之后而不是之前创建的。
- 如果用户定义的处理删除了或更改了摄取管道期望的字段,则可能会破坏 Elasticsearch 中的集成摄取管道。
- 如果您通过处理器创建新字段,则您有责任在
*-@custom组件模板中设置字段映射,并确保新映射与 ECS 对齐。
还有哪些其他选项可用于处理数据?
编辑Elastic Stack 提供了几种处理 Elastic Agent 收集的数据的选项。您选择的选项取决于您需要做什么
| 如果您需要… | 执行此操作… |
|---|---|
在源头清理或丰富原始数据 |
使用 Elastic Agent 处理器 |
将数据转换为 ECS,规范化字段数据或丰富传入的数据 |
使用摄取管道 |
在查询时定义或更改架构 |
使用运行时字段 |
对您的数据执行其他操作 |
Elastic Agent 处理器与 Logstash 插件或摄取管道有何不同?
编辑Logstash 插件和摄取管道都要求您将数据发送到另一个系统进行处理。另一方面,处理器允许您在源头应用处理逻辑。这意味着您可以过滤掉您不想通过连接发送的数据,并且可以将部分处理负载分散到在边缘节点上运行的主机系统上。