Elastic Agent 健康状态
编辑Elastic Agent 健康状态
编辑Elastic Agent 监控文档描述了可通过 Fleet UI 查看 Elastic Agent 状态和活动、访问指标和诊断、启用警报等功能。
有关 Fleet 如何监控 Elastic Agent 状态的详细信息,包括连接性、签入频率等,请参阅以下内容
Elastic Agent 如何连接到 Fleet 来报告其可用性和健康状况,并接收策略更新?
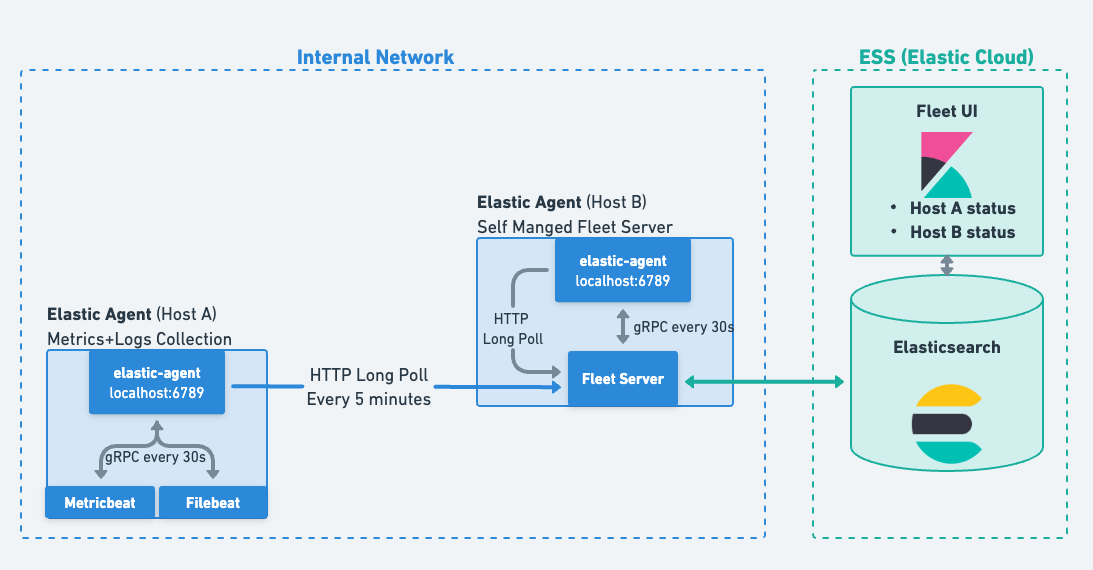
编辑注册后,Elastic Agent 会定期使用 HTTP 长轮询向 Fleet Server 发起签入(Fleet Server 部署在本地或作为 Elastic Cloud 中 Elasticsearch 的一部分部署)。
HTTP 长轮询请求会保持打开状态,直到 Elastic Agent 需要使用的配置发生更改、向 Agent 发送操作或 5 分钟超时为止。5 分钟后,Agent 将再次发送另一个签入以重新开始该过程。
签入频率可以配置为新值,但可能会影响可以连接到 Fleet 的 Agent 的最大数量。我们对该解决方案的常规规模测试不会修改此参数。
我们使用堆栈监控来监控集群的状态。Elastic Agent 的监控以及 Fleet 中显示的状态是否也使用堆栈监控?
编辑否。Fleet 中报告的 Elastic Agent 及其输入的健康状况监控完全独立于堆栈监控所提供的功能。
Elastic Agent 由许多组件组成。Elastic Agent 如何确保这些组件/进程正在运行且处于健康状态?
编辑Elastic Agent 本质上是一个主管,它(至少)将部署一个 Filebeat 实例用于日志收集,以及一个 Metricbeat 实例用于从系统和该系统上运行的应用程序收集指标。作为主管,它还会确保这些派生的进程正在运行且处于健康状态。Elastic Agent 使用 gRPC 每 30 秒与底层进程通信一次,以确保它们的健康状况。如果没有响应,Agent 将转变为 不健康 状态,结果和详细信息将报告给 Fleet。
如果 Elastic Agent 出现故障,Fleet 是否会生成警报?
编辑否。必须在 Kibana 中对显示每个特定状态下 Agent 总数的索引创建警报。有关配置警报的步骤,请参阅 Elastic Agent 监控文档中的基于 Fleet 和 Elastic Agent 状态启用警报和 ML 作业。目前计划在未来版本中发布针对单个 Agent 状态更改生成警报的功能。
Elastic Agent 需要多长时间来报告状态更改?
编辑某些 Elastic Agent 状态会立即报告,例如 Agent 变为 不健康 时。其他一些状态是在满足特定条件后得出的。有关监控 Agent 状态的详细信息,请参阅 Elastic Agent 监控文档中的查看 Agent 状态概览。
从 离线 状态转换为 非活动 状态可由用户配置,并且可以通过设置非活动超时参数来微调该转换。