游乐场
编辑游乐场编辑
此功能处于技术预览阶段,可能会在将来的版本中更改或删除。Elastic 将努力解决任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
使用游乐场将您的 Elasticsearch 数据与大型语言模型 (LLM) 的强大功能相结合,以实现检索增强生成 (RAG)。聊天界面将您的自然语言问题转换为 Elasticsearch 查询,从您的 Elasticsearch 文档中检索最相关的结果,并将这些文档传递给 LLM 以生成定制的响应。
开始聊天后,使用 UI 查看和修改搜索数据的 Elasticsearch 查询。您还可以查看为聊天界面提供支持的底层 Python 代码,并下载此代码以集成到您自己的应用程序中。
了解如何在本文档中入门。有关更高级主题,请参阅以下内容
游乐场的工作原理编辑
以下是游乐场工作原理的简化概述
- 用户 创建与 LLM 提供商的连接
- 用户 选择一个模型 用于生成响应
-
用户 使用初始指令定义模型的行为和语气
- 示例: "您是一位友好的助手,用于问答任务。保持响应清晰简洁。"
- 用户 选择 Elasticsearch 索引 进行搜索
- 用户 在聊天界面中输入问题
-
游乐场 自动生成 Elasticsearch 查询 以检索相关文档
- 用户可以在 UI 中 查看和修改底层 Elasticsearch 查询
-
游乐场 自动选择相关字段 从检索到的文档中传递给 LLM
- 用户可以 编辑目标字段
-
游乐场将 过滤后的文档 传递给 LLM
- LLM 根据原始查询、初始指令、聊天历史记录和 Elasticsearch 上下文生成响应
-
用户可以 查看为聊天界面提供支持的 Python 代码
- 用户还可以 下载代码 以集成到应用程序中
可用性和先决条件编辑
对于 Elastic Cloud 和自管理部署,游乐场在 Kibana 的 搜索 空间中可用,位于 内容 > 游乐场 下。
对于 Elastic Serverless,游乐场在您的 Elasticsearch 项目 UI 中可用。
要使用游乐场,您需要以下内容
- Elastic v8.14.0+ 部署或 Elasticsearch Serverless 项目。(开始 免费试用)。
-
至少一个包含要搜索的文档的 Elasticsearch 索引。
- 如果您想导入示例数据,请参阅 导入数据。
-
具有 支持的 LLM 提供商 帐户。游乐场支持以下内容
提供商 模型 备注 Amazon Bedrock
- Anthropic: Claude 3 Sonnet
- Anthropic: Claude 3 Haiku
目前不支持流式传输。
OpenAI
- GPT-3 turbo
- GPT-4 turbo
- GPT-4 omni
Azure OpenAI
- GPT-3 turbo
- GPT-4 turbo
入门编辑
连接到 LLM 提供商编辑
要开始使用游乐场,您需要为您的 LLM 提供商创建一个 连接器。在游乐场登录页面上按照以下步骤操作
- 在 连接到 LLM 下,单击 创建连接器。
- 选择您的 LLM 提供商。
- 命名 您的连接器。
- 选择一个 URL 端点(或使用默认值)。
- 输入您的 LLM 提供商的 访问凭据。
如果您需要更新连接器或添加新连接器,请单击 模型设置 下的扳手按钮 (🔧)。
导入数据(可选)编辑
如果您已经在 Elasticsearch 索引中拥有数据,则可以跳过此步骤。
将数据导入 Elasticsearch 有很多选项,包括
- 用于网页内容的 Elastic 爬虫 (注意: 尚未在 Serverless 中提供)
- Elastic 连接器 用于从第三方来源同步的数据
-
用于 JSON 文档的 Elasticsearch Bulk API
展开 以查看示例
要将一些文档添加到名为
books的索引中,请在 Dev Tools 控制台中运行以下命令POST /_bulk { "index" : { "_index" : "books" } } {"name": "Snow Crash", "author": "Neal Stephenson", "release_date": "1992-06-01", "page_count": 470} { "index" : { "_index" : "books" } } {"name": "Revelation Space", "author": "Alastair Reynolds", "release_date": "2000-03-15", "page_count": 585} { "index" : { "_index" : "books" } } {"name": "1984", "author": "George Orwell", "release_date": "1985-06-01", "page_count": 328} { "index" : { "_index" : "books" } } {"name": "Fahrenheit 451", "author": "Ray Bradbury", "release_date": "1953-10-15", "page_count": 227} { "index" : { "_index" : "books" } } {"name": "Brave New World", "author": "Aldous Huxley", "release_date": "1932-06-01", "page_count": 268} { "index" : { "_index" : "books" } } {"name": "The Handmaids Tale", "author": "Margaret Atwood", "release_date": "1985-06-01", "page_count": 311}
我们还提供了一些 Jupyter 笔记本,可以轻松地将示例数据导入 Elasticsearch。在 elasticsearch-labs 存储库中找到这些笔记本。这些笔记本使用官方 Elasticsearch Python 客户端。
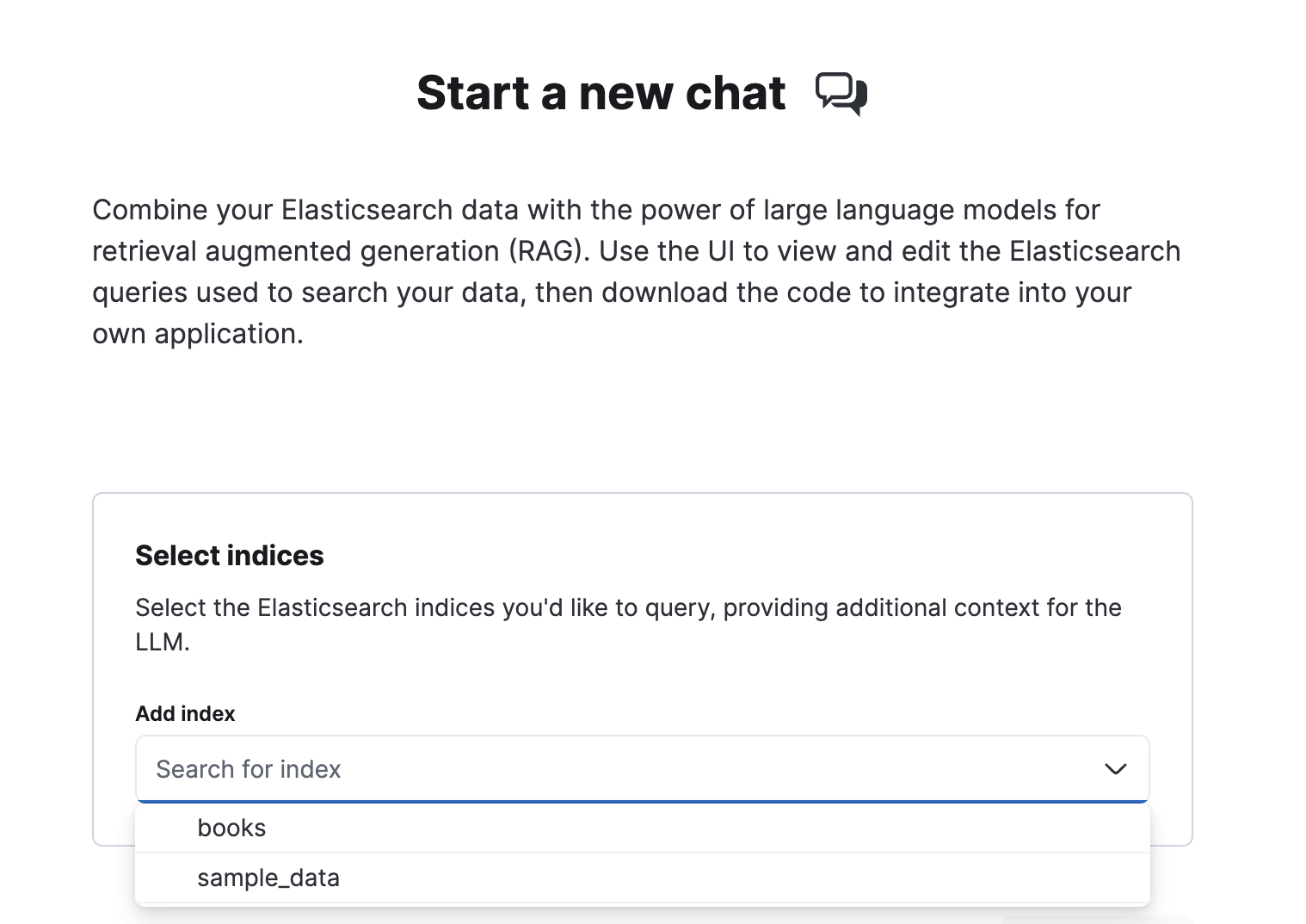
选择 Elasticsearch 索引编辑
连接到 LLM 提供商后,就可以选择要搜索的数据了。按照 选择索引 下的步骤操作
- 在 添加索引 下选择一个或多个 Elasticsearch 索引。
-
单击 开始 以启动聊天界面。
在 查看和修改查询 中了解有关用于搜索数据的底层 Elasticsearch 查询的更多信息。
设置聊天界面编辑
您可以立即开始与数据聊天,但您可能希望先调整一些默认设置。
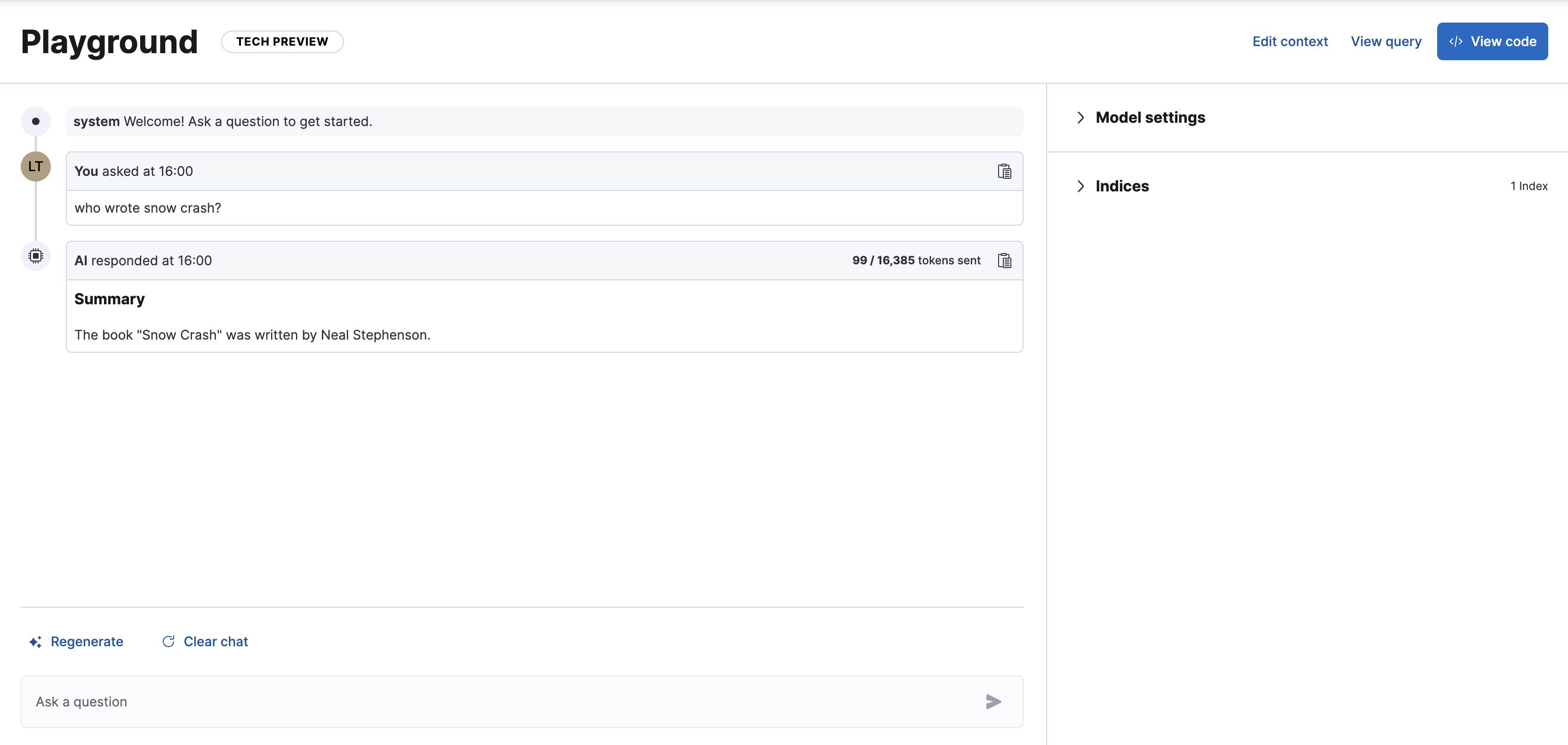
您可以在 模型设置 下调整以下内容
- 模型。用于生成响应的模型。
- 指令。也称为系统提示,这些初始指令和指南定义了模型在整个对话中的行为。为了获得最佳效果,请保持 清晰和具体。
- 包含引用。一个切换按钮,用于在响应中包含来自相关 Elasticsearch 文档的引用。
游乐场还在幕后使用另一个 LLM,对所有以前的问题和响应进行编码,并将其提供给主模型。这确保模型具有“对话记忆”。
在 索引 下,您可以编辑将要搜索的 Elasticsearch 索引。这将影响底层 Elasticsearch 查询。
单击 ✨ 重新生成 以将最后一个查询重新发送到模型以获取新的响应。
单击 ⟳ 清除聊天 以清除聊天历史记录并开始新的对话。
后续步骤编辑
游乐场启动并运行后,您已经测试了聊天界面,您可能希望探索一些更高级的主题