部署和扩展 Logstash
编辑部署和扩展 Logstash
编辑Elastic Stack 用于大量用例,从运营日志和指标分析到企业和应用程序搜索。确保您的数据能够以可扩展、持久且安全的方式传输到 Elasticsearch 至关重要,尤其是在关键任务环境中。
本文档的目的是重点介绍 Logstash 最常见的架构模式以及如何在部署规模增长时有效扩展。重点将围绕运营日志、指标和安全分析用例,因为它们往往需要更大规模的部署。此处提供的部署和扩展建议可能会因您自己的需求而异。
入门
编辑对于首次用户,如果您只是想跟踪日志文件以了解 Elastic Stack 的强大功能,我们建议您尝试 Filebeat 模块。Filebeat 模块使您能够在几分钟内快速收集、解析和索引流行的日志类型,并查看预构建的 Kibana 仪表板。 Metricbeat 模块 提供了类似的体验,但使用的是指标数据。在这种情况下,Beats 将数据直接发送到 Elasticsearch,其中 摄取节点 将处理和索引您的数据。
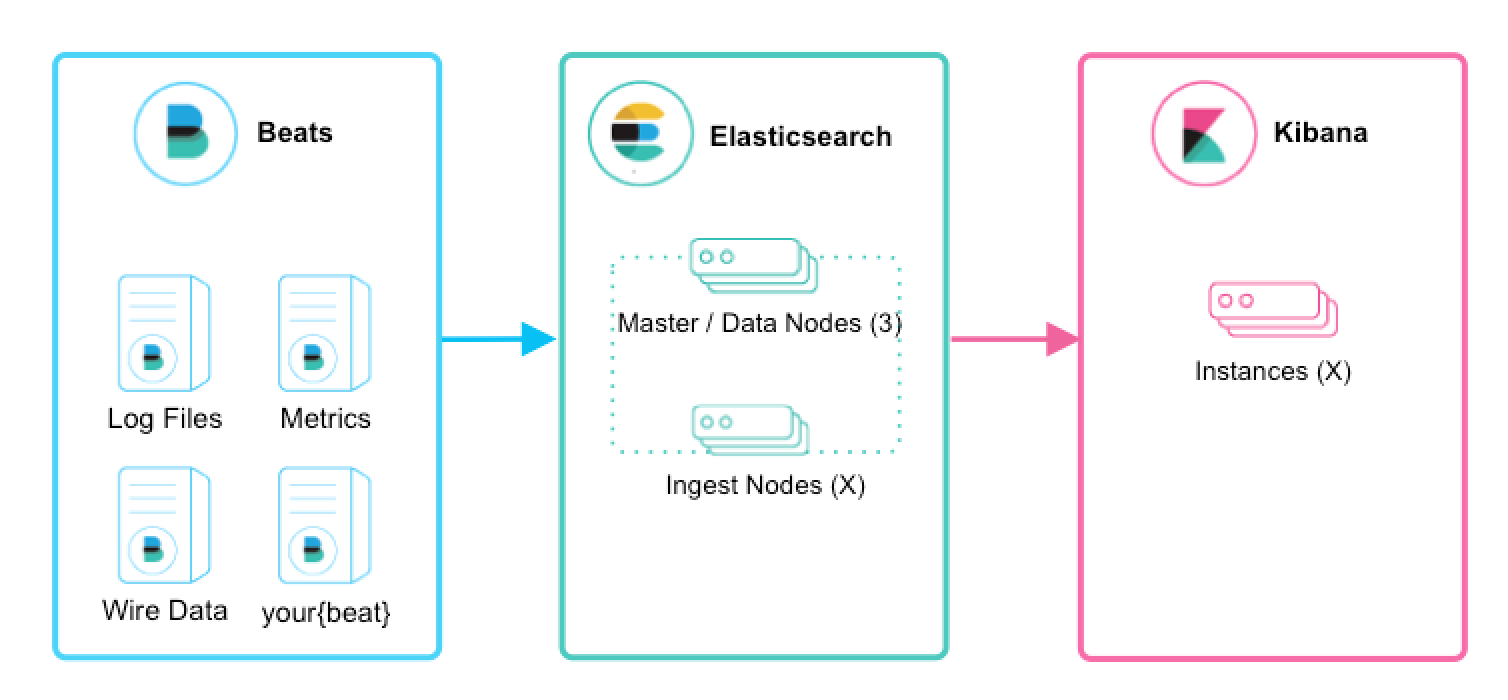
介绍 Logstash
编辑将 Logstash 集成到您的架构中的主要好处是什么?
- 通过摄取峰值进行扩展 - Logstash 具有自适应的基于磁盘的缓冲系统,可以吸收传入的吞吐量,从而减轻反压
- 从其他数据源(如数据库、S3 或消息队列)摄取数据
- 将数据发送到多个目标,例如 S3、HDFS 或写入文件
- 使用条件数据流逻辑构建更复杂的处理管道
扩展摄取
编辑Beats 和 Logstash 使摄取变得很棒。它们共同提供了一个可扩展且弹性的综合解决方案。您可以期待什么?
- 横向扩展、高可用性和可变负载处理
- 至少一次传递保证的消息持久性
- 使用身份验证和线加密的端到端安全传输
Beats 和 Logstash
编辑Beats 运行在数千个边缘主机服务器上,收集、跟踪并将日志发送到 Logstash。Logstash 充当数据统一和增强的集中式流引擎。 Beats 输入插件 为 Beats 提供了一个安全的、基于确认的端点,用于将数据发送到 Logstash。
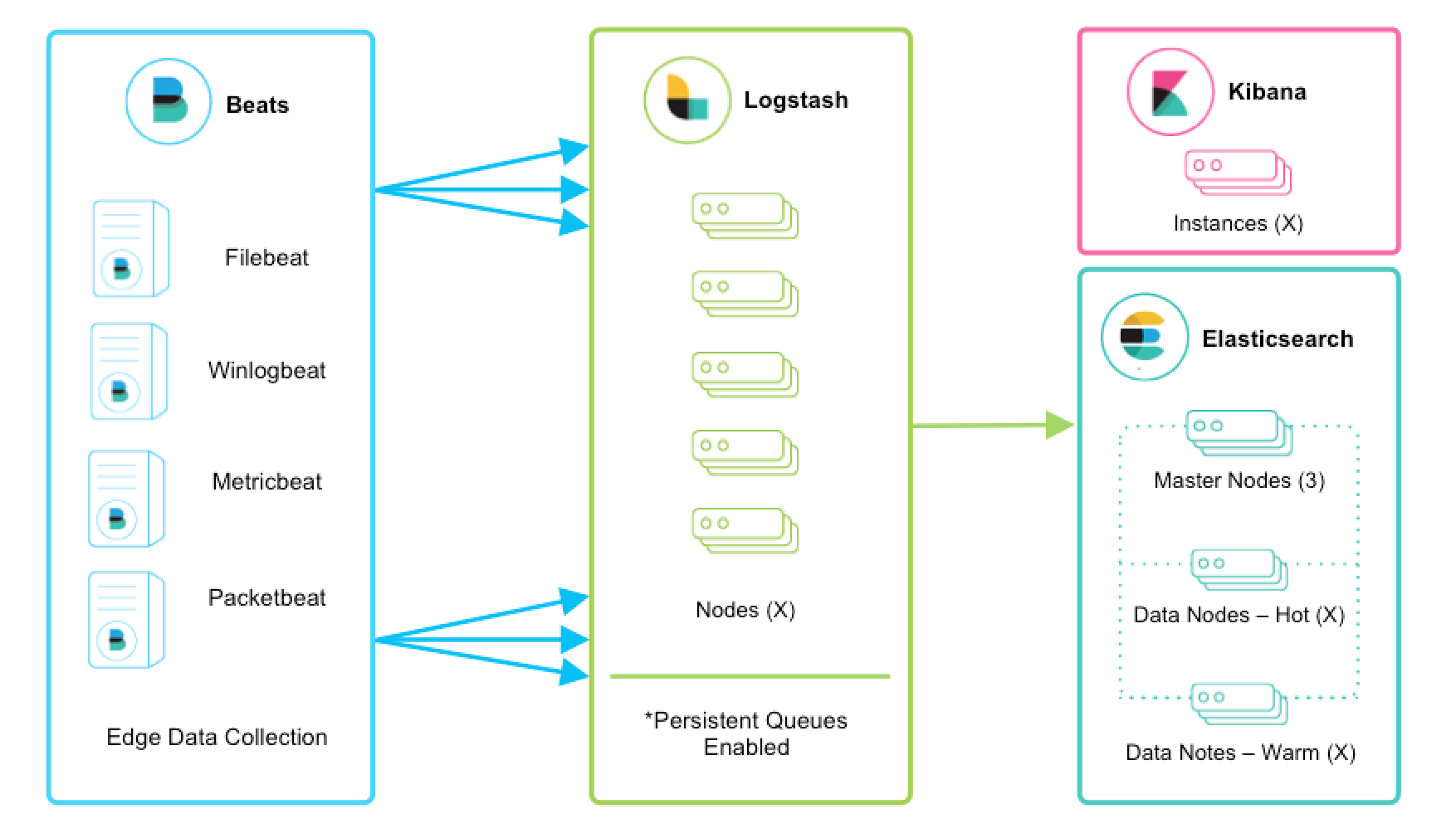
强烈建议启用持久队列,并且这些架构特性假定已启用它们。我们鼓励您查看 持久队列 (PQ) 文档以了解功能优势以及有关弹性的更多详细信息。
可扩展性
编辑Logstash 可横向扩展,并且可以形成运行相同管道的节点组。即使在可变吞吐量负载下,Logstash 的自适应缓冲功能也将促进平滑流传输。如果 Logstash 层成为摄取瓶颈,只需添加更多节点即可扩展。以下是一些一般建议
- Beats 应在 Logstash 节点组之间进行 负载均衡。
- 建议至少使用两个 Logstash 节点以实现高可用性。
- 通常每个 Logstash 节点只部署一个 Beats 输入,但每个 Logstash 节点也可以部署多个 Beats 输入以公开不同数据源的独立端点。
弹性
编辑在使用 Filebeat 或 Winlogbeat 在此摄取流中进行日志收集时,至少一次传递 是有保证的。从 Filebeat 或 Winlogbeat 到 Logstash 以及从 Logstash 到 Elasticsearch 的通信协议都是同步的,并支持确认。其他 Beats 尚未支持确认。
Logstash 持久队列提供了跨节点故障的保护。对于 Logstash 中的磁盘级弹性,务必确保磁盘冗余。对于本地部署,建议您配置 RAID。在云中或容器化环境中运行时,建议您使用具有反映您数据 SLA 的复制策略的持久磁盘。
确保设置了 queue.checkpoint.writes: 1 以获得至少一次传递的保证。有关更多详细信息,请参阅 持久队列持久性 文档。
处理
编辑Logstash 通常会使用 grok 或 dissect 提取字段,增强 地理 信息,并可以使用 文件、数据库 或 Elasticsearch 查找数据集进一步丰富事件。请注意,处理复杂性会影响整体吞吐量和 CPU 利用率。请务必查看其他 可用的过滤器插件。
安全传输
编辑整个交付链都提供了企业级安全性。
- 建议对 Beats 到 Logstash 和 Logstash 到 Elasticsearch 的传输都进行线加密。
- 与 Elasticsearch 通信时,有大量的安全选项,包括基本身份验证、TLS、PKI、LDAP、AD 和其他自定义领域。要启用 Elasticsearch 安全性,请参阅 保护集群。
监控
编辑在运行 Logstash 5.2 或更高版本时,监控 UI 提供了对您的部署指标的深入可见性,有助于观察性能并在扩展时缓解瓶颈。监控是基本许可证下的 X-Pack 功能,因此免费使用。要开始使用,请参阅 监控 Logstash。
如果首选外部监控,则有一些 监控 API 可以返回时间点指标快照。
添加其他常用来源
编辑用户可能还有其他收集日志数据的机制,并且可以轻松地将它们集成和集中到 Elastic Stack 中。让我们逐步完成一些场景
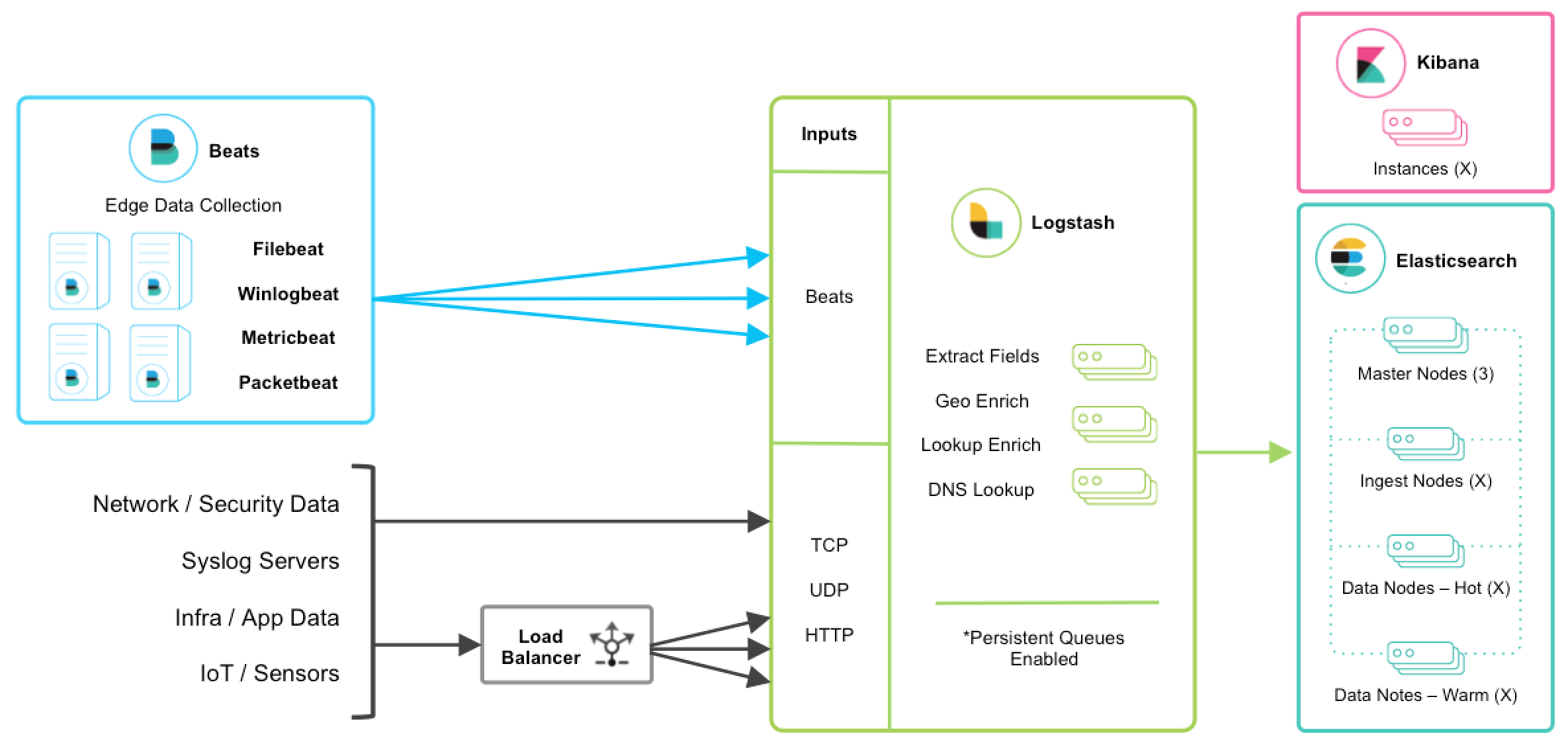
TCP、UDP 和 HTTP 协议
编辑TCP、UDP 和 HTTP 协议是将数据馈送到 Logstash 的常用方法。Logstash 可以使用相应的 TCP、UDP 和 HTTP 输入插件公开端点侦听器。下面列出的数据源通常通过这三种协议之一摄取。
TCP 和 UDP 协议不支持应用程序级确认,因此连接问题可能会导致数据丢失。
对于高可用性场景,应添加第三方硬件或软件负载均衡器(如 HAProxy)以将流量扇出到 Logstash 节点组。
网络和安全数据
编辑尽管 Beats 可能已经满足了您的数据摄取用例,但网络和安全数据集有多种形式。让我们讨论一些其他摄取点。
- 网络线数据 - 使用 Packetbeat 收集和分析网络流量。
- Netflow v5/v9/v10 - Logstash 使用 Netflow 编解码器 了解来自 Netflow/IPFIX 导出器的数据。
- Nmap - Logstash 使用 Nmap 编解码器 接受并解析 Nmap XML 数据。
- SNMP 陷阱 - Logstash 具有本机 SNMP 陷阱输入。
- CEF - Logstash 使用 CEF 编解码器 接受并解析来自 Arcsight SmartConnectors 等系统的 CEF 数据。有关更多详细信息,请参阅此 博文系列。
集中式 Syslog 服务器
编辑现有的 syslog 服务器技术(如 rsyslog 和 syslog-ng)通常将 syslog 发送到 Logstash TCP 或 UDP 端点以进行提取、处理和持久化。如果数据格式符合 RFC3164,则可以直接馈送到 Logstash syslog 输入。
基础设施和应用程序数据以及物联网
编辑可以使用 Metricbeat 收集基础设施和应用程序指标,但应用程序也可以将 Webhook 发送到 Logstash HTTP 输入,或者使用 HTTP 轮询输入插件 从 HTTP 端点轮询指标。
对于使用 log4j2 记录日志的应用程序,建议使用 SocketAppender 将 JSON 发送到 Logstash TCP 输入。或者,log4j2 也可以记录到文件中,以便使用 FIlebeat 进行收集。不建议使用 log4j1 SocketAppender。
物联网设备(如 Raspberry Pi、智能手机和联网车辆)通常通过这些协议之一发送遥测数据。
与消息队列集成
编辑如果您正在利用消息队列技术作为您现有基础设施的一部分,则将这些数据输入 Elastic Stack 很容易。对于正在使用 Redis 或 RabbitMQ 等外部排队层仅用于 Logstash 数据缓冲的现有用户,建议改用 Logstash 持久队列,而不是使用外部排队层。这将有助于简化整体管理,从而避免在摄取架构中引入不必要的复杂层。
对于希望从现有的 Kafka 部署中集成数据或需要使用短暂存储的用户,Kafka 可以用作数据中心,Beats 可以持久化到其中,而 Logstash 节点可以从中消费数据。
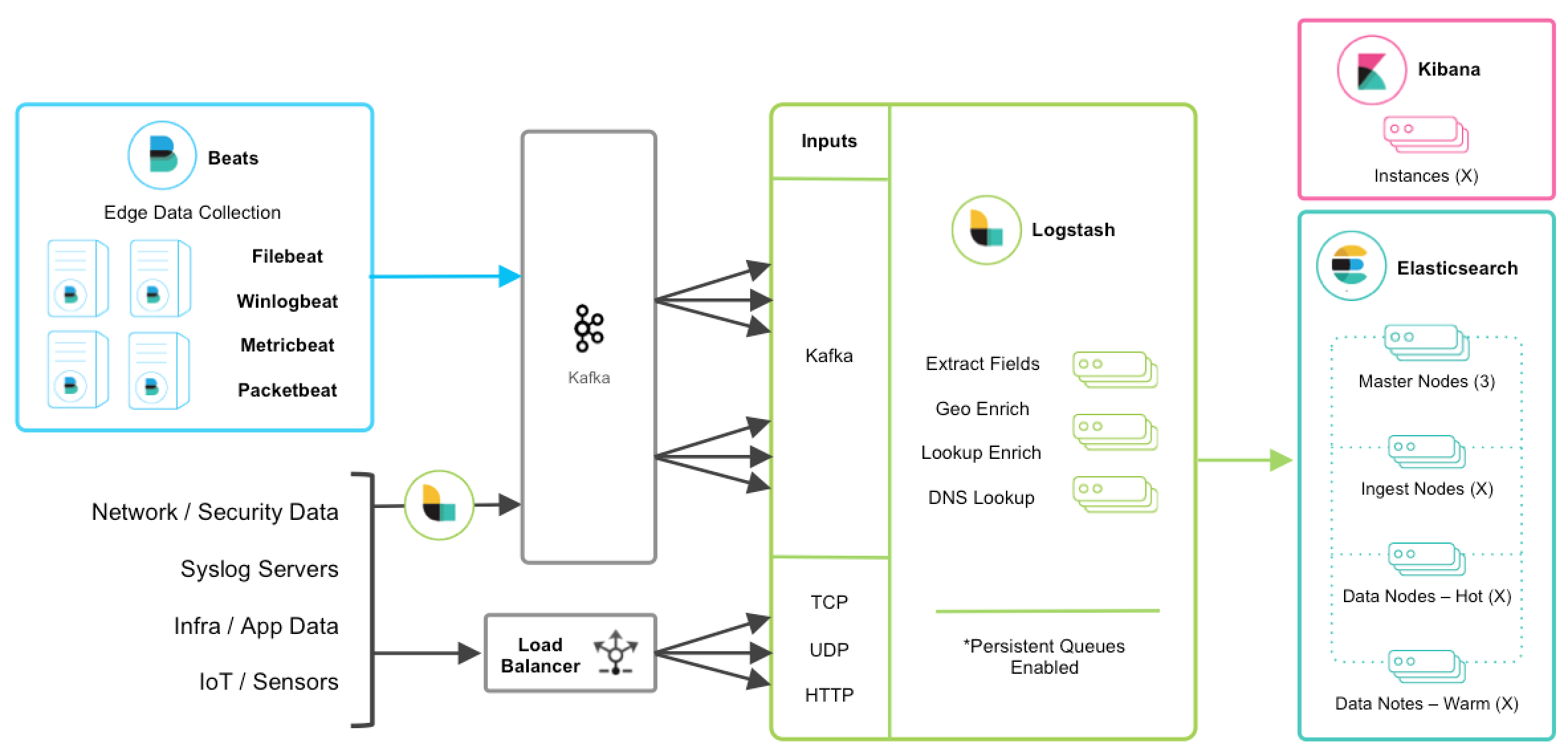
其他 TCP、UDP 和 HTTP 源可以使用 Logstash 作为管道持久化到 Kafka,以实现负载均衡的高可用性。然后,一组 Logstash 节点可以使用 Kafka 输入 从主题中消费数据,以进一步转换和丰富传输中的数据。
弹性和恢复
编辑当 Logstash 从 Kafka 中消费数据时,应启用持久化队列,这将增加传输弹性,以减轻 Logstash 节点故障期间重新处理的需求。在这种情况下,建议使用默认的持久化队列磁盘分配大小 queue.max_bytes: 1GB。
如果 Kafka 配置为长时间保留数据,则可以在灾难恢复和协调的情况下从 Kafka 中重新处理数据。
其他消息队列集成
编辑尽管不需要额外的队列层,但 Logstash 也可以从各种其他消息队列技术中消费数据,例如 RabbitMQ 和 Redis。它还支持从托管队列服务中提取数据,例如 Pub/Sub、Kinesis 和 SQS。