为异常检测作业生成告警
编辑为异常检测作业生成告警
编辑Kibana 告警功能包括对机器学习规则的支持,这些规则会定期检查一个或多个异常检测作业中的异常情况,或检查作业的运行状况(基于某些条件)。如果满足规则的条件,则会创建一个告警并触发关联的操作。例如,您可以创建一个规则,每 15 分钟检查一次异常检测作业中是否存在严重异常,并通过电子邮件通知您。要了解有关 Kibana 告警功能的更多信息,请参阅告警。
以下机器学习规则可用:
- 异常检测告警
- 检查异常检测作业结果是否包含与规则条件匹配的异常。
- 异常检测作业运行状况
- 监视作业运行状况,并在发生可能阻止作业检测到异常的操作问题时发出告警。
如果您已经为特定的异常检测作业创建了规则,并且想要监视这些作业是否按预期工作,则异常检测作业运行状况规则非常适合此目的。
在 Stack Management > 规则 中,您可以创建两种类型的机器学习规则。在 机器学习 应用中,您只能创建异常检测告警规则;可以在启动作业后从异常检测作业向导中创建,也可以从异常检测作业列表中创建。
异常检测告警规则
编辑创建异常检测告警规则时,必须选择规则所应用的作业。
您还必须选择一种机器学习结果类型。特别是,您可以根据存储桶、记录或影响因子结果创建规则。
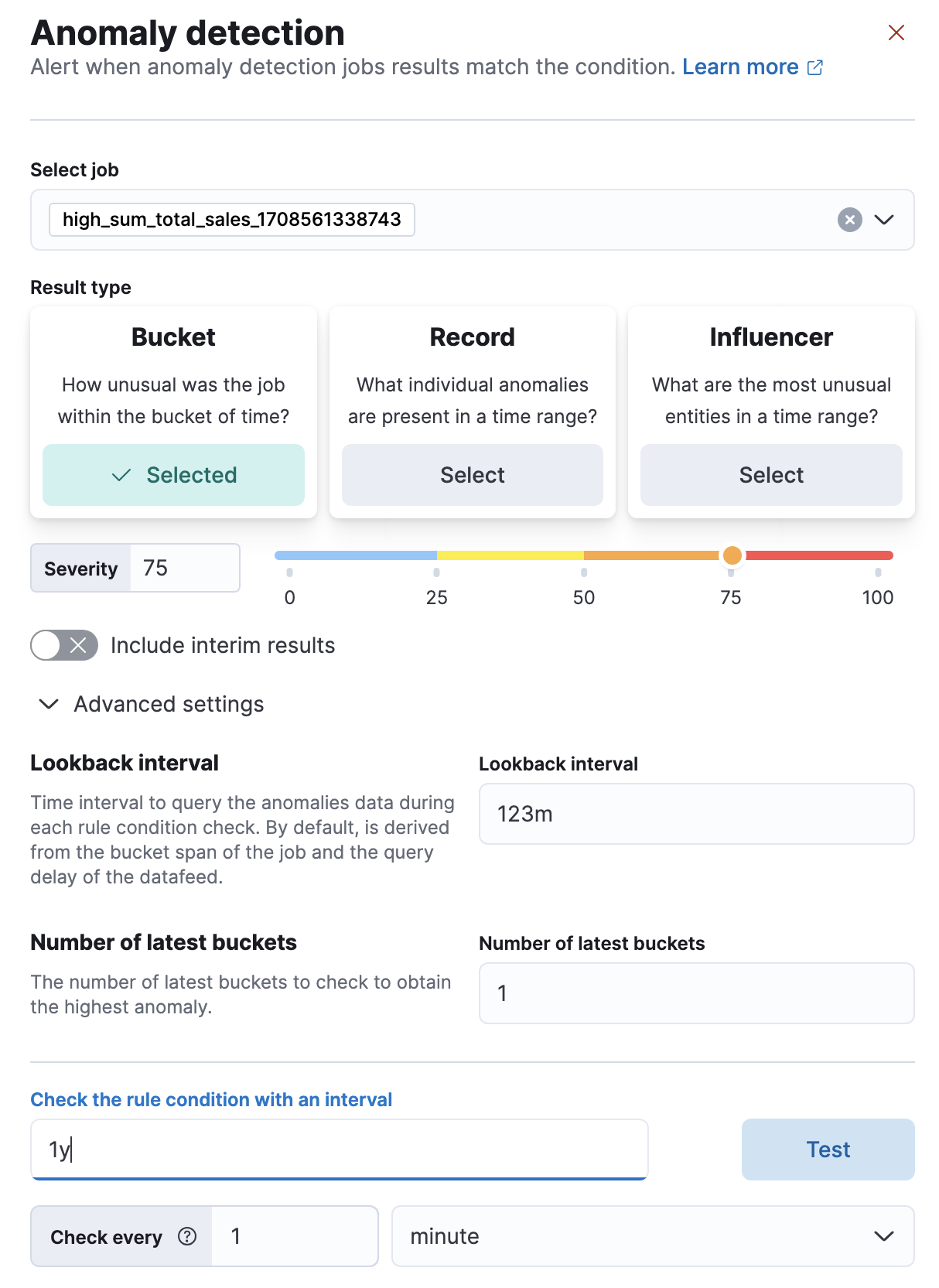
对于每个规则,您可以配置触发操作的 anomaly_score。anomaly_score 表示给定异常相对于先前异常的显著性。默认严重性阈值为 75,这意味着 anomaly_score 为 75 或更高的每个异常都会触发关联的操作。
您可以选择是否要包括临时结果。临时结果是在存储桶最终确定之前由异常检测作业创建的。这些结果可能会在存储桶完全处理后消失。如果您希望更早地收到有关潜在异常的通知(即使它可能是误报),请包括临时结果。如果您只想收到有关完全处理的存储桶的异常通知,则不要包括临时结果。
您还可以配置高级设置。回溯间隔设置一个间隔,该间隔用于在每次条件检查期间查询之前的异常。默认情况下,其值源自作业的存储桶跨度和数据馈送的查询延迟。不建议将回溯间隔设置得低于默认值,因为它可能导致遗漏异常。最新存储桶数设置要检查多少个存储桶,以从回溯间隔期间找到的所有异常中获得最高异常。告警是基于最异常的存储桶中异常分数最高的异常创建的。
您还可以针对现有数据测试配置的条件,并通过为数据提供有效间隔来检查示例结果。生成的预览包含您定义的相对时间范围内可能创建的告警数量。
您还必须提供一个检查间隔,该间隔定义了评估规则条件的频率。建议选择一个接近作业存储桶跨度的间隔。
在规则创建过程的最后一步中,定义其操作。
异常检测作业运行状况规则
编辑创建异常检测作业运行状况规则时,必须选择规则所应用的作业或组。如果您向该组分配了更多作业,则会在下次检查规则条件时将其包括在内。
您还可以使用特殊字符(*)将规则应用于所有作业。在规则之后创建的作业会自动包括在内。您可以使用排除字段排除不重要的作业。
启用您想要应用的运行状况检查类型。默认情况下,所有检查都处于启用状态。必须启用至少一个检查才能创建规则。以下运行状况检查可用:
- 数据馈送未启动
- 如果作业的相应数据馈送未启动但作业处于打开状态,则会发出通知。通知消息建议解决错误所需的必要操作。
- 模型内存限制已达到
- 如果作业的模型内存状态达到软或硬模型内存限制,则会发出通知。通过遵循这些准则来优化您的作业,或者考虑修改模型内存限制。
- 发生数据延迟
- 当作业遗漏某些数据时发出通知。您可以通过设置文档数来定义收到告警的遗漏文档量的阈值。您可以使用时间间隔来控制用于检查延迟数据的回溯间隔。请参阅处理延迟数据页面,了解如何处理延迟数据。
- 作业消息中的错误
- 当作业消息包含错误消息时发出通知。查看通知;它包含错误消息、相应的作业 ID 以及有关如何解决问题的建议。此检查查找在规则创建后发生的作业错误;它不查看历史行为。
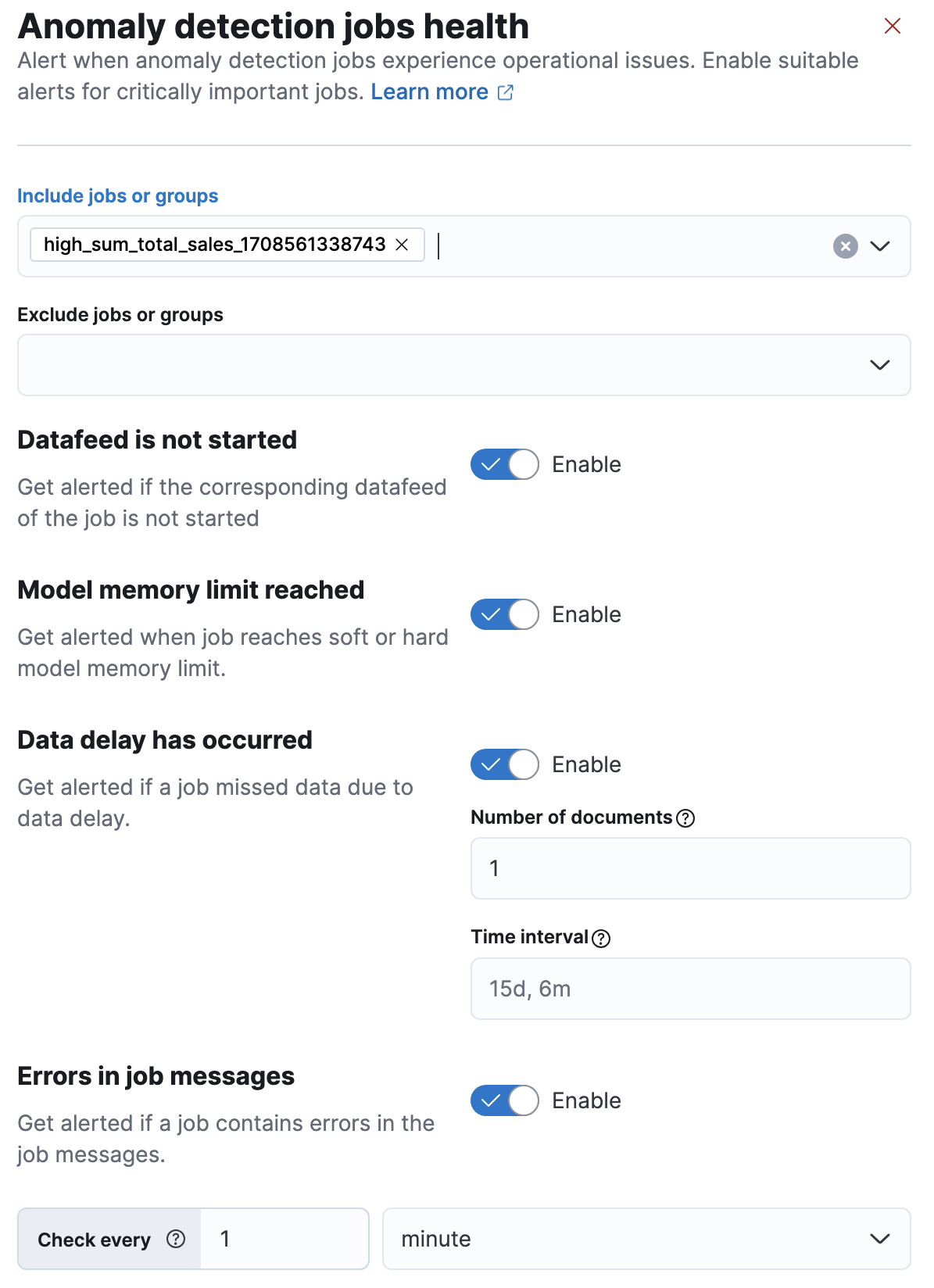
您还必须提供一个检查间隔,该间隔定义了评估规则条件的频率。建议选择一个接近作业存储桶跨度的间隔。
在规则创建过程的最后一步中,定义其操作。
操作
编辑您可以选择在满足规则条件时以及不再满足规则条件时发送通知。特别是,这些规则支持:
- 告警摘要
- 当异常分数与条件匹配时运行的操作(对于异常检测告警规则)
- 当检测到问题时运行的操作(对于异常检测作业运行状况规则)
- 当不再满足条件时运行的恢复操作
每个操作都使用一个连接器,该连接器存储 Kibana 服务或支持的第三方集成的连接信息,具体取决于您想要将通知发送到哪里。例如,您可以使用 Slack 连接器向频道发送消息。或者,您可以使用索引连接器将 JSON 对象写入特定索引。有关创建连接器的详细信息,请参阅连接器。
选择连接器后,必须设置操作频率。您可以选择在每次检查间隔或自定义间隔时创建告警摘要。例如,发送 Slack 通知,汇总新的、正在进行的和已恢复的告警
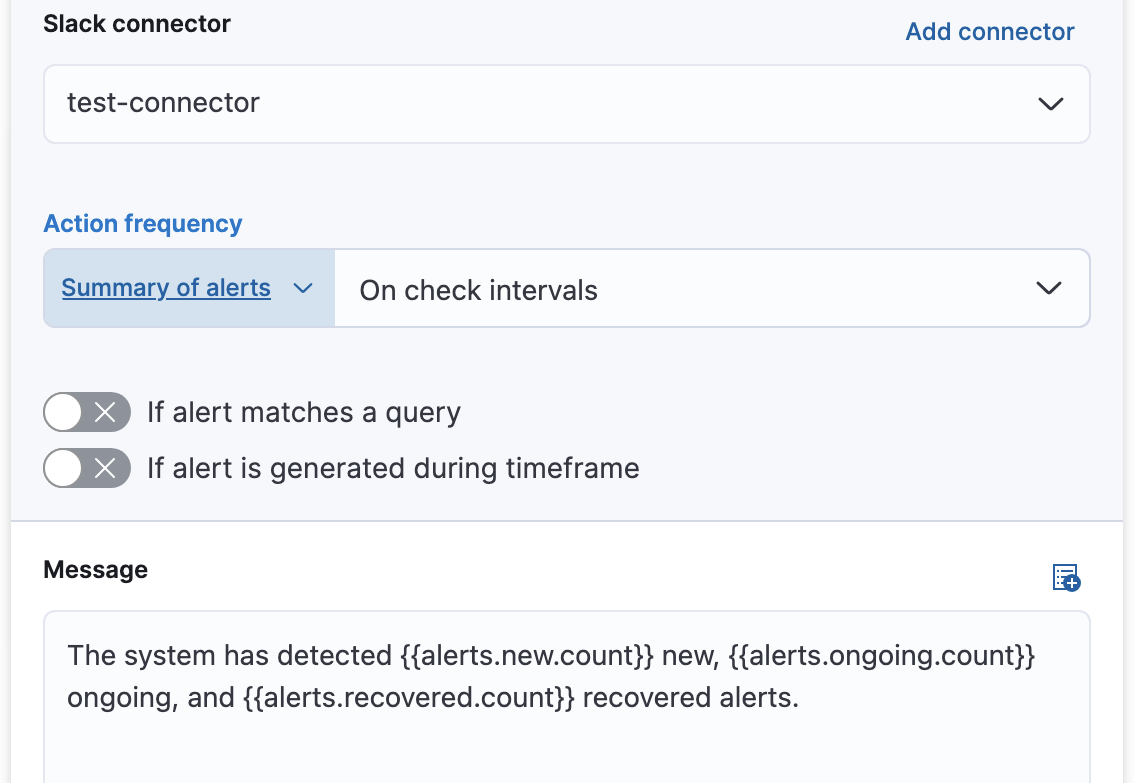
如果您选择自定义操作间隔,则该间隔不能短于规则的检查间隔。
或者,您可以设置操作频率,以便操作针对每个告警运行。选择操作运行的频率(在每个检查间隔、仅当告警状态更改时或在自定义操作间隔)。对于异常检测告警规则,您还必须选择操作是在异常分数与条件匹配时运行还是在告警恢复时运行
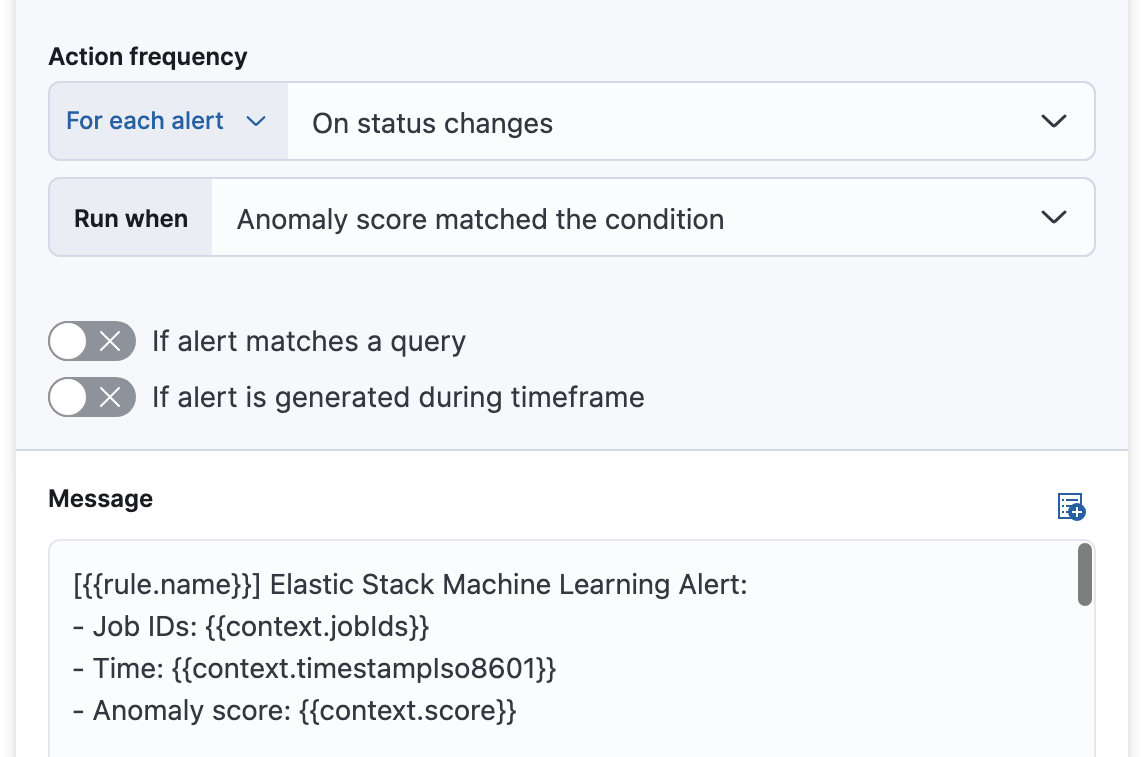
在异常检测作业运行状况规则中,选择操作是在检测到问题时运行还是在问题恢复时运行
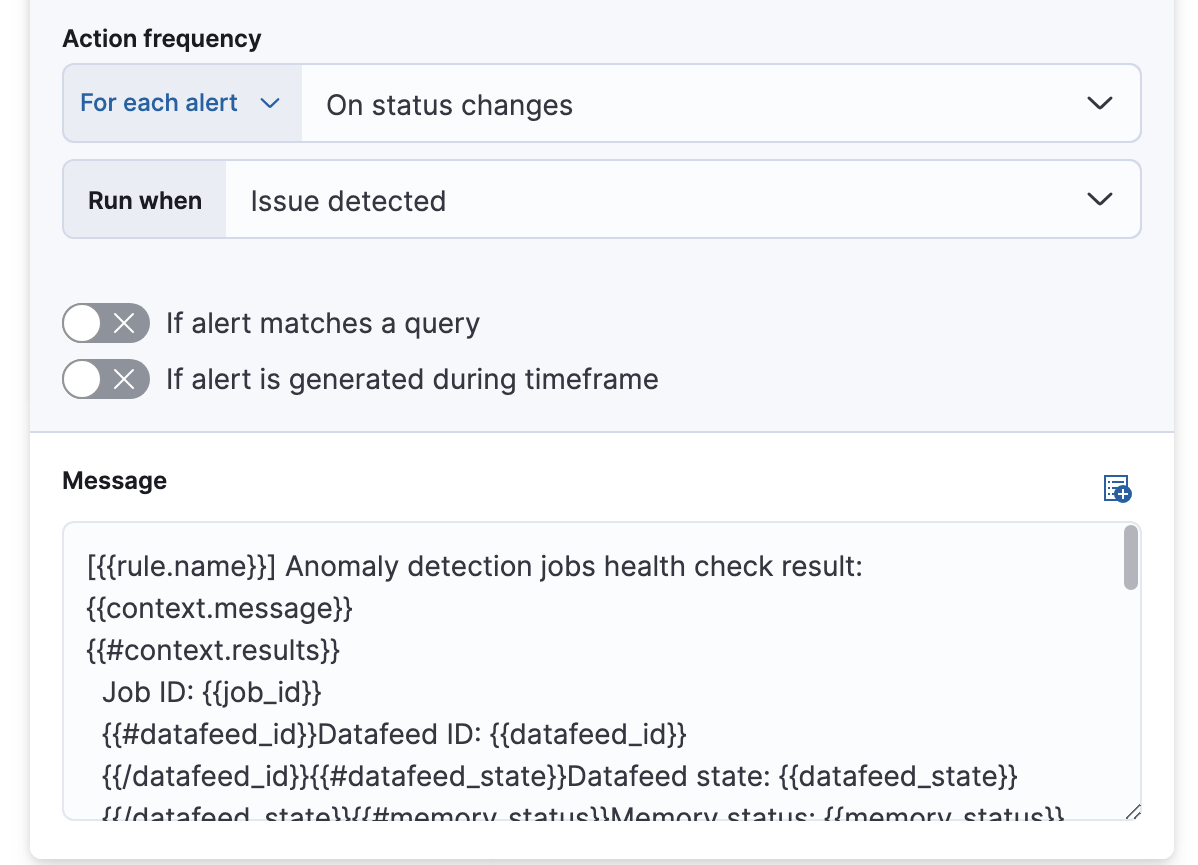
您可以通过指定操作仅在它们匹配 KQL 查询时或在特定时间范围内发生告警时运行来进一步优化规则。
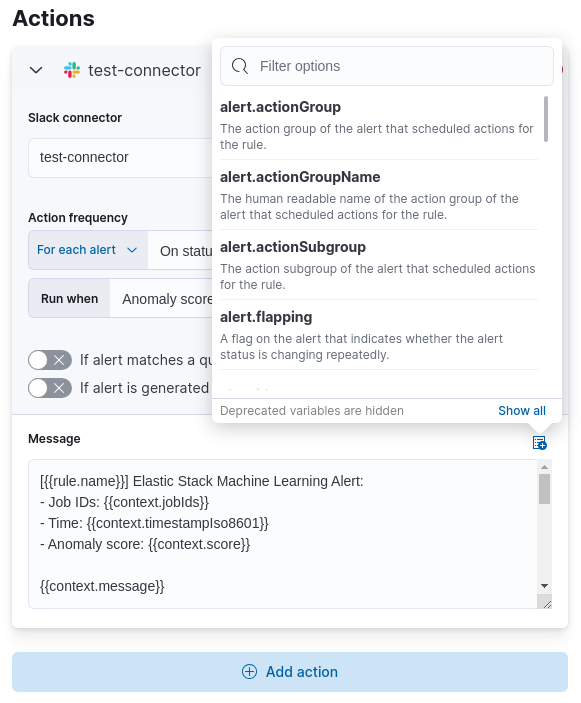
有一组变量可用于自定义每个操作的通知消息。单击消息文本框上方的图标以获取变量列表,或参阅操作变量。例如
保存配置后,该规则将显示在 Stack Management > 规则 列表中;您可以检查其状态并查看其配置信息的概述。
当异常检测告警规则发生告警时,其名称始终与触发该告警的相关异常检测作业的作业 ID 相同。您可以使用异常浏览器中的异常时间线泳道和告警面板,查看发生的告警如何与异常检测结果相关联。
如有必要,您可以暂停规则以防止它们生成操作。有关更多详细信息,请参阅暂停和禁用规则。
操作变量
编辑以下变量是机器学习规则类型特有的。星号(*)标记您可以在与已恢复告警相关的操作中使用的变量。
您还可以指定所有规则通用的变量。
异常检测告警操作变量
编辑每个异常检测告警都有以下操作变量:
-
context.anomalyExplorerUrl* - 在异常浏览器中打开的 URL。
-
context.isInterim - 指示前几条命中是否包含临时结果。
-
context.jobIds* - 触发告警的作业 ID 列表。
-
context.message* - 告警的预构建消息。
-
context.score - 通知操作时的异常分数。
-
context.timestamp - 异常的存储桶时间戳。
-
context.timestampIso8601 - ISO8601 格式的异常的存储桶时间戳。
-
context.topInfluencers -
顶级影响因素列表。
context.topInfluencers的属性-
influencer_field_name - 影响因素的字段名称。
-
influencer_field_value - 导致异常、对此做出贡献或应为此负责的实体。
-
score - 影响因素得分。一个介于 0-100 之间的归一化分数,表示影响因素对异常的总体贡献。
-
-
context.topRecords -
顶级记录列表。
context.topRecords的属性-
actual - 存储桶的实际值。
-
by_field_value - by 字段的值。
-
field_name - 某些函数需要一个字段才能操作,例如
sum()。对于这些函数,此值是要分析的字段的名称。 -
function - 在检测器配置中指定的,发生异常的函数。例如,
max。 -
over_field_name - 用于拆分数据的字段。
-
partition_field_value - 用于分割分析的字段。
-
score - 一个介于 0-100 之间的归一化分数,它基于此记录异常的概率。
-
typical - 根据分析建模,存储桶的典型值。
-
异常检测作业运行状况操作变量
编辑每个运行状况检查都有两个主要变量:context.message 和 context.results。context.results 的属性可能因检查类型而异。您可以在下面找到所有检查的可能属性。
数据馈送未启动
编辑-
context.message* - 告警的预构建消息。
-
context.results -
包含以下属性
context.results的属性-
datafeed_id* - 数据馈送标识符。
-
datafeed_state* - 数据馈送的状态。它可以是
starting、started、stopping、stopped。 -
job_id* - 作业标识符。
-
job_state* - 作业的状态。它可以是
opening、opened、closing、closed或failed。
-
已达到模型内存限制
编辑-
context.message* - 规则的预构建消息。
-
context.results -
包含以下属性
context.results的属性-
job_id* - 作业标识符。
-
memory_status* -
数学模型的状态。它可以具有以下值之一
-
soft_limit:模型使用的内存超过了配置的内存限制的 60%,并且将修剪旧的未使用模型以释放空间。在分类作业中,不会存储进一步的类别示例。 -
hard_limit:模型使用的空间超过了配置的内存限制。因此,并非所有传入的数据都得到了处理。
-
对于恢复的警报,
memory_status为ok。-
model_bytes* - 模型使用的内存字节数。
-
model_bytes_exceeded* - 上次分配失败时,超出内存使用量上限的字节数。
-
model_bytes_memory_limit* - 模型内存使用量的上限。
-
log_time* - 根据服务器时间,模型大小统计信息的时间戳。时间格式基于 Kibana 设置。
-
peak_model_bytes* - 模型曾经使用的内存峰值字节数。
-
已发生数据延迟
编辑-
context.message* - 规则的预构建消息。
-
context.results -
对于已恢复的警报,
context.results为空(当没有延迟数据时)或与活动警报相同(当丢失的文档数小于用户设置的“文档数”阈值时)。包含以下属性context.results的属性-
annotation* - 与作业中的数据延迟对应的注释。
-
end_timestamp* - 具有丢失文档的最新最终确定存储桶的时间戳。时间格式基于 Kibana 设置。
-
job_id* - 作业标识符。
-
missed_docs_count* - 丢失的文档数。
-
作业消息中出现错误
编辑-
context.message* - 规则的预构建消息。
-
context.results -
包含以下属性
context.results的属性-
timestamp - 具有丢失文档的最新最终确定存储桶的时间戳。
-
job_id - 作业标识符。
-
message - 错误消息。
-
node_name - 运行作业的节点的名称。
-