训练模型
编辑训练模型
编辑当你使用数据框分析作业执行分类或回归分析时,它会创建一个机器学习模型,该模型根据标记的数据集进行训练和测试。当你对训练好的模型感到满意时,可以使用它对新数据进行预测。例如,你可以在摄取管道的处理器中使用它,或者在搜索查询中的管道聚合中使用它。有关此过程的更多信息,请参阅有监督学习简介以及分类推理和回归推理。
在 Kibana 中,你可以在堆栈管理 > 告警和见解 > 机器学习和 机器学习 > 模型管理中查看和管理你的训练模型。
或者,你可以使用 API,如 获取训练模型和 删除训练模型。
部署训练模型
编辑由数据框分析训练的模型
编辑- 要在管道中部署数据框分析模型,请在 Kibana 中导航到机器学习 > 模型管理 > 训练模型。
-
在列表中找到要部署的模型,然后在操作菜单中单击部署模型。
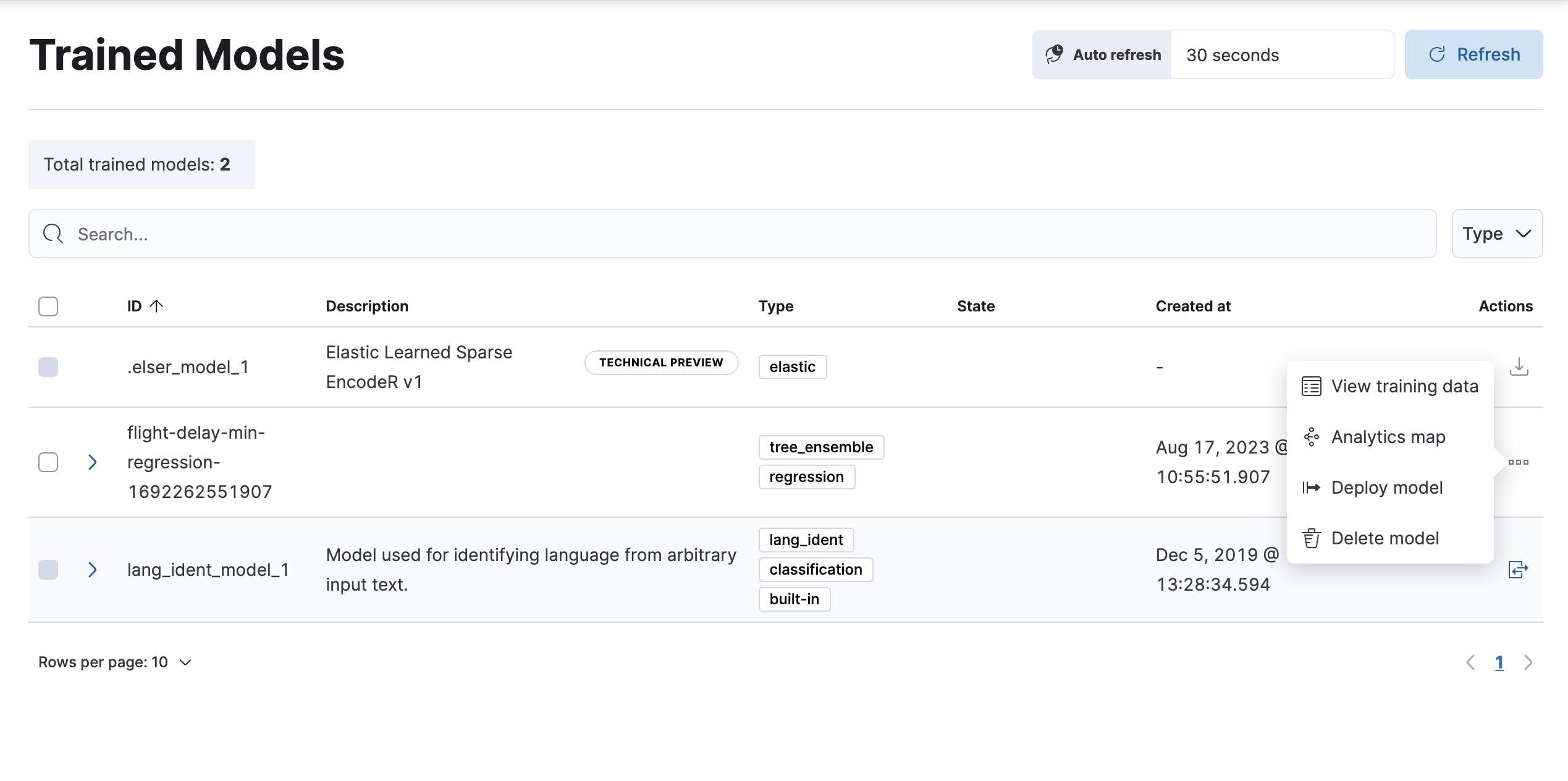
-
创建一个推理管道,以便能够通过管道对新数据使用该模型。添加名称和描述或使用默认值。
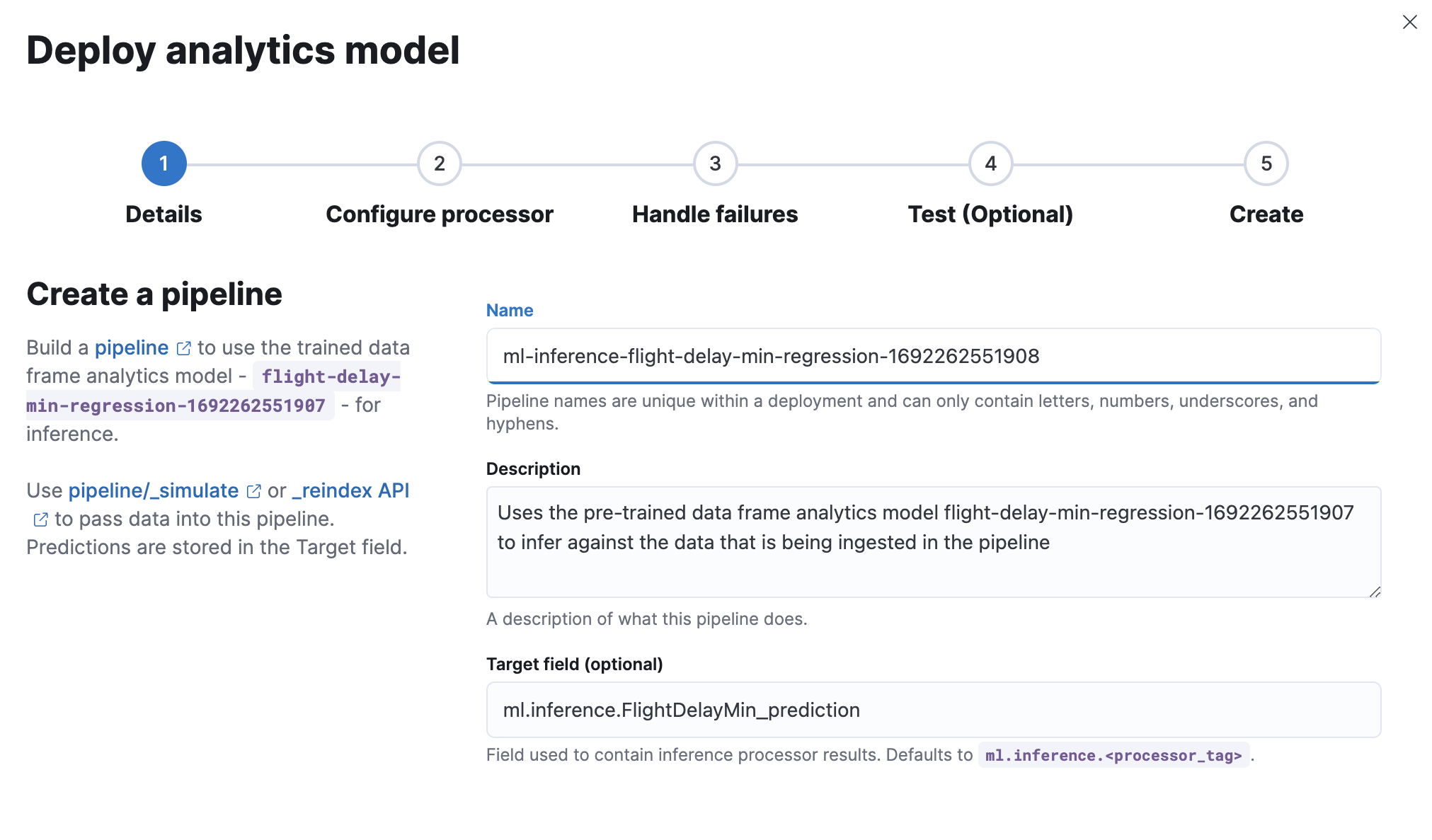
-
配置管道处理器或使用默认设置。
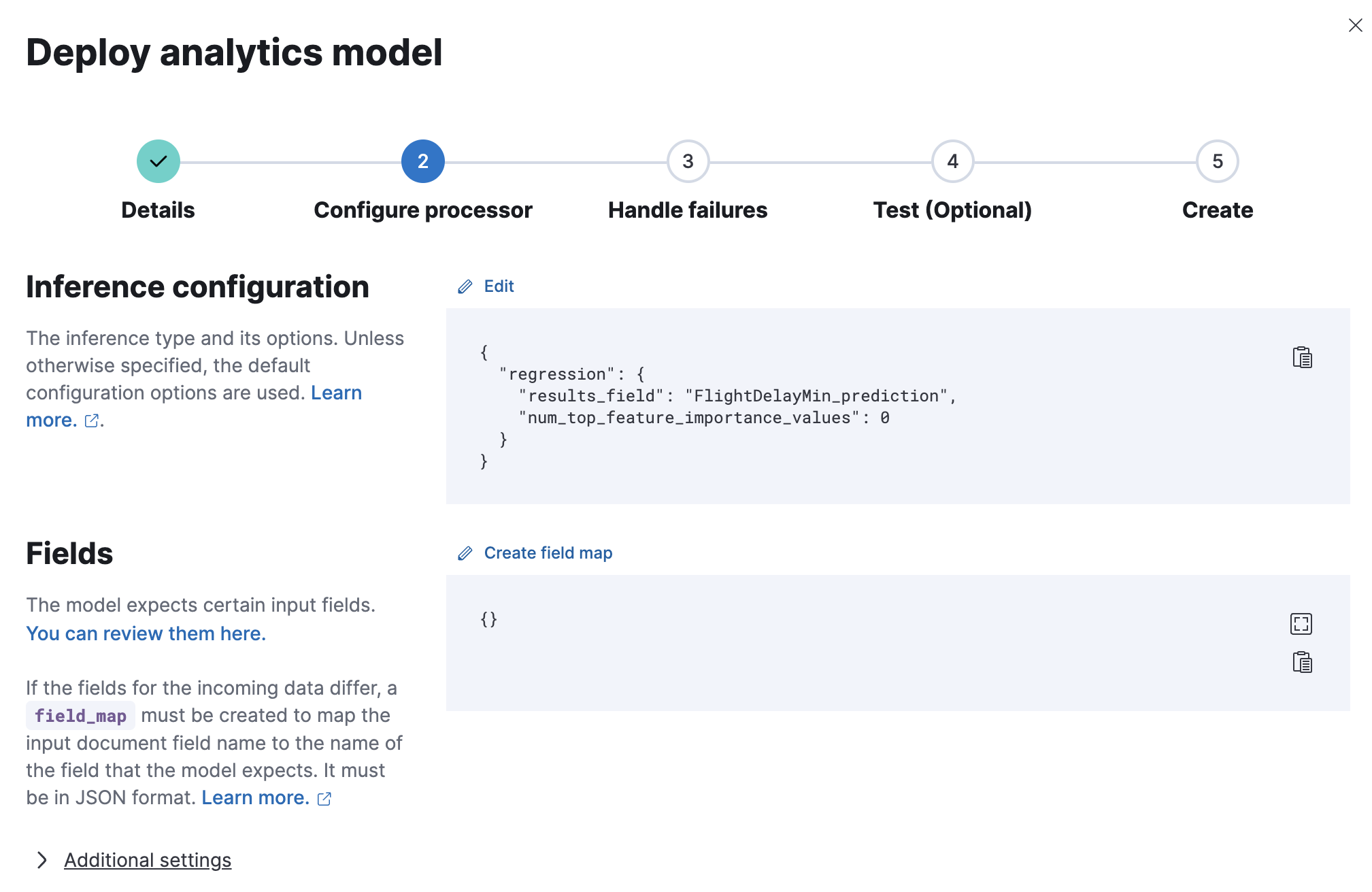
- 配置以处理摄取失败或使用默认设置。
- (可选)通过运行管道模拟来测试你的管道,以确认它产生预期的结果。
- 查看设置并单击创建管道。
该模型已部署,可以通过推理管道使用。
其他方法训练的模型
编辑你还可以提供不是由数据框分析作业创建但符合适当的JSON 模式的训练模型。同样,你可以使用第三方模型来执行自然语言处理 (NLP) 任务。如果你想在 Elastic Stack 中使用这些训练模型,你必须使用创建训练模型 API 将它们存储在 Elasticsearch 文档中。有关 NLP 模型的更多信息,请参阅部署训练模型。
导出和导入模型
编辑在 Elasticsearch 中训练的模型是可移植的,可以在集群之间传输。当模型与用于推理的集群隔离训练时,这尤其有用。以下说明展示了如何使用 curl 和 jq 将模型导出为 JSON 并将其导入到另一个集群。
-
给定一个模型名称,找到模型ID。你可以使用
curl调用 获取训练模型 API 列出所有模型及其 ID。curl -s -u username:password \ -X GET "https://127.0.0.1:9200/_ml/trained_models" \ | jq . -C \ | more如果你只想显示可用的模型 ID,请使用
jq选择一个子集。curl -s -u username:password \ -X GET "https://127.0.0.1:9200/_ml/trained_models" \ | jq -C -r '.trained_model_configs[].model_id'flights1-1607953694065 flights0-1607953585123 lang_ident_model_1
在此示例中,你正在导出 ID 为
flights1-1607953694065的模型。 -
再次使用命令行中的
curl,使用 获取训练模型 API 导出整个模型定义并将其保存到 JSON 文件。curl -u username:password \ -X GET "https://127.0.0.1:9200/_ml/trained_models/flights1-1607953694065?exclude_generated=true&include=definition&decompress_definition=false" \ | jq '.trained_model_configs[0] | del(.model_id)' \ > flights1.json一些注意事项
- 导出模型需要使用
curl或类似的工具,可以将模型通过 HTTP 流式传输到文件中。如果你使用 Kibana 控制台,由于导出模型的大小,浏览器可能会无响应。 - 请注意导出期间使用的查询参数。这些参数对于以可以稍后再次导入并用于推理的方式导出模型是必要的。
- 你必须将 JSON 对象解嵌套一级以仅提取模型定义。你还必须删除现有的模型 ID,以免再次导入时发生 ID 冲突。你可以使用
jq内联完成这些步骤,或者也可以在下载后使用jq或其他工具对生成的 JSON 文件执行这些操作。
- 导出模型需要使用
-
使用
curl导入保存的模型,将 JSON 文件上传到创建训练模型 API。当你指定 URL 时,你还可以使用 URL 的最后一个路径部分将模型 ID 设置为新的 ID。curl -u username:password \ -H 'Content-Type: application/json' \ -X PUT "https://127.0.0.1:9200/_ml/trained_models/flights1-imported" \ --data-binary @flights1.json
- 从 获取训练模型 API 导出的模型的大小受 Elasticsearch 中 http.max_content_length 全局配置值的限制。默认值为
100mb,可能需要根据导出的模型的大小进行增加。 - 可能会发生连接超时,例如,当模型大小非常大或你的集群处于负载下时。如果需要,你可以增加
curl的 超时配置(例如,curl --max-time 600)或你选择的客户端。
如果你还想将数据框分析作业复制到新集群,你可以在 Kibana 中的堆栈管理应用程序中导出和导入作业。请参阅导出和导入机器学习作业。
将外部模型导入到 Elastic Stack
编辑即使模型不是由 Elastic 数据框分析训练的,也可以将模型导入到你的 Elasticsearch 集群。Eland 支持通过其 API 直接导入模型。请参阅最新的Eland 文档,了解有关支持的模型类型以及使用 Eland 导入模型的其他详细信息的更多信息。