数据框分析概述
编辑数据框分析概述
编辑数据框分析使您能够对数据执行不同的分析,并用结果对其进行注释。 通过这样做,它可以提供对数据的额外见解。 异常值检测识别数据集中的异常数据点。 回归在确定数据点之间的某些关系后,对您的数据进行预测。 分类预测数据集中给定数据点的类别或种类。 推理使您能够以连续的方式对传入数据使用训练好的机器学习模型。
此过程保持源索引不变,它创建一个新索引,其中包含源数据的副本和注释数据。您可以像处理任何其他数据集一样,对扩展了结果的数据进行切片和切块。有关更多信息,请阅读 数据框分析作业的工作原理。
您可以通过使用评估数据框分析 API 对标记的数据集进行评估来评估数据框分析的性能。 它可以帮助您了解误差分布,并识别数据框分析模型表现良好或不太可靠的点。
请参阅 监督式学习简介,以了解有关如何使用监督式学习进行预测的更多信息。
表 2. 数据框分析概述表
| 数据框分析类型 | 学习类型 |
|---|---|
异常值检测 |
无监督 |
回归 |
监督式 |
分类 |
监督式 |
监督式学习简介
编辑Elastic 监督式学习使您能够根据您提供的训练示例训练机器学习模型。 然后,您可以使用您的模型对新数据进行预测。 此页面总结了训练、评估和部署模型的端到端工作流程。 它给出了使用监督式学习识别和实现解决方案所需步骤的高级概述。
监督式学习的工作流程包括以下阶段
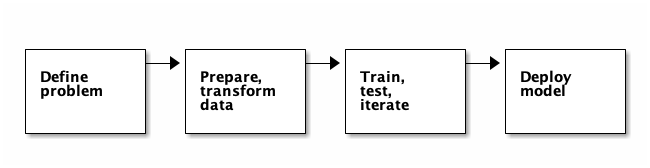
这些是迭代阶段,这意味着在评估每个步骤之后,您可能需要在继续之前进行调整。
定义问题
编辑花点时间思考一下机器学习在哪里可以发挥最大的作用非常重要。考虑您有哪些类型的数据可用,以及它具有什么价值。 您对数据了解得越多,就越能更快地创建可以生成有用见解的机器学习模型。您想在数据中发现哪些类型的模式?您想预测哪种类型的价值:类别还是数值? 答案可以帮助您选择适合您的用例的分析类型。
在确定问题后,请考虑哪些机器学习功能最有可能帮助您解决问题。 监督式学习需要一个包含模型可以基于其进行训练的已知值的数据集。无监督学习(如异常检测或异常值检测)没有此要求。
Elastic Stack 提供以下类型的监督式学习
- 回归:预测连续的数值,例如 Web 请求的响应时间。
- 分类:预测离散的类别值,例如DNS 请求是否来自恶意域或良性域。
准备和转换数据
编辑您已经定义了问题并选择了合适的分析类型。 下一步是在 Elasticsearch 中生成一个与您的训练目标具有明确关系的高质量数据集。 如果您的数据尚未在 Elasticsearch 中,则这是您开发数据管道的阶段。 如果您想了解有关如何将数据摄取到 Elasticsearch 中的更多信息,请参阅摄取节点文档。
回归和分类是监督式机器学习技术,因此您必须提供用于训练的标记数据集。 这通常称为“真实数据”。 训练过程使用此信息来识别数据的各种特征和预测值之间的关系。 它还在模型评估中起着至关重要的作用。
一个重要的要求是数据集足够大,可以训练模型。 例如,如果您想训练一个分类模型来决定电子邮件是否是垃圾邮件,则需要一个标记数据集,其中包含来自每个可能类别的足够数据点来训练模型。 “足够”的计数取决于各种因素,例如问题的复杂性或您选择的机器学习解决方案。 没有适合所有用例的精确数字;决定可以接受多少数据是一个启发式过程,可能涉及迭代试验。
在训练模型之前,请考虑预处理数据。 实际上,预处理的类型取决于数据集的性质。 预处理可以包括但不限于缓解冗余、减少偏差、应用标准和/或约定、数据标准化等等。
回归和分类需要特定结构的源数据:二维表格数据结构。 因此,您可能需要转换您的数据以创建可以用作这些类型数据框分析源的数据框。
训练、测试、迭代
编辑在您的数据准备好并转换为正确的格式后,就该训练模型了。 训练是一个迭代过程,每次迭代之后都要进行评估,以了解模型的性能如何。
第一步是定义特征——数据集中将用于训练模型的相关字段。默认情况下,所有具有支持类型的字段都会自动包含在回归和分类中。但是,您可以选择从该过程中排除不相关的字段。这样做可以使大型数据集更易于管理,从而减少训练所需的计算资源和时间。
接下来,您必须定义如何将数据拆分为训练集和测试集。 测试集不会用于训练模型; 它用于评估模型的性能。 没有适合所有用例的最佳百分比,这取决于数据量和您用于训练的时间。 对于大型数据集,您可能希望从较低的训练百分比开始,以便在短时间内完成端到端迭代。
在训练过程中,训练数据通过学习算法输入。 模型预测值并将其与真实数据进行比较,然后对模型进行微调以使预测更准确。
模型训练完成后,您可以使用模型泛化误差来评估它如何预测以前未见过的数据。 对于回归和分类分析,还有其他评估类型,它们提供有关训练性能的指标。 当您对结果感到满意时,就可以部署模型了。 否则,您可能需要调整训练配置或考虑其他方法来预处理和表示您的数据。
部署模型
编辑您已经训练了模型,并且对性能感到满意。 最后一步是部署您训练的模型,并开始将其用于新数据。
Elastic 机器学习功能(称为推理)使您可以通过在摄取管道中将其用作处理器、在连续转换中或在搜索时将其用作聚合来对新数据进行预测。 当新数据进入您的摄取管道或您对数据运行带有推理聚合的搜索时,该模型将用于对数据进行推理并对其进行预测。
后续步骤
编辑- 阅读有关如何将您的数据转换为以实体为中心的索引的更多信息。
- 查阅文档以了解有关回归和分类的更多信息。
- 了解如何评估回归和分类模型。
- 了解如何通过对分类和回归使用推理来部署模型。
- 训练、评估、监控、推理:Elastic 中的端到端机器学习.