事务采样
编辑事务采样
编辑分布式追踪会产生大量数据。更多数据意味着更高的成本和更多噪音。采样的目的是降低摄取的数据量和分析这些数据所需的工作量,同时仍然能够轻松找到应用程序中的异常模式、检测故障、跟踪错误并降低平均恢复时间 (MTTR)。
Elastic APM 支持两种类型的采样
在头部采样中,每个跟踪的采样决策是在跟踪启动时做出的。每个跟踪都有一个定义的且相等的被采样概率。
例如,采样值为 .2 表示事务采样率为 20%。这意味着只有 20% 的跟踪将发送并保留其所有关联信息。其余跟踪将丢弃上下文信息以减少跟踪的传输和存储大小。
头部采样设置起来快速简便。它的缺点是完全随机——有趣的数据可能仅仅由于偶然性而被丢弃。
请参阅 配置头部采样 开始使用。
在分布式追踪中,采样决策仍然是在跟踪启动时做出的。每个后续服务都会尊重初始服务的采样决策,而不管其配置的采样率如何;结果是采样百分比与启动服务匹配。
在图 1 的示例中,服务 A 启动四个事务,采样率为 .5 (50%)。上游采样决策被尊重,因此即使在服务 B 和 服务 C 中定义了采样率并且值不同,所有服务的采样率也将为 .5 (50%)。
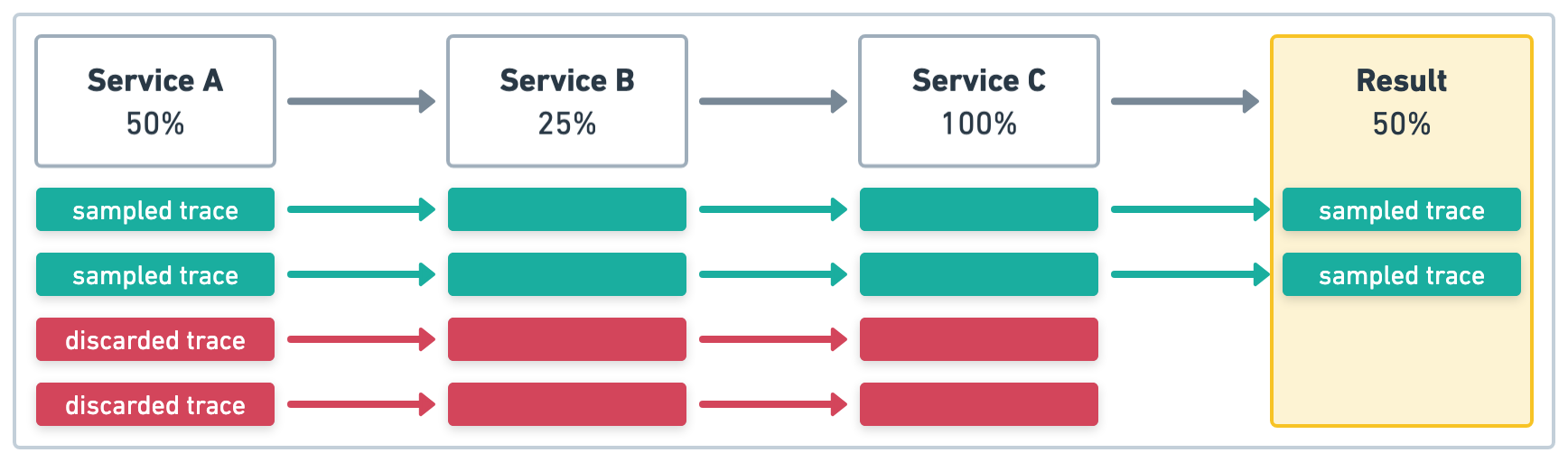
在图 2 的示例中,服务 A 启动四个事务,采样率为 1 (100%)。同样,上游采样决策被尊重,因此所有服务的采样率都将为 1 (100%)。
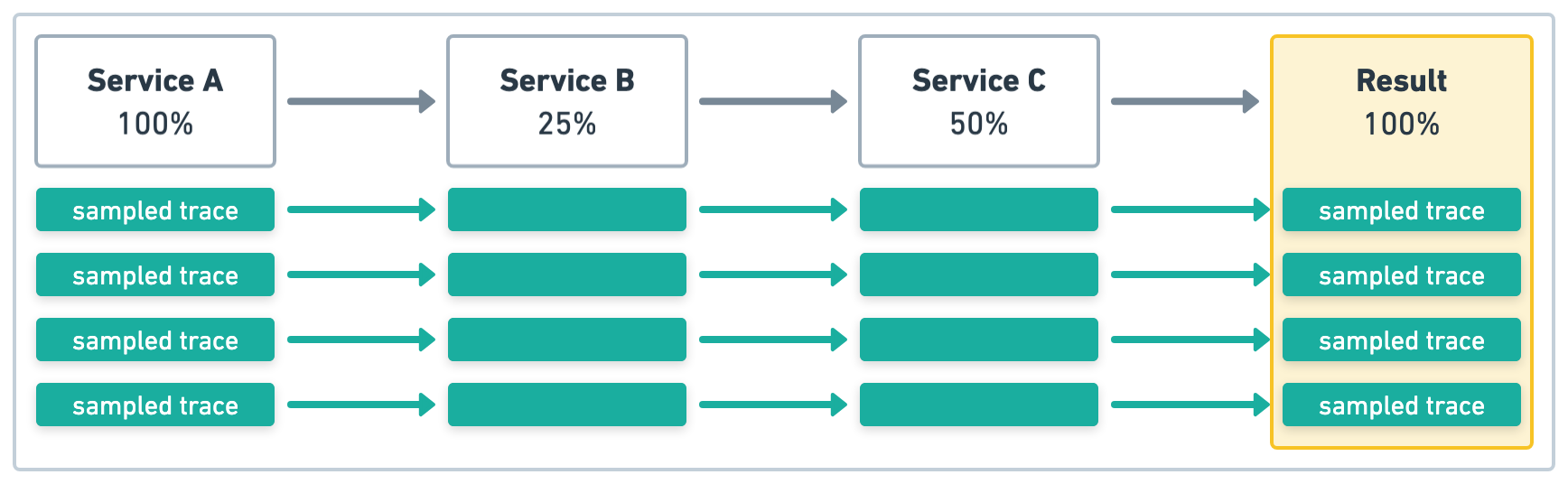
除了设置采样率外,还可以指定要使用的追踪延续策略。有三种追踪延续策略:continue、restart 和 restart_external。
continue 追踪延续策略是默认策略,其行为类似于分布式追踪部分中的示例。
在 Elastic 监控的服务上使用 restart_external 追踪延续策略,如果之前的服务没有带有 es 供应商数据的 traceparent 头,则启动一个新的追踪。如果事务包含从未监控服务接收请求的 Elastic 监控服务,这将非常有用。
在图 3 的示例中,服务 A 是一个 Elastic 监控的服务,它以 .25 (25%) 的采样率启动四个事务。因为 服务 B 未被监控,所以在 服务 A 中启动的追踪将在那里结束。服务 C 是一个 Elastic 监控的服务,它启动四个事务,这些事务以新的采样率 .5 (50%) 开始新的追踪。因为 服务 D 也是 Elastic 监控的服务,所以尊重在 服务 C 中定义的上游采样决策。最终结果将是三个采样追踪。
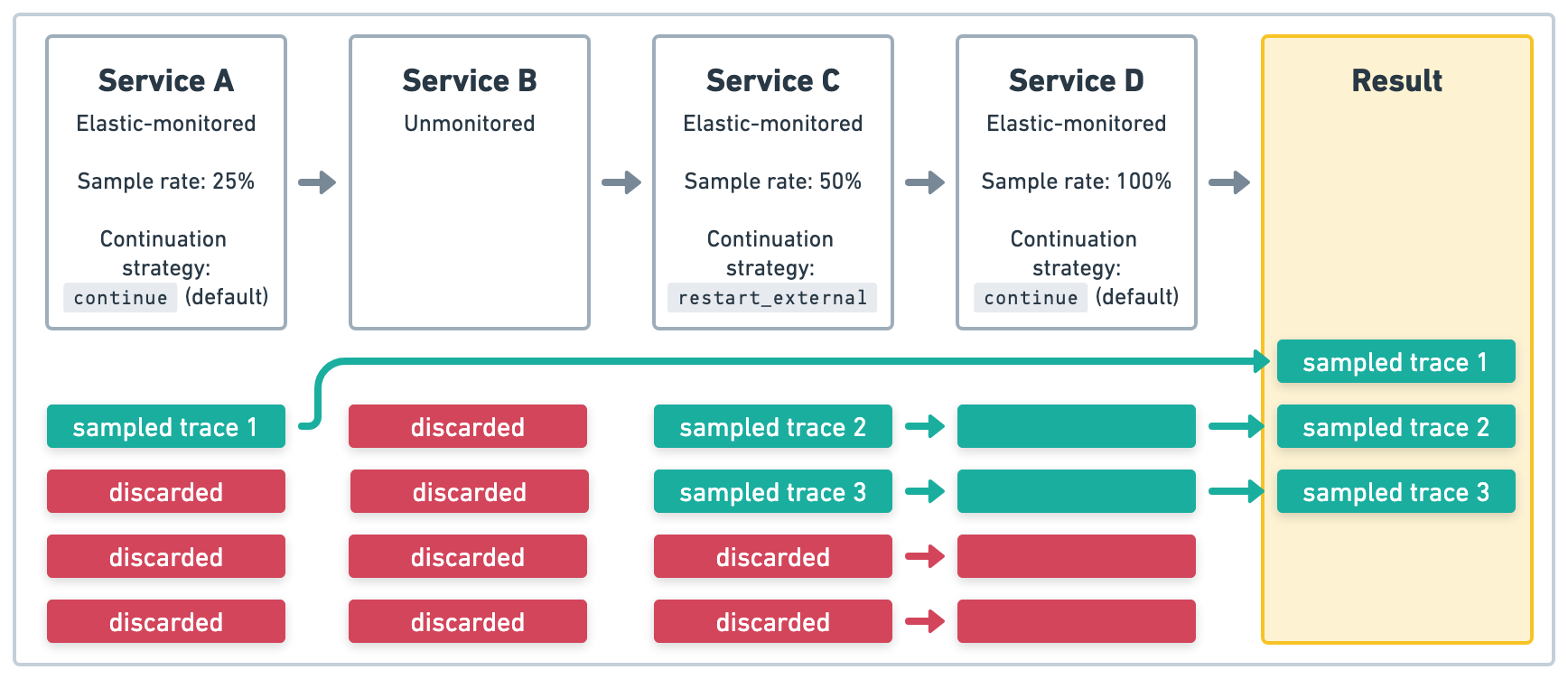
restart_external 追踪延续策略在 Elastic 监控的服务上使用 restart 追踪延续策略,以启动新的追踪,而不管之前的服务是否具有 traceparent 头。如果 Elastic 监控的服务是公开暴露的,并且您不希望追踪数据可能被用户请求欺骗,这将非常有用。
在图 4 的示例中,服务 A 和 服务 B 是使用默认追踪延续策略的 Elastic 监控的服务。服务 A 的采样率为 .25 (25%),并且该采样决策在 服务 B 中被尊重。服务 C 是一个使用 restart 追踪延续策略且采样率为 1 (100%) 的 Elastic 监控的服务。因为它使用了 restart,所以 服务 C 中不尊重上游采样率,所有四个追踪都将作为 服务 C 中的新追踪进行采样。最终结果将是五个采样追踪。
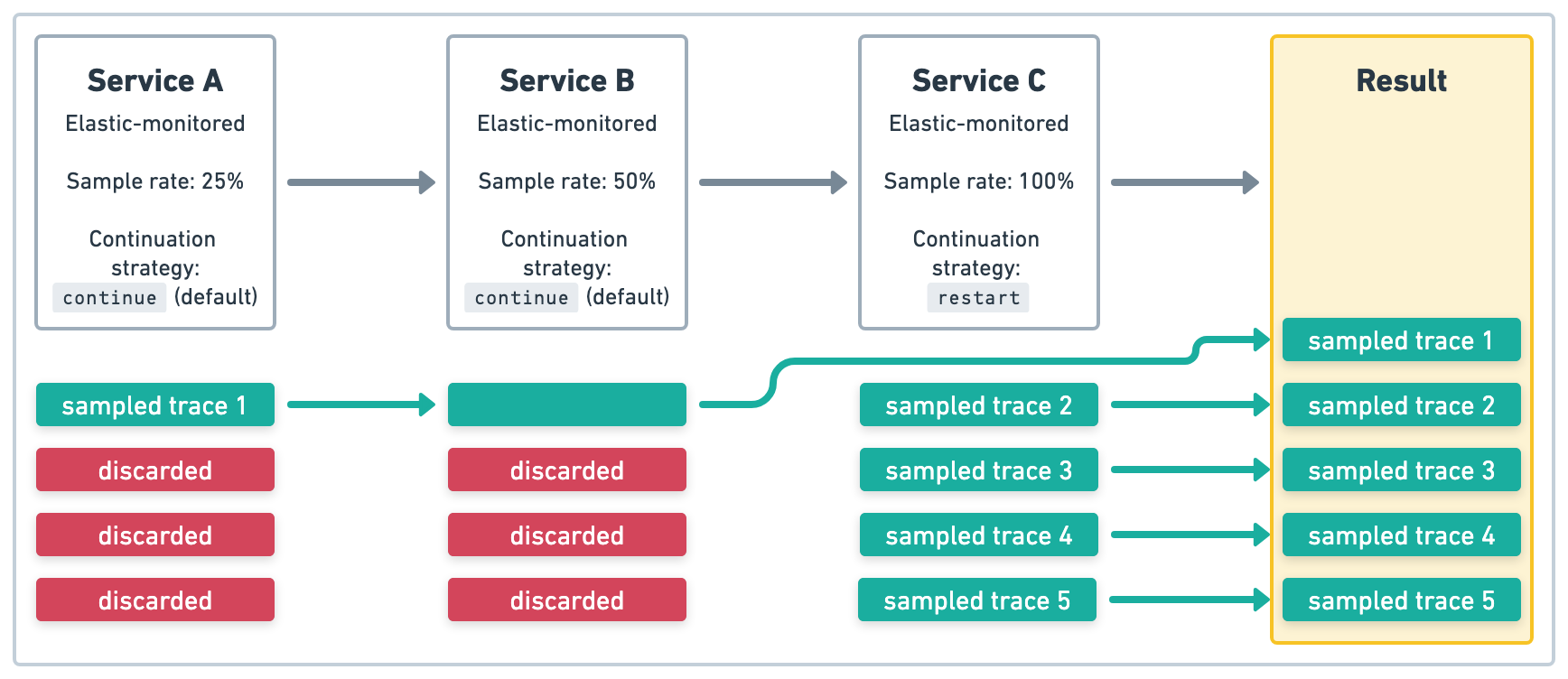
restart 追踪延续策略头部采样直接在 APM 代理和 SDK 中实现。为了生成准确的指标,必须在服务和托管的摄取服务之间传播采样率。
OpenTelemetry 提供多个采样器。但是,大多数采样器不会传播采样率。这会导致基于跨度的指标(如 APM 吞吐量、延迟和错误指标)不准确。
为了在使用 OpenTelemetry 进行头部采样时获得准确的基于跨度的指标,必须使用 一致概率采样器。这些采样器在服务和托管的摄取服务之间传播采样率,从而产生准确的指标。
OpenTelemetry 并非在所有语言中都提供一致的概率采样器。OpenTelemetry 用户应考虑改用尾部采样。
有关一致概率采样器的可用性的更多信息,请参阅您最喜欢的 OpenTelemetry 代理或 SDK 的文档。
在尾部采样中,每个跟踪的采样决策是在跟踪完成后做出的。这意味着所有跟踪都将根据一组规则或策略进行分析,这些规则或策略将确定它们的采样率。
与头部采样不同,每个跟踪的采样概率并不相等。因为较慢的跟踪比较快的跟踪更有趣,所以尾部采样使用加权随机采样——因此根事务持续时间较长的跟踪比根事务持续时间较短的跟踪更有可能被采样。
尾部采样的缺点是它会导致从 APM 代理发送到 APM 服务器的数据更多。因此,与头部采样相比,APM 服务器将使用更多 CPU、内存和磁盘。但是,由于尾部采样决策发生在 APM 服务器中,因此从 APM 服务器到 Elasticsearch 的数据传输量更少。因此,将 APM 服务器部署在靠近已检测服务的附近可以减少尾部采样带来的任何传输成本增加。
请参阅 配置尾部采样 开始使用。
使用尾部采样,将观察所有跟踪,并且只有在跟踪完成后才会做出采样决策。
在此示例中,服务 A 启动四个事务。如果对于结果为 success 的跟踪,我们的采样率为 .5 (50%),而对于结果为 failure 的跟踪,采样率为 1 (100%),则采样跟踪将如下所示
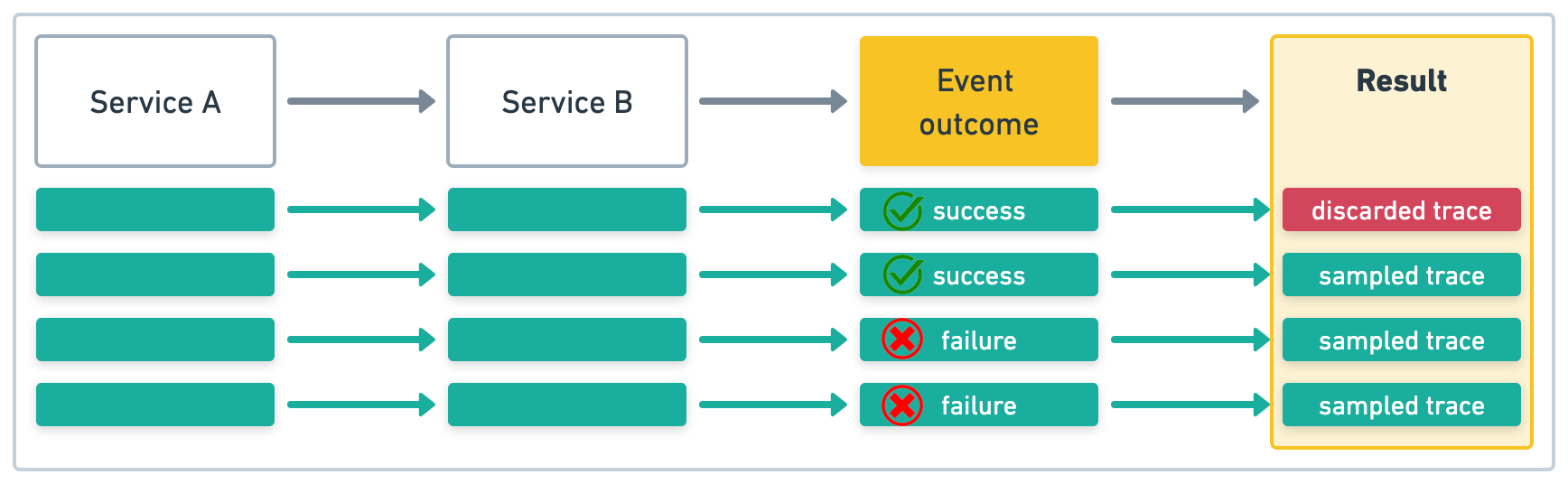
尾部采样完全在 APM 服务器中实现,并且可以与 Elastic APM 代理或 OpenTelemetry SDK 发送的跟踪一起使用。
由于使用 tailsamplingprocessor 时 OpenTelemetry 尾部采样限制,我们建议改用 APM 服务器尾部采样。
采样跟踪保留与其关联的所有数据。未采样跟踪将丢弃所有 跨度 和 事务 数据1。无论采样决策如何,所有跟踪都保留 错误 数据。
APM 应用程序中的一些可视化(如延迟)由聚合的事务和跨度 指标 提供支持。这些指标的计算方式取决于使用的采样方法
- 头部采样:指标根据所有采样事件计算。
- 尾部采样:指标根据所有事件计算,而不管它们最终是否被采样。
- 头部和尾部采样:同时使用这两种方法时,指标根据头部采样策略采样的所有事件计算。
对于所有采样方法,指标都按头部采样策略的反向采样率加权,以提供对总体的估计。例如,如果您的头部采样率为 5%,则每个采样跟踪都计为 20。随着延迟方差的增加或头部采样率的降低,这些计算中的误差水平可能会增加。
这些计算方法确保 APM 应用程序根据使用的采样策略提供尽可能准确的指标,同时还考虑头部采样率以估计跟踪的总体数量。
1 真实用户监控 (RUM) 跟踪是此规则的例外。利用 RUM 数据的 Kibana 应用程序依赖于事务事件,因此未采样的 RUM 跟踪保留事务数据——仅丢弃跨度数据。
最佳采样率是多少?不幸的是,没有一个最佳值。采样取决于您的数据、应用程序的吞吐量、数据保留策略和其他因素。.1% 到 100% 的采样率都属于正常范围。您可能会为不同的场景决定一个独特的采样率。以下是一些示例
- 流量明显高于其他服务的服务可以安全地以较低的比率进行采样
- 重要程度不同的路由可能会以不同的采样率进行采样。
- 生产服务环境可能需要比开发环境更高的采样率。
- 失败的追踪结果可能比成功的追踪更有趣——因此需要更高的采样率。
无论上述情况如何,注重成本的客户可能只需要较低的采样率。
有三种方法可以调整APM代理的基于头部采样率
事务采样率可以在每个服务和每个环境的基础上动态更改(无需重新部署),方法是使用Kibana中的APM代理配置。
APM代理配置公开了一个API,可用于以编程方式更改代理的采样率。示例可在代理配置API参考中找到。
每个代理都提供一个配置值,用于设置事务采样率。有关更多详细信息,请参阅相关代理的文档。
- Go:
ELASTIC_APM_TRANSACTION_SAMPLE_RATE - Java:
transaction_sample_rate - .NET:
TransactionSampleRate - Node.js:
transactionSampleRate - PHP:
transaction_sample_rate - Python:
transaction_sample_rate - Ruby:
transaction_sample_rate
使用启用基于尾部采样。启用后,追踪事件将映射到采样策略。每个采样策略必须指定一个采样率,并且可以选择指定其他条件。所有策略条件都必须为真,追踪事件才能与之匹配。
追踪事件将按指定的顺序与策略匹配。每个策略列表必须以默认策略结束——一个只指定采样率的策略。此默认策略用于捕获与更严格策略不匹配的其余追踪事件。此默认策略可确保仅在有意的情况下才会丢弃追踪。如果启用基于尾部采样并发送与任何策略都不匹配的事务,APM服务器将使用错误no matching policy拒绝事务。
请注意,从8.3.1版本开始,APM服务器实现了3GB的默认存储限制,但是,由于限制的计算和执行方式,实际磁盘空间仍然可能会略微超过限制。
此示例定义了三个基于尾部采样的策略。
- sample_rate: 1 service.environment: production trace.name: "GET /very_important_route" - sample_rate: .01 service.environment: production trace.name: "GET /not_important_route" - sample_rate: .1
|
在 |
|
|
在 |
|
|
默认策略,对其余追踪进行10%采样,例如不同环境(如 |
设置为true以启用基于尾部采样。默认情况下禁用。(布尔值)
APM服务器二进制文件 |
|
集群管理 |
|
多个APM服务器的同步间隔。应为数十秒或几分钟的量级。默认值:1m(1分钟)。(持续时间)
APM服务器二进制文件 |
|
集群管理 |
|
用于将根事务匹配到采样率的标准。
策略将追踪事件映射到采样率。每个策略必须指定一个采样率。追踪事件将按指定的顺序与策略匹配。所有策略条件都必须为真,追踪事件才能与之匹配。每个策略列表都应以仅指定采样率的策略结束。此最终策略用于捕获与更严格策略不匹配的其余追踪事件。([]policy)
APM服务器二进制文件 |
|
集群管理 |
|
为匹配尾部采样策略的追踪事件分配的存储空间量。警告:将此限制设置为高于允许空间可能会导致APM服务器运行不健康。
如果配置的存储限制不足,它将记录“已达到配置的存储限制”。当达到存储限制时,事件将绕过采样并始终被索引。
默认值:3GB。(文本)
APM服务器二进制文件 |
|
集群管理 |
|
sample_rate应用于与该策略匹配的追踪事件的采样率。每个策略中都必需。
采样率必须大于或等于0且小于或等于1。例如,sample_rate为0.01表示将采样与策略匹配的1%的追踪事件。 sample_rate为1表示将采样与策略匹配的100%的追踪事件。(整数)
trace.name要匹配策略的事件的追踪名称。当配置的trace.name与追踪根事务的transaction.name匹配时,就会发生匹配。根事务是没有parent.id的任何事务。(字符串)
trace.outcome要匹配策略的事件的追踪结果。当配置的trace.outcome与追踪的event.outcome字段匹配时,就会发生匹配。追踪结果可以是success、failure或unknown。(字符串)
service.name要匹配策略的服务名称。(字符串)
service.environment要匹配策略的服务环境。(字符串)