创建监控状态规则
编辑创建监控状态规则
编辑监控状态规则有两种类型
- 合成监控状态 用于 Elastic Synthetics。
-
[8.15.0] 已在 8.15.0 版本中弃用。 正常运行时间监控状态 用于正常运行时间应用程序。
从 8.15.0 版本开始,正常运行时间应用程序和正常运行时间监控状态规则已弃用。
如果您正在将正常运行时间监控状态规则与正常运行时间应用程序一起使用,则应将正常运行时间监控和正常运行时间监控状态规则迁移到 Elastic Synthetics 和 Synthetics 监控规则。
如果您正在将正常运行时间监控状态规则与使用 Elastic Synthetics 创建的监控一起使用,则应将正常运行时间监控状态规则迁移到 Synthetics 监控规则。 请在 从正常运行时间规则迁移到 Synthetics 规则 中了解如何操作。
合成监控状态
编辑在 Synthetics UI 中,创建一个 监控状态 规则,以根据错误和中断接收通知。
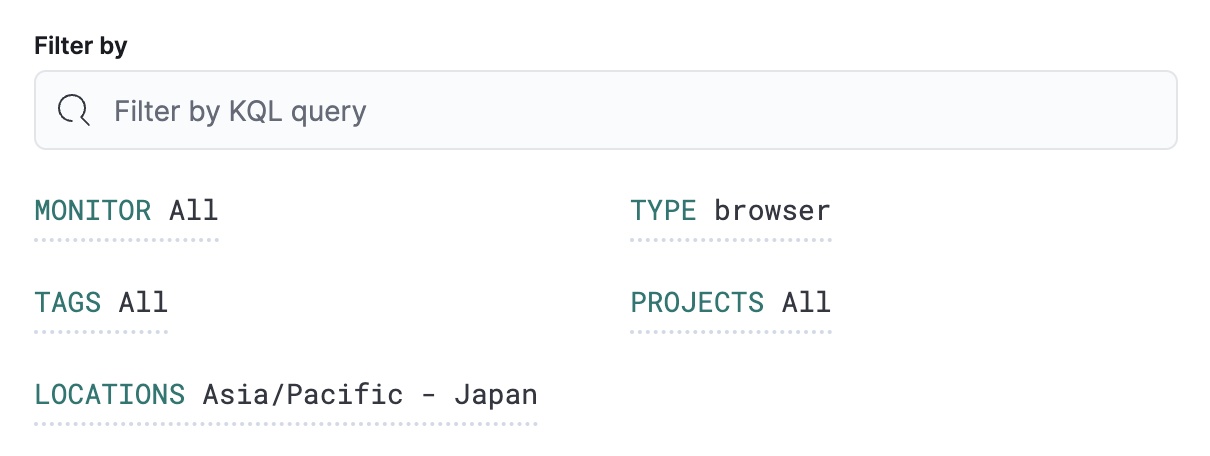
按以下条件筛选 部分控制规则的范围。该规则只会检查与本部分中定义的过滤器匹配的监控。在此示例中,该规则只会针对位于 Asia/Pacific - Japan 的 browser 监控发出告警。
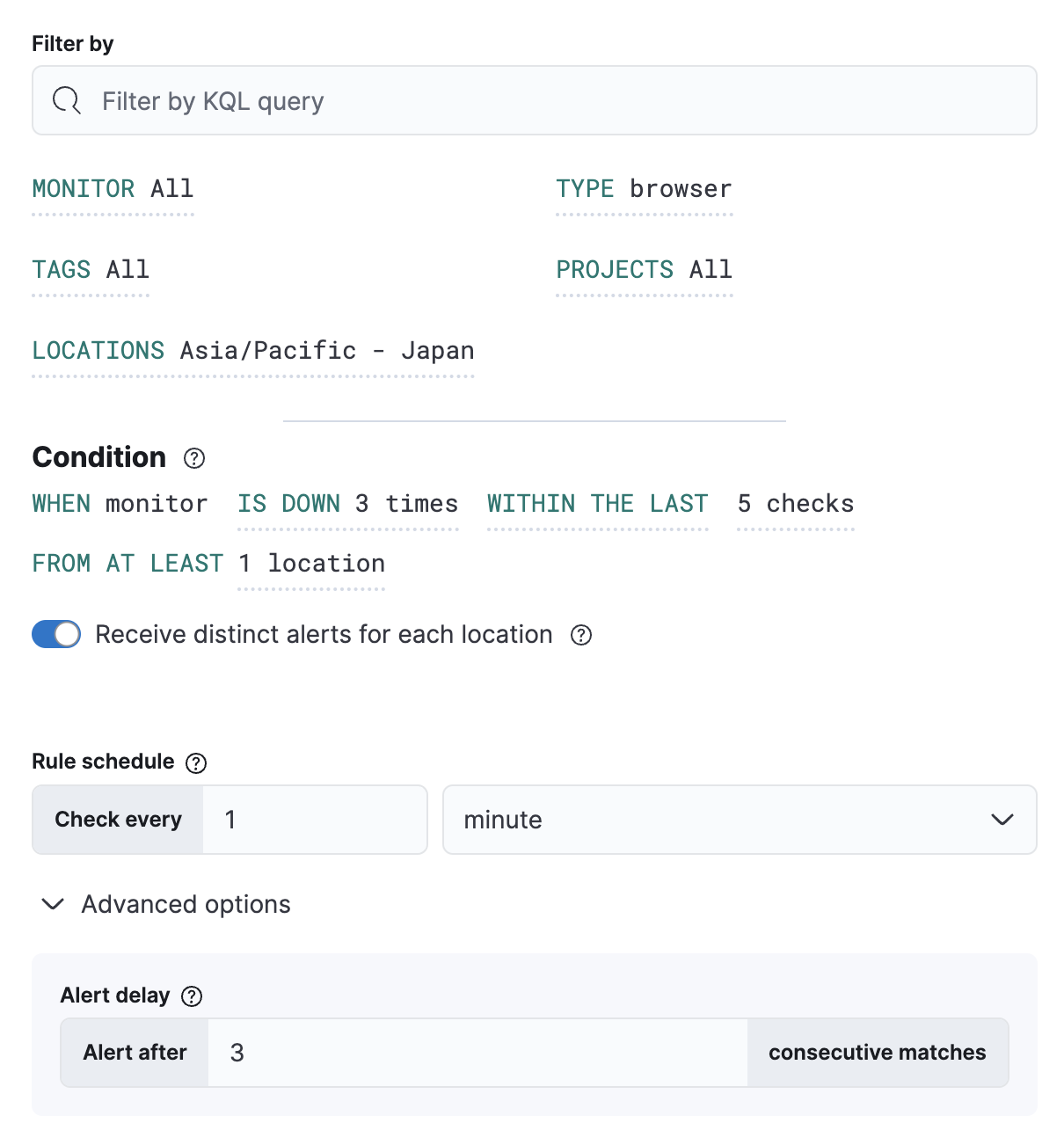
每个规则的条件将应用于与按以下条件筛选 部分中的过滤器匹配的所有监控。您可以选择监控必须宕机的次数(相对于运行的检查次数或运行检查的时间范围),以及监控必须宕机的最少位置数。
重新测试包含在检查次数中。
规则计划 定义评估条件的频率。请注意,检查是排队的,它们在尽可能接近定义值的情况下运行。例如,如果计划每 2 分钟运行一次检查,但检查运行时间超过 2 分钟,则在之前的检查完成之前不会运行检查。
您还可以设置高级选项,例如必须满足规则条件的连续运行次数,才能发出告警。
在此示例中,只要 browser 监控在监控运行的最后 5 次中宕机了 3 次(跨任何与过滤器匹配的位置),条件就会满足。这些条件将每分钟评估一次,只有在连续三次满足条件时,您才会收到告警。
通过将规则连接到使用以下支持的内置集成的操作来扩展您的规则。
某些连接器类型是付费商业功能,而其他连接器类型是免费的。要比较 Elastic 订阅级别,请访问 订阅页面。
选择连接器后,必须设置操作频率。您可以选择在每个检查间隔或自定义间隔创建告警摘要。例如,每小时发送一次电子邮件通知,总结新的、正在进行的和已恢复的告警。
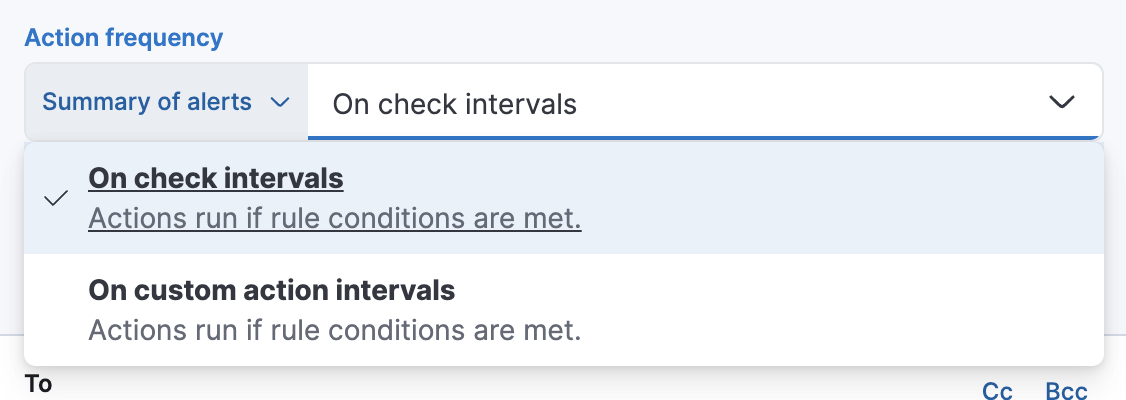
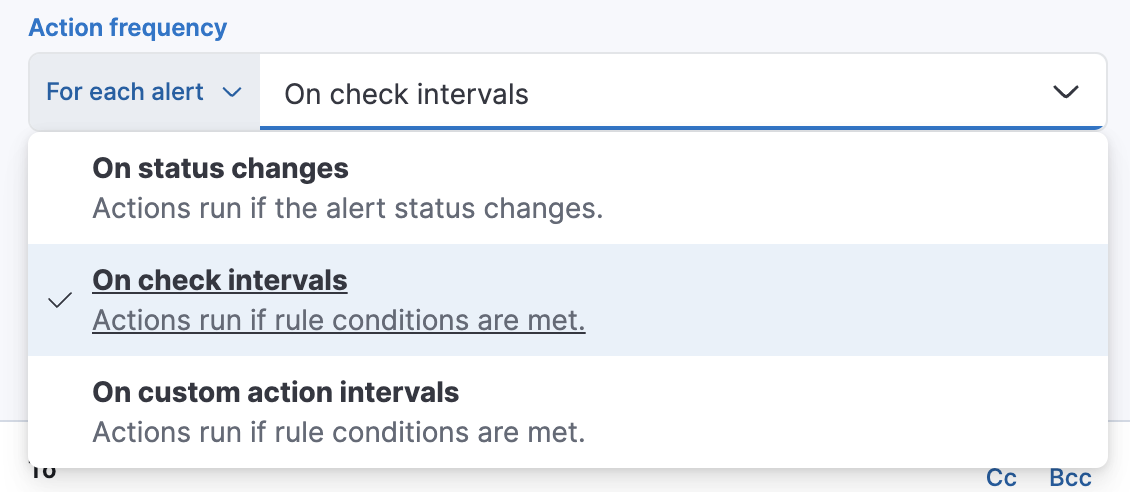
或者,您可以设置操作频率,以便选择操作运行的频率(例如,在每个检查间隔、只有在告警状态更改时,或在自定义操作间隔)。在这种情况下,还必须选择影响操作运行时间的特定阈值条件:“合成监控状态”更改或“已恢复”(从宕机变为正常)。
您还可以通过指定操作仅在与 KQL 查询匹配或告警在特定时间范围内发生时运行来进一步优化操作运行的条件。
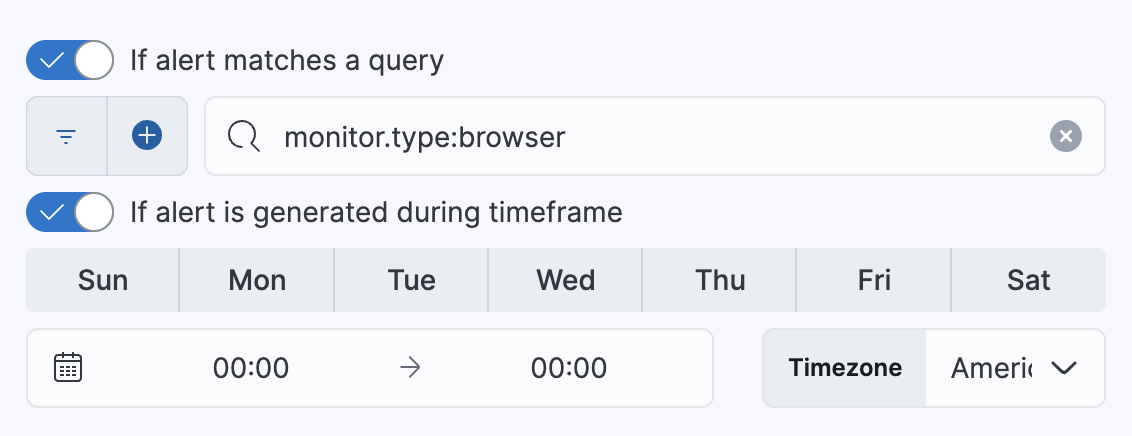
- 如果告警与查询匹配:输入一个 KQL 查询,该查询定义必须满足的字段值对或查询条件才能发送通知。该查询仅搜索为规则指定的索引中的告警文档。
- 如果在时间范围内生成告警:设置时间范围详细信息。只有在您定义的时间范围内生成告警时,才会发送通知。
使用默认通知消息或自定义它。您可以通过单击消息文本框上方的图标并从可用变量列表中选择来向消息添加更多上下文。

以下变量特定于此规则类型。您还可以指定所有规则通用的变量。
-
context.checkedAt - 监控运行的时间戳。
-
context.hostName - 执行检查的位置的主机名。
-
context.lastErrorMessage - 监控的最后一条错误消息。
-
context.locationId - 执行检查的位置 ID。
-
context.locationName - 执行检查的位置名称。
-
context.locationNames - 执行检查的位置名称。
-
context.message - 总结当前宕机监控状态的生成消息。
-
context.monitorId - 监控的 ID。
-
context.monitorName - 监控的名称。
-
context.monitorTags - 与监控关联的标签。
-
context.monitorType - 监控的类型(例如,HTTP/TCP)。
-
context.monitorUrl - 监控的 URL。
-
context.reason - 告警原因的简要说明。
-
context.recoveryReason - 恢复原因的简要说明。
-
context.status - 监控状态(例如,“宕机”)。
-
context.viewInAppUrl - 在 Synthetics 应用程序中打开告警详细信息和上下文。
正常运行时间监控状态
编辑从 8.15.0 版本开始,正常运行时间应用程序和正常运行时间监控状态规则已弃用。
如果您正在将正常运行时间监控状态规则与正常运行时间应用程序一起使用,则应将正常运行时间监控和正常运行时间监控状态规则迁移到 Elastic Synthetics 和 Synthetics 监控规则。
如果您正在将正常运行时间监控状态规则与使用 Elastic Synthetics 创建的监控一起使用,则应将正常运行时间监控状态规则迁移到 Synthetics 监控规则。 请在 从正常运行时间规则迁移到 Synthetics 规则 中了解如何操作。
在正常运行时间应用程序中,创建一个 监控状态 规则,以根据错误和中断接收通知。
- 要访问此页面,请转到 可观测性 → 正常运行时间。
- 在页面顶部,单击 告警和规则 → 创建规则。
- 选择 监控状态规则。
如果您在概述页面搜索栏中已经有查询,则会在此处填充。
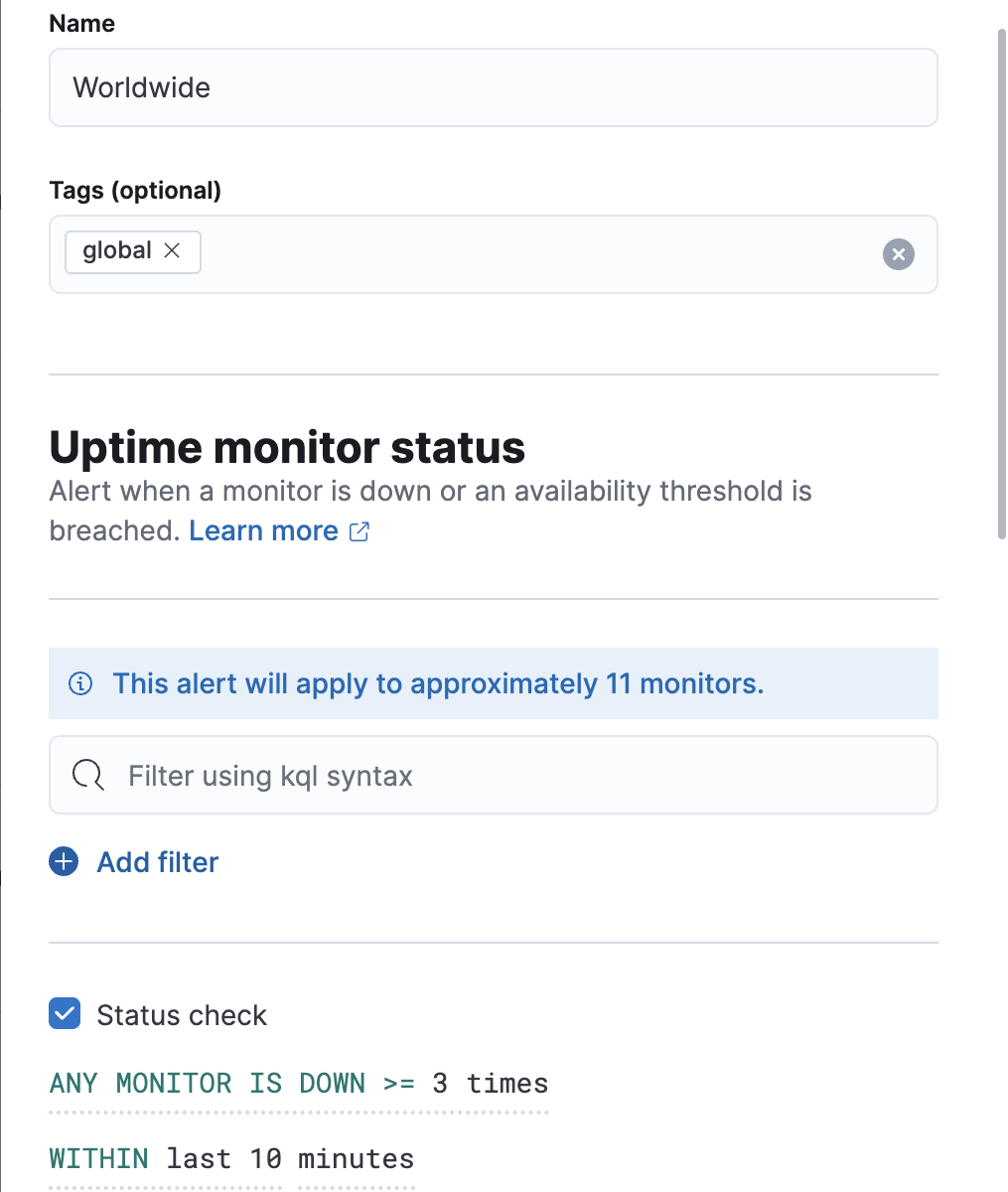
您可以为规则指定以下阈值。
状态检查 |
当监控在指定时间范围(秒、分钟、小时或天)内宕机指定次数时接收告警。 |
可用性 |
当监控在指定时间范围(天、周、月或年)内低于指定的可用性阈值时接收告警。 |
让我们创建一个规则,用于在 10 分钟内显示 Down 超过三次的任何监控。
此规则涵盖您正在运行的所有监控。您可以使用查询指定特定监控,并且每个监控也可以有不同的条件。
创建规则的最后一步是选择一个或多个在触发告警时要执行的操作。
您可以通过将规则连接到使用以下支持的内置集成的操作来扩展您的规则。操作是 Kibana 服务或与第三方系统的集成,当满足规则条件时,它们作为 Kibana 服务器上的后台任务运行。
您可以在 设置 页面上配置操作类型。

选择连接器后,必须设置操作频率。您可以选择在每个检查间隔或自定义间隔创建告警摘要。例如,每小时发送一次电子邮件通知,总结新的、正在进行的和已恢复的告警。
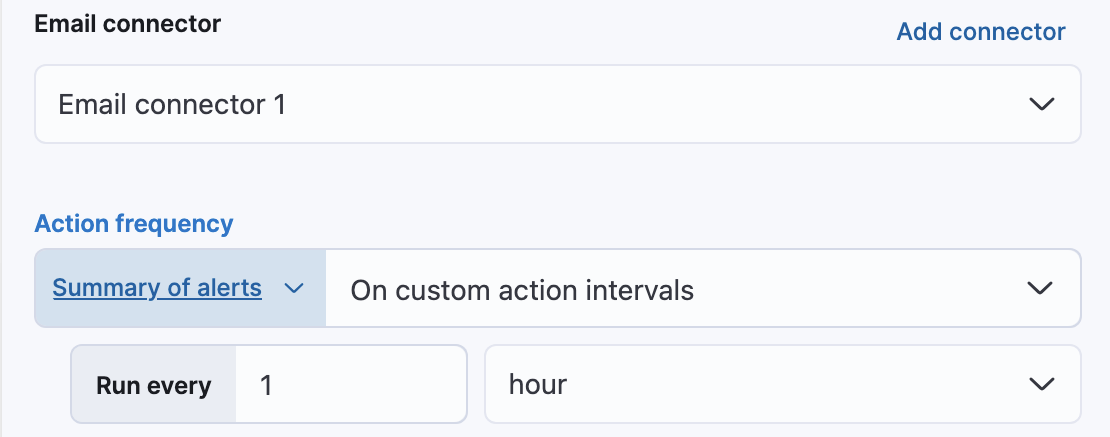
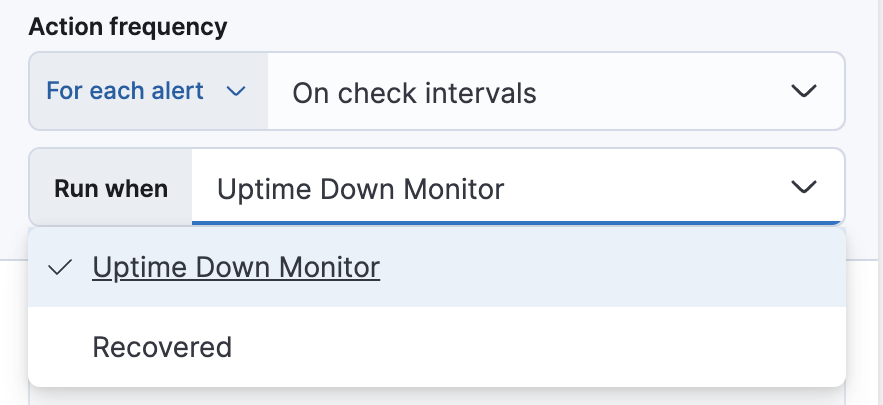
或者,您可以设置操作频率,以便选择操作运行的频率(例如,在每个检查间隔、只有在告警状态更改时,或在自定义操作间隔)。在这种情况下,还必须选择影响操作运行时间的特定阈值条件:Uptime Down Monitor 或 Recovered。
使用默认通知消息或自定义它。您可以通过单击消息文本框上方的图标并从可用变量列表中选择来向消息添加更多上下文。
要接收告警恢复时的通知,请选择 恢复时运行。使用默认通知消息或自定义它。您可以通过单击消息文本框上方的图标并从可用变量列表中选择来向消息添加更多上下文。
从正常运行时间规则迁移到 Synthetics 规则
编辑如果您目前正在将正常运行时间监控状态与使用 Elastic Synthetics 创建的监控一起使用,则应将正常运行时间监控状态规则迁移到
您在正常运行时间监控状态规则中使用的 KQL 语法在 Synthetics 监控状态规则的 按以下条件筛选 部分中也有效。Synthetics 监控状态规则还为几个类别提供了下拉菜单,方便过滤。但是,如果您愿意,仍然可以使用这些类别的 KQL 语法。
如果您使用的是正常运行时间可用性条件,请参考 正常运行时间可用性检查到 Synthetics 可用性 SLI。
如果您使用的是正常运行时间状态检查条件,您可以使用以下 Synthetics 监控状态规则条件等效项来重新创建类似的效果
| 正常运行时间 | Synthetics 等效项 | |
|---|---|---|
监控宕机的次数 |
示例: |
示例: |
时间范围 |
示例: |
示例: |
正常运行时间监控状态规则和合成监控状态规则的默认消息不同,但是您可以使用合成监控状态规则操作变量来创建类似的消息。
SLO 允许您根据可用性等因素为您的服务性能设置清晰、可衡量的目标。 合成可用性 SLI 是基于合成监控的可用性的服务级别指标 (SLI)。
您在正常运行时间监控状态规则中使用的 KQL 语法在合成可用性 SLI 的查询过滤器字段中也同样有效。
使用以下合成可用性 SLI 字段替换正常运行时间监控状态规则的可用性条件
| 正常运行时间 | Synthetics 等效项 | |
|---|---|---|
相对于所有运行的检查,已关闭的检查数量 |
示例: |
目标/SLO (%) 字段 示例: |
时间范围 |
示例: |
时间窗口 和 持续时间 字段 示例:时间窗口: |
使用合成可用性 SLI 创建新的 SLO 后,您可以使用 SLO 消耗率规则。有关配置规则的更多信息,请参阅创建 SLO 消耗率规则。