攻击发现
编辑攻击发现
编辑此功能处于技术预览阶段。它将来可能会发生变化,在生产环境中使用时应谨慎。Elastic 将努力解决任何问题,但技术预览中的功能不受 GA 功能的支持 SLA 约束。
攻击发现利用大型语言模型 (LLM) 分析您环境中的警报并识别威胁。每个“发现”都代表一次潜在攻击,并描述多个警报之间的关系,告诉您涉及哪些用户和主机、警报如何与 MITRE ATT&CK 矩阵对应以及哪些威胁参与者可能负责。这有助于充分利用每个安全分析师的时间,缓解警报疲劳并缩短平均响应时间。
有关演示,请参阅以下视频。

此页面描述
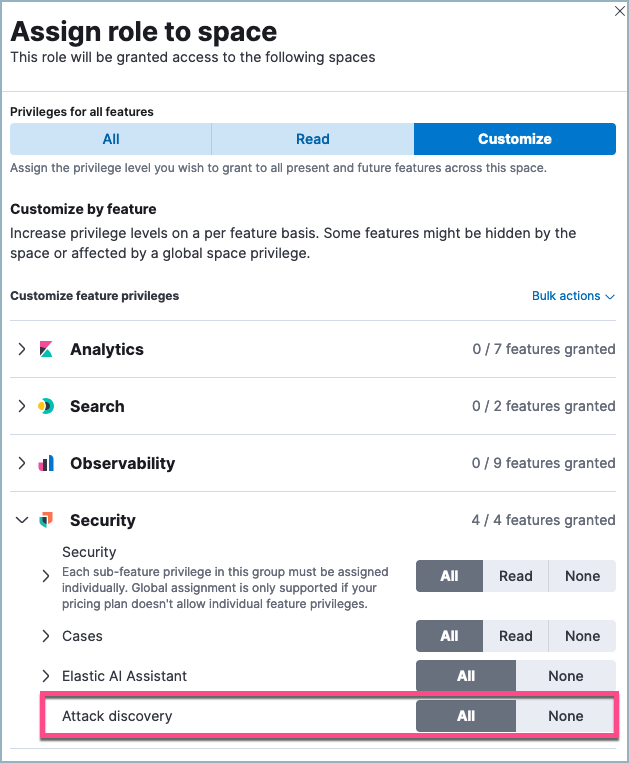
攻击发现的基于角色的访问控制 (RBAC)
编辑Attack Discovery: All 权限允许您使用攻击发现。
生成发现
编辑首次访问攻击发现时,您需要选择一个 LLM 连接器才能分析警报。攻击发现使用与AI 助手相同的 LLM 连接器。要开始,请
- 单击 Elastic Security 导航菜单中的攻击发现页面。
-
从下拉菜单中选择现有连接器,或添加新的连接器。
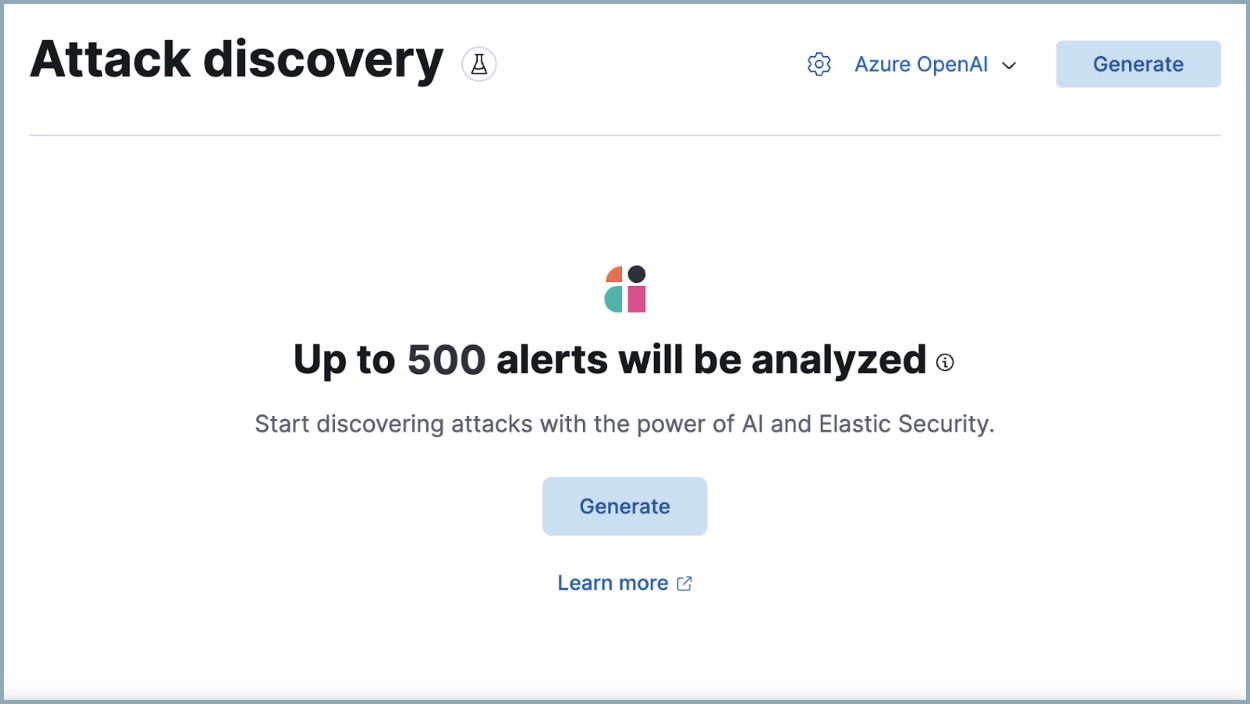
- 选择连接器后,单击生成以启动分析。
根据警报数量和您选择的模型,生成发现可能需要几秒钟到几分钟的时间。
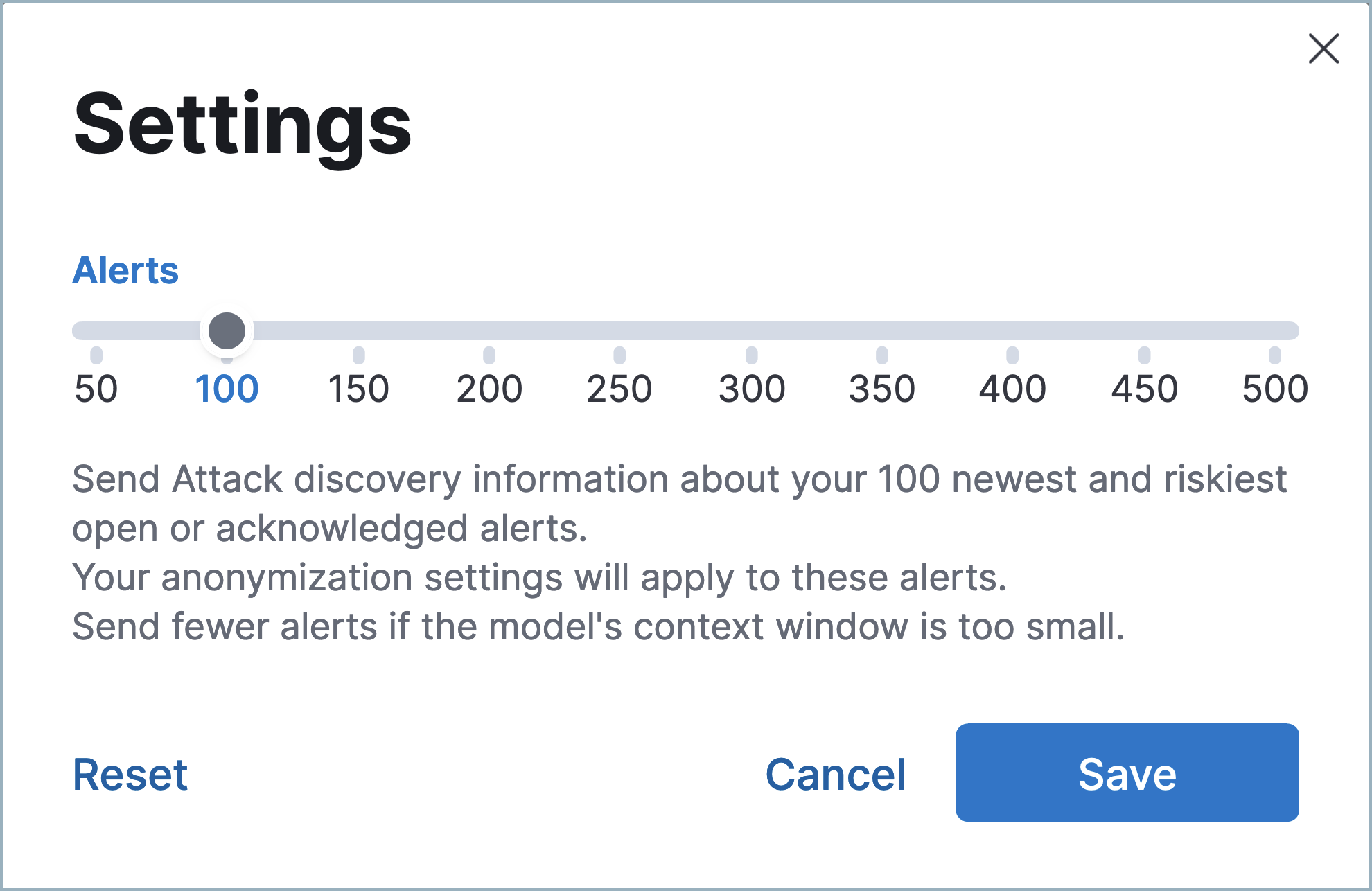
默认情况下,攻击发现在此时间范围内最多分析 100 个警报,但您可以通过单击模型选择菜单旁边的设置图标(![]() ) 并调整警报滑块将其扩展到 500 个。请注意,发送超过所选 LLM 可处理数量的警报可能会导致错误。
) 并调整警报滑块将其扩展到 500 个。请注意,发送超过所选 LLM 可处理数量的警报可能会导致错误。
攻击发现使用与Elastic AI 助手相同的数据匿名化设置。要配置发送到 LLM 的警报字段以及哪些字段被模糊处理,请使用 Elastic AI 助手设置。在向第三方 LLM 发送敏感数据之前,请考虑其隐私策略。
分析完成后,它识别的任何威胁都将显示为发现。单击每个威胁的标题以展开或折叠它。随时单击生成以使用最新的警报再次启动攻击发现过程。
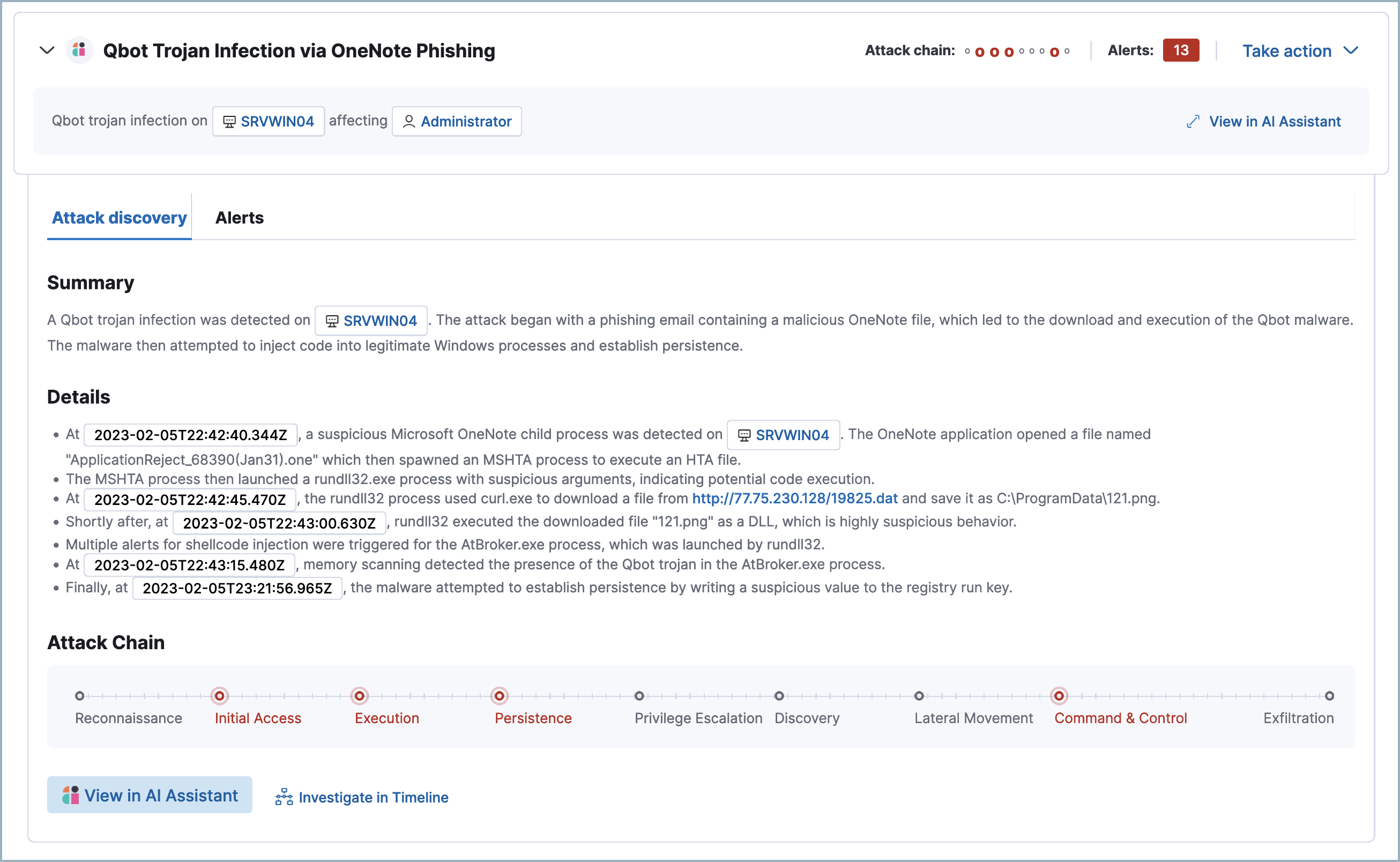
每个发现包含哪些信息?
编辑每个发现都包含以下信息,这些信息描述了由连接的 LLM 生成的潜在威胁
- 对潜在威胁的描述性标题和摘要。
- 关联警报的数量以及它们与MITRE ATT&CK 矩阵的哪些部分相对应。
- 涉嫌的实体(用户和主机)以及为每个实体观察到的可疑活动。
将发现与其他工作流程结合使用
编辑您可以通过多种方式将发现整合到您的 Elastic Security 工作流程中
