
作为运营工程师(SRE、IT 运营、DevOps),管理技术和数据蔓延是一项持续的挑战。仅仅管理大量的高维度和高基数数据就让人不堪重负。
作为一个单一平台,Elastic® 帮助 SRE 将无限的遥测数据(包括指标、日志、跟踪和性能分析)统一并关联到一个单一的数据存储中 — Elasticsearch®。然后,通过应用 Elastic 的高级机器学习 (ML)、AIOps、AI 助手和分析功能,您可以打破数据孤岛,将数据转化为见解。作为一个全栈可观测性解决方案,从基础设施监控到日志监控和应用程序性能监控 (APM),一切都可以在单一、统一的体验中找到。
在 Elastic 8.11 中,现在提供了一个技术预览版 Elastic 的新管道查询语言 ES|QL(Elasticsearch 查询语言),该语言可以转换、丰富和简化数据调查。ES|QL 由新的查询引擎提供支持,可提供具有并发处理的高级搜索功能,从而提高速度和效率,而与数据源和结构无关。通过在一个屏幕上创建聚合和可视化,加速问题解决,从而提供迭代的、不间断的工作流程。
ES|QL 对 SRE 的优势
使用 Elastic 可观测性的 SRE 可以利用 ES|QL 来分析日志、指标、跟踪和性能分析数据,从而使他们能够通过单个查询来查明性能瓶颈和系统问题。在使用 Elastic 可观测性中的 ES|QL 管理高维度和高基数数据时,SRE 可以获得以下优势
- 提高运营效率: 通过使用 ES|QL,SRE 可以从单个查询中创建具有聚合值作为阈值的更具可操作性的通知,这些通知也可以通过 Elastic API 进行管理并集成到 DevOps 流程中。
- 通过见解增强分析: ES|QL 可以处理各种可观测性数据,包括应用程序、基础设施、业务数据等,而与来源和结构无关。ES|QL 可以轻松地使用附加字段和上下文丰富数据,从而可以通过单个查询创建用于仪表板或问题分析的可视化。
- 缩短平均解决时间: ES|QL 与 Elastic 可观测性的 AIOps 和 AI 助手结合使用时,可以通过识别趋势、隔离事件和减少误报来提高检测准确性。上下文的这种改进有助于故障排除以及快速查明和解决问题。
Elastic 可观测性中的 ES|QL 不仅可以增强 SRE 更有效地管理客户体验、组织收入和 SLO 的能力,还可以通过提供上下文相关的聚合数据来促进与开发人员和 DevOps 的协作。
在本博客中,我们将介绍 SRE 可以利用 ES|QL 的一些关键用例
- ES|QL 与 Elastic AI 助手集成,后者使用公共 LLM 和私有数据,增强了 Elastic 可观测性中任何位置的分析体验。
- SRE 可以在单个 ES|QL 查询中分解、分析和可视化来自多个来源且跨任何时间范围的可观测性数据。
- 可以轻松地从单个 ES|QL 查询创建可操作的警报,从而增强运营。
我将通过展示 SRE 如何解决使用 OpenTelemetry 检测并在 Kubernetes 上运行的应用程序中的问题来演示这些用例。OpenTelemetry (OTel) 演示是在 Amazon EKS 集群上进行的,并配置了 Elastic Cloud 8.11。
您还可以查看我们的 Elastic 可观测性 ES|QL 演示,其中介绍了可观测性的 ES|QL 功能。
带有 AI 助手的 ES|QL
作为 SRE,您正在使用 Elastic 可观测性监控您的 OTel 检测的应用程序,并且在 Elastic APM 中,您注意到服务地图中突出显示了一些问题。
使用 Elastic AI 助手,您可以轻松地要求进行分析,特别是,我们检查应用程序服务之间的整体延迟是多少。
My APM data is in traces-apm*. What's the average latency per service over the last hour? Use ESQL, the data is mapped to ECS
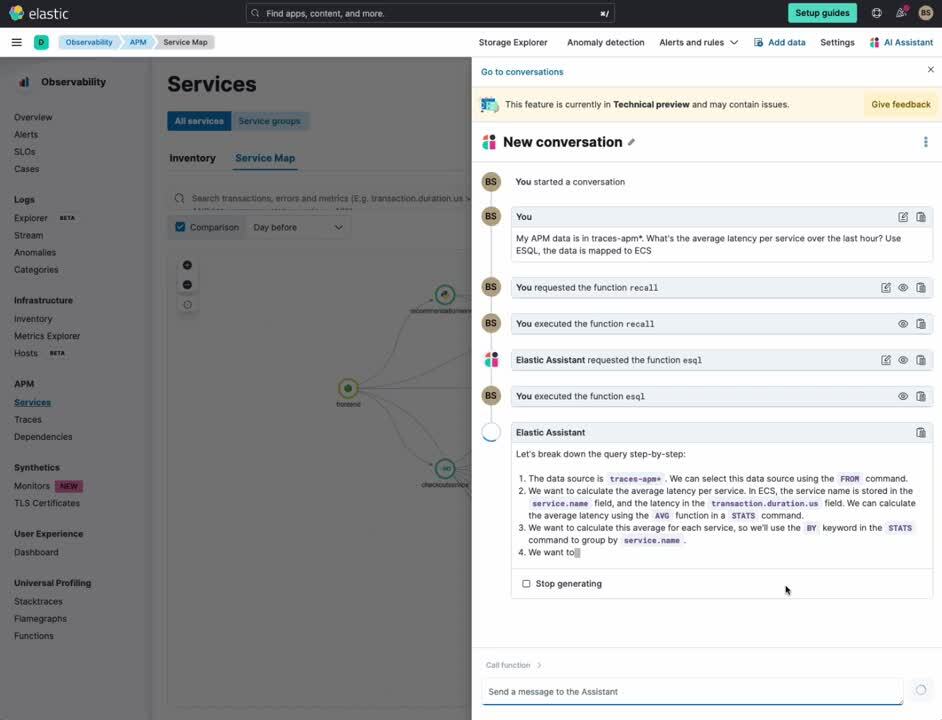
Elastic AI 助手生成一个 ES|QL 查询,我们在 AI 助手中运行该查询,以获取所有应用程序服务的平均延迟列表。我们可以轻松地看到前四个是
- 负载生成器
- 前端代理
- 前端服务
- 结账服务
通过 AI 助手中的简单自然语言查询,它生成了一个 ES|QL 查询,该查询帮助列出了各个服务的延迟。
注意到多个服务存在问题,我们决定从前端代理开始。当我们查看详细信息时,我们看到明显的故障,并且通过 Elastic APM 故障关联,很明显前端代理未正确完成其对下游服务的调用。
ES|QL 在发现中的深入分析和上下文分析
知道应用程序在 Kubernetes 上运行,我们调查 Kubernetes 中是否存在问题。特别是,我们想看看是否有任何服务出现问题。
我们在 Elastic 发现中的 ES|QL 中使用以下查询
from metrics-* | where kubernetes.container.status.last_terminated_reason != "" and kubernetes.namespace == "default" | stats reason_count=count(kubernetes.container.status.last_terminated_reason) by kubernetes.container.name, kubernetes.container.status.last_terminated_reason | where reason_count > 0
ES|QL 帮助分析来自 Kubernetes 的数千/数万个指标事件,并突出显示两个由于 OOMKilled 而重新启动的服务。
当被问及 OOMKilled 时,Elastic AI 助手指出,由于内存不足,Pod 中的容器被杀死。
我们运行另一个 ES|QL 查询来了解电子邮件服务和产品目录服务的内存使用情况。
ES|QL 轻松地发现平均内存使用量相当高。
我们现在可以进一步调查这两个服务的日志、指标和 Kubernetes 相关数据。但是,在我们继续之前,我们创建一个警报来跟踪大量内存使用情况。
使用 ES|QL 的可操作警报
怀疑存在可能重复出现的特定问题,我们只需创建一个警报,引入刚刚运行的 ES|QL 查询,该查询将跟踪任何内存利用率超过 50% 的服务。
我们修改最后一个查询,以查找任何内存使用率高的服务。
FROM metrics*
| WHERE @timestamp >= NOW() - 1 hours
| STATS avg_memory_usage = AVG(kubernetes.pod.memory.usage.limit.pct) BY kubernetes.deployment.name | where avg_memory_usage > .5
使用该查询,我们创建一个简单的警报。请注意 ES|QL 查询是如何被引入到警报中的。我们只需将其连接到 PagerDuty。但我们可以从多个连接器中选择,例如 ServiceNow、Opsgenie、电子邮件等。
有了这个警报,我们现在可以轻松监控任何 pod 中内存利用率超过 50% 的服务。
通过 ES|QL 最大化利用您的数据
在这篇文章中,我们展示了 ES|QL 为分析、运营和减少平均修复时间 (MTTR) 带来的强大功能。总而言之,Elastic Observability 中 ES|QL 的三个用例如下:
- ES|QL 与 Elastic AI 助手集成,后者使用公共 LLM 和私有数据,增强了 Elastic 可观测性中任何位置的分析体验。
- SRE 可以在单个 ES|QL 查询中分解、分析和可视化来自多个来源且跨任何时间范围的可观测性数据。
- 可以轻松地从单个 ES|QL 查询创建可操作的警报,从而增强运营。
Elastic 邀请 SRE 和开发人员亲身体验这种变革性的语言,并在他们的数据任务中解锁新的视野。立即在技术预览版中通过 https://ela.st/free-trial 试用。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。任何当前不可用的特性或功能可能不会按时交付或根本不交付。