使用 DISSECT 和 GROK 处理数据
编辑使用 DISSECT 和 GROK 处理数据
编辑你的数据可能包含你想要结构化的非结构化字符串。 这使得分析数据更容易。 例如,日志消息可能包含你想要提取的 IP 地址,以便你可以找到最活跃的 IP 地址。
Elasticsearch 可以在索引时或查询时结构化你的数据。 在索引时,你可以使用 Dissect 和 Grok 摄取处理器,或 Logstash Dissect 和 Grok 过滤器。 在查询时,你可以使用 ES|QL DISSECT 和 GROK 命令。
DISSECT 或 GROK?还是两者都用?
编辑DISSECT 通过使用基于分隔符的模式来分解字符串。 GROK 的工作方式类似,但使用正则表达式。 这使得 GROK 更强大,但通常也更慢。 当数据可靠地重复时,DISSECT 效果很好。 当你确实需要正则表达式的强大功能时,例如当文本的结构因行而异时,GROK 是更好的选择。
你可以将 DISSECT 和 GROK 都用于混合用例。 例如,当行的某个部分可靠地重复时,但整行不重复。 DISSECT 可以解构重复的行部分。 GROK 可以使用正则表达式处理剩余的字段值。
使用 DISSECT 处理数据
编辑DISSECT 处理命令将字符串与基于分隔符的模式进行匹配,并将指定的键提取为列。
例如,以下模式
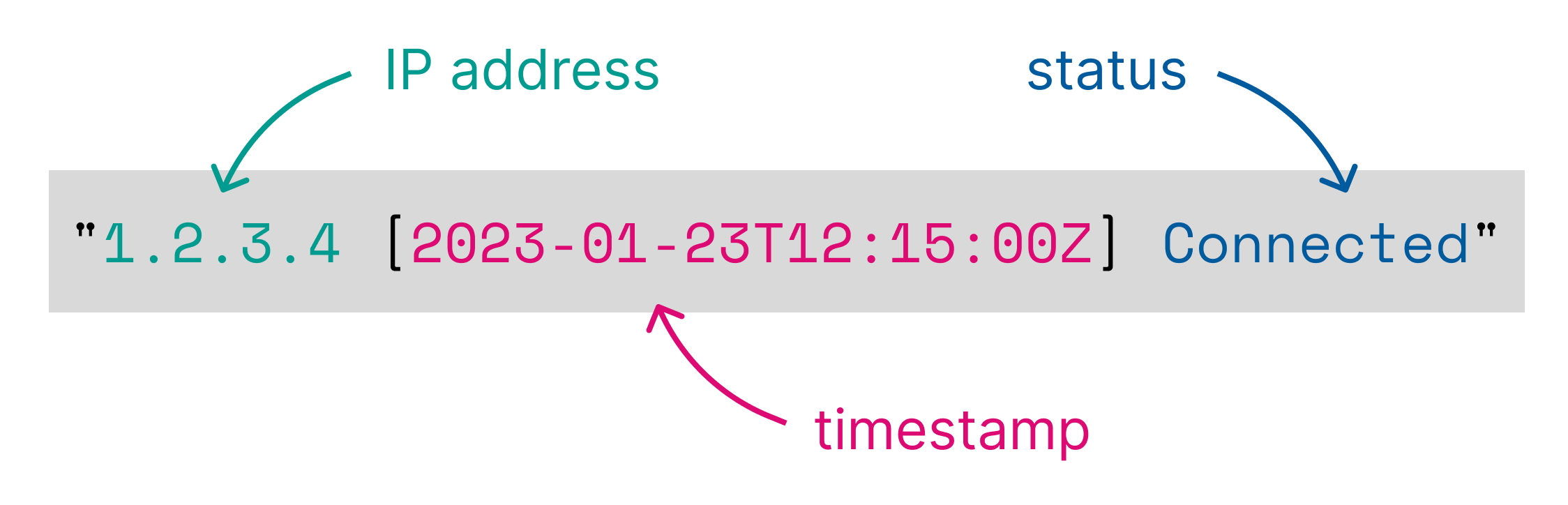
%{clientip} [%{@timestamp}] %{status}
匹配此格式的日志行
1.2.3.4 [2023-01-23T12:15:00.000Z] Connected
并导致向输入表添加以下列
| clientip:keyword | @timestamp:keyword | status:keyword |
|---|---|---|
1.2.3.4 |
2023-01-23T12:15:00.000Z |
已连接 |
Dissect 模式
编辑dissect 模式由要丢弃的字符串部分定义。 在前面的示例中,要丢弃的第一个部分是单个空格。 Dissect 找到这个空格,然后将 clientip 的值分配给该空格之前的所有内容。 接下来,dissect 匹配 [,然后是 ],然后将 @timestamp 分配给 [ 和 ] 之间的所有内容。 特别注意要丢弃的字符串部分将有助于构建成功的 dissect 模式。
可以使用空键 (%{}) 或已命名的跳过键来匹配值,但将值从输出中排除。
所有匹配的值都作为 keyword 字符串数据类型输出。 使用 类型转换函数转换为其他数据类型。
Dissect 还支持可以更改 dissect 默认行为的键修饰符。 例如,你可以指示 dissect 忽略某些字段、附加字段、跳过填充等。
术语
编辑- dissect 模式
- 描述文本格式的字段和分隔符集。 也称为解剖。 解剖是使用一组
%{}部分描述的:%{a} - %{b} - %{c} - 字段
- 从
%{到}(包括)的文本。 - 分隔符
- 在
}和下一个%{字符之间的文本。 除%{、'not }'或}之外的任何字符集都是分隔符。 - 键
-
在
%{和}之间,不包括?、+、&前缀和序数后缀的文本。示例
-
%{?aaa}- 键是aaa -
%{+bbb/3}- 键是bbb -
%{&ccc}- 键是ccc
-
示例
编辑以下示例解析包含时间戳、一些文本和 IP 地址的字符串
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a """%{date} - %{msg} - %{ip}"""
| KEEP date, msg, ip
| date:keyword | msg:keyword | ip:keyword |
|---|---|---|
2023-01-23T12:15:00.000Z |
一些文本 |
127.0.0.1 |
默认情况下,DISSECT 输出 keyword 字符串列。 要转换为其他类型,请使用类型转换函数
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a """%{date} - %{msg} - %{ip}"""
| KEEP date, msg, ip
| EVAL date = TO_DATETIME(date)
| msg:keyword | ip:keyword | date:date |
|---|---|---|
一些文本 |
127.0.0.1 |
2023-01-23T12:15:00.000Z |
Dissect 键修饰符
编辑键修饰符可以更改解剖的默认行为。 键修饰符可能位于 %{keyname} 的左侧或右侧,始终位于 %{ 和 } 内。 例如,%{+keyname ->} 具有附加和右填充修饰符。
右填充修饰符 (->)
编辑执行解剖的算法非常严格,因为它要求模式中的所有字符都与源字符串匹配。 例如,模式 %{fookey} %{barkey}(1 个空格)将匹配字符串 "foo bar"(1 个空格),但不会匹配字符串 "foo bar"(2 个空格),因为模式只有 1 个空格,而源字符串有 2 个空格。
右填充修饰符有助于解决这种情况。 将右填充修饰符添加到模式 %{fookey->} %{barkey},它现在将匹配 "foo bar"(1 个空格)、"foo bar"(2 个空格)甚至是 "foo bar"(10 个空格)。
使用右填充修饰符允许在 %{keyname->} 之后重复字符。
右填充修饰符可以放置在具有任何其他修饰符的任何键上。 它始终应该是最右侧的修饰符。 例如:%{+keyname/1->} 和 %{->}
例如
ROW message="1998-08-10T17:15:42 WARN"
| DISSECT message """%{ts->} %{level}"""
| message:keyword | ts:keyword | level:keyword |
|---|---|---|
1998-08-10T17:15:42 WARN |
1998-08-10T17:15:42 |
WARN |
右填充修饰符可以与空键一起使用,以帮助跳过不需要的数据。 例如,相同的输入字符串,但用括号括起来,需要使用空的右填充键才能实现相同的结果。
例如
ROW message="[1998-08-10T17:15:42] [WARN]"
| DISSECT message """[%{ts}]%{->}[%{level}]"""
| message:keyword | ts:keyword | level:keyword |
|---|---|---|
["[1998-08-10T17:15:42] [WARN]"] |
1998-08-10T17:15:42 |
WARN |
附加修饰符 (+)
编辑Dissect 支持将两个或多个结果附加在一起进行输出。 值从左到右附加。 可以指定附加分隔符。 在此示例中,append_separator 定义为空格。
ROW message="john jacob jingleheimer schmidt"
| DISSECT message """%{+name} %{+name} %{+name} %{+name}""" APPEND_SEPARATOR=" "
| message:keyword | name:keyword |
|---|---|
john jacob jingleheimer schmidt |
john jacob jingleheimer schmidt |
按顺序附加修饰符 (+ 和 /n)
编辑Dissect 支持将两个或多个结果附加在一起进行输出。 值根据定义的顺序 (/n) 附加。 可以指定附加分隔符。 在此示例中,append_separator 定义为逗号。
ROW message="john jacob jingleheimer schmidt"
| DISSECT message """%{+name/2} %{+name/4} %{+name/3} %{+name/1}""" APPEND_SEPARATOR=","
| message:keyword | name:keyword |
|---|---|
john jacob jingleheimer schmidt |
schmidt,john,jingleheimer,jacob |
已命名的跳过键 (?)
编辑Dissect 支持忽略最终结果中的匹配项。 这可以使用空键 %{} 完成,但为了便于阅读,可能需要为空键指定名称。
这可以使用 {?name} 语法使用已命名的跳过键完成。 在以下查询中,ident 和 auth 不会添加到输出表
ROW message="1.2.3.4 - - 30/Apr/1998:22:00:52 +0000"
| DISSECT message """%{clientip} %{?ident} %{?auth} %{@timestamp}"""
| message:keyword | clientip:keyword | @timestamp:keyword |
|---|---|---|
1.2.3.4 - - 30/Apr/1998:22:00:52 +0000 |
1.2.3.4 |
30/Apr/1998:22:00:52 +0000 |
限制
编辑DISSECT 命令不支持引用键。
使用 GROK 处理数据
编辑GROK 处理命令将字符串与基于正则表达式的模式进行匹配,并将指定的键提取为列。
例如,以下模式
%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}
匹配此格式的日志行
1.2.3.4 [2023-01-23T12:15:00.000Z] Connected
将其组合为一个 ES|QL 查询
ROW a = "1.2.3.4 [2023-01-23T12:15:00.000Z] Connected"
| GROK a """%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}"""
GROK 向输入表添加以下列
| @timestamp:keyword | ip:keyword | status:keyword |
|---|---|---|
2023-01-23T12:15:00.000Z |
1.2.3.4 |
已连接 |
grok 模式中的特殊正则表达式字符,例如 [ 和 ] 需要使用 \ 进行转义。例如,在之前的模式中
%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}
在 ES|QL 查询中,当使用单引号表示字符串时,反斜杠字符本身是一个特殊字符,需要用另一个 \ 进行转义。对于此示例,相应的 ES|QL 查询变为
ROW a = "1.2.3.4 [2023-01-23T12:15:00.000Z] Connected"
| GROK a "%{IP:ip} \\[%{TIMESTAMP_ISO8601:@timestamp}\\] %{GREEDYDATA:status}"
因此,通常来说,使用三引号 """ 表示 GROK 模式更为方便,因为它不需要转义反斜杠。
ROW a = "1.2.3.4 [2023-01-23T12:15:00.000Z] Connected"
| GROK a """%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}"""
Grok 模式
编辑grok 模式的语法是 %{SYNTAX:SEMANTIC}
SYNTAX 是匹配文本的模式名称。例如,3.44 由 NUMBER 模式匹配,而 55.3.244.1 由 IP 模式匹配。语法是您如何进行匹配的。
SEMANTIC 是您给匹配文本片段的标识符。例如,3.44 可以是一个事件的持续时间,因此您可以简单地称其为 duration。此外,字符串 55.3.244.1 可以标识发出请求的 client。
默认情况下,匹配的值将作为关键字字符串数据类型输出。要转换语义的数据类型,请在其后附加目标数据类型。例如 %{NUMBER:num:int},它将 num 语义从字符串转换为整数。目前唯一支持的转换是 int 和 float。对于其他类型,请使用类型转换函数。
正则表达式
编辑Grok 基于正则表达式。任何正则表达式在 grok 中也都是有效的。Grok 使用 Oniguruma 正则表达式库。有关完整的支持的正则表达式语法,请参阅 Oniguruma GitHub 存储库。
自定义模式
编辑如果 grok 没有您需要的模式,您可以使用 Oniguruma 语法的命名捕获,它可以让您匹配一段文本并将其保存为列
(?<field_name>the pattern here)
例如,postfix 日志有一个 queue id,它是一个 10 或 11 个字符的十六进制值。可以使用以下方式将其捕获到名为 queue_id 的列中
(?<queue_id>[0-9A-F]{10,11})
示例
编辑以下示例解析一个包含时间戳、IP 地址、电子邮件地址和数字的字符串
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num}"""
| KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:keyword |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
默认情况下,GROK 输出关键字字符串列。通过在模式中的语义后附加 :type 可以转换 int 和 float 类型。例如 {NUMBER:num:int}
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"""
| KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:integer |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
对于其他类型转换,请使用类型转换函数
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"""
| KEEP date, ip, email, num
| EVAL date = TO_DATETIME(date)
| ip:keyword | email:keyword | num:integer | date:date |
|---|---|---|---|
127.0.0.1 |
42 |
2023-01-23T12:15:00.000Z |
如果一个字段名被多次使用,GROK 会创建一个多值列
FROM addresses
| KEEP city.name, zip_code
| GROK zip_code """%{WORD:zip_parts} %{WORD:zip_parts}"""
| city.name:keyword | zip_code:keyword | zip_parts:keyword |
|---|---|---|
阿姆斯特丹 |
1016 ED |
["1016", "ED"] |
旧金山 |
CA 94108 |
["CA", "94108"] |
东京 |
100-7014 |
null |
局限性
编辑GROK 命令不支持配置自定义模式或多个模式。GROK 命令不受Grok 监视器设置的约束。