- Elasticsearch 指南其他版本
- 8.17 中的新功能
- Elasticsearch 基础
- 快速入门
- 设置 Elasticsearch
- 升级 Elasticsearch
- 索引模块
- 映射
- 文本分析
- 索引模板
- 数据流
- 摄取管道
- 别名
- 搜索您的数据
- 重新排名
- 查询 DSL
- 聚合
- 地理空间分析
- 连接器
- EQL
- ES|QL
- SQL
- 脚本
- 数据管理
- 自动缩放
- 监视集群
- 汇总或转换数据
- 设置高可用性集群
- 快照和还原
- 保护 Elastic Stack 的安全
- Watcher
- 命令行工具
- elasticsearch-certgen
- elasticsearch-certutil
- elasticsearch-create-enrollment-token
- elasticsearch-croneval
- elasticsearch-keystore
- elasticsearch-node
- elasticsearch-reconfigure-node
- elasticsearch-reset-password
- elasticsearch-saml-metadata
- elasticsearch-service-tokens
- elasticsearch-setup-passwords
- elasticsearch-shard
- elasticsearch-syskeygen
- elasticsearch-users
- 优化
- 故障排除
- 修复常见的集群问题
- 诊断未分配的分片
- 向系统中添加丢失的层
- 允许 Elasticsearch 在系统中分配数据
- 允许 Elasticsearch 分配索引
- 索引将索引分配过滤器与数据层节点角色混合,以在数据层之间移动
- 没有足够的节点来分配所有分片副本
- 单个节点上索引的分片总数已超过
- 每个节点的分片总数已达到
- 故障排除损坏
- 修复磁盘空间不足的数据节点
- 修复磁盘空间不足的主节点
- 修复磁盘空间不足的其他角色节点
- 启动索引生命周期管理
- 启动快照生命周期管理
- 从快照恢复
- 故障排除损坏的存储库
- 解决重复的快照策略失败问题
- 故障排除不稳定的集群
- 故障排除发现
- 故障排除监控
- 故障排除转换
- 故障排除 Watcher
- 故障排除搜索
- 故障排除分片容量健康问题
- 故障排除不平衡的集群
- 捕获诊断信息
- REST API
- API 约定
- 通用选项
- REST API 兼容性
- 自动缩放 API
- 行为分析 API
- 紧凑和对齐文本 (CAT) API
- 集群 API
- 跨集群复制 API
- 连接器 API
- 数据流 API
- 文档 API
- 丰富 API
- EQL API
- ES|QL API
- 功能 API
- Fleet API
- 图表探索 API
- 索引 API
- 别名是否存在
- 别名
- 分析
- 分析索引磁盘使用量
- 清除缓存
- 克隆索引
- 关闭索引
- 创建索引
- 创建或更新别名
- 创建或更新组件模板
- 创建或更新索引模板
- 创建或更新索引模板(旧版)
- 删除组件模板
- 删除悬挂索引
- 删除别名
- 删除索引
- 删除索引模板
- 删除索引模板(旧版)
- 存在
- 字段使用情况统计信息
- 刷新
- 强制合并
- 获取别名
- 获取组件模板
- 获取字段映射
- 获取索引
- 获取索引设置
- 获取索引模板
- 获取索引模板(旧版)
- 获取映射
- 导入悬挂索引
- 索引恢复
- 索引段
- 索引分片存储
- 索引统计信息
- 索引模板是否存在(旧版)
- 列出悬挂索引
- 打开索引
- 刷新
- 解析索引
- 解析集群
- 翻转
- 收缩索引
- 模拟索引
- 模拟模板
- 拆分索引
- 解冻索引
- 更新索引设置
- 更新映射
- 索引生命周期管理 API
- 推理 API
- 信息 API
- 摄取 API
- 许可 API
- Logstash API
- 机器学习 API
- 机器学习异常检测 API
- 机器学习数据帧分析 API
- 机器学习训练模型 API
- 迁移 API
- 节点生命周期 API
- 查询规则 API
- 重新加载搜索分析器 API
- 存储库计量 API
- 汇总 API
- 根 API
- 脚本 API
- 搜索 API
- 搜索应用程序 API
- 可搜索快照 API
- 安全 API
- 身份验证
- 更改密码
- 清除缓存
- 清除角色缓存
- 清除权限缓存
- 清除 API 密钥缓存
- 清除服务帐户令牌缓存
- 创建 API 密钥
- 创建或更新应用程序权限
- 创建或更新角色映射
- 创建或更新角色
- 批量创建或更新角色 API
- 批量删除角色 API
- 创建或更新用户
- 创建服务帐户令牌
- 委托 PKI 身份验证
- 删除应用程序权限
- 删除角色映射
- 删除角色
- 删除服务帐户令牌
- 删除用户
- 禁用用户
- 启用用户
- 注册 Kibana
- 注册节点
- 获取 API 密钥信息
- 获取应用程序权限
- 获取内置权限
- 获取角色映射
- 获取角色
- 查询角色
- 获取服务帐户
- 获取服务帐户凭据
- 获取安全设置
- 获取令牌
- 获取用户权限
- 获取用户
- 授予 API 密钥
- 具有权限
- 使 API 密钥失效
- 使令牌失效
- OpenID Connect 准备身份验证
- OpenID Connect 身份验证
- OpenID Connect 注销
- 查询 API 密钥信息
- 查询用户
- 更新 API 密钥
- 更新安全设置
- 批量更新 API 密钥
- SAML 准备身份验证
- SAML 身份验证
- SAML 注销
- SAML 失效
- SAML 完成注销
- SAML 服务提供商元数据
- SSL 证书
- 激活用户配置文件
- 禁用用户配置文件
- 启用用户配置文件
- 获取用户配置文件
- 建议用户配置文件
- 更新用户配置文件数据
- 具有用户配置文件权限
- 创建跨集群 API 密钥
- 更新跨集群 API 密钥
- 快照和还原 API
- 快照生命周期管理 API
- SQL API
- 同义词 API
- 文本结构 API
- 转换 API
- 使用情况 API
- Watcher API
- 定义
- 迁移指南
- 发行说明
- Elasticsearch 版本 8.17.0
- Elasticsearch 版本 8.16.1
- Elasticsearch 版本 8.16.0
- Elasticsearch 版本 8.15.5
- Elasticsearch 版本 8.15.4
- Elasticsearch 版本 8.15.3
- Elasticsearch 版本 8.15.2
- Elasticsearch 版本 8.15.1
- Elasticsearch 版本 8.15.0
- Elasticsearch 版本 8.14.3
- Elasticsearch 版本 8.14.2
- Elasticsearch 版本 8.14.1
- Elasticsearch 版本 8.14.0
- Elasticsearch 版本 8.13.4
- Elasticsearch 版本 8.13.3
- Elasticsearch 版本 8.13.2
- Elasticsearch 版本 8.13.1
- Elasticsearch 版本 8.13.0
- Elasticsearch 版本 8.12.2
- Elasticsearch 版本 8.12.1
- Elasticsearch 版本 8.12.0
- Elasticsearch 版本 8.11.4
- Elasticsearch 版本 8.11.3
- Elasticsearch 版本 8.11.2
- Elasticsearch 版本 8.11.1
- Elasticsearch 版本 8.11.0
- Elasticsearch 版本 8.10.4
- Elasticsearch 版本 8.10.3
- Elasticsearch 版本 8.10.2
- Elasticsearch 版本 8.10.1
- Elasticsearch 版本 8.10.0
- Elasticsearch 版本 8.9.2
- Elasticsearch 版本 8.9.1
- Elasticsearch 版本 8.9.0
- Elasticsearch 版本 8.8.2
- Elasticsearch 版本 8.8.1
- Elasticsearch 版本 8.8.0
- Elasticsearch 版本 8.7.1
- Elasticsearch 版本 8.7.0
- Elasticsearch 版本 8.6.2
- Elasticsearch 版本 8.6.1
- Elasticsearch 版本 8.6.0
- Elasticsearch 版本 8.5.3
- Elasticsearch 版本 8.5.2
- Elasticsearch 版本 8.5.1
- Elasticsearch 版本 8.5.0
- Elasticsearch 版本 8.4.3
- Elasticsearch 版本 8.4.2
- Elasticsearch 版本 8.4.1
- Elasticsearch 版本 8.4.0
- Elasticsearch 版本 8.3.3
- Elasticsearch 版本 8.3.2
- Elasticsearch 版本 8.3.1
- Elasticsearch 版本 8.3.0
- Elasticsearch 版本 8.2.3
- Elasticsearch 版本 8.2.2
- Elasticsearch 版本 8.2.1
- Elasticsearch 版本 8.2.0
- Elasticsearch 版本 8.1.3
- Elasticsearch 版本 8.1.2
- Elasticsearch 版本 8.1.1
- Elasticsearch 版本 8.1.0
- Elasticsearch 版本 8.0.1
- Elasticsearch 版本 8.0.0
- Elasticsearch 版本 8.0.0-rc2
- Elasticsearch 版本 8.0.0-rc1
- Elasticsearch 版本 8.0.0-beta1
- Elasticsearch 版本 8.0.0-alpha2
- Elasticsearch 版本 8.0.0-alpha1
- 依赖项和版本
ES|QL 命令
编辑ES|QL 命令
编辑
处理命令
编辑ES|QL 处理命令通过添加、删除或更改行和列来更改输入表格。

ES|QL 支持以下处理命令
FROM
编辑FROM 源命令返回一个包含来自数据流、索引或别名的数据的表格。
语法
FROM index_pattern [METADATA fields]
参数
-
index_pattern - 索引、数据流或别名的列表。支持通配符和日期数学。
-
fields - 要检索的元数据字段的逗号分隔列表。
描述
FROM 源命令返回一个包含来自数据流、索引或别名的数据的表格。结果表中的每一行代表一个文档。每一列对应一个字段,并且可以通过该字段的名称访问。
默认情况下,没有显式LIMIT 的 ES|QL 查询使用 1000 的隐式限制。这也适用于 FROM。没有 LIMIT 的 FROM 命令
FROM employees
执行方式如下
FROM employees | LIMIT 1000
示例
FROM employees
您可以使用日期数学来引用索引、别名和数据流。这对于时间序列数据很有用,例如访问今天的索引
FROM <logs-{now/d}>
使用逗号分隔的列表或通配符来查询多个数据流、索引或别名
FROM employees-00001,other-employees-*
使用 <remote_cluster_name>:<target> 格式来查询远程集群上的数据流和索引
FROM cluster_one:employees-00001,cluster_two:other-employees-*
使用可选的 METADATA 指令来启用元数据字段
FROM employees METADATA _id
使用双引号 (") 或三个双引号 (""") 来转义包含特殊字符的索引名称
FROM "this=that", """this[that"""
ROW
编辑ROW 源命令生成一个包含您指定的一个或多个带值的列的行。这对于测试非常有用。
语法
ROW column1 = value1[, ..., columnN = valueN]
参数
-
columnX - 列名。如果存在重复的列名,则只有最右边的重复项会创建一个列。
-
valueX - 列的值。可以是字面量、表达式或函数。
示例
ROW a = 1, b = "two", c = null
| a:integer | b:keyword | c:null |
|---|---|---|
1 |
"two" |
null |
使用方括号创建多值列
ROW a = [2, 1]
ROW 支持使用函数
ROW a = ROUND(1.23, 0)
SHOW
编辑SHOW 源命令返回有关部署及其功能的信息。
语法
SHOW item
参数
-
item - 只能是
INFO。
示例
使用 SHOW INFO 返回部署的版本、构建日期和哈希值。
SHOW INFO
| version | date | hash |
|---|---|---|
8.13.0 |
2024-02-23T10:04:18.123117961Z |
04ba8c8db2507501c88f215e475de7b0798cb3b3 |
DISSECT
编辑DISSECT 使您能够从字符串中提取结构化数据。
语法
DISSECT input "pattern" [APPEND_SEPARATOR="<separator>"]
参数
-
input - 包含您要构建结构的字符串的列。如果该列有多个值,
DISSECT将处理每个值。 -
pattern - Dissect 模式。如果字段名称与现有列冲突,则会删除现有列。如果一个字段名使用多次,则只有最右边的重复项会创建一个列。
-
<separator> - 一个字符串,用作在使用追加修饰符时,附加值之间的分隔符。
描述
DISSECT 使您能够从字符串中提取结构化数据。DISSECT 将字符串与基于分隔符的模式进行匹配,并将指定的键提取为列。
有关 dissect 模式的语法,请参阅使用 DISSECT 处理数据。
示例
以下示例解析包含时间戳、一些文本和一个 IP 地址的字符串
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1" | DISSECT a """%{date} - %{msg} - %{ip}""" | KEEP date, msg, ip
| date:keyword | msg:keyword | ip:keyword |
|---|---|---|
2023-01-23T12:15:00.000Z |
some text |
127.0.0.1 |
默认情况下,DISSECT 输出关键字字符串列。要转换为其他类型,请使用类型转换函数
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1" | DISSECT a """%{date} - %{msg} - %{ip}""" | KEEP date, msg, ip | EVAL date = TO_DATETIME(date)
| msg:keyword | ip:keyword | date:date |
|---|---|---|
some text |
127.0.0.1 |
2023-01-23T12:15:00.000Z |
DROP
编辑DROP 处理命令删除一个或多个列。
语法
DROP columns
参数
-
columns - 要删除的列的逗号分隔列表。支持通配符。
示例
FROM employees | DROP height
您可以使用通配符删除名称与模式匹配的所有列,而不是按名称指定每一列
FROM employees | DROP height*
ENRICH
编辑ENRICH 使您能够使用充实策略将现有索引中的数据添加为新列。
语法
ENRICH policy [ON match_field] [WITH [new_name1 = ]field1, [new_name2 = ]field2, ...]
参数
-
policy - 充实策略的名称。您需要先创建和执行充实策略。
-
mode - 跨集群 ES|QL 中充实命令的模式。请参阅跨集群进行充实。
-
match_field - 匹配字段。
ENRICH使用它的值在充实索引中查找记录。如果未指定,则将在名称与充实策略中定义的match_field相同的列上执行匹配。 -
fieldX - 从充实索引添加到结果作为新列的充实字段。如果已存在与充实字段同名的列,则现有列将被新列替换。如果未指定,则会添加策略中定义的每个充实字段。除非重命名充实字段,否则将删除与充实字段同名的列。
-
new_nameX - 使您能够更改为每个充实字段添加的列的名称。默认为充实字段名称。如果列具有与新名称相同的名称,则会将其丢弃。如果一个名称(新名称或原始名称)多次出现,则只有最右边的重复项会创建一个新列。
描述
ENRICH 使您能够使用充实策略将现有索引中的数据添加为新列。有关设置策略的信息,请参阅数据充实。
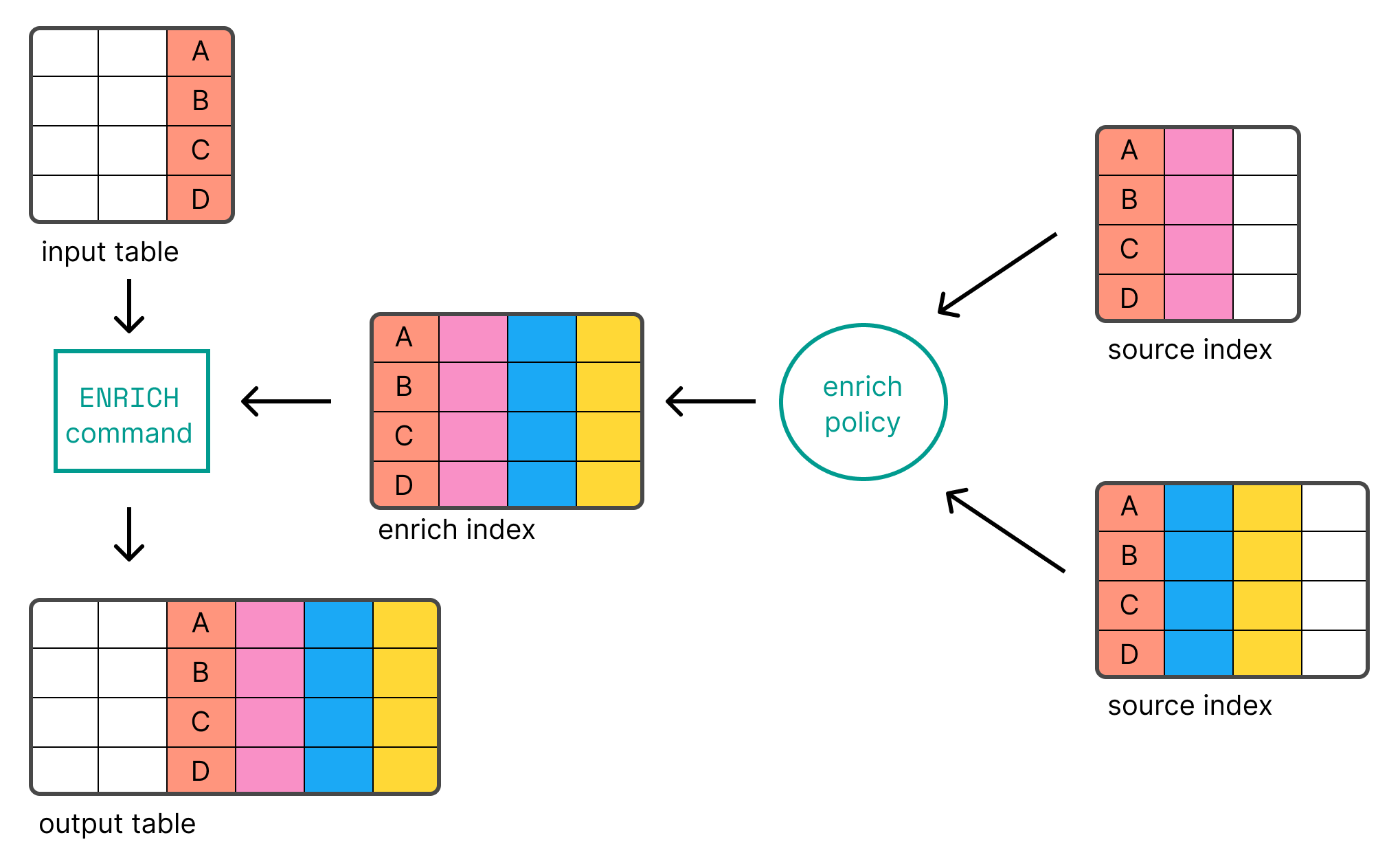
在使用 ENRICH 之前,您需要创建并执行充实策略。
示例
以下示例使用 languages_policy 充实策略来为策略中定义的每个充实字段添加一个新列。匹配是使用充实策略中定义的 match_field 执行的,并且要求输入表具有一个与其名称相同的列(本示例中为 language_code)。ENRICH 将根据匹配字段值在充实索引中查找记录。
ROW language_code = "1" | ENRICH languages_policy
| language_code:keyword | language_name:keyword |
|---|---|
1 |
English |
要使用与策略中定义的 match_field 名称不同的列作为匹配字段,请使用 ON <column-name>
ROW a = "1" | ENRICH languages_policy ON a
| a:keyword | language_name:keyword |
|---|---|
1 |
English |
默认情况下,策略中定义的每个充实字段都将添加为一列。要显式选择要添加的充实字段,请使用 WITH <field1>, <field2>, ...
ROW a = "1" | ENRICH languages_policy ON a WITH language_name
| a:keyword | language_name:keyword |
|---|---|
1 |
English |
您可以使用 WITH new_name=<field1> 重命名添加的列
ROW a = "1" | ENRICH languages_policy ON a WITH name = language_name
| a:keyword | name:keyword |
|---|---|
1 |
English |
如果发生名称冲突,新创建的列将覆盖现有列。
EVAL
编辑EVAL 处理命令使您能够追加具有计算值的新列。
语法
EVAL [column1 =] value1[, ..., [columnN =] valueN]
参数
-
columnX - 列名。如果已存在与该名称相同的列,则会删除现有列。如果一个列名使用多次,则只有最右边的重复项会创建一个列。
-
valueX - 列的值。可以是字面量、表达式或函数。可以使用定义在其左侧的列。
描述
EVAL 处理命令使您能够追加具有计算值的新列。EVAL 支持用于计算值的各种函数。有关更多信息,请参阅函数。
示例
FROM employees | SORT emp_no | KEEP first_name, last_name, height | EVAL height_feet = height * 3.281, height_cm = height * 100
| first_name:keyword | last_name:keyword | height:double | height_feet:double | height_cm:double |
|---|---|---|---|---|
Georgi |
Facello |
2.03 |
6.66043 |
202.99999999999997 |
Bezalel |
Simmel |
2.08 |
6.82448 |
208.0 |
Parto |
Bamford |
1.83 |
6.004230000000001 |
183.0 |
如果指定的列已存在,则会删除现有列,并将新列附加到表中
FROM employees | SORT emp_no | KEEP first_name, last_name, height | EVAL height = height * 3.281
| first_name:keyword | last_name:keyword | height:double |
|---|---|---|
Georgi |
Facello |
6.66043 |
Bezalel |
Simmel |
6.82448 |
Parto |
Bamford |
6.004230000000001 |
指定输出列名是可选的。如果未指定,则新列名等于表达式。以下查询添加一个名为 height*3.281 的列
FROM employees | SORT emp_no | KEEP first_name, last_name, height | EVAL height * 3.281
| first_name:keyword | last_name:keyword | height:double | height * 3.281:double |
|---|---|---|---|
Georgi |
Facello |
2.03 |
6.66043 |
Bezalel |
Simmel |
2.08 |
6.82448 |
Parto |
Bamford |
1.83 |
6.004230000000001 |
由于此名称包含特殊字符,因此在后续命令中使用时需要用反引号 (`) 引起来
FROM employees | EVAL height * 3.281 | STATS avg_height_feet = AVG(`height * 3.281`)
| avg_height_feet:double |
|---|
5.801464200000001 |
GROK
编辑GROK 使您能够从字符串中提取结构化数据。
语法
GROK input "pattern"
参数
-
input - 包含要结构化的字符串的列。如果列具有多个值,则
GROK将处理每个值。 -
pattern - 一个 grok 模式。如果字段名称与现有列冲突,则会丢弃现有列。如果一个字段名称被多次使用,则会创建一个多值列,每个字段名称的出现都会有一个值。
描述
GROK 使您能够从字符串中提取结构化数据。GROK 基于正则表达式将字符串与模式匹配,并将指定的模式提取为列。
有关 grok 模式的语法,请参阅使用 GROK 处理数据。
示例
以下示例解析包含时间戳、IP 地址、电子邮件地址和数字的字符串
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42" | GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num}""" | KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:keyword |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
默认情况下,GROK 输出关键字字符串列。int 和 float 类型可以通过在模式中的语义后面附加 :type 来进行转换。例如 {NUMBER:num:int}
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42" | GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}""" | KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:integer |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
对于其他类型转换,请使用类型转换函数
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42" | GROK a """%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}""" | KEEP date, ip, email, num | EVAL date = TO_DATETIME(date)
| ip:keyword | email:keyword | num:integer | date:date |
|---|---|---|---|
127.0.0.1 |
42 |
2023-01-23T12:15:00.000Z |
如果一个字段名称被多次使用,GROK 会创建一个多值列
FROM addresses | KEEP city.name, zip_code | GROK zip_code """%{WORD:zip_parts} %{WORD:zip_parts}"""
| city.name:keyword | zip_code:keyword | zip_parts:keyword |
|---|---|---|
Amsterdam |
1016 ED |
["1016", "ED"] |
San Francisco |
CA 94108 |
["CA", "94108"] |
Tokyo |
100-7014 |
null |
KEEP
编辑KEEP 处理命令允许您指定要返回的列以及返回的顺序。
语法
KEEP columns
参数
-
columns - 要保留的列的逗号分隔列表。支持通配符。请参阅下文,了解现有列与多个给定通配符或列名匹配时的行为。
描述
KEEP 处理命令允许您指定要返回的列以及返回的顺序。
当一个字段名称与多个表达式匹配时,将应用优先级规则。字段按照它们出现的顺序添加。如果一个字段与多个表达式匹配,则应用以下优先级规则(从最高到最低优先级):
- 完整字段名称(无通配符)
- 部分通配符表达式(例如:
fieldNam*) - 仅通配符 (
*)
如果一个字段与两个具有相同优先级的表达式匹配,则最右边的表达式胜出。
有关这些优先级规则的说明,请参阅示例。
示例
列将按指定的顺序返回
FROM employees | KEEP emp_no, first_name, last_name, height
| emp_no:integer | first_name:keyword | last_name:keyword | height:double |
|---|---|---|---|
10001 |
Georgi |
Facello |
2.03 |
10002 |
Bezalel |
Simmel |
2.08 |
10003 |
Parto |
Bamford |
1.83 |
10004 |
Chirstian |
Koblick |
1.78 |
10005 |
Kyoichi |
Maliniak |
2.05 |
您可以使用通配符返回所有名称与模式匹配的列,而无需按名称指定每个列
FROM employees | KEEP h*
| height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date |
|---|
星号通配符 (*) 本身转换为所有与其它参数不匹配的列。
此查询将首先返回所有名称以 h 开头的列,然后返回所有其他列
FROM employees | KEEP h*, *
| height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date | avg_worked_seconds:long | birth_date:date | emp_no:integer | first_name:keyword | gender:keyword | is_rehired:boolean | job_positions:keyword | languages:integer | languages.byte:integer | languages.long:long | languages.short:integer | last_name:keyword | salary:integer | salary_change:double | salary_change.int:integer | salary_change.keyword:keyword | salary_change.long:long | still_hired:boolean |
|---|
以下示例显示当一个字段名称与多个表达式匹配时,优先级规则如何工作。
完整字段名称的优先级高于通配符表达式
FROM employees | KEEP first_name, last_name, first_name*
| first_name:keyword | last_name:keyword |
|---|
通配符表达式具有相同的优先级,但最后一个胜出(尽管不太具体)
FROM employees | KEEP first_name*, last_name, first_na*
| last_name:keyword | first_name:keyword |
|---|
简单的通配符表达式 * 具有最低优先级。输出顺序由其他参数确定
FROM employees | KEEP *, first_name
| avg_worked_seconds:long | birth_date:date | emp_no:integer | gender:keyword | height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date | is_rehired:boolean | job_positions:keyword | languages:integer | languages.byte:integer | languages.long:long | languages.short:integer | last_name:keyword | salary:integer | salary_change:double | salary_change.int:integer | salary_change.keyword:keyword | salary_change.long:long | still_hired:boolean | first_name:keyword |
|---|
LIMIT
编辑LIMIT 处理命令允许您限制返回的行数。
语法
LIMIT max_number_of_rows
参数
-
max_number_of_rows - 要返回的最大行数。
描述
LIMIT 处理命令允许您限制返回的行数。无论 LIMIT 命令的值如何,查询返回的行数都不会超过 10,000 行。
此限制仅适用于查询检索的行数。查询和聚合在完整数据集上运行。
要克服此限制
可以使用以下动态集群设置更改默认限制和最大限制
-
esql.query.result_truncation_default_size -
esql.query.result_truncation_max_size
示例
FROM employees | SORT emp_no ASC | LIMIT 5
MV_EXPAND
编辑此功能处于技术预览阶段,可能会在未来版本中更改或删除。Elastic 将努力解决任何问题,但技术预览中的功能不受官方 GA 功能的支持 SLA 约束。
MV_EXPAND 处理命令将多值列展开为每值一行,复制其他列。
语法
MV_EXPAND column
参数
-
column - 要展开的多值列。
示例
ROW a=[1,2,3], b="b", j=["a","b"] | MV_EXPAND a
| a:integer | b:keyword | j:keyword |
|---|---|---|
1 |
b |
["a", "b"] |
2 |
b |
["a", "b"] |
3 |
b |
["a", "b"] |
RENAME
编辑RENAME 处理命令重命名一个或多个列。
语法
RENAME old_name1 AS new_name1[, ..., old_nameN AS new_nameN]
参数
-
old_nameX - 您要重命名的列的名称。
-
new_nameX - 列的新名称。如果它与现有列名冲突,则会删除现有列。如果多个列被重命名为相同的名称,则会删除除最右侧具有相同新名称的列之外的所有列。
描述
RENAME 处理命令重命名一个或多个列。如果已存在具有新名称的列,则它将被新列替换。
示例
FROM employees | KEEP first_name, last_name, still_hired | RENAME still_hired AS employed
可以使用单个 RENAME 命令重命名多个列
FROM employees | KEEP first_name, last_name | RENAME first_name AS fn, last_name AS ln
SORT
编辑SORT 处理命令根据一个或多个列对表进行排序。
语法
SORT column1 [ASC/DESC][NULLS FIRST/NULLS LAST][, ..., columnN [ASC/DESC][NULLS FIRST/NULLS LAST]]
参数
-
columnX - 要排序的列。
描述
SORT 处理命令根据一个或多个列对表进行排序。
默认排序顺序为升序。使用 ASC 或 DESC 指定显式排序顺序。
具有相同排序键的两行被认为是相等的。您可以提供额外的排序表达式来作为平局打破器。
在多值列上排序时,升序排序时使用最小值,降序排序时使用最大值。
默认情况下,null 值被视为大于任何其他值。使用升序排序顺序,null 值将排在最后,而使用降序排序顺序,null 值将排在最前面。您可以通过提供 NULLS FIRST 或 NULLS LAST 来更改此行为。
示例
FROM employees | KEEP first_name, last_name, height | SORT height
使用 ASC 显式按升序排序
FROM employees | KEEP first_name, last_name, height | SORT height DESC
提供额外的排序表达式来作为平局打破器
FROM employees | KEEP first_name, last_name, height | SORT height DESC, first_name ASC
使用 NULLS FIRST 首先排序 null 值
FROM employees | KEEP first_name, last_name, height | SORT first_name ASC NULLS FIRST
STATS
编辑STATS 处理命令根据公共值对行进行分组,并计算分组行的一个或多个聚合值。
语法
STATS [column1 =] expression1 [WHERE boolean_expression1][, ..., [columnN =] expressionN [WHERE boolean_expressionN]] [BY grouping_expression1[, ..., grouping_expressionN]]
参数
-
columnX - 聚合值返回的名称。如果省略,则名称等于相应的表达式 (
expressionX)。如果多个列具有相同的名称,则会忽略除最右侧具有此名称的列之外的所有列。 -
expressionX - 计算聚合值的表达式。
-
grouping_expressionX - 输出要分组的值的表达式。如果其名称与计算列之一重合,则会忽略该列。
-
boolean_expressionX - 一行要包含在
expressionX的评估中必须满足的条件。
计算聚合时会跳过单独的 null 值。
描述
STATS 处理命令根据公共值对行进行分组,并计算分组行的一个或多个聚合值。对于每个聚合值的计算,可以使用 WHERE 过滤组中的行。如果省略 BY,则输出表将只包含一行,其中包含应用于整个数据集的聚合。
支持以下聚合函数
-
AVG -
COUNT -
COUNT_DISTINCT -
MAX -
MEDIAN -
MEDIAN_ABSOLUTE_DEVIATION -
MIN -
PERCENTILE -
[预览] 此功能处于技术预览阶段,可能会在未来版本中更改或删除。Elastic 将努力解决任何问题,但技术预览中的功能不受官方 GA 功能的支持 SLA 约束。
ST_CENTROID_AGG -
SUM -
TOP -
VALUES -
WEIGHTED_AVG
支持以下分组函数
不带任何组的 STATS 比添加组快得多。
对单个表达式进行分组比对多个表达式进行分组要优化得多。在某些测试中,我们发现对单个 keyword 列进行分组比对两个 keyword 列进行分组快五倍。不要尝试通过使用诸如 CONCAT 之类的方式将两列组合在一起然后进行分组来解决此问题 - 这不会更快。
示例
计算统计信息并按另一列的值进行分组
FROM employees | STATS count = COUNT(emp_no) BY languages | SORT languages
| count:long | languages:integer |
|---|---|
15 |
1 |
19 |
2 |
17 |
3 |
18 |
4 |
21 |
5 |
10 |
null |
省略 BY 将返回一行,其中包含应用于整个数据集的聚合
FROM employees | STATS avg_lang = AVG(languages)
| avg_lang:double |
|---|
3.1222222222222222 |
可以计算多个值
FROM employees | STATS avg_lang = AVG(languages), max_lang = MAX(languages)
| avg_lang:double | max_lang:integer |
|---|---|
3.1222222222222222 |
5 |
要筛选进入聚合的行,请使用 WHERE 子句
FROM employees | STATS avg50s = AVG(salary)::LONG WHERE birth_date < "1960-01-01", avg60s = AVG(salary)::LONG WHERE birth_date >= "1960-01-01" BY gender | SORT gender
| avg50s:long | avg60s:long | gender:keyword |
|---|---|---|
55462 |
46637 |
F |
48279 |
44879 |
M |
聚合可以混合使用,可以有或没有过滤器,并且分组也是可选的
FROM employees | EVAL Ks = salary / 1000 // thousands | STATS under_40K = COUNT(*) WHERE Ks < 40, inbetween = COUNT(*) WHERE 40 <= Ks AND Ks < 60, over_60K = COUNT(*) WHERE 60 <= Ks, total = COUNT(*)
| under_40K:long | inbetween:long | over_60K:long | total:long |
|---|---|---|---|
36 |
39 |
25 |
100 |
ROW i=1, a=["a", "b"] | STATS MIN(i) BY a | SORT a ASC
| MIN(i):integer | a:keyword |
|---|---|
1 |
a |
1 |
b |
也可以按多个值进行分组
FROM employees | EVAL hired = DATE_FORMAT("yyyy", hire_date) | STATS avg_salary = AVG(salary) BY hired, languages.long | EVAL avg_salary = ROUND(avg_salary) | SORT hired, languages.long
如果所有分组键都是多值的,则输入行会出现在所有组中
ROW i=1, a=["a", "b"], b=[2, 3] | STATS MIN(i) BY a, b | SORT a ASC, b ASC
| MIN(i):integer | a:keyword | b:整数 |
|---|---|---|
1 |
a |
2 |
1 |
a |
3 |
1 |
b |
2 |
1 |
b |
3 |
聚合函数和分组表达式都接受其他函数。这对于在多值列上使用 STATS 非常有用。例如,要计算平均工资变化,可以使用 MV_AVG 先计算每位员工的多个值的平均值,然后将结果与 AVG 函数一起使用
FROM employees | STATS avg_salary_change = ROUND(AVG(MV_AVG(salary_change)), 10)
| avg_salary_change:双精度浮点数 |
|---|
1.3904535865 |
按表达式分组的一个示例是按员工姓氏的首字母对员工进行分组
FROM employees | STATS my_count = COUNT() BY LEFT(last_name, 1) | SORT `LEFT(last_name, 1)`
| my_count:长整数 | LEFT(last_name, 1):关键词 |
|---|---|
2 |
A |
11 |
B |
5 |
C |
5 |
D |
2 |
E |
4 |
F |
4 |
G |
6 |
H |
2 |
J |
3 |
K |
5 |
L |
12 |
M |
4 |
N |
1 |
O |
7 |
P |
5 |
R |
13 |
S |
4 |
T |
2 |
W |
3 |
Z |
指定输出列名是可选的。如果未指定,则新列名与表达式相同。以下查询返回一个名为 AVG(salary) 的列
FROM employees | STATS AVG(salary)
| AVG(salary):双精度浮点数 |
|---|
48248.55 |
由于此名称包含特殊字符,因此在后续命令中使用时需要用反引号 (`) 引起来
FROM employees | STATS AVG(salary) | EVAL avg_salary_rounded = ROUND(`AVG(salary)`)
| AVG(salary):双精度浮点数 | avg_salary_rounded:双精度浮点数 |
|---|---|
48248.55 |
48249.0 |
WHERE
编辑WHERE 处理命令生成一个表,其中包含输入表中所有满足所提供条件的行的记录。
语法
WHERE expression
参数
-
表达式 - 一个布尔表达式。
示例
FROM employees | KEEP first_name, last_name, still_hired | WHERE still_hired == true
如果 still_hired 是一个布尔字段,则可以简化为
FROM employees | KEEP first_name, last_name, still_hired | WHERE still_hired
使用日期数学从特定时间范围检索数据。例如,要检索最近一小时的日志
FROM sample_data | WHERE @timestamp > NOW() - 1 hour
FROM employees | KEEP first_name, last_name, height | WHERE LENGTH(first_name) < 4
有关所有函数的完整列表,请参阅函数概述。
对于 NULL 比较,请使用 IS NULL 和 IS NOT NULL 谓词
FROM employees | WHERE birth_date IS NULL | KEEP first_name, last_name | SORT first_name | LIMIT 3
| first_name:keyword | last_name:keyword |
|---|---|
Basil |
Tramer |
Florian |
Syrotiuk |
Lucien |
Rosenbaum |
FROM employees | WHERE is_rehired IS NOT NULL | STATS COUNT(emp_no)
| COUNT(emp_no):长整数 |
|---|
84 |
使用 LIKE 通过通配符根据字符串模式筛选数据。LIKE 通常作用于运算符左侧的字段,但也可以作用于常量(字面量)表达式。运算符的右侧表示模式。
支持以下通配符
-
*匹配零个或多个字符。 -
?匹配一个字符。
支持的类型
| 字符串 | pattern | 结果 |
|---|---|---|
关键词 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
FROM employees | WHERE first_name LIKE """?b*""" | KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
Ebbe |
Callaway |
Eberhardt |
Terkki |
匹配 * 和 . 等确切字符将需要转义。转义字符是反斜杠 \。由于反斜杠也是字符串字面量中的特殊字符,因此需要进一步转义。
ROW message = "foo * bar" | WHERE message LIKE "foo \\* bar"
为了减少转义的开销,我们建议使用三引号字符串 """
ROW message = "foo * bar" | WHERE message LIKE """foo \* bar"""
使用 RLIKE 通过 正则表达式根据字符串模式筛选数据。RLIKE 通常作用于运算符左侧的字段,但也可以作用于常量(字面量)表达式。运算符的右侧表示模式。
支持的类型
| 字符串 | pattern | 结果 |
|---|---|---|
关键词 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
FROM employees | WHERE first_name RLIKE """.leja.*""" | KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
Alejandro |
McAlpine |
匹配特殊字符(例如 ., *, (…)将需要转义。转义字符是反斜杠 \。由于反斜杠也是字符串字面量中的特殊字符,因此需要进一步转义。
ROW message = "foo ( bar" | WHERE message RLIKE "foo \\( bar"
为了减少转义的开销,我们建议使用三引号字符串 """
ROW message = "foo ( bar" | WHERE message RLIKE """foo \( bar"""
IN 运算符允许测试字段或表达式是否等于字面量、字段或表达式列表中的一个元素
ROW a = 1, b = 4, c = 3 | WHERE c-a IN (3, b / 2, a)
| a:integer | b:整数 | c:整数 |
|---|---|---|
1 |
4 |
3 |
有关所有运算符的完整列表,请参阅运算符。