- Elasticsearch 指南其他版本
- 8.17 中的新功能
- Elasticsearch 基础
- 快速入门
- 设置 Elasticsearch
- 升级 Elasticsearch
- 索引模块
- 映射
- 文本分析
- 索引模板
- 数据流
- 摄取管道
- 别名
- 搜索您的数据
- 重新排名
- 查询 DSL
- 聚合
- 地理空间分析
- 连接器
- EQL
- ES|QL
- SQL
- 脚本
- 数据管理
- 自动缩放
- 监视集群
- 汇总或转换数据
- 设置高可用性集群
- 快照和还原
- 保护 Elastic Stack 的安全
- Watcher
- 命令行工具
- elasticsearch-certgen
- elasticsearch-certutil
- elasticsearch-create-enrollment-token
- elasticsearch-croneval
- elasticsearch-keystore
- elasticsearch-node
- elasticsearch-reconfigure-node
- elasticsearch-reset-password
- elasticsearch-saml-metadata
- elasticsearch-service-tokens
- elasticsearch-setup-passwords
- elasticsearch-shard
- elasticsearch-syskeygen
- elasticsearch-users
- 优化
- 故障排除
- 修复常见的集群问题
- 诊断未分配的分片
- 向系统中添加丢失的层
- 允许 Elasticsearch 在系统中分配数据
- 允许 Elasticsearch 分配索引
- 索引将索引分配过滤器与数据层节点角色混合,以在数据层之间移动
- 没有足够的节点来分配所有分片副本
- 单个节点上索引的分片总数已超过
- 每个节点的分片总数已达到
- 故障排除损坏
- 修复磁盘空间不足的数据节点
- 修复磁盘空间不足的主节点
- 修复磁盘空间不足的其他角色节点
- 启动索引生命周期管理
- 启动快照生命周期管理
- 从快照恢复
- 故障排除损坏的存储库
- 解决重复的快照策略失败问题
- 故障排除不稳定的集群
- 故障排除发现
- 故障排除监控
- 故障排除转换
- 故障排除 Watcher
- 故障排除搜索
- 故障排除分片容量健康问题
- 故障排除不平衡的集群
- 捕获诊断信息
- REST API
- API 约定
- 通用选项
- REST API 兼容性
- 自动缩放 API
- 行为分析 API
- 紧凑和对齐文本 (CAT) API
- 集群 API
- 跨集群复制 API
- 连接器 API
- 数据流 API
- 文档 API
- 丰富 API
- EQL API
- ES|QL API
- 功能 API
- Fleet API
- 图表探索 API
- 索引 API
- 别名是否存在
- 别名
- 分析
- 分析索引磁盘使用量
- 清除缓存
- 克隆索引
- 关闭索引
- 创建索引
- 创建或更新别名
- 创建或更新组件模板
- 创建或更新索引模板
- 创建或更新索引模板(旧版)
- 删除组件模板
- 删除悬挂索引
- 删除别名
- 删除索引
- 删除索引模板
- 删除索引模板(旧版)
- 存在
- 字段使用情况统计信息
- 刷新
- 强制合并
- 获取别名
- 获取组件模板
- 获取字段映射
- 获取索引
- 获取索引设置
- 获取索引模板
- 获取索引模板(旧版)
- 获取映射
- 导入悬挂索引
- 索引恢复
- 索引段
- 索引分片存储
- 索引统计信息
- 索引模板是否存在(旧版)
- 列出悬挂索引
- 打开索引
- 刷新
- 解析索引
- 解析集群
- 翻转
- 收缩索引
- 模拟索引
- 模拟模板
- 拆分索引
- 解冻索引
- 更新索引设置
- 更新映射
- 索引生命周期管理 API
- 推理 API
- 信息 API
- 摄取 API
- 许可 API
- Logstash API
- 机器学习 API
- 机器学习异常检测 API
- 机器学习数据帧分析 API
- 机器学习训练模型 API
- 迁移 API
- 节点生命周期 API
- 查询规则 API
- 重新加载搜索分析器 API
- 存储库计量 API
- 汇总 API
- 根 API
- 脚本 API
- 搜索 API
- 搜索应用程序 API
- 可搜索快照 API
- 安全 API
- 身份验证
- 更改密码
- 清除缓存
- 清除角色缓存
- 清除权限缓存
- 清除 API 密钥缓存
- 清除服务帐户令牌缓存
- 创建 API 密钥
- 创建或更新应用程序权限
- 创建或更新角色映射
- 创建或更新角色
- 批量创建或更新角色 API
- 批量删除角色 API
- 创建或更新用户
- 创建服务帐户令牌
- 委托 PKI 身份验证
- 删除应用程序权限
- 删除角色映射
- 删除角色
- 删除服务帐户令牌
- 删除用户
- 禁用用户
- 启用用户
- 注册 Kibana
- 注册节点
- 获取 API 密钥信息
- 获取应用程序权限
- 获取内置权限
- 获取角色映射
- 获取角色
- 查询角色
- 获取服务帐户
- 获取服务帐户凭据
- 获取安全设置
- 获取令牌
- 获取用户权限
- 获取用户
- 授予 API 密钥
- 具有权限
- 使 API 密钥失效
- 使令牌失效
- OpenID Connect 准备身份验证
- OpenID Connect 身份验证
- OpenID Connect 注销
- 查询 API 密钥信息
- 查询用户
- 更新 API 密钥
- 更新安全设置
- 批量更新 API 密钥
- SAML 准备身份验证
- SAML 身份验证
- SAML 注销
- SAML 失效
- SAML 完成注销
- SAML 服务提供商元数据
- SSL 证书
- 激活用户配置文件
- 禁用用户配置文件
- 启用用户配置文件
- 获取用户配置文件
- 建议用户配置文件
- 更新用户配置文件数据
- 具有用户配置文件权限
- 创建跨集群 API 密钥
- 更新跨集群 API 密钥
- 快照和还原 API
- 快照生命周期管理 API
- SQL API
- 同义词 API
- 文本结构 API
- 转换 API
- 使用情况 API
- Watcher API
- 定义
- 迁移指南
- 发行说明
- Elasticsearch 版本 8.17.0
- Elasticsearch 版本 8.16.1
- Elasticsearch 版本 8.16.0
- Elasticsearch 版本 8.15.5
- Elasticsearch 版本 8.15.4
- Elasticsearch 版本 8.15.3
- Elasticsearch 版本 8.15.2
- Elasticsearch 版本 8.15.1
- Elasticsearch 版本 8.15.0
- Elasticsearch 版本 8.14.3
- Elasticsearch 版本 8.14.2
- Elasticsearch 版本 8.14.1
- Elasticsearch 版本 8.14.0
- Elasticsearch 版本 8.13.4
- Elasticsearch 版本 8.13.3
- Elasticsearch 版本 8.13.2
- Elasticsearch 版本 8.13.1
- Elasticsearch 版本 8.13.0
- Elasticsearch 版本 8.12.2
- Elasticsearch 版本 8.12.1
- Elasticsearch 版本 8.12.0
- Elasticsearch 版本 8.11.4
- Elasticsearch 版本 8.11.3
- Elasticsearch 版本 8.11.2
- Elasticsearch 版本 8.11.1
- Elasticsearch 版本 8.11.0
- Elasticsearch 版本 8.10.4
- Elasticsearch 版本 8.10.3
- Elasticsearch 版本 8.10.2
- Elasticsearch 版本 8.10.1
- Elasticsearch 版本 8.10.0
- Elasticsearch 版本 8.9.2
- Elasticsearch 版本 8.9.1
- Elasticsearch 版本 8.9.0
- Elasticsearch 版本 8.8.2
- Elasticsearch 版本 8.8.1
- Elasticsearch 版本 8.8.0
- Elasticsearch 版本 8.7.1
- Elasticsearch 版本 8.7.0
- Elasticsearch 版本 8.6.2
- Elasticsearch 版本 8.6.1
- Elasticsearch 版本 8.6.0
- Elasticsearch 版本 8.5.3
- Elasticsearch 版本 8.5.2
- Elasticsearch 版本 8.5.1
- Elasticsearch 版本 8.5.0
- Elasticsearch 版本 8.4.3
- Elasticsearch 版本 8.4.2
- Elasticsearch 版本 8.4.1
- Elasticsearch 版本 8.4.0
- Elasticsearch 版本 8.3.3
- Elasticsearch 版本 8.3.2
- Elasticsearch 版本 8.3.1
- Elasticsearch 版本 8.3.0
- Elasticsearch 版本 8.2.3
- Elasticsearch 版本 8.2.2
- Elasticsearch 版本 8.2.1
- Elasticsearch 版本 8.2.0
- Elasticsearch 版本 8.1.3
- Elasticsearch 版本 8.1.2
- Elasticsearch 版本 8.1.1
- Elasticsearch 版本 8.1.0
- Elasticsearch 版本 8.0.1
- Elasticsearch 版本 8.0.0
- Elasticsearch 版本 8.0.0-rc2
- Elasticsearch 版本 8.0.0-rc1
- Elasticsearch 版本 8.0.0-beta1
- Elasticsearch 版本 8.0.0-alpha2
- Elasticsearch 版本 8.0.0-alpha1
- 依赖项和版本
基数聚合
编辑基数聚合
编辑一个 单值 指标聚合,用于计算不同值的近似计数。
假设您正在索引商店销售数据,并且想要计算与查询匹配的已售出产品的唯一数量
resp = client.search( index="sales", size="0", aggs={ "type_count": { "cardinality": { "field": "type" } } }, ) print(resp)
response = client.search( index: 'sales', size: 0, body: { aggregations: { type_count: { cardinality: { field: 'type' } } } } ) puts response
const response = await client.search({ index: "sales", size: 0, aggs: { type_count: { cardinality: { field: "type", }, }, }, }); console.log(response);
POST /sales/_search?size=0 { "aggs": { "type_count": { "cardinality": { "field": "type" } } } }
响应
{ ... "aggregations": { "type_count": { "value": 3 } } }
精度控制
编辑此聚合还支持 precision_threshold 选项
resp = client.search( index="sales", size="0", aggs={ "type_count": { "cardinality": { "field": "type", "precision_threshold": 100 } } }, ) print(resp)
response = client.search( index: 'sales', size: 0, body: { aggregations: { type_count: { cardinality: { field: 'type', precision_threshold: 100 } } } } ) puts response
const response = await client.search({ index: "sales", size: 0, aggs: { type_count: { cardinality: { field: "type", precision_threshold: 100, }, }, }, }); console.log(response);
计数是近似的
编辑计算精确计数需要将值加载到哈希集中并返回其大小。当处理高基数集和/或大值时,这无法扩展,因为所需的内存使用量以及在节点之间传递每个分片集的需要会利用集群的太多资源。
此 cardinality 聚合基于 HyperLogLog++ 算法,该算法基于值的哈希进行计数,并具有一些有趣的特性
- 可配置的精度,决定如何在内存和准确性之间进行权衡,
- 在低基数集上具有出色的准确性,
- 固定的内存使用量:无论是否存在数十个还是数十亿个唯一值,内存使用量仅取决于配置的精度。
对于 c 的精度阈值,我们正在使用的实现需要大约 c * 8 个字节。
下图显示了误差在阈值之前和之后如何变化
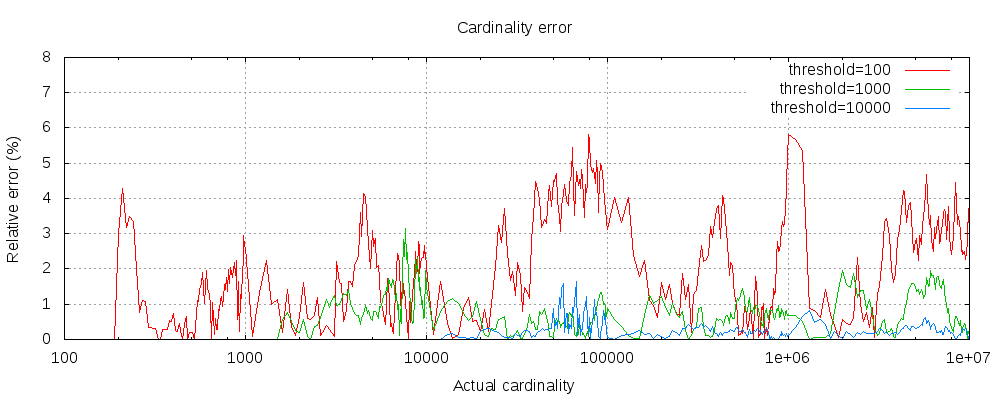
对于所有 3 个阈值,计数在配置的阈值之前都是准确的。虽然不能保证,但这种情况很可能发生。实际的准确性取决于所讨论的数据集。一般来说,大多数数据集都显示出始终如一的良好准确性。另请注意,即使阈值低至 100,即使在计数数百万个项目时,误差仍然非常低(如上图所示的 1-6%)。
HyperLogLog++ 算法取决于哈希值的前导零,数据集中哈希的精确分布会影响基数的准确性。
预先计算的哈希
编辑对于具有高基数的字符串字段,将字段值的哈希存储在索引中,然后在此字段上运行基数聚合可能会更快。这可以通过从客户端提供哈希值来完成,也可以通过使用 mapper-murmur3 插件让 Elasticsearch 为您计算哈希值来完成。
预先计算哈希通常仅在非常大和/或高基数字段上才有用,因为它节省了 CPU 和内存。但是,在数字字段上,哈希速度非常快,并且存储原始值所需的内存与存储哈希一样多或更少。对于低基数字符串字段也是如此,尤其是考虑到这些字段具有优化,以确保每个段的每个唯一值最多计算一次哈希。
脚本
编辑如果您需要两个字段组合的基数,请创建一个组合它们的运行时字段并对其进行聚合。
resp = client.search( index="sales", size="0", runtime_mappings={ "type_and_promoted": { "type": "keyword", "script": "emit(doc['type'].value + ' ' + doc['promoted'].value)" } }, aggs={ "type_promoted_count": { "cardinality": { "field": "type_and_promoted" } } }, ) print(resp)
response = client.search( index: 'sales', size: 0, body: { runtime_mappings: { type_and_promoted: { type: 'keyword', script: "emit(doc['type'].value + ' ' + doc['promoted'].value)" } }, aggregations: { type_promoted_count: { cardinality: { field: 'type_and_promoted' } } } } ) puts response
const response = await client.search({ index: "sales", size: 0, runtime_mappings: { type_and_promoted: { type: "keyword", script: "emit(doc['type'].value + ' ' + doc['promoted'].value)", }, }, aggs: { type_promoted_count: { cardinality: { field: "type_and_promoted", }, }, }, }); console.log(response);
POST /sales/_search?size=0 { "runtime_mappings": { "type_and_promoted": { "type": "keyword", "script": "emit(doc['type'].value + ' ' + doc['promoted'].value)" } }, "aggs": { "type_promoted_count": { "cardinality": { "field": "type_and_promoted" } } } }
缺失值
编辑missing 参数定义了应如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
resp = client.search( index="sales", size="0", aggs={ "tag_cardinality": { "cardinality": { "field": "tag", "missing": "N/A" } } }, ) print(resp)
response = client.search( index: 'sales', size: 0, body: { aggregations: { tag_cardinality: { cardinality: { field: 'tag', missing: 'N/A' } } } } ) puts response
const response = await client.search({ index: "sales", size: 0, aggs: { tag_cardinality: { cardinality: { field: "tag", missing: "N/A", }, }, }, }); console.log(response);
执行提示
编辑您可以使用不同的机制运行基数聚合
- 直接使用字段值 (
direct) - 通过使用字段的全局序号并在完成分片后解析这些值 (
global_ordinals) - 通过使用段序号值并在每个段之后解析这些值 (
segment_ordinals)
此外,还有两种“基于启发式”的模式。这些模式将导致 Elasticsearch 使用一些关于索引状态的数据来选择适当的执行方法。这两个启发式方法是
-
save_time_heuristic- 这是 Elasticsearch 8.4 及更高版本中的默认值。 -
save_memory_heuristic- 这是 Elasticsearch 8.3 及更早版本中的默认值
如果未指定,Elasticsearch 将应用启发式方法来选择适当的模式。另请注意,对于某些数据(非序号字段),direct 是唯一选项,在这种情况下,提示将被忽略。一般来说,没有必要设置此值。