- Elasticsearch 指南其他版本
- 8.17 中的新功能
- Elasticsearch 基础
- 快速入门
- 设置 Elasticsearch
- 升级 Elasticsearch
- 索引模块
- 映射
- 文本分析
- 索引模板
- 数据流
- 摄取管道
- 别名
- 搜索您的数据
- 重新排名
- 查询 DSL
- 聚合
- 地理空间分析
- 连接器
- EQL
- ES|QL
- SQL
- 脚本
- 数据管理
- 自动缩放
- 监视集群
- 汇总或转换数据
- 设置高可用性集群
- 快照和还原
- 保护 Elastic Stack 的安全
- Watcher
- 命令行工具
- elasticsearch-certgen
- elasticsearch-certutil
- elasticsearch-create-enrollment-token
- elasticsearch-croneval
- elasticsearch-keystore
- elasticsearch-node
- elasticsearch-reconfigure-node
- elasticsearch-reset-password
- elasticsearch-saml-metadata
- elasticsearch-service-tokens
- elasticsearch-setup-passwords
- elasticsearch-shard
- elasticsearch-syskeygen
- elasticsearch-users
- 优化
- 故障排除
- 修复常见的集群问题
- 诊断未分配的分片
- 向系统中添加丢失的层
- 允许 Elasticsearch 在系统中分配数据
- 允许 Elasticsearch 分配索引
- 索引将索引分配过滤器与数据层节点角色混合,以在数据层之间移动
- 没有足够的节点来分配所有分片副本
- 单个节点上索引的分片总数已超过
- 每个节点的分片总数已达到
- 故障排除损坏
- 修复磁盘空间不足的数据节点
- 修复磁盘空间不足的主节点
- 修复磁盘空间不足的其他角色节点
- 启动索引生命周期管理
- 启动快照生命周期管理
- 从快照恢复
- 故障排除损坏的存储库
- 解决重复的快照策略失败问题
- 故障排除不稳定的集群
- 故障排除发现
- 故障排除监控
- 故障排除转换
- 故障排除 Watcher
- 故障排除搜索
- 故障排除分片容量健康问题
- 故障排除不平衡的集群
- 捕获诊断信息
- REST API
- API 约定
- 通用选项
- REST API 兼容性
- 自动缩放 API
- 行为分析 API
- 紧凑和对齐文本 (CAT) API
- 集群 API
- 跨集群复制 API
- 连接器 API
- 数据流 API
- 文档 API
- 丰富 API
- EQL API
- ES|QL API
- 功能 API
- Fleet API
- 图表探索 API
- 索引 API
- 别名是否存在
- 别名
- 分析
- 分析索引磁盘使用量
- 清除缓存
- 克隆索引
- 关闭索引
- 创建索引
- 创建或更新别名
- 创建或更新组件模板
- 创建或更新索引模板
- 创建或更新索引模板(旧版)
- 删除组件模板
- 删除悬挂索引
- 删除别名
- 删除索引
- 删除索引模板
- 删除索引模板(旧版)
- 存在
- 字段使用情况统计信息
- 刷新
- 强制合并
- 获取别名
- 获取组件模板
- 获取字段映射
- 获取索引
- 获取索引设置
- 获取索引模板
- 获取索引模板(旧版)
- 获取映射
- 导入悬挂索引
- 索引恢复
- 索引段
- 索引分片存储
- 索引统计信息
- 索引模板是否存在(旧版)
- 列出悬挂索引
- 打开索引
- 刷新
- 解析索引
- 解析集群
- 翻转
- 收缩索引
- 模拟索引
- 模拟模板
- 拆分索引
- 解冻索引
- 更新索引设置
- 更新映射
- 索引生命周期管理 API
- 推理 API
- 信息 API
- 摄取 API
- 许可 API
- Logstash API
- 机器学习 API
- 机器学习异常检测 API
- 机器学习数据帧分析 API
- 机器学习训练模型 API
- 迁移 API
- 节点生命周期 API
- 查询规则 API
- 重新加载搜索分析器 API
- 存储库计量 API
- 汇总 API
- 根 API
- 脚本 API
- 搜索 API
- 搜索应用程序 API
- 可搜索快照 API
- 安全 API
- 身份验证
- 更改密码
- 清除缓存
- 清除角色缓存
- 清除权限缓存
- 清除 API 密钥缓存
- 清除服务帐户令牌缓存
- 创建 API 密钥
- 创建或更新应用程序权限
- 创建或更新角色映射
- 创建或更新角色
- 批量创建或更新角色 API
- 批量删除角色 API
- 创建或更新用户
- 创建服务帐户令牌
- 委托 PKI 身份验证
- 删除应用程序权限
- 删除角色映射
- 删除角色
- 删除服务帐户令牌
- 删除用户
- 禁用用户
- 启用用户
- 注册 Kibana
- 注册节点
- 获取 API 密钥信息
- 获取应用程序权限
- 获取内置权限
- 获取角色映射
- 获取角色
- 查询角色
- 获取服务帐户
- 获取服务帐户凭据
- 获取安全设置
- 获取令牌
- 获取用户权限
- 获取用户
- 授予 API 密钥
- 具有权限
- 使 API 密钥失效
- 使令牌失效
- OpenID Connect 准备身份验证
- OpenID Connect 身份验证
- OpenID Connect 注销
- 查询 API 密钥信息
- 查询用户
- 更新 API 密钥
- 更新安全设置
- 批量更新 API 密钥
- SAML 准备身份验证
- SAML 身份验证
- SAML 注销
- SAML 失效
- SAML 完成注销
- SAML 服务提供商元数据
- SSL 证书
- 激活用户配置文件
- 禁用用户配置文件
- 启用用户配置文件
- 获取用户配置文件
- 建议用户配置文件
- 更新用户配置文件数据
- 具有用户配置文件权限
- 创建跨集群 API 密钥
- 更新跨集群 API 密钥
- 快照和还原 API
- 快照生命周期管理 API
- SQL API
- 同义词 API
- 文本结构 API
- 转换 API
- 使用情况 API
- Watcher API
- 定义
- 迁移指南
- 发行说明
- Elasticsearch 版本 8.17.0
- Elasticsearch 版本 8.16.1
- Elasticsearch 版本 8.16.0
- Elasticsearch 版本 8.15.5
- Elasticsearch 版本 8.15.4
- Elasticsearch 版本 8.15.3
- Elasticsearch 版本 8.15.2
- Elasticsearch 版本 8.15.1
- Elasticsearch 版本 8.15.0
- Elasticsearch 版本 8.14.3
- Elasticsearch 版本 8.14.2
- Elasticsearch 版本 8.14.1
- Elasticsearch 版本 8.14.0
- Elasticsearch 版本 8.13.4
- Elasticsearch 版本 8.13.3
- Elasticsearch 版本 8.13.2
- Elasticsearch 版本 8.13.1
- Elasticsearch 版本 8.13.0
- Elasticsearch 版本 8.12.2
- Elasticsearch 版本 8.12.1
- Elasticsearch 版本 8.12.0
- Elasticsearch 版本 8.11.4
- Elasticsearch 版本 8.11.3
- Elasticsearch 版本 8.11.2
- Elasticsearch 版本 8.11.1
- Elasticsearch 版本 8.11.0
- Elasticsearch 版本 8.10.4
- Elasticsearch 版本 8.10.3
- Elasticsearch 版本 8.10.2
- Elasticsearch 版本 8.10.1
- Elasticsearch 版本 8.10.0
- Elasticsearch 版本 8.9.2
- Elasticsearch 版本 8.9.1
- Elasticsearch 版本 8.9.0
- Elasticsearch 版本 8.8.2
- Elasticsearch 版本 8.8.1
- Elasticsearch 版本 8.8.0
- Elasticsearch 版本 8.7.1
- Elasticsearch 版本 8.7.0
- Elasticsearch 版本 8.6.2
- Elasticsearch 版本 8.6.1
- Elasticsearch 版本 8.6.0
- Elasticsearch 版本 8.5.3
- Elasticsearch 版本 8.5.2
- Elasticsearch 版本 8.5.1
- Elasticsearch 版本 8.5.0
- Elasticsearch 版本 8.4.3
- Elasticsearch 版本 8.4.2
- Elasticsearch 版本 8.4.1
- Elasticsearch 版本 8.4.0
- Elasticsearch 版本 8.3.3
- Elasticsearch 版本 8.3.2
- Elasticsearch 版本 8.3.1
- Elasticsearch 版本 8.3.0
- Elasticsearch 版本 8.2.3
- Elasticsearch 版本 8.2.2
- Elasticsearch 版本 8.2.1
- Elasticsearch 版本 8.2.0
- Elasticsearch 版本 8.1.3
- Elasticsearch 版本 8.1.2
- Elasticsearch 版本 8.1.1
- Elasticsearch 版本 8.1.0
- Elasticsearch 版本 8.0.1
- Elasticsearch 版本 8.0.0
- Elasticsearch 版本 8.0.0-rc2
- Elasticsearch 版本 8.0.0-rc1
- Elasticsearch 版本 8.0.0-beta1
- Elasticsearch 版本 8.0.0-alpha2
- Elasticsearch 版本 8.0.0-alpha1
- 依赖项和版本
函数分数查询
编辑函数分数查询
编辑function_score 允许您修改查询检索到的文档的分数。例如,如果某个评分函数计算量很大,并且仅在已过滤的文档集上计算分数就足够了,则这会很有用。
要使用 function_score,用户必须定义一个查询和一个或多个函数,这些函数将为查询返回的每个文档计算新的分数。
function_score 可以像这样仅使用一个函数:
resp = client.search( query={ "function_score": { "query": { "match_all": {} }, "boost": "5", "random_score": {}, "boost_mode": "multiply" } }, ) print(resp)
response = client.search( body: { query: { function_score: { query: { match_all: {} }, boost: '5', random_score: {}, boost_mode: 'multiply' } } } ) puts response
res, err := es.Search( es.Search.WithBody(strings.NewReader(`{ "query": { "function_score": { "query": { "match_all": {} }, "boost": "5", "random_score": {}, "boost_mode": "multiply" } } }`)), es.Search.WithPretty(), ) fmt.Println(res, err)
const response = await client.search({ query: { function_score: { query: { match_all: {}, }, boost: "5", random_score: {}, boost_mode: "multiply", }, }, }); console.log(response);
GET /_search { "query": { "function_score": { "query": { "match_all": {} }, "boost": "5", "random_score": {}, "boost_mode": "multiply" } } }
|
有关支持的函数列表,请参阅 函数分数。 |
此外,可以组合多个函数。在这种情况下,可以选择仅在文档与给定的过滤查询匹配时才应用该函数。
resp = client.search( query={ "function_score": { "query": { "match_all": {} }, "boost": "5", "functions": [ { "filter": { "match": { "test": "bar" } }, "random_score": {}, "weight": 23 }, { "filter": { "match": { "test": "cat" } }, "weight": 42 } ], "max_boost": 42, "score_mode": "max", "boost_mode": "multiply", "min_score": 42 } }, ) print(resp)
response = client.search( body: { query: { function_score: { query: { match_all: {} }, boost: '5', functions: [ { filter: { match: { test: 'bar' } }, random_score: {}, weight: 23 }, { filter: { match: { test: 'cat' } }, weight: 42 } ], max_boost: 42, score_mode: 'max', boost_mode: 'multiply', min_score: 42 } } } ) puts response
res, err := es.Search( es.Search.WithBody(strings.NewReader(`{ "query": { "function_score": { "query": { "match_all": {} }, "boost": "5", "functions": [ { "filter": { "match": { "test": "bar" } }, "random_score": {}, "weight": 23 }, { "filter": { "match": { "test": "cat" } }, "weight": 42 } ], "max_boost": 42, "score_mode": "max", "boost_mode": "multiply", "min_score": 42 } } }`)), es.Search.WithPretty(), ) fmt.Println(res, err)
const response = await client.search({ query: { function_score: { query: { match_all: {}, }, boost: "5", functions: [ { filter: { match: { test: "bar", }, }, random_score: {}, weight: 23, }, { filter: { match: { test: "cat", }, }, weight: 42, }, ], max_boost: 42, score_mode: "max", boost_mode: "multiply", min_score: 42, }, }, }); console.log(response);
GET /_search { "query": { "function_score": { "query": { "match_all": {} }, "boost": "5", "functions": [ { "filter": { "match": { "test": "bar" } }, "random_score": {}, "weight": 23 }, { "filter": { "match": { "test": "cat" } }, "weight": 42 } ], "max_boost": 42, "score_mode": "max", "boost_mode": "multiply", "min_score": 42 } } }
|
整个查询的提升。 |
|
|
有关支持的函数列表,请参阅 函数分数。 |
每个函数的过滤查询产生的分数无关紧要。
如果某个函数没有给定过滤器,则等效于指定 "match_all": {}。
首先,每个文档都由定义的函数进行评分。参数 score_mode 指定如何组合计算的分数。
|
|
分数相乘(默认) |
|
|
分数相加 |
|
|
分数求平均值 |
|
|
应用具有匹配过滤器的第一个函数 |
|
|
使用最大分数 |
|
|
使用最小分数 |
由于分数可能具有不同的刻度(例如,衰减函数在 0 和 1 之间,但 field_value_factor 是任意的),并且有时需要函数对分数产生不同的影响,因此可以使用用户定义的 weight 来调整每个函数的分数。weight 可以在 functions 数组中为每个函数定义(如上例所示),并与相应函数计算的分数相乘。如果在没有任何其他函数声明的情况下给出 weight,则 weight 会充当一个简单返回 weight 的函数。
如果将 score_mode 设置为 avg,则各个分数将通过加权平均值进行组合。例如,如果两个函数返回的分数为 1 和 2,并且它们的权重分别为 3 和 4,则它们的分数将组合为 (1*3+2*4)/(3+4),而不是 (1*3+2*4)/2。
可以通过设置 max_boost 参数来限制新分数不超过某个限制。max_boost 的默认值为 FLT_MAX。
新计算的分数将与查询的分数组合。参数 boost_mode 定义了如何组合:
|
|
查询分数和函数分数相乘(默认) |
|
|
仅使用函数分数,忽略查询分数 |
|
|
查询分数和函数分数相加 |
|
|
average |
|
|
查询分数和函数分数中的最大值 |
|
|
查询分数和函数分数中的最小值 |
默认情况下,修改分数不会更改哪些文档匹配。要排除不满足特定分数阈值的文档,可以将 min_score 参数设置为所需的分数阈值。
要使 min_score 生效,需要对查询返回的所有文档进行评分,然后逐个过滤掉。
function_score 查询提供了多种类型的评分函数。
-
script_score -
weight -
random_score -
field_value_factor -
衰减函数:
gauss、linear、exp
脚本分数
编辑script_score 函数允许您封装另一个查询,并可选择使用从文档中的其他数值字段值导出的计算(使用脚本表达式)来自定义其评分。这是一个简单的示例:
resp = client.search( query={ "function_score": { "query": { "match": { "message": "elasticsearch" } }, "script_score": { "script": { "source": "Math.log(2 + doc['my-int'].value)" } } } }, ) print(resp)
response = client.search( body: { query: { function_score: { query: { match: { message: 'elasticsearch' } }, script_score: { script: { source: "Math.log(2 + doc['my-int'].value)" } } } } } ) puts response
const response = await client.search({ query: { function_score: { query: { match: { message: "elasticsearch", }, }, script_score: { script: { source: "Math.log(2 + doc['my-int'].value)", }, }, }, }, }); console.log(response);
GET /_search { "query": { "function_score": { "query": { "match": { "message": "elasticsearch" } }, "script_score": { "script": { "source": "Math.log(2 + doc['my-int'].value)" } } } } }
在 Elasticsearch 中,所有文档分数都是正 32 位浮点数。
如果 script_score 函数产生的分数具有更高的精度,则会将其转换为最接近的 32 位浮点数。
同样,分数必须为非负数。否则,Elasticsearch 将返回错误。
除了不同的脚本字段值和表达式外,_score 脚本参数可用于检索基于封装查询的分数。
脚本编译会被缓存以加快执行速度。如果脚本具有需要考虑的参数,则最好重用同一脚本并为其提供参数:
resp = client.search( query={ "function_score": { "query": { "match": { "message": "elasticsearch" } }, "script_score": { "script": { "params": { "a": 5, "b": 1.2 }, "source": "params.a / Math.pow(params.b, doc['my-int'].value)" } } } }, ) print(resp)
response = client.search( body: { query: { function_score: { query: { match: { message: 'elasticsearch' } }, script_score: { script: { params: { a: 5, b: 1.2 }, source: "params.a / Math.pow(params.b, doc['my-int'].value)" } } } } } ) puts response
const response = await client.search({ query: { function_score: { query: { match: { message: "elasticsearch", }, }, script_score: { script: { params: { a: 5, b: 1.2, }, source: "params.a / Math.pow(params.b, doc['my-int'].value)", }, }, }, }, }); console.log(response);
GET /_search { "query": { "function_score": { "query": { "match": { "message": "elasticsearch" } }, "script_score": { "script": { "params": { "a": 5, "b": 1.2 }, "source": "params.a / Math.pow(params.b, doc['my-int'].value)" } } } } }
请注意,与 custom_score 查询不同,查询的分数会与脚本评分的结果相乘。如果您希望禁止此操作,请设置 "boost_mode": "replace"。
权重
编辑weight 分数允许您将分数乘以提供的 weight。有时可能需要这样做,因为在特定查询上设置的提升值会被规范化,而对于此评分函数则不会。数字值的类型为 float。
"weight" : number
随机
编辑random_score 生成的分数均匀分布在 0 到 1 之间(不包括 1)。默认情况下,它使用内部 Lucene 文档 ID 作为随机性来源,这非常高效,但不幸的是,由于文档可能会被合并重新编号,因此无法重现。
如果您希望分数是可重现的,则可以提供 seed 和 field。然后,将根据此种子、所考虑文档的 field 的最小值和一个基于索引名称和分片 ID 计算的盐值来计算最终分数,以便具有相同值但存储在不同索引中的文档获得不同的分数。请注意,同一分片内且 field 的值相同的文档仍将获得相同的分数,因此通常最好使用对所有文档都具有唯一值的字段。一个很好的默认选择可能是使用 _seq_no 字段,其唯一的缺点是如果文档更新,分数也会更改,因为更新操作也会更新 _seq_no 字段的值。
可以在不设置字段的情况下设置种子,但这已被弃用,因为这需要在 _id 字段上加载 fielddata,这会消耗大量内存。
resp = client.search( query={ "function_score": { "random_score": { "seed": 10, "field": "_seq_no" } } }, ) print(resp)
response = client.search( body: { query: { function_score: { random_score: { seed: 10, field: '_seq_no' } } } } ) puts response
res, err := es.Search( es.Search.WithBody(strings.NewReader(`{ "query": { "function_score": { "random_score": { "seed": 10, "field": "_seq_no" } } } }`)), es.Search.WithPretty(), ) fmt.Println(res, err)
const response = await client.search({ query: { function_score: { random_score: { seed: 10, field: "_seq_no", }, }, }, }); console.log(response);
GET /_search { "query": { "function_score": { "random_score": { "seed": 10, "field": "_seq_no" } } } }
字段值因子
编辑field_value_factor 函数允许您使用文档中的字段来影响分数。它类似于使用 script_score 函数,但是它避免了脚本开销。如果对多值字段使用,则仅在计算中使用该字段的第一个值。
例如,假设您有一个使用数值 my-int 字段索引的文档,并且希望使用此字段影响文档的分数,一个这样做的示例如下所示:
resp = client.search( query={ "function_score": { "field_value_factor": { "field": "my-int", "factor": 1.2, "modifier": "sqrt", "missing": 1 } } }, ) print(resp)
response = client.search( body: { query: { function_score: { field_value_factor: { field: 'my-int', factor: 1.2, modifier: 'sqrt', missing: 1 } } } } ) puts response
const response = await client.search({ query: { function_score: { field_value_factor: { field: "my-int", factor: 1.2, modifier: "sqrt", missing: 1, }, }, }, }); console.log(response);
GET /_search { "query": { "function_score": { "field_value_factor": { "field": "my-int", "factor": 1.2, "modifier": "sqrt", "missing": 1 } } } }
这将转换为以下评分公式:
sqrt(1.2 * doc['my-int'].value)
field_value_factor 函数有许多选项:
|
|
要从文档中提取的字段。 |
|
|
可选因子,用于与字段值相乘,默认为 |
|
|
要应用于字段值的修饰符,可以是以下之一: |
| 修饰符 | 含义 |
|---|---|
|
不对字段值应用任何乘数 |
|
取字段值的常用对数。由于此函数将返回负值,并且如果对 0 到 1 之间的值使用将导致错误,因此建议改用 |
|
将 1 添加到字段值并取常用对数 |
|
将 2 添加到字段值并取常用对数 |
|
取字段值的自然对数。由于此函数将返回负值,并且如果对 0 到 1 之间的值使用将导致错误,因此建议改用 |
|
将 1 添加到字段值并取自然对数 |
|
将 2 添加到字段值并取自然对数 |
|
将字段值平方(将其自身相乘) |
|
取字段值的平方根 |
|
求倒数 字段值,与 |
-
missing - 如果文档没有该字段,则使用该值。修饰符和因子仍然像从文档中读取一样应用于它。
field_value_score 函数产生的分数必须为非负数,否则将引发错误。log 和 ln 修饰符如果对 0 到 1 之间的值使用,则会产生负值。请务必使用范围过滤器限制字段的值以避免这种情况,或使用 log1p 和 ln1p。
请记住,对 0 取 log() 或对负数开平方根是一种非法操作,将引发异常。请务必使用范围过滤器限制字段的值以避免这种情况,或使用 log1p 和 ln1p。
衰减函数
编辑衰减函数使用一个函数对文档进行评分,该函数根据文档的数值字段值与用户给定的原点之间的距离进行衰减。这类似于范围查询,但具有平滑的边缘而不是硬边界。
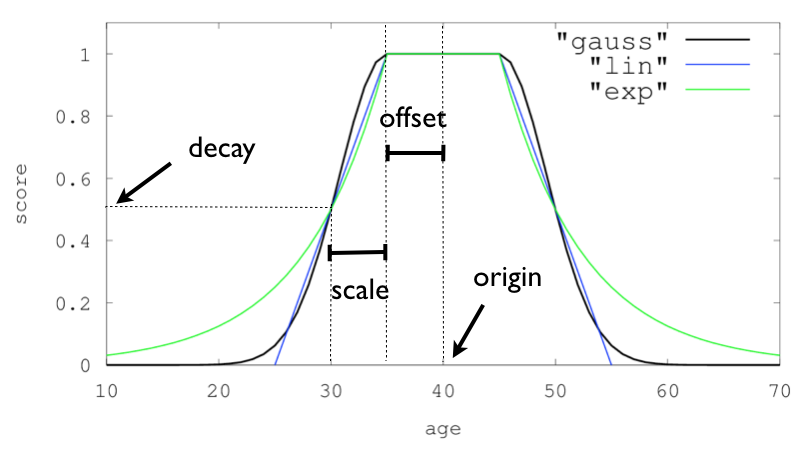
要在具有数值字段的查询中使用距离评分,用户必须为每个字段定义一个 origin(原点)和一个 scale(比例)。origin 用于定义计算距离的“中心点”,而 scale 用于定义衰减率。衰减函数指定为
"DECAY_FUNCTION": { "FIELD_NAME": { "origin": "11, 12", "scale": "2km", "offset": "0km", "decay": 0.33 } }
在上面的示例中,该字段是一个 geo_point(地理点),并且可以以地理格式提供原点。scale 和 offset(偏移量)在这种情况下必须给出单位。如果您的字段是日期字段,则可以将 scale 和 offset 设置为天、周等。示例
resp = client.search( query={ "function_score": { "gauss": { "@timestamp": { "origin": "2013-09-17", "scale": "10d", "offset": "5d", "decay": 0.5 } } } }, ) print(resp)
response = client.search( body: { query: { function_score: { gauss: { "@timestamp": { origin: '2013-09-17', scale: '10d', offset: '5d', decay: 0.5 } } } } } ) puts response
const response = await client.search({ query: { function_score: { gauss: { "@timestamp": { origin: "2013-09-17", scale: "10d", offset: "5d", decay: 0.5, }, }, }, }, }); console.log(response);
GET /_search { "query": { "function_score": { "gauss": { "@timestamp": { "origin": "2013-09-17", "scale": "10d", "offset": "5d", "decay": 0.5 } } } } }
|
原点的日期格式取决于您的映射中定义的 |
|
|
|
|
|
用于计算距离的原点。对于数值字段,必须作为数字给出;对于日期字段,必须作为日期给出;对于地理字段,必须作为地理点给出。地理和数值字段是必需的。对于日期字段,默认值为 |
|
|
所有类型都必需。定义计算出的分数将等于 |
|
|
如果定义了 |
|
|
|
在第一个示例中,您的文档可能代表酒店,并包含一个地理位置字段。您想根据酒店与给定位置的距离计算衰减函数。您可能不会立即看到为高斯函数选择什么比例,但是您可以说:“在距离所需位置 2 公里的距离处,分数应降低到三分之一。” 然后将自动调整参数“scale”,以确保得分函数为距离所需位置 2 公里的酒店计算得分 0.33。
在第二个示例中,字段值在 2013-09-12 和 2013-09-22 之间的文档将获得权重 1.0,而距离该日期 15 天的文档将获得权重 0.5。
支持的衰减函数
编辑DECAY_FUNCTION 确定衰减的形状
-
gauss(高斯) -
正态衰减,计算为

其中
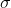 被计算以确保得分在距离
被计算以确保得分在距离 origin+-offset的scale处的值为decay。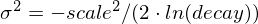
请参阅 正态衰减,关键字
gauss,其中包含演示gauss函数生成的曲线的图表。 -
exp(指数) -
指数衰减,计算为
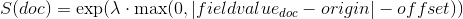
再次,参数
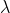 被计算以确保得分在距离
被计算以确保得分在距离 origin+-offset的scale处的值为decay。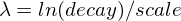
请参阅 指数衰减,关键字
exp,其中包含演示exp函数生成的曲线的图表。 -
linear(线性) -
线性衰减,计算为
 .
.再次,参数
s被计算以确保得分在距离origin+-offset的scale处的值为decay。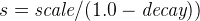
与正态衰减和指数衰减相比,此函数实际上会在字段值超过用户给定的比例值的两倍时将分数设置为 0。
对于单个函数,三个衰减函数及其参数可以这样可视化(此示例中的字段称为“age”)
多值字段
编辑如果用于计算衰减的字段包含多个值,则默认情况下,选择最接近原点的值来确定距离。可以通过设置 multi_value_mode 来更改此设置。
|
|
距离是最小距离 |
|
|
距离是最大距离 |
|
|
距离是平均距离 |
|
|
距离是所有距离的总和 |
示例
"DECAY_FUNCTION": { "FIELD_NAME": { "origin": ..., "scale": ... }, "multi_value_mode": "avg" }
详细示例
编辑假设您正在某个城镇寻找酒店。您的预算有限。此外,您希望酒店靠近市中心,因此酒店距离所需位置越远,您入住的可能性就越小。
您希望根据到市中心的距离以及价格对符合您条件的查询结果(例如,“酒店,南希,不吸烟”)进行评分。
直观上,您想将市中心定义为原点,也许您愿意从酒店步行 2 公里到市中心。
在这种情况下,位置字段的 原点 是市中心,比例 是 ~2 公里。
如果您的预算较低,您可能会更喜欢便宜的而不是贵的。对于价格字段,原点 将是 0 欧元,而 比例 取决于您愿意支付多少钱,例如 20 欧元。
在此示例中,这些字段可能称为酒店价格的“price”和酒店坐标的“location”。
在这种情况下,price 的函数将是
对于 location
假设您想将这两个函数乘以原始分数,则请求将如下所示
resp = client.search( query={ "function_score": { "functions": [ { "gauss": { "price": { "origin": "0", "scale": "20" } } }, { "gauss": { "location": { "origin": "11, 12", "scale": "2km" } } } ], "query": { "match": { "properties": "balcony" } }, "score_mode": "multiply" } }, ) print(resp)
response = client.search( body: { query: { function_score: { functions: [ { gauss: { price: { origin: '0', scale: '20' } } }, { gauss: { location: { origin: '11, 12', scale: '2km' } } } ], query: { match: { properties: 'balcony' } }, score_mode: 'multiply' } } } ) puts response
res, err := es.Search( es.Search.WithBody(strings.NewReader(`{ "query": { "function_score": { "functions": [ { "gauss": { "price": { "origin": "0", "scale": "20" } } }, { "gauss": { "location": { "origin": "11, 12", "scale": "2km" } } } ], "query": { "match": { "properties": "balcony" } }, "score_mode": "multiply" } } }`)), es.Search.WithPretty(), ) fmt.Println(res, err)
const response = await client.search({ query: { function_score: { functions: [ { gauss: { price: { origin: "0", scale: "20", }, }, }, { gauss: { location: { origin: "11, 12", scale: "2km", }, }, }, ], query: { match: { properties: "balcony", }, }, score_mode: "multiply", }, }, }); console.log(response);
GET /_search { "query": { "function_score": { "functions": [ { "gauss": { "price": { "origin": "0", "scale": "20" } } }, { "gauss": { "location": { "origin": "11, 12", "scale": "2km" } } } ], "query": { "match": { "properties": "balcony" } }, "score_mode": "multiply" } } }
接下来,我们将展示三种可能的衰减函数中每种函数的计算得分如何。
正态衰减,关键字 gauss
编辑在上面的示例中选择 gauss 作为衰减函数时,乘数的轮廓图和表面图如下所示


假设您的原始搜索结果匹配了三家酒店
- “背包客旅馆”
- “酒驾旅馆”
- “贝尔维尤住宿加早餐酒店”。
“酒驾旅馆”离您定义的位置很远(将近 2 公里),而且不是很便宜(大约 13 欧元),因此它的系数较低,为 0.56。“贝尔维尤住宿加早餐酒店”和“背包客旅馆”都非常靠近定义的位置,但是“贝尔维尤住宿加早餐酒店”更便宜,因此它的乘数为 0.86,而“背包客旅馆”的值为 0.66。




衰减函数支持的字段
编辑仅支持数值型、日期型和地理点型字段。
如果缺少字段怎么办?
编辑如果文档中缺少数值字段,则该函数将返回 1。
On this page