对时间序列数据流进行降采样
编辑对时间序列数据流进行降采样
编辑降采样提供了一种方法,通过以降低的粒度存储您的时间序列数据来减少其占用空间。
指标解决方案会收集大量随时间增长的时间序列数据。随着这些数据的老化,它与系统的当前状态的相关性降低。降采样过程将固定时间间隔内的文档汇总到单个摘要文档中。每个摘要文档都包含原始数据的统计表示:每个指标的 min、max、sum 和 value_count。数据流 时间序列维度保持不变。
实际上,降采样允许您以数据分辨率和精度为代价来换取存储空间。您可以将其包含在 索引生命周期管理 (ILM) 策略中,以便在其老化时自动管理指标数据的量和相关成本。
查看以下部分以了解更多信息
工作原理
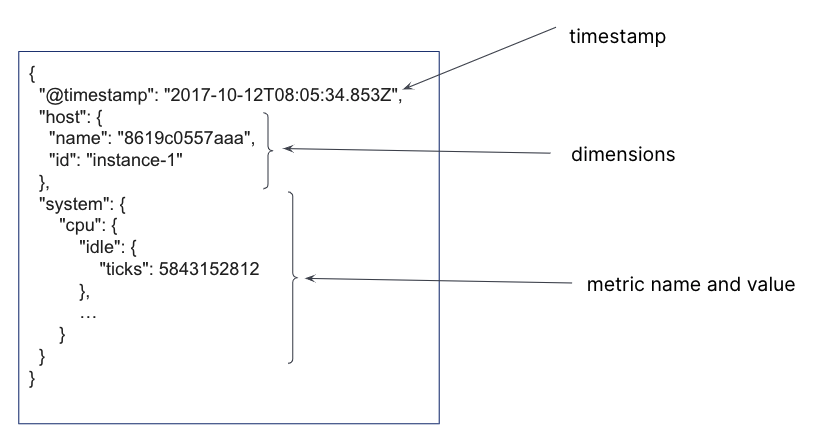
编辑时间序列是针对特定实体随时间推移进行的一系列观测。观测到的样本可以表示为连续函数,其中时间序列维度保持不变,而时间序列指标随时间变化。
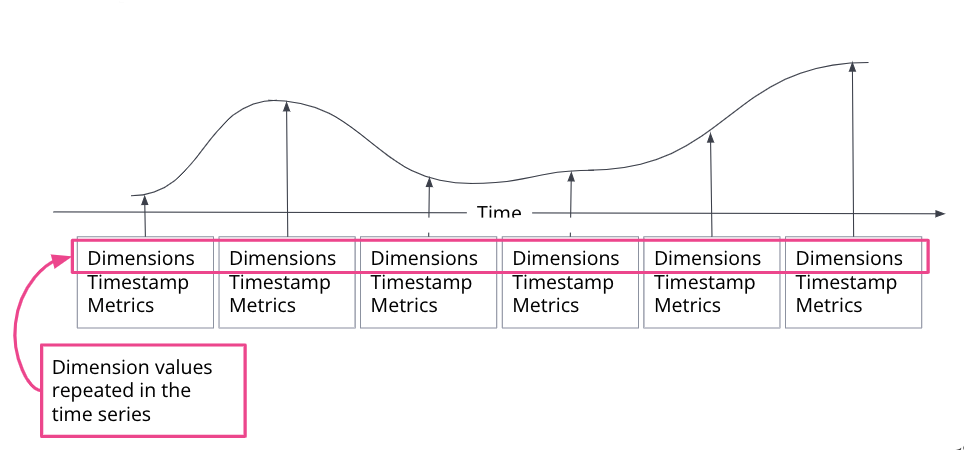
在 Elasticsearch 索引中,每个时间戳都会创建一个单独的文档,其中包含不可变的时间序列维度,以及指标名称和变化的指标值。对于单个时间戳,可以存储多个时间序列维度和指标。
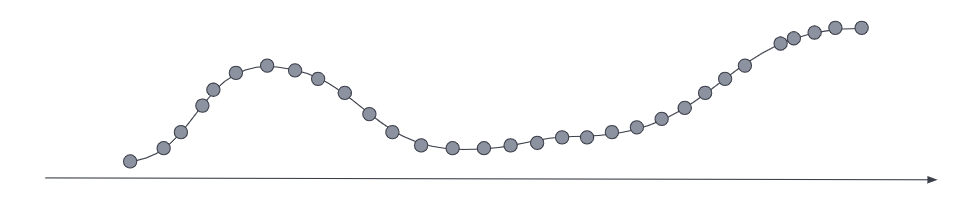
对于您最新和最相关的数据,指标序列通常具有较低的采样时间间隔,因此它针对需要高数据分辨率的查询进行了优化。
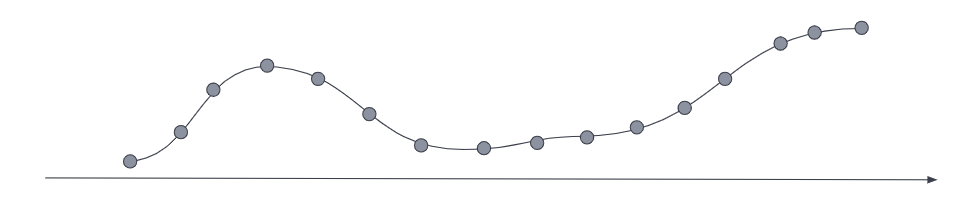
降采样通过将原始时间序列替换为更高采样间隔的数据流以及该数据的统计表示,来处理较旧、访问频率较低的数据。例如,原始指标样本可能是每十秒钟采集一次,随着数据的老化,您可以选择将采样粒度降低到每小时或每天。您可以选择将 cold 归档数据的粒度降低到每月甚至更低。
对时间序列数据运行降采样
编辑要对时间序列索引进行降采样,请使用 降采样 API 并将 fixed_interval 设置为您所需的粒度级别。
resp = client.indices.downsample(
index="my-time-series-index",
target_index="my-downsampled-time-series-index",
config={
"fixed_interval": "1d"
},
)
print(resp)
response = client.indices.downsample(
index: 'my-time-series-index',
target_index: 'my-downsampled-time-series-index',
body: {
fixed_interval: '1d'
}
)
puts response
const response = await client.indices.downsample({
index: "my-time-series-index",
target_index: "my-downsampled-time-series-index",
config: {
fixed_interval: "1d",
},
});
console.log(response);
POST /my-time-series-index/_downsample/my-downsampled-time-series-index
{
"fixed_interval": "1d"
}
要将时间序列数据作为 ILM 的一部分进行降采样,请在您的 ILM 策略中包含 降采样操作,并将 fixed_interval 设置为您所需的粒度级别。
resp = client.ilm.put_lifecycle(
name="my_policy",
policy={
"phases": {
"warm": {
"actions": {
"downsample": {
"fixed_interval": "1h"
}
}
}
}
},
)
print(resp)
response = client.ilm.put_lifecycle(
policy: 'my_policy',
body: {
policy: {
phases: {
warm: {
actions: {
downsample: {
fixed_interval: '1h'
}
}
}
}
}
}
)
puts response
const response = await client.ilm.putLifecycle({
name: "my_policy",
policy: {
phases: {
warm: {
actions: {
downsample: {
fixed_interval: "1h",
},
},
},
},
},
});
console.log(response);
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"warm": {
"actions": {
"downsample" : {
"fixed_interval": "1h"
}
}
}
}
}
}
查询降采样索引
编辑您可以使用 _search 和 _async_search 端点来查询降采样索引。可以在单个请求中查询多个原始数据和降采样索引,并且单个请求可以包含具有不同粒度(不同的存储桶时间跨度)的降采样索引。也就是说,您可以查询包含具有多个降采样间隔(例如,15m、1h、1d)的降采样索引的数据流。
基于时间的直方图聚合的结果在统一的存储桶大小中,并且每个降采样索引都返回数据,而忽略降采样时间间隔。例如,如果在以每小时分辨率("fixed_interval": "1h")进行降采样的降采样索引上运行 date_histogram 聚合并使用 "fixed_interval": "1m",则查询会返回一个存储桶,其中包含所有分钟 0 的数据,然后是 59 个空存储桶,然后在下一小时再次返回一个带有数据的存储桶。
有关降采样查询的注意事项
编辑关于查询降采样索引,有几点需要注意
- 当您在 Kibana 中并通过 Elastic 解决方案运行查询时,会返回正常响应,而不会通知您某些查询的索引已降采样。
- 对于 日期直方图聚合,仅支持
fixed_intervals(而不是日历感知间隔)。 -
时区支持存在一些注意事项
- 小时倍数的间隔的日期直方图基于 UTC 生成的值。这对于小时的时区(例如,+5:00 或 -3:00)效果很好,但需要偏移报告的时间存储桶,例如,对于时区 +5:30(印度),如果降采样按小时聚合值,则使用
2020-01-01T10:30:00.000而不是2020-03-07T10:00:00.000。在这种情况下,结果包括字段downsampled_results_offset: true,以指示时间存储桶已移动。如果使用 15 分钟的降采样间隔,则可以避免这种情况,因为它允许正确计算移动存储桶的每小时值。 - 如果降采样按天聚合值,则天数倍数的间隔的日期直方图也会受到类似的影响。在这种情况下,每天的开始始终在生成降采样值时以 UTC 计算,因此需要移动时间存储桶,例如,对于时区
America/New_York,报告为2020-03-07T19:00:00.000而不是2020-03-07T00:00:00.000。在这种情况下也会添加字段downsampled_results_offset: true。 - 夏令时和时区周围类似的特殊性会影响报告的结果,如文档中有关日期直方图聚合的记录所述。此外,按天间隔进行降采样会阻碍跟踪与夏令时更改相关的任何信息。
- 小时倍数的间隔的日期直方图基于 UTC 生成的值。这对于小时的时区(例如,+5:00 或 -3:00)效果很好,但需要偏移报告的时间存储桶,例如,对于时区 +5:30(印度),如果降采样按小时聚合值,则使用
限制和约束
编辑以下限制和约束适用于降采样
- 仅支持 时间序列数据流中的索引。
- 数据仅基于时间维度进行降采样。所有其他维度都复制到新索引,而无需进行任何修改。
- 在数据流中,降采样索引会替换原始索引,并且原始索引会被删除。对于给定的时间段,只能存在一个索引。
- 源索引必须处于只读模式,降采样过程才能成功。有关详细信息,请查看手动运行降采样示例。
- 支持多次降采样同一时间段的数据(对降采样索引进行降采样)。降采样间隔必须是降采样索引的间隔的倍数。
- 降采样作为 ILM 操作提供。请参阅降采样。
- 新的降采样索引是在原始索引的数据层上创建的,它会继承其设置(例如,分片和副本的数量)。
- 支持数值
gauge和counter指标类型。 - 降采样配置是从时间序列数据流索引映射中提取的。唯一需要的额外设置是降采样
fixed_interval。
试用
编辑要试用降采样,请尝试我们手动运行降采样的示例。
可以轻松地将降采样添加到您的 ILM 策略中。要了解如何操作,请尝试我们的使用 ILM 运行降采样示例。