转换示例
编辑转换示例
编辑这些示例演示了如何使用转换从您的数据中获得有用的见解。所有示例都使用Kibana 示例数据集之一。有关更详细的逐步示例,请参阅教程:转换电子商务示例数据。
查找您的最佳客户
编辑此示例使用电子商务订单示例数据集来查找在假设的网上商店中花费最多的客户。让我们使用 pivot 类型的转换,使目标索引包含每个客户的订单数量、订单总价、唯一产品数量、每个订单的平均价格以及订购产品的总数量。
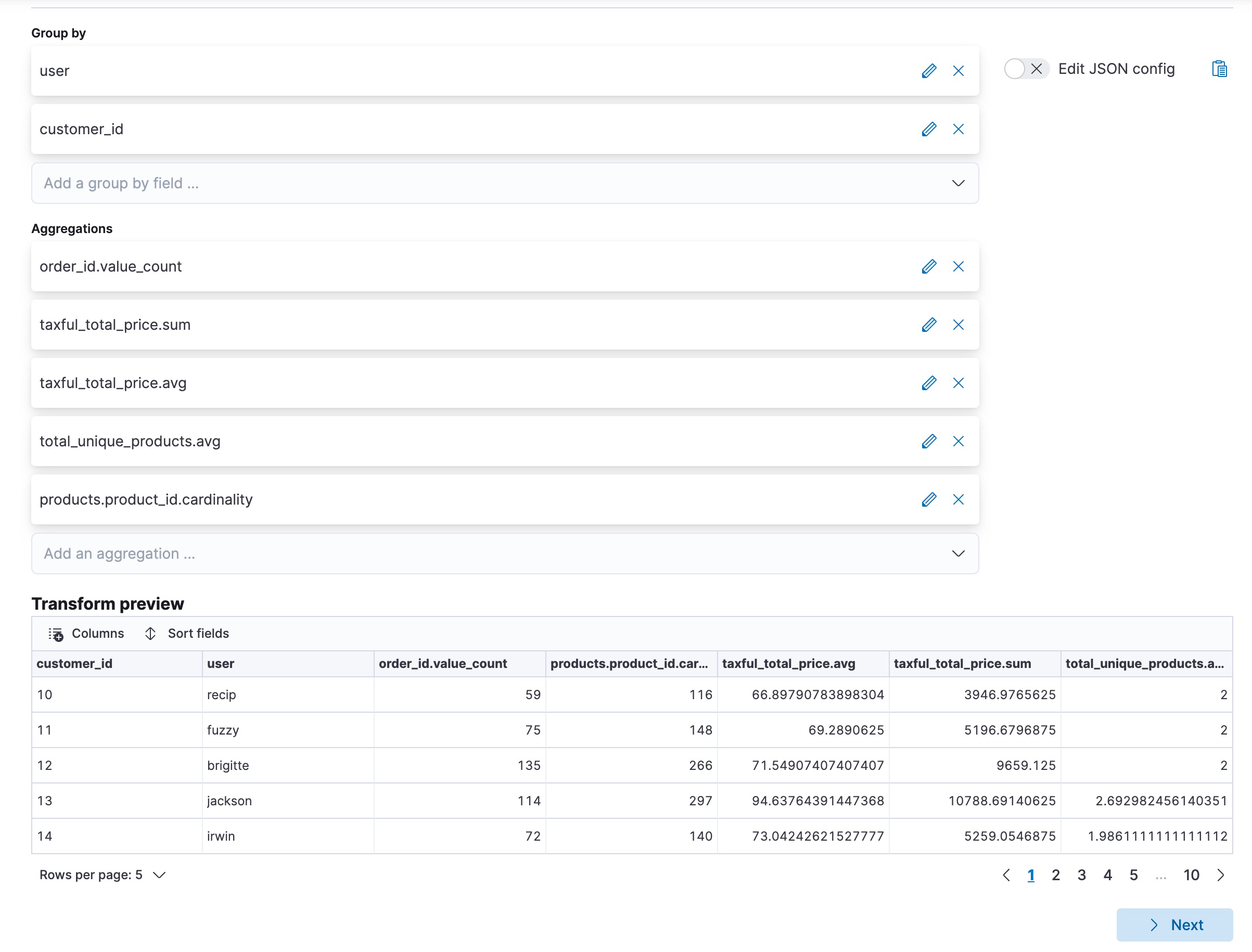
API 示例
resp = client.transform.preview_transform(
source={
"index": "kibana_sample_data_ecommerce"
},
dest={
"index": "sample_ecommerce_orders_by_customer"
},
pivot={
"group_by": {
"user": {
"terms": {
"field": "user"
}
},
"customer_id": {
"terms": {
"field": "customer_id"
}
}
},
"aggregations": {
"order_count": {
"value_count": {
"field": "order_id"
}
},
"total_order_amt": {
"sum": {
"field": "taxful_total_price"
}
},
"avg_amt_per_order": {
"avg": {
"field": "taxful_total_price"
}
},
"avg_unique_products_per_order": {
"avg": {
"field": "total_unique_products"
}
},
"total_unique_products": {
"cardinality": {
"field": "products.product_id"
}
}
}
},
)
print(resp)
const response = await client.transform.previewTransform({
source: {
index: "kibana_sample_data_ecommerce",
},
dest: {
index: "sample_ecommerce_orders_by_customer",
},
pivot: {
group_by: {
user: {
terms: {
field: "user",
},
},
customer_id: {
terms: {
field: "customer_id",
},
},
},
aggregations: {
order_count: {
value_count: {
field: "order_id",
},
},
total_order_amt: {
sum: {
field: "taxful_total_price",
},
},
avg_amt_per_order: {
avg: {
field: "taxful_total_price",
},
},
avg_unique_products_per_order: {
avg: {
field: "total_unique_products",
},
},
total_unique_products: {
cardinality: {
field: "products.product_id",
},
},
},
},
});
console.log(response);
POST _transform/_preview
{
"source": {
"index": "kibana_sample_data_ecommerce"
},
"dest" : {
"index" : "sample_ecommerce_orders_by_customer"
},
"pivot": {
"group_by": {
"user": { "terms": { "field": "user" }},
"customer_id": { "terms": { "field": "customer_id" }}
},
"aggregations": {
"order_count": { "value_count": { "field": "order_id" }},
"total_order_amt": { "sum": { "field": "taxful_total_price" }},
"avg_amt_per_order": { "avg": { "field": "taxful_total_price" }},
"avg_unique_products_per_order": { "avg": { "field": "total_unique_products" }},
"total_unique_products": { "cardinality": { "field": "products.product_id" }}
}
}
}
|
转换的目标索引。它被 |
|
|
选择了两个 |
在上面的示例中,使用了精简的 JSON 格式,以便更轻松地读取 pivot 对象。
预览转换 API 使您能够预先查看转换的布局,其中填充了一些示例值。例如
{
"preview" : [
{
"total_order_amt" : 3946.9765625,
"order_count" : 59.0,
"total_unique_products" : 116.0,
"avg_unique_products_per_order" : 2.0,
"customer_id" : "10",
"user" : "recip",
"avg_amt_per_order" : 66.89790783898304
},
...
]
}
此转换使您可以更轻松地回答以下问题,例如
- 哪些客户花费最多?
- 哪些客户每个订单花费最多?
- 哪些客户订购最频繁?
- 哪些客户订购的不同产品数量最少?
可以使用聚合单独回答这些问题,但是转换允许我们将此数据持久化为以客户为中心的索引。这使我们能够大规模地分析数据,并为从以客户为中心的角度探索和浏览数据提供了更大的灵活性。在某些情况下,它甚至可以使创建可视化效果更加简单。
查找延误最多的航空公司
编辑此示例使用 Flights 示例数据集来查找哪个航空公司的延误最多。首先,通过使用查询过滤器过滤源数据,使其排除所有已取消的航班。然后转换数据以包含不同的航班数量、延迟分钟的总和以及每个航空公司的飞行分钟的总和。最后,使用bucket_script来确定实际延误的飞行时间百分比。
resp = client.transform.preview_transform(
source={
"index": "kibana_sample_data_flights",
"query": {
"bool": {
"filter": [
{
"term": {
"Cancelled": False
}
}
]
}
}
},
dest={
"index": "sample_flight_delays_by_carrier"
},
pivot={
"group_by": {
"carrier": {
"terms": {
"field": "Carrier"
}
}
},
"aggregations": {
"flights_count": {
"value_count": {
"field": "FlightNum"
}
},
"delay_mins_total": {
"sum": {
"field": "FlightDelayMin"
}
},
"flight_mins_total": {
"sum": {
"field": "FlightTimeMin"
}
},
"delay_time_percentage": {
"bucket_script": {
"buckets_path": {
"delay_time": "delay_mins_total.value",
"flight_time": "flight_mins_total.value"
},
"script": "(params.delay_time / params.flight_time) * 100"
}
}
}
},
)
print(resp)
const response = await client.transform.previewTransform({
source: {
index: "kibana_sample_data_flights",
query: {
bool: {
filter: [
{
term: {
Cancelled: false,
},
},
],
},
},
},
dest: {
index: "sample_flight_delays_by_carrier",
},
pivot: {
group_by: {
carrier: {
terms: {
field: "Carrier",
},
},
},
aggregations: {
flights_count: {
value_count: {
field: "FlightNum",
},
},
delay_mins_total: {
sum: {
field: "FlightDelayMin",
},
},
flight_mins_total: {
sum: {
field: "FlightTimeMin",
},
},
delay_time_percentage: {
bucket_script: {
buckets_path: {
delay_time: "delay_mins_total.value",
flight_time: "flight_mins_total.value",
},
script: "(params.delay_time / params.flight_time) * 100",
},
},
},
},
});
console.log(response);
POST _transform/_preview
{
"source": {
"index": "kibana_sample_data_flights",
"query": {
"bool": {
"filter": [
{ "term": { "Cancelled": false } }
]
}
}
},
"dest" : {
"index" : "sample_flight_delays_by_carrier"
},
"pivot": {
"group_by": {
"carrier": { "terms": { "field": "Carrier" }}
},
"aggregations": {
"flights_count": { "value_count": { "field": "FlightNum" }},
"delay_mins_total": { "sum": { "field": "FlightDelayMin" }},
"flight_mins_total": { "sum": { "field": "FlightTimeMin" }},
"delay_time_percentage": {
"bucket_script": {
"buckets_path": {
"delay_time": "delay_mins_total.value",
"flight_time": "flight_mins_total.value"
},
"script": "(params.delay_time / params.flight_time) * 100"
}
}
}
}
}
|
过滤源数据以仅选择未取消的航班。 |
|
|
转换的目标索引。它被 |
|
|
数据按包含航空公司名称的 |
|
|
此 |
预览显示新索引将包含每个航空公司的数据,如下所示
{
"preview" : [
{
"carrier" : "ES-Air",
"flights_count" : 2802.0,
"flight_mins_total" : 1436927.5130677223,
"delay_time_percentage" : 9.335543983955839,
"delay_mins_total" : 134145.0
},
...
]
}
此转换使您可以更轻松地回答以下问题,例如
- 哪个航空公司的延误时间占飞行时间的百分比最高?
此数据是虚构的,并不反映任何特色目的地或始发机场的实际延误或航班统计数据。
查找可疑的客户端 IP
编辑此示例使用 Web 日志示例数据集来识别可疑的客户端 IP。它转换数据,使新索引包含每个客户端 IP 的字节总和、不同 URL 的数量、代理、按位置的传入请求以及地理目的地。它还使用过滤器聚合来计算每个客户端 IP 收到的特定类型的 HTTP 响应。最终,以下示例将 Web 日志数据转换为以实体为中心的索引,其中实体为 clientip。
resp = client.transform.put_transform(
transform_id="suspicious_client_ips",
source={
"index": "kibana_sample_data_logs"
},
dest={
"index": "sample_weblogs_by_clientip"
},
sync={
"time": {
"field": "timestamp",
"delay": "60s"
}
},
pivot={
"group_by": {
"clientip": {
"terms": {
"field": "clientip"
}
}
},
"aggregations": {
"url_dc": {
"cardinality": {
"field": "url.keyword"
}
},
"bytes_sum": {
"sum": {
"field": "bytes"
}
},
"geo.src_dc": {
"cardinality": {
"field": "geo.src"
}
},
"agent_dc": {
"cardinality": {
"field": "agent.keyword"
}
},
"geo.dest_dc": {
"cardinality": {
"field": "geo.dest"
}
},
"responses.total": {
"value_count": {
"field": "timestamp"
}
},
"success": {
"filter": {
"term": {
"response": "200"
}
}
},
"error404": {
"filter": {
"term": {
"response": "404"
}
}
},
"error5xx": {
"filter": {
"range": {
"response": {
"gte": 500,
"lt": 600
}
}
}
},
"timestamp.min": {
"min": {
"field": "timestamp"
}
},
"timestamp.max": {
"max": {
"field": "timestamp"
}
},
"timestamp.duration_ms": {
"bucket_script": {
"buckets_path": {
"min_time": "timestamp.min.value",
"max_time": "timestamp.max.value"
},
"script": "(params.max_time - params.min_time)"
}
}
}
},
)
print(resp)
const response = await client.transform.putTransform({
transform_id: "suspicious_client_ips",
source: {
index: "kibana_sample_data_logs",
},
dest: {
index: "sample_weblogs_by_clientip",
},
sync: {
time: {
field: "timestamp",
delay: "60s",
},
},
pivot: {
group_by: {
clientip: {
terms: {
field: "clientip",
},
},
},
aggregations: {
url_dc: {
cardinality: {
field: "url.keyword",
},
},
bytes_sum: {
sum: {
field: "bytes",
},
},
"geo.src_dc": {
cardinality: {
field: "geo.src",
},
},
agent_dc: {
cardinality: {
field: "agent.keyword",
},
},
"geo.dest_dc": {
cardinality: {
field: "geo.dest",
},
},
"responses.total": {
value_count: {
field: "timestamp",
},
},
success: {
filter: {
term: {
response: "200",
},
},
},
error404: {
filter: {
term: {
response: "404",
},
},
},
error5xx: {
filter: {
range: {
response: {
gte: 500,
lt: 600,
},
},
},
},
"timestamp.min": {
min: {
field: "timestamp",
},
},
"timestamp.max": {
max: {
field: "timestamp",
},
},
"timestamp.duration_ms": {
bucket_script: {
buckets_path: {
min_time: "timestamp.min.value",
max_time: "timestamp.max.value",
},
script: "(params.max_time - params.min_time)",
},
},
},
},
});
console.log(response);
PUT _transform/suspicious_client_ips
{
"source": {
"index": "kibana_sample_data_logs"
},
"dest" : {
"index" : "sample_weblogs_by_clientip"
},
"sync" : {
"time": {
"field": "timestamp",
"delay": "60s"
}
},
"pivot": {
"group_by": {
"clientip": { "terms": { "field": "clientip" } }
},
"aggregations": {
"url_dc": { "cardinality": { "field": "url.keyword" }},
"bytes_sum": { "sum": { "field": "bytes" }},
"geo.src_dc": { "cardinality": { "field": "geo.src" }},
"agent_dc": { "cardinality": { "field": "agent.keyword" }},
"geo.dest_dc": { "cardinality": { "field": "geo.dest" }},
"responses.total": { "value_count": { "field": "timestamp" }},
"success" : {
"filter": {
"term": { "response" : "200"}}
},
"error404" : {
"filter": {
"term": { "response" : "404"}}
},
"error5xx" : {
"filter": {
"range": { "response" : { "gte": 500, "lt": 600}}}
},
"timestamp.min": { "min": { "field": "timestamp" }},
"timestamp.max": { "max": { "field": "timestamp" }},
"timestamp.duration_ms": {
"bucket_script": {
"buckets_path": {
"min_time": "timestamp.min.value",
"max_time": "timestamp.max.value"
},
"script": "(params.max_time - params.min_time)"
}
}
}
}
}
|
转换的目标索引。 |
|
|
配置转换以连续运行。它使用 |
|
|
数据按 |
|
|
过滤器聚合,用于计算 |
|
|
此 |
创建转换后,您必须启动它
resp = client.transform.start_transform(
transform_id="suspicious_client_ips",
)
print(resp)
response = client.transform.start_transform( transform_id: 'suspicious_client_ips' ) puts response
const response = await client.transform.startTransform({
transform_id: "suspicious_client_ips",
});
console.log(response);
POST _transform/suspicious_client_ips/_start
此后不久,第一个结果应在目标索引中可用
resp = client.search(
index="sample_weblogs_by_clientip",
)
print(resp)
response = client.search( index: 'sample_weblogs_by_clientip' ) puts response
const response = await client.search({
index: "sample_weblogs_by_clientip",
});
console.log(response);
GET sample_weblogs_by_clientip/_search
搜索结果显示每个客户端 IP 的数据,如下所示
"hits" : [
{
"_index" : "sample_weblogs_by_clientip",
"_id" : "MOeHH_cUL5urmartKj-b5UQAAAAAAAAA",
"_score" : 1.0,
"_source" : {
"geo" : {
"src_dc" : 2.0,
"dest_dc" : 2.0
},
"success" : 2,
"error404" : 0,
"error503" : 0,
"clientip" : "0.72.176.46",
"agent_dc" : 2.0,
"bytes_sum" : 4422.0,
"responses" : {
"total" : 2.0
},
"url_dc" : 2.0,
"timestamp" : {
"duration_ms" : 5.2191698E8,
"min" : "2020-03-16T07:51:57.333Z",
"max" : "2020-03-22T08:50:34.313Z"
}
}
}
]
与其他 Kibana 示例数据集一样,Web 日志示例数据集包含相对于您安装它时的时间戳,包括将来的时间戳。一旦数据点过去,连续转换将拾取数据点。如果您在一段时间前安装了 Web 日志示例数据集,则可以卸载并重新安装它,并且时间戳将更改。
此转换使您可以更轻松地回答以下问题,例如
- 哪些客户端 IP 正在传输最多的数据量?
- 哪些客户端 IP 正在与大量的不同 URL 交互?
- 哪些客户端 IP 的错误率较高?
- 哪些客户端 IP 正在与大量的目标国家/地区交互?
查找每个 IP 地址的最后一个日志事件
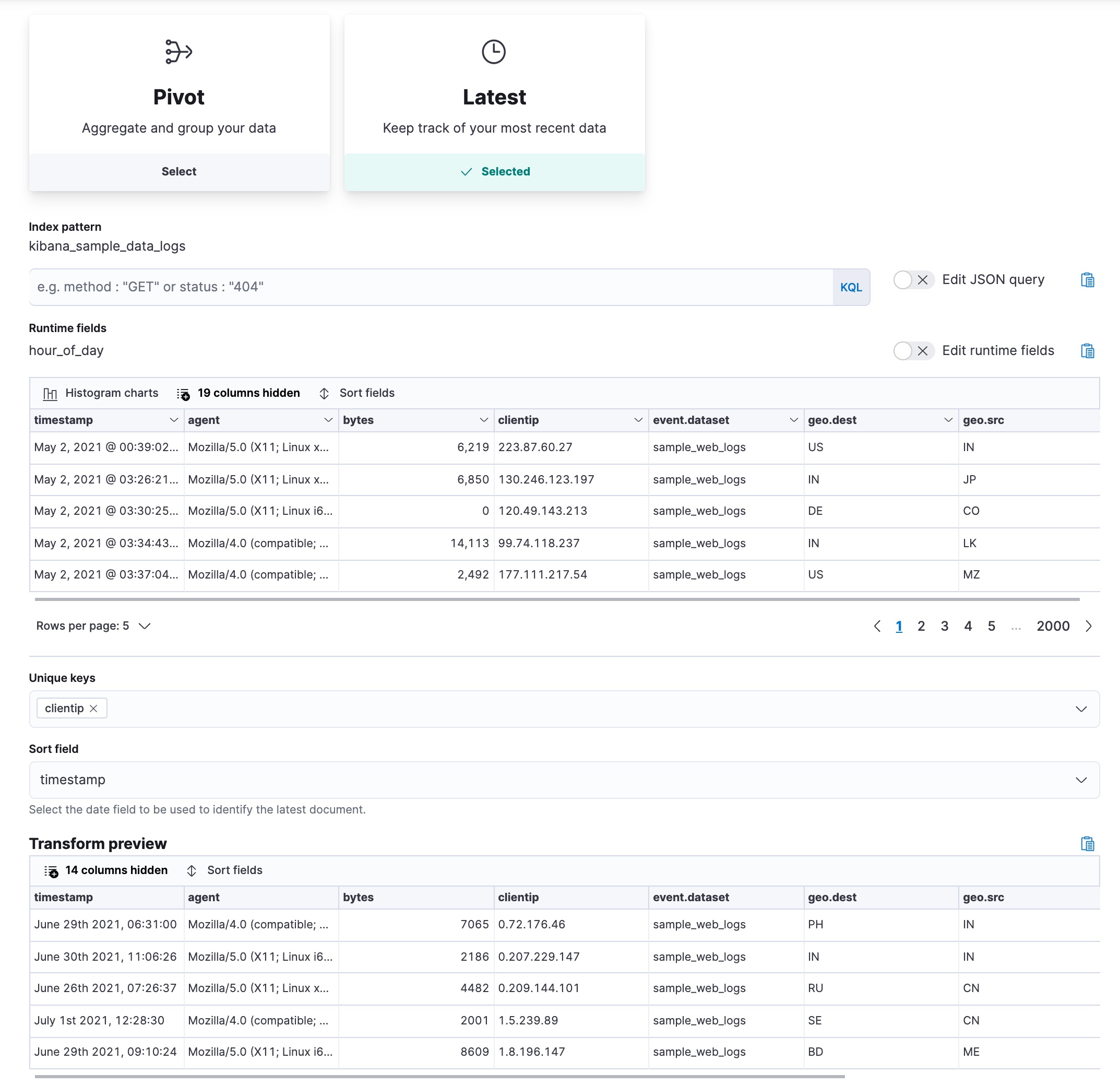
编辑此示例使用 Web 日志示例数据集来查找来自 IP 地址的最后一个日志。让我们在连续模式下使用 latest 类型的转换。它将每个唯一键的最新文档从源索引复制到目标索引,并在新数据进入源索引时更新目标索引。
选择 clientip 字段作为唯一键;数据按此字段分组。选择 timestamp 作为按时间顺序对数据进行排序的日期字段。对于连续模式,指定用于识别新文档的日期字段,以及检查源索引中更改的间隔。
假设我们有兴趣仅保留最近出现在日志中的 IP 地址的文档。您可以定义保留策略并指定用于计算文档年龄的日期字段。此示例使用用于对数据进行排序的同一日期字段。然后设置文档的最长保留时间;比您设置的值旧的文档将从目标索引中删除。
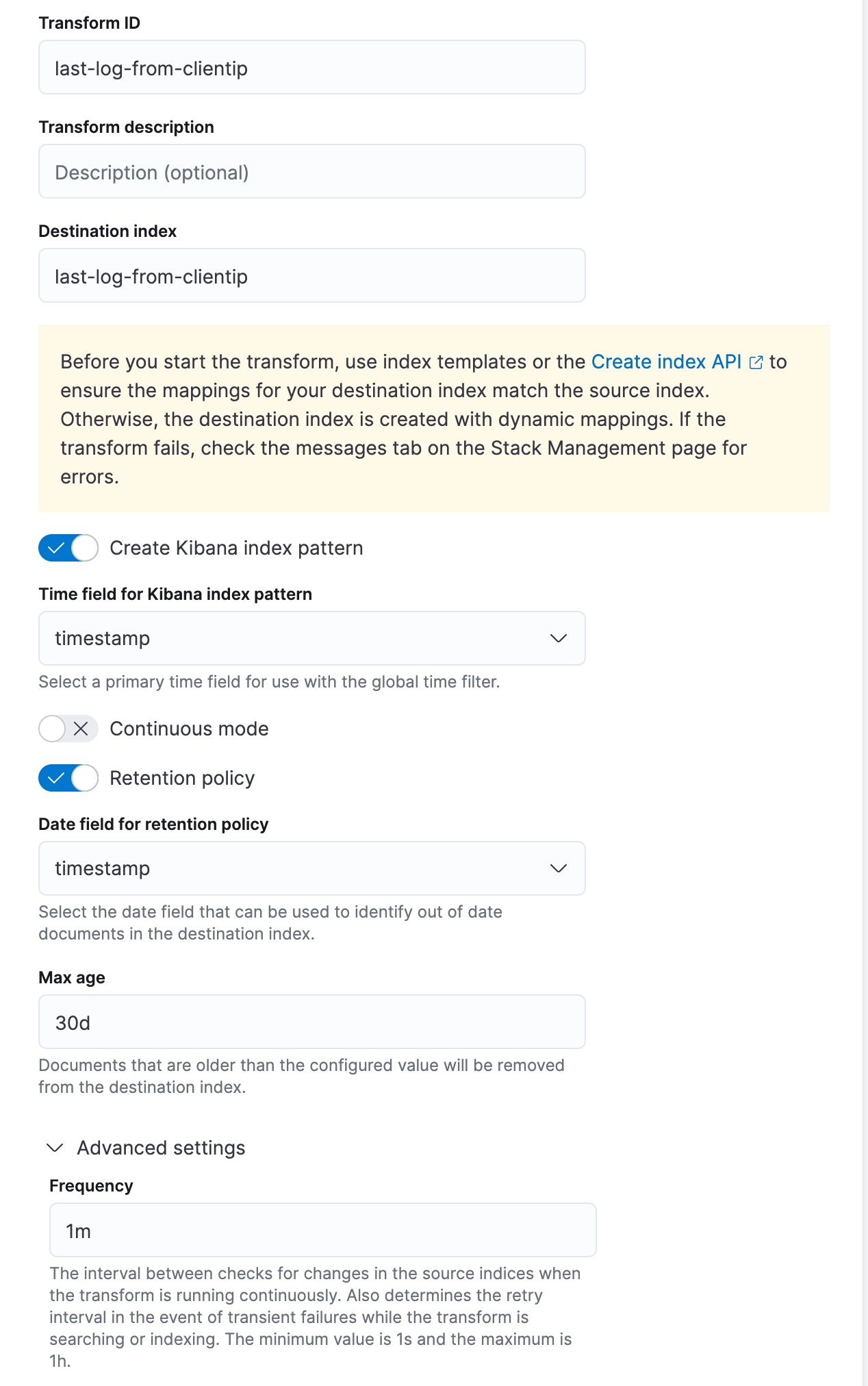
此转换创建目标索引,该索引包含每个客户端 IP 的最新登录日期。由于转换以连续模式运行,因此当新数据进入源索引时,目标索引将更新。最后,由于应用了保留策略,每个超过 30 天的文档都将从目标索引中删除。
API 示例
resp = client.transform.put_transform(
transform_id="last-log-from-clientip",
source={
"index": [
"kibana_sample_data_logs"
]
},
latest={
"unique_key": [
"clientip"
],
"sort": "timestamp"
},
frequency="1m",
dest={
"index": "last-log-from-clientip"
},
sync={
"time": {
"field": "timestamp",
"delay": "60s"
}
},
retention_policy={
"time": {
"field": "timestamp",
"max_age": "30d"
}
},
settings={
"max_page_search_size": 500
},
)
print(resp)
const response = await client.transform.putTransform({
transform_id: "last-log-from-clientip",
source: {
index: ["kibana_sample_data_logs"],
},
latest: {
unique_key: ["clientip"],
sort: "timestamp",
},
frequency: "1m",
dest: {
index: "last-log-from-clientip",
},
sync: {
time: {
field: "timestamp",
delay: "60s",
},
},
retention_policy: {
time: {
field: "timestamp",
max_age: "30d",
},
},
settings: {
max_page_search_size: 500,
},
});
console.log(response);
PUT _transform/last-log-from-clientip
{
"source": {
"index": [
"kibana_sample_data_logs"
]
},
"latest": {
"unique_key": [
"clientip"
],
"sort": "timestamp"
},
"frequency": "1m",
"dest": {
"index": "last-log-from-clientip"
},
"sync": {
"time": {
"field": "timestamp",
"delay": "60s"
}
},
"retention_policy": {
"time": {
"field": "timestamp",
"max_age": "30d"
}
},
"settings": {
"max_page_search_size": 500
}
}
|
指定用于对数据进行分组的字段。 |
|
|
指定用于对数据进行排序的日期字段。 |
|
|
设置转换检查源索引中更改的间隔。 |
|
|
包含用于同步源索引和目标索引的时间字段和延迟设置。 |
|
|
指定转换的保留策略。比配置的值旧的文档将从目标索引中删除。 |
创建转换后,启动它
resp = client.transform.start_transform(
transform_id="last-log-from-clientip",
)
print(resp)
response = client.transform.start_transform( transform_id: 'last-log-from-clientip' ) puts response
const response = await client.transform.startTransform({
transform_id: "last-log-from-clientip",
});
console.log(response);
POST _transform/last-log-from-clientip/_start
转换处理数据后,搜索目标索引
resp = client.search(
index="last-log-from-clientip",
)
print(resp)
response = client.search( index: 'last-log-from-clientip' ) puts response
const response = await client.search({
index: "last-log-from-clientip",
});
console.log(response);
GET last-log-from-clientip/_search
搜索结果显示每个客户端 IP 的数据,如下所示
{
"_index" : "last-log-from-clientip",
"_id" : "MOeHH_cUL5urmartKj-b5UQAAAAAAAAA",
"_score" : 1.0,
"_source" : {
"referer" : "http://twitter.com/error/don-lind",
"request" : "/elasticsearch",
"agent" : "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)",
"extension" : "",
"memory" : null,
"ip" : "0.72.176.46",
"index" : "kibana_sample_data_logs",
"message" : "0.72.176.46 - - [2018-09-18T06:31:00.572Z] \"GET /elasticsearch HTTP/1.1\" 200 7065 \"-\" \"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)\"",
"url" : "https://elastic.ac.cn/downloads/elasticsearch",
"tags" : [
"success",
"info"
],
"geo" : {
"srcdest" : "IN:PH",
"src" : "IN",
"coordinates" : {
"lon" : -124.1127917,
"lat" : 40.80338889
},
"dest" : "PH"
},
"utc_time" : "2021-05-04T06:31:00.572Z",
"bytes" : 7065,
"machine" : {
"os" : "ios",
"ram" : 12884901888
},
"response" : 200,
"clientip" : "0.72.176.46",
"host" : "www.elastic.co",
"event" : {
"dataset" : "sample_web_logs"
},
"phpmemory" : null,
"timestamp" : "2021-05-04T06:31:00.572Z"
}
}
此转换使您可以更轻松地回答以下问题,例如
- 与特定 IP 地址关联的最新日志事件是什么?
查找发送到服务器字节数最多的客户端 IP
编辑此示例使用 Web 日志示例数据集来查找每小时向服务器发送字节数最多的客户端 IP。该示例使用具有 top_metrics 聚合的 pivot 转换。
按时间字段上的日期直方图(间隔为一小时)对数据进行分组。使用 bytes 字段上的最大聚合来获取发送到服务器的最大数据量。如果没有 max 聚合,API 调用仍会返回发送字节最多的客户端 IP,但是不会返回它发送的字节数。在 top_metrics 属性中,指定 clientip 和 geo.src,然后按降序按 bytes 字段对它们进行排序。转换返回发送最大数据量的客户端 IP 和相应位置的 2 个字母的 ISO 代码。
resp = client.transform.preview_transform(
source={
"index": "kibana_sample_data_logs"
},
pivot={
"group_by": {
"timestamp": {
"date_histogram": {
"field": "timestamp",
"fixed_interval": "1h"
}
}
},
"aggregations": {
"bytes.max": {
"max": {
"field": "bytes"
}
},
"top": {
"top_metrics": {
"metrics": [
{
"field": "clientip"
},
{
"field": "geo.src"
}
],
"sort": {
"bytes": "desc"
}
}
}
}
},
)
print(resp)
const response = await client.transform.previewTransform({
source: {
index: "kibana_sample_data_logs",
},
pivot: {
group_by: {
timestamp: {
date_histogram: {
field: "timestamp",
fixed_interval: "1h",
},
},
},
aggregations: {
"bytes.max": {
max: {
field: "bytes",
},
},
top: {
top_metrics: {
metrics: [
{
field: "clientip",
},
{
field: "geo.src",
},
],
sort: {
bytes: "desc",
},
},
},
},
},
});
console.log(response);
POST _transform/_preview
{
"source": {
"index": "kibana_sample_data_logs"
},
"pivot": {
"group_by": {
"timestamp": {
"date_histogram": {
"field": "timestamp",
"fixed_interval": "1h"
}
}
},
"aggregations": {
"bytes.max": {
"max": {
"field": "bytes"
}
},
"top": {
"top_metrics": {
"metrics": [
{
"field": "clientip"
},
{
"field": "geo.src"
}
],
"sort": {
"bytes": "desc"
}
}
}
}
}
}
上面的 API 调用返回类似于此的响应
{
"preview" : [
{
"top" : {
"clientip" : "223.87.60.27",
"geo.src" : "IN"
},
"bytes" : {
"max" : 6219
},
"timestamp" : "2021-04-25T00:00:00.000Z"
},
{
"top" : {
"clientip" : "99.74.118.237",
"geo.src" : "LK"
},
"bytes" : {
"max" : 14113
},
"timestamp" : "2021-04-25T03:00:00.000Z"
},
{
"top" : {
"clientip" : "218.148.135.12",
"geo.src" : "BR"
},
"bytes" : {
"max" : 4531
},
"timestamp" : "2021-04-25T04:00:00.000Z"
},
...
]
}
按客户 ID 获取客户姓名和电子邮件地址
编辑此示例使用电子商务示例数据集基于客户 ID 创建以实体为中心的索引,并通过使用 top_metrics 聚合来获取客户姓名和电子邮件地址。
按 customer_id 对数据进行分组,然后添加 top_metrics 聚合,其中 metrics 是 email、customer_first_name.keyword 和 customer_last_name.keyword 字段。按降序按 order_date 对 top_metrics 进行排序。API 调用如下所示
resp = client.transform.preview_transform(
source={
"index": "kibana_sample_data_ecommerce"
},
pivot={
"group_by": {
"customer_id": {
"terms": {
"field": "customer_id"
}
}
},
"aggregations": {
"last": {
"top_metrics": {
"metrics": [
{
"field": "email"
},
{
"field": "customer_first_name.keyword"
},
{
"field": "customer_last_name.keyword"
}
],
"sort": {
"order_date": "desc"
}
}
}
}
},
)
print(resp)
const response = await client.transform.previewTransform({
source: {
index: "kibana_sample_data_ecommerce",
},
pivot: {
group_by: {
customer_id: {
terms: {
field: "customer_id",
},
},
},
aggregations: {
last: {
top_metrics: {
metrics: [
{
field: "email",
},
{
field: "customer_first_name.keyword",
},
{
field: "customer_last_name.keyword",
},
],
sort: {
order_date: "desc",
},
},
},
},
},
});
console.log(response);
POST _transform/_preview
{
"source": {
"index": "kibana_sample_data_ecommerce"
},
"pivot": {
"group_by": {
"customer_id": {
"terms": {
"field": "customer_id"
}
}
},
"aggregations": {
"last": {
"top_metrics": {
"metrics": [
{
"field": "email"
},
{
"field": "customer_first_name.keyword"
},
{
"field": "customer_last_name.keyword"
}
],
"sort": {
"order_date": "desc"
}
}
}
}
}
}
API 返回类似于此的响应
{
"preview" : [
{
"last" : {
"customer_last_name.keyword" : "Long",
"customer_first_name.keyword" : "Recip",
"email" : "[email protected]"
},
"customer_id" : "10"
},
{
"last" : {
"customer_last_name.keyword" : "Jackson",
"customer_first_name.keyword" : "Fitzgerald",
"email" : "[email protected]"
},
"customer_id" : "11"
},
{
"last" : {
"customer_last_name.keyword" : "Cross",
"customer_first_name.keyword" : "Brigitte",
"email" : "[email protected]"
},
"customer_id" : "12"
},
...
]
}