教程:监控 Java 应用程序
编辑教程:监控 Java 应用程序
编辑在本指南中,您将学习如何使用 Elastic 可观测性(日志、基础设施指标、APM 和正常运行时间)来监控 Java 应用程序。
您将学习的内容
编辑您将学习如何:
- 创建示例 Java 应用程序。
- 使用 Filebeat 摄取日志并在 Kibana 中查看您的日志。
- 使用 Metricbeat Prometheus 模块 摄取指标并在 Kibana 中查看您的指标。
- 使用 Elastic APM Java 代理 为您的应用程序添加监控。
- 使用 Heartbeat 监控您的服务并在 Kibana 中查看您的正常运行时间数据。
开始之前
编辑使用我们在 Elastic Cloud 上托管的 Elasticsearch 服务创建一个部署。该部署包括一个用于存储和搜索数据的 Elasticsearch 集群、用于可视化和管理数据的 Kibana 以及一个 APM 服务器。如果您不想按照此处列出的所有步骤操作,并查看最终的 Java 代码,请查看 observability-contrib GitHub 存储库 以获取示例应用程序。
步骤 1:创建 Java 应用程序
编辑要创建 Java 应用程序,您需要 OpenJDK 14(或更高版本)和 Javalin Web 框架。该应用程序将包含主端点、一个人工长时间运行的端点以及需要轮询另一个数据源的端点。还将运行一个后台作业。
-
设置一个 Gradle 项目并创建以下
build.gradle文件。plugins { id 'java' id 'application' } repositories { jcenter() } dependencies { implementation 'io.javalin:javalin:3.10.1' testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.2' testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.6.2' } application { mainClassName = 'de.spinscale.javalin.App' } test { useJUnitPlatform() } -
运行以下命令。
echo "rootProject.name = 'javalin-app'" >> settings.gradle mkdir -p src/main/java/de/spinscale/javalin mkdir -p src/test/java/de/spinscale/javalin
- 安装 Gradle 包装器。安装 Gradle 的一种简单方法是使用 sdkman 并运行
sdk install gradle 6.5.1。接下来,在当前目录中运行gradle wrapper以安装 Gradle 包装器。 - 运行
./gradlew clean check。您应该看到一个成功的构建,但尚未构建或编译任何内容。 -
要创建一个 Javalin 服务器及其第一个端点(主端点),请创建
src/main/java/de/spinscale/javalin/App.java文件。package de.spinscale.javalin; import io.javalin.Javalin; public class App { public static void main(String[] args) { Javalin app = Javalin.create().start(7000); app.get("/", ctx -> ctx.result("Appsolutely perfect")); } } -
运行
./gradlew assemble此命令编译了
build目录中的App.class文件。但是,无法启动服务器。让我们创建一个包含已编译类以及所有必需依赖项的 jar 包。 -
在
build.gradle文件中,按如下所示编辑plugins。plugins { id 'com.github.johnrengelman.shadow' version '6.0.0' id 'application' id 'java' } -
运行
./gradlew shadowJar。此命令创建一个build/libs/javalin-app-all.jar文件。shadowJar插件需要其主类信息。 -
将以下代码段添加到
build.gradle文件中。jar { manifest { attributes 'Main-Class': 'de.spinscale.javalin.App' } } -
重新构建项目并启动服务器。
java -jar build/libs/javalin-app-all.jar
打开另一个终端并运行
curl localhost:7000以显示 HTTP 响应。 -
测试代码。将所有内容放入
main()方法会使代码测试变得困难。但是,专用处理程序可以解决此问题。重构
App类。package de.spinscale.javalin; import io.javalin.Javalin; import io.javalin.http.Handler; public class App { public static void main(String[] args) { Javalin app = Javalin.create().start(7000); app.get("/", mainHandler()); } static Handler mainHandler() { return ctx -> ctx.result("Appsolutely perfect"); } }将 Mockito 和 Assertj 依赖项添加到
build.gradle文件中。dependencies { implementation 'io.javalin:javalin:3.10.1' testImplementation 'org.mockito:mockito-core:3.5.10' testImplementation 'org.assertj:assertj-core:3.17.2' testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.2' testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.6.2' }在
src/test/java/de/spinscale/javalin中创建AppTests.java类文件。package de.spinscale.javalin; import io.javalin.http.Context; import org.junit.jupiter.api.Test; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.io.IOException; import java.nio.charset.StandardCharsets; import java.util.HashMap; import static de.spinscale.javalin.App.mainHandler; import static org.assertj.core.api.Assertions.assertThat; import static org.mockito.Mockito.mock; public class AppTests { final HttpServletRequest req = mock(HttpServletRequest.class); final HttpServletResponse res = mock(HttpServletResponse.class); final Context ctx = new Context(req, res, new HashMap<>()); @Test public void testMainHandler() throws Exception { mainHandler().handle(ctx); String response = resultStreamToString(ctx); assertThat(response).isEqualTo("Appsolutely perfect"); } private String resultStreamToString(Context ctx) throws IOException { final byte[] bytes = ctx.resultStream().readAllBytes(); return new String(bytes, StandardCharsets.UTF_8); } } -
测试通过后,构建并打包应用程序。
./gradlew clean check shadowJar
步骤 2:摄取日志
编辑日志可以是诸如结账、异常或 HTTP 请求之类的事件。在本教程中,让我们使用 log4j2 作为我们的日志记录实现。
添加日志记录实现
编辑-
将依赖项添加到
build.gradle文件中。dependencies { implementation 'io.javalin:javalin:3.10.1' implementation 'org.apache.logging.log4j:log4j-slf4j18-impl:2.13.3' ... } -
要开始日志记录,请编辑
App.java文件并更改处理程序。logger 调用必须在 lambda 表达式内。否则,日志消息仅在启动期间记录。
package de.spinscale.javalin; import io.javalin.Javalin; import io.javalin.http.Handler; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class App { private static final Logger logger = LoggerFactory.getLogger(App.class); public static void main(String[] args) { Javalin app = Javalin.create(); app.get("/", mainHandler()); app.start(7000); } static Handler mainHandler() { return ctx -> { logger.info("This is an informative logging message, user agent [{}]", ctx.userAgent()); ctx.result("Appsolutely perfect"); }; } } -
在
src/main/resources/log4j2.xml文件中创建一个 log4j2 配置文件。您可能需要先创建该目录。<?xml version="1.0" encoding="UTF-8"?> <Configuration> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} [%-5level] %logger{36} %msg%n"/> </Console> </Appenders> <Loggers> <Logger name="de.spinscale.javalin.App" level="INFO"/> <Root level="ERROR"> <AppenderRef ref="Console" /> </Root> </Loggers> </Configuration>默认情况下,这会在
ERROR级别进行日志记录。对于App类,还有一个附加配置,以便也记录所有INFO日志。重新打包和重新启动后,日志消息将显示在终端中。17:17:40.019 [INFO ] de.spinscale.javalin.App - This is an informative logging message, user agent [curl/7.64.1]
记录请求
编辑根据应用程序流量以及它是否发生在应用程序外部,在应用程序级别记录每个请求是有意义的。
-
在
App.java文件中,编辑App类。public class App { private static final Logger logger = LoggerFactory.getLogger(App.class); public static void main(String[] args) { Javalin app = Javalin.create(config -> { config.requestLogger((ctx, executionTimeMs) -> { logger.info("{} {} {} {} \"{}\" {}", ctx.method(), ctx.url(), ctx.req.getRemoteHost(), ctx.res.getStatus(), ctx.userAgent(), executionTimeMs.longValue()); }); }); app.get("/", mainHandler()); app.start(7000); } static Handler mainHandler() { return ctx -> { logger.info("This is an informative logging message, user agent [{}]", ctx.userAgent()); ctx.result("Appsolutely perfect"); }; } } -
重新构建并重新启动应用程序。将为每个请求记录日志消息。
10:43:50.066 [INFO ] de.spinscale.javalin.App - GET / 200 0:0:0:0:0:0:0:1 "curl/7.64.1" 7
创建 ISO8601 时间戳
编辑在将日志摄取到 Elasticsearch Service 之前,请通过编辑 log4j2.xml 文件来创建 ISO8601 时间戳。
创建 ISO8601 时间戳消除了在摄取日志时进行任何时间戳计算的需要,因为这是一个唯一的时间点,包括时区。当您在尝试跟踪数据流的同时跨数据中心运行时,时区变得越来越重要。
<PatternLayout pattern="%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n"/>
摄取的日志条目包含如下所示的时间戳。
2020-07-03T14:25:40,378+02:00 [INFO ] de.spinscale.javalin.App GET / 200 0:0:0:0:0:0:0:1 "curl/7.64.1" 0
记录到文件和标准输出
编辑-
要读取日志输出,让我们将数据写入文件和标准输出。这是一个新的
log4j2.xml文件。<?xml version="1.0" encoding="UTF-8"?> <Configuration> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%highlight{%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n}"/> </Console> <File name="JavalinAppLog" fileName="/tmp/javalin/app.log"> <PatternLayout pattern="%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n"/> </File> </Appenders> <Loggers> <Logger name="de.spinscale.javalin.App" level="INFO"/> <Root level="ERROR"> <AppenderRef ref="Console" /> <AppenderRef ref="JavalinAppLog" /> </Root> </Loggers> </Configuration> - 重新启动应用程序并发送请求。日志将发送到
/tmp/javalin/app.log。
安装和配置 Filebeat
编辑要读取日志文件并将其发送到 Elasticsearch,需要 Filebeat。要下载并安装 Filebeat,请使用适合您系统的命令
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.16.0-amd64.deb sudo dpkg -i filebeat-8.16.0-amd64.deb
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.16.0-x86_64.rpm sudo rpm -vi filebeat-8.16.0-x86_64.rpm
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.16.0-darwin-x86_64.tar.gz tar xzvf filebeat-8.16.0-darwin-x86_64.tar.gz
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.16.0-linux-x86_64.tar.gz tar xzvf filebeat-8.16.0-linux-x86_64.tar.gz
- 从 下载页面 下载 Filebeat Windows zip 文件。
- 将 zip 文件的内容解压缩到
C:\Program Files。 - 将
filebeat-<version>-windows目录重命名为Filebeat。 - 以管理员身份打开 PowerShell 提示符(右键单击 PowerShell 图标并选择以管理员身份运行)。
-
从 PowerShell 提示符中,运行以下命令将 Filebeat 安装为 Windows 服务
PS > cd 'C:\Program Files\Filebeat' PS C:\Program Files\Filebeat> .\install-service-filebeat.ps1
如果您的系统禁用了脚本执行,则需要将当前会话的执行策略设置为允许脚本运行。例如:PowerShell.exe -ExecutionPolicy UnRestricted -File .\install-service-filebeat.ps1。
-
使用 Filebeat 密钥库存储 安全设置。让我们将 Cloud ID 存储在密钥库中。
在以下命令中替换您部署中的 Cloud ID。要查找您的 Cloud ID,请在 https://cloud.elastic.co/deployments 中单击您的部署
./filebeat keystore create echo -n "<Your Cloud ID>" | ./filebeat keystore add CLOUD_ID --stdin
要以最小的权限将日志存储在 Elasticsearch 中,请创建一个 API 密钥以将数据从 Filebeat 发送到 Elasticsearch Service。
-
登录 Kibana 用户(您可以在无需输入任何权限的情况下从 Cloud 控制台执行此操作)并选择管理 → 开发工具。发送以下请求
POST /_security/api_key { "name": "filebeat_javalin-app", "role_descriptors": { "filebeat_writer": { "cluster": ["monitor", "read_ilm"], "index": [ { "names": ["filebeat-*"], "privileges": ["view_index_metadata", "create_doc"] } ] } } }响应包含一个
api_key字段和一个id字段,可以以下格式存储在 Filebeat 密钥库中:id:api_key。echo -n "IhrJJHMB4JmIUAPLuM35:1GbfxhkMT8COBB4JWY3pvQ" | ./filebeat keystore add ES_API_KEY --stdin
确保指定
-n参数;否则,由于在 API 密钥末尾添加了换行符,您将进行痛苦的调试会话。要查看是否已存储这两个设置,请运行
./filebeat keystore list。 -
要加载 Filebeat 仪表板,请使用
elastic超级用户。./filebeat setup -e -E 'cloud.id=${CLOUD_ID}' -E 'cloud.auth=elastic:YOUR_SUPER_SECRET_PASS'如果您不想将凭据存储在 shell 的
.history文件中,请在行首添加一个空格。根据 shell 配置,这些命令不会添加到历史记录中。 -
配置 Filebeat,使其知道从哪里读取数据以及发送到哪里。创建一个
filebeat.yml文件。name: javalin-app-shipper filebeat.inputs: - type: log paths: - /tmp/javalin/*.log cloud.id: ${CLOUD_ID} output.elasticsearch: api_key: ${ES_API_KEY}
将数据发送到 Elasticsearch
编辑要将数据发送到 Elasticsearch,请启动 Filebeat。
sudo service filebeat start
如果您使用 init.d 脚本启动 Filebeat,则无法指定命令行标志(请参阅 命令参考)。要指定标志,请在前景中启动 Filebeat。
另请参阅 Filebeat 和 systemd。
sudo service filebeat start
如果您使用 init.d 脚本启动 Filebeat,则无法指定命令行标志(请参阅 命令参考)。要指定标志,请在前景中启动 Filebeat。
另请参阅 Filebeat 和 systemd。
./filebeat -e
./filebeat -e
PS C:\Program Files\filebeat> Start-Service filebeat
默认情况下,Windows 日志文件存储在 C:\ProgramData\filebeat\Logs 中。
在日志输出中,您应该看到以下行。
2020-07-03T15:41:56.532+0200 INFO log/harvester.go:297 Harvester started for file: /tmp/javalin/app.log
让我们为应用程序创建一些日志条目。您可以使用诸如 wrk 之类的工具并运行以下命令以向应用程序发送请求。
wrk -t1 -c 100 -d10s https://127.0.0.1:7000
此命令每秒产生大约 8000 个请求,并写入等量的日志行。
步骤 3:在 Kibana 中查看日志
编辑-
登录 Kibana 并选择发现 应用程序。
顶部有文档摘要,但让我们看一下单个文档。
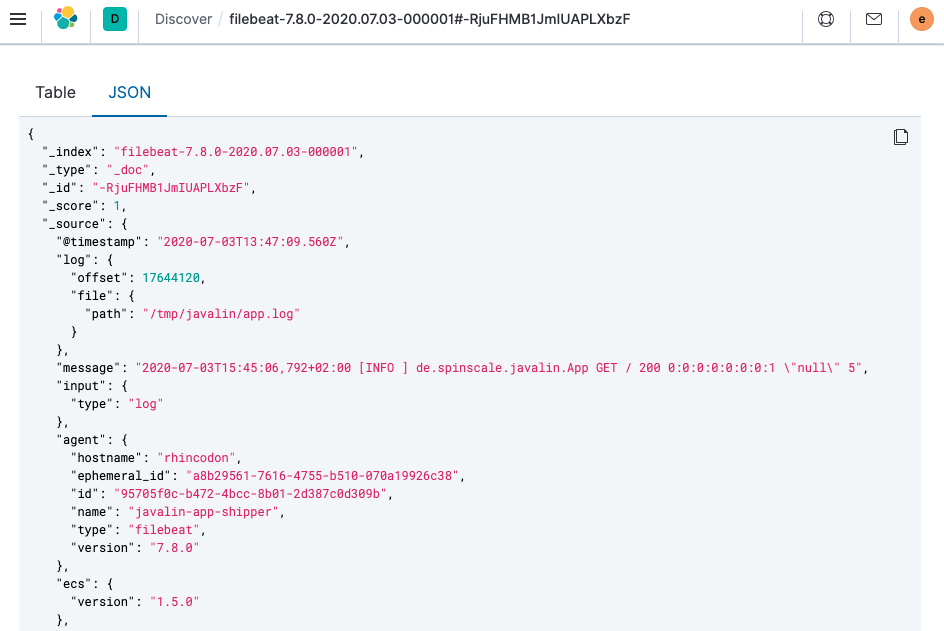
您可以看到索引的数据远不止事件本身。其中包含有关文件偏移量的信息、有关发送日志的组件的信息、输出中发送者名称的名称,以及包含日志行内容的
message字段。您可以看到请求日志记录存在缺陷。如果用户代理为
null,则返回null以外的内容。阅读我们的日志至关重要;但是,仅仅索引它们对我们没有任何好处。要解决此问题,这里有一个新的请求记录器。Javalin app = Javalin.create(config -> { config.requestLogger((ctx, executionTimeMs) -> { String userAgent = ctx.userAgent() != null ? ctx.userAgent() : "-"; logger.info("{} {} {} {} \"{}\" {}", ctx.method(), ctx.req.getPathInfo(), ctx.res.getStatus(), ctx.req.getRemoteHost(), userAgent, executionTimeMs.longValue()); }); });您可能还希望在主处理程序中的日志消息中修复此问题。
static Handler mainHandler() { return ctx -> { String userAgent = ctx.userAgent() != null ? ctx.userAgent() : "-"; logger.info("This is an informative logging message, user agent [{}]", userAgent); ctx.result("Appsolutely perfect"); }; } -
现在让我们看一下 Kibana 中的日志应用程序。选择可观测性 → 日志。
如果您想查看流式传输功能的工作原理,请在休眠时循环运行以下 curl 请求。
while $(sleep 0.7) ; do curl localhost:7000 ; done
-
要查看连续的日志消息流,请单击流式直播。您还可以突出显示特定术语,如下所示。
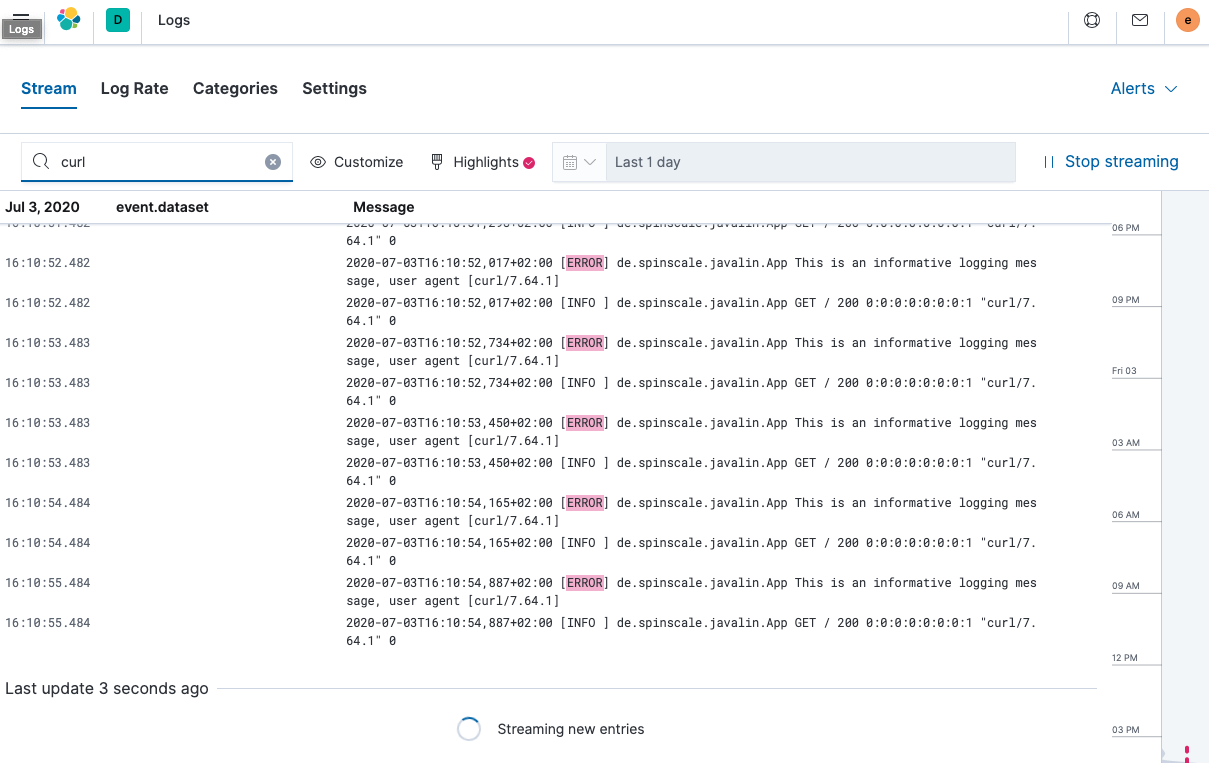
查看正在索引的文档之一,您可以看到日志消息包含在一个字段中。通过查看这些文档之一来验证这一点。
GET filebeat-*/_search { "size": 1 }注意事项
- 当您将
@timestamp字段与日志消息的时间戳进行比较时,您会注意到它们有所不同。这意味着当您根据@timestamp字段进行筛选时,您不会获得预期的结果。当前的@timestamp字段反映的是 Filebeat 中创建事件的时间戳,而不是应用程序中发生日志事件的时间戳。 - 无法根据特定字段进行筛选,例如 HTTP 动词、HTTP 状态代码、日志级别或生成日志消息的类。
- 当您将
步骤 4:处理您的日志
编辑构建日志结构
编辑要将单行日志中的更多数据提取到多个字段中,需要对日志进行额外的结构化处理。
让我们再次看一下我们的应用程序生成的日志消息。
2020-07-03T15:45:01,479+02:00 [INFO ] de.spinscale.javalin.App This is an informative logging message
此消息包含四个部分:时间戳、日志级别、类名和消息。分割规则也很明显,大多数规则都涉及空格。
好消息是,所有 Beats 都可以在将日志行发送到 Elasticsearch 之前使用处理器进行处理。如果这些处理器的功能不足,您可以始终使用摄取节点让 Elasticsearch 完成繁重的工作。许多 Filebeat 模块都是这样做的。Filebeat 中的模块是一种解析特定软件的特定日志文件格式的方法。
让我们尝试使用几个处理器和仅 Filebeat 配置来实现这一点。
processors:
- add_host_metadata: ~
- dissect:
tokenizer: '%{timestamp} [%{log.level}] %{log.logger} %{message_content}'
field: "message"
target_prefix: ""
- timestamp:
field: "timestamp"
layouts:
- '2006-01-02T15:04:05.999Z0700'
test:
- '2020-07-18T04:59:51.123+0200'
- drop_fields:
fields: [ "message", "timestamp" ]
- rename:
fields:
- from: "message_content"
- to: "message"
dissect处理器将日志消息分成四个部分。如果希望在message字段中保留原始消息的最后一部分,则需要先删除旧的message字段,然后重命名该字段。dissect 过滤器不支持就地替换。
还有一个专门的时间戳解析器,以便@timestamp字段包含已解析的值。删除重复的字段,但确保原始消息的一部分仍然保留在message字段中。
删除原始消息的部分内容是有争议的。在我看来,保留原始消息非常有意义。使用上面的示例,如果时间戳解析没有按预期工作,则调试可能会变得很麻烦。
时间戳的解析也略有不同,因为 Go 时间解析器只接受点作为秒和毫秒之间的分隔符。但是,我们的 log4j2 默认输出使用的是逗号。
任何一种方法都可以修复日志输出中的时间戳,使其看起来像 Filebeat 预期的那样。这将产生以下模式布局。
<PatternLayout pattern="%d{yyyy-MM-dd'T'HH:mm:ss.SSSZ} [%-5level] %logger{36} %msg%n"/>
修复时间戳解析是另一种方法,因为您并不总是能够完全控制日志并更改其格式。想象一下使用一些第三方软件。就目前而言,这已经足够好了。
更改后重启 Filebeat,并通过运行此搜索(并索引另一条日志消息)查看已索引 JSON 文档中发生了哪些更改。
GET filebeat-*/_search?filter_path=**._source
{
"size": 1,
"_source": {
"excludes": [
"host.ip",
"host.mac"
]
},
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
]
}
这将返回如下文档。
{
"hits" : {
"hits" : [
{
"_source" : {
"input" : {
"type" : "log"
},
"agent" : {
"hostname" : "rhincodon",
"name" : "javalin-app-shipper",
"id" : "95705f0c-b472-4bcc-8b01-2d387c0d309b",
"type" : "filebeat",
"ephemeral_id" : "e4df883f-6073-4a90-a4c4-9e116704f871",
"version" : "7.9.0"
},
"@timestamp" : "2020-07-03T15:11:51.925Z",
"ecs" : {
"version" : "1.5.0"
},
"log" : {
"file" : {
"path" : "/tmp/javalin/app.log"
},
"offset" : 1440,
"level" : "ERROR",
"logger" : "de.spinscale.javalin.App"
},
"host" : {
"hostname" : "rhincodon",
"os" : {
"build" : "19F101",
"kernel" : "19.5.0",
"name" : "Mac OS X",
"family" : "darwin",
"version" : "10.15.5",
"platform" : "darwin"
},
"name" : "javalin-app-shipper",
"id" : "C28736BF-0EB3-5A04-BE85-C27A62C99316",
"architecture" : "x86_64"
},
"message" : "This is an informative logging message, user agent [curl/7.64.1]"
}
}
]
}
}
您可以看到message字段只包含日志消息的最后一部分。此外,还有一个log.level和log.logger字段。
当日志级别为INFO时,它会在末尾添加额外的空格。您可以使用脚本处理器并调用trim()。但是,修复我们的日志记录配置以不总是发出 5 个字符(与日志级别长度无关)可能会更容易。写入标准输出时,您仍然可以保留此设置。
<File name="JavalinAppLog" fileName="/tmp/javalin/app.log">
<PatternLayout pattern="%d{yyyy-MM-dd'T'HH:mm:ss.SSSZ} [%level] %logger{36} %msg%n"/>
</File>
解析异常
编辑在日志记录的情况下,异常是一种特殊的情况。它们跨越多行,因此每行一条消息的旧规则在异常中不存在。
首先在App.java中添加一个触发异常的端点,并确保使用异常映射器进行记录。
app.get("/exception", ctx -> {
throw new IllegalArgumentException("not yet implemented");
});
app.exception(Exception.class, (e, ctx) -> {
logger.error("Exception found", e);
ctx.status(500).result(e.getMessage());
});
调用/exception会向客户端返回 HTTP 500 错误,但它会在日志中留下如下所示的堆栈跟踪。
2020-07-06T11:27:29,491+02:00 [ERROR] de.spinscale.javalin.App Exception found
java.lang.IllegalArgumentException: not yet implemented
at de.spinscale.javalin.App.lambda$main$2(App.java:24) ~[classes/:?]
at io.javalin.core.security.SecurityUtil.noopAccessManager(SecurityUtil.kt:23) ~[javalin-3.10.1.jar:?]
at io.javalin.http.JavalinServlet$addHandler$protectedHandler$1.handle(JavalinServlet.kt:119) ~[javalin-3.10.1.jar:?]
at io.javalin.http.JavalinServlet$service$2$1.invoke(JavalinServlet.kt:45) ~[javalin-3.10.1.jar:?]
at io.javalin.http.JavalinServlet$service$2$1.invoke(JavalinServlet.kt:24) ~[javalin-3.10.1.jar:?]
... goes on and on and on and own ...
有一个属性有助于解析此堆栈跟踪。与常规日志消息相比,它看起来有所不同。每行新行的开头都有空格,因此与以日期开头的日志消息不同。让我们将此逻辑添加到我们的 Beats 配置中。
- type: log
enabled: true
paths:
- /tmp/javalin/*.log
multiline.pattern: ^20
multiline.negate: true
multiline.match: after
因此,上述设置的逐字翻译是将所有内容都视为现有消息的一部分,即一行中不以20开头的内容。20代表时间戳的年份开头。一些用户更喜欢将日期用[]括起来,以便更容易理解。
这会在您的日志记录中引入状态。您现在无法在多个处理器之间分割日志文件,因为每行日志仍然可能属于当前事件。这并不是一件坏事,但同样需要注意。
重启 Filebeat 和 Javalin 应用程序后,触发异常,您将在日志的message字段中看到一个很长的堆栈跟踪。
配置日志轮转
编辑为了确保日志不会无限增长,让我们向您的日志记录配置中添加一些日志轮转功能。
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%highlight{%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n}"/>
</Console>
<RollingFile name="JavalinAppLogRolling" fileName="/tmp/javalin/app.log" filePattern="/tmp/javalin/%d{yyyy-MM-dd}-%i.log.gz">
<PatternLayout pattern="%d{yyyy-MM-dd'T'HH:mm:ss.SSSZ} [%level] %logger{36} %msg%n"/>
<Policies>
<TimeBasedTriggeringPolicy />
<SizeBasedTriggeringPolicy size="50 MB"/>
</Policies>
<DefaultRolloverStrategy max="20"/>
</RollingFile>
</Appenders>
<Loggers>
<Logger name="de.spinscale.javalin.App" level="INFO"/>
<Root level="ERROR">
<AppenderRef ref="Console" />
<AppenderRef ref="JavalinAppLogRolling" />
</Root>
</Loggers>
</Configuration>
示例向我们的配置中添加了一个JavalinAppLogRolling追加器,它使用与之前相同的日志记录模式,但在新的一天开始或日志文件达到 50 兆字节时进行轮转。
如果创建了新的日志文件,旧的日志文件也会被压缩,以减少磁盘空间占用。50 兆字节的大小指的是解压缩的文件大小,因此磁盘上可能有二十个文件,每个文件都小得多。
摄取节点
编辑内置模块几乎完全使用 Elasticsearch 的摄取节点功能,而不是 Beats 处理器。
摄取管道的最有帮助的部分之一是能够使用模拟管道 API进行调试。
-
让我们在 Kibana 的 Dev Tools 面板中编写一个类似于我们的 Filebeat 处理器的管道,运行以下命令
# Store the pipeline in Elasticsearch PUT _ingest/pipeline/javalin_pipeline { "processors": [ { "dissect": { "field": "message", "pattern": "%{@timestamp} [%{log.level}] %{log.logger} %{message}" } }, { "trim": { "field": "log.level" } }, { "date": { "field": "@timestamp", "formats": [ "ISO8601" ] } } ] } # Test the pipeline POST _ingest/pipeline/javalin_pipeline/_simulate { "docs": [ { "_source": { "message": "2020-07-06T13:39:51,737+02:00 [INFO ] de.spinscale.javalin.App This is an informative logging message" } } ] }您可以在输出中看到管道创建的字段,它现在看起来像之前的 Filebeat 处理器。由于摄取管道在文档级别上工作,您仍然需要检查日志生成的异常,并让 Filebeat 从中创建一个单一消息。您甚至可以使用单个处理器来实现日志级别修剪,并且日期解析也很容易,因为 Elasticsearch ISO8601 解析器在分割秒和毫秒时可以正确识别逗号而不是点。
-
现在,让我们来看一下 Filebeat 配置。首先,让我们删除所有处理器,除了add_host_metadata 处理器,以便添加一些主机信息,例如主机名和操作系统。
processors: - add_host_metadata: ~
-
编辑 Elasticsearch 输出以确保在从 Filebeat 索引文档时会引用该管道。
cloud.id: ${CLOUD_ID} output.elasticsearch: api_key: ${ES_API_KEY} pipeline: javalin_pipeline - 重启 Filebeat 并查看日志是否按预期流动。
将日志写入 JSON
编辑您现在已经了解了如何在 Beats 或 Elasticsearch 中解析日志。如果我们不需要考虑解析日志并手动提取数据怎么办?
将日志写成纯文本可以工作,并且易于人们阅读。但是,首先将它们写成纯文本,使用dissect处理器解析它们,然后再次创建 JSON,听起来很繁琐,并且会浪费不必要的 CPU 周期。
虽然 log4j2 有一个JSONLayout,但您可以更进一步,使用一个名为ecs-logging-java的库。ECS 日志记录的优势在于它使用了Elastic 通用架构。ECS 定义了一组标准字段,用于在 Elasticsearch 中存储事件数据,例如日志和指标。
-
与其编写我们自己的日志记录标准,不如使用现有的标准。让我们将日志记录依赖项添加到我们的 Javalin 应用程序中。
dependencies { implementation 'io.javalin:javalin:3.10.1' implementation 'org.apache.logging.log4j:log4j-slf4j18-impl:2.13.3' implementation 'co.elastic.logging:log4j2-ecs-layout:0.5.0' testImplementation 'org.mockito:mockito-core:3.5.10' testImplementation 'org.assertj:assertj-core:3.17.2' testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.2' testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.6.2' } // this is needed to ensure JSON logging works as expected when building // a shadow jar shadowJar { transform(com.github.jengelman.gradle.plugins.shadow.transformers.Log4j2PluginsCacheFileTransformer) }log4j2-ecs-layout附带一个自定义的<EcsLayout>,可以在日志记录设置中用于滚动文件追加器<RollingFile name="JavalinAppLogRolling" fileName="/tmp/javalin/app.log" filePattern="/tmp/javalin/%d{yyyy-MM-dd}-%i.log.gz"> <EcsLayout serviceName="my-javalin-app"/> <Policies> <TimeBasedTriggeringPolicy /> <SizeBasedTriggeringPolicy size="50 MB"/> </Policies> <DefaultRolloverStrategy max="20"/> </RollingFile>重启应用程序后,您将看到写入日志文件的纯 JSON。当您触发异常时,您会看到堆栈跟踪已经包含在您的单个文档中。这意味着 Filebeat 配置可以变得无状态,甚至更轻量级。此外,Elasticsearch 端的摄取管道也可以再次删除。
-
您可以为
EcsLayout配置一些更多参数,但默认参数已明智地选择。让我们修复 Filebeat 配置,并删除多行设置以及管道filebeat.inputs: - type: log enabled: true paths: - /tmp/javalin/*.log json.keys_under_root: true name: javalin-app-shipper cloud.id: ${CLOUD_ID} output.elasticsearch: api_key: ${ES_API_KEY} # ================================= Processors ================================= processors: - add_host_metadata: ~如您所见,仅通过将日志写成 JSON,我们的整个日志记录设置就变得容易得多,因此,尽可能直接将日志写成 JSON。
步骤 5:摄取指标
编辑指标被认为是随时可能改变的某个时间点的值。当前请求的数量可能每毫秒都在变化。您可能会有 1000 个请求的峰值,然后一切都会恢复到一个请求。这也意味着这些类型的指标可能不准确,您还需要提取最小值/最大值以获得更多指示。此外,这意味着您还需要考虑这些指标的持续时间。您是否需要每分钟或每 10 秒获取一次这些指标?
为了从不同的角度查看您的应用程序,让我们摄取一些指标。在这个示例中,我们将使用Metricbeat Prometheus 模块将数据发送到 Elasticsearch。
我们的应用程序中使用的底层库是micrometer.io,它是一个供应商中立的应用程序指标外观,结合其Prometheus 支持来实现基于拉取的模型。您可以使用Elastic 支持来实现基于推送的模型。这需要用户在我们的应用程序中存储 Elasticsearch 集群的凭据数据。此示例将这些数据保留在周围的工具中。
向应用程序添加指标
编辑-
将依赖项添加到我们的
build.gradle文件中。// metrics via micrometer implementation 'io.micrometer:micrometer-core:1.5.4' implementation 'io.micrometer:micrometer-registry-prometheus:1.5.4' implementation 'org.apache.commons:commons-lang3:3.11'
-
将 micrometer 插件及其相应的导入添加到我们的 Javalin 应用程序中。
... import io.javalin.plugin.metrics.MicrometerPlugin; import io.javalin.core.security.BasicAuthCredentials; ... Javalin app = Javalin.create(config -> { ... config.registerPlugin(new MicrometerPlugin()); ); -
添加一个新的指标端点,并确保导入了
BasicAuthCredentials类。final Micrometer micrometer = new Micrometer(); app.get("/metrics", ctx -> { ctx.status(404); if (ctx.basicAuthCredentialsExist()) { final BasicAuthCredentials credentials = ctx.basicAuthCredentials(); if ("metrics".equals(credentials.getUsername()) && "secret".equals(credentials.getPassword())) { ctx.status(200).result(micrometer.scrape()); } } });此处,
MicroMeter类是一个名为MicroMeter.java的自编写类,它设置了几个指标监控器并为 Prometheus 创建注册表,从而提供基于文本的 Prometheus 输出。package de.spinscale.javalin; import io.micrometer.core.instrument.Metrics; import io.micrometer.core.instrument.binder.jvm.JvmCompilationMetrics; import io.micrometer.core.instrument.binder.jvm.JvmGcMetrics; import io.micrometer.core.instrument.binder.jvm.JvmHeapPressureMetrics; import io.micrometer.core.instrument.binder.jvm.JvmMemoryMetrics; import io.micrometer.core.instrument.binder.jvm.JvmThreadMetrics; import io.micrometer.core.instrument.binder.logging.Log4j2Metrics; import io.micrometer.core.instrument.binder.system.FileDescriptorMetrics; import io.micrometer.core.instrument.binder.system.ProcessorMetrics; import io.micrometer.core.instrument.binder.system.UptimeMetrics; import io.micrometer.prometheus.PrometheusConfig; import io.micrometer.prometheus.PrometheusMeterRegistry; public class Micrometer { final PrometheusMeterRegistry registry = new PrometheusMeterRegistry(new PrometheusConfig() { @Override public String get(String key) { return null; } @Override public String prefix() { return "javalin"; } }); public Micrometer() { Metrics.addRegistry(registry); new JvmGcMetrics().bindTo(Metrics.globalRegistry); new JvmHeapPressureMetrics().bindTo(Metrics.globalRegistry); new JvmThreadMetrics().bindTo(Metrics.globalRegistry); new JvmCompilationMetrics().bindTo(Metrics.globalRegistry); new JvmMemoryMetrics().bindTo(Metrics.globalRegistry); new Log4j2Metrics().bindTo(Metrics.globalRegistry); new UptimeMetrics().bindTo(Metrics.globalRegistry); new FileDescriptorMetrics().bindTo(Metrics.globalRegistry); new ProcessorMetrics().bindTo(Metrics.globalRegistry); } public String scrape() { return registry.scrape(); } } -
重新构建您的应用程序并轮询指标端点。
curl localhost:7000/metrics -u metrics:secret
这将返回基于行的响应,每行一个指标。这是标准的 Prometheus 格式。
安装和配置 Metricbeat
编辑要将指标发送到 Elasticsearch,需要 Metricbeat。要下载并安装 Metricbeat,请使用适合您系统的命令。
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.16.0-amd64.deb sudo dpkg -i metricbeat-8.16.0-amd64.deb
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.16.0-x86_64.rpm sudo rpm -vi metricbeat-8.16.0-x86_64.rpm
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.16.0-darwin-x86_64.tar.gz tar xzvf metricbeat-8.16.0-darwin-x86_64.tar.gz
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.16.0-linux-x86_64.tar.gz tar xzvf metricbeat-8.16.0-linux-x86_64.tar.gz
- 从下载页面下载 Metricbeat Windows zip 文件。
- 将 zip 文件的内容解压缩到
C:\Program Files。 - 将
metricbeat-<version>-windows目录重命名为Metricbeat。 - 以管理员身份打开 PowerShell 提示符(右键单击 PowerShell 图标并选择以管理员身份运行)。
-
从 PowerShell 提示符运行以下命令,将 Metricbeat 安装为 Windows 服务
PS > cd 'C:\Program Files\Metricbeat' PS C:\Program Files\Metricbeat> .\install-service-metricbeat.ps1
如果您的系统禁用了脚本执行,则需要将当前会话的执行策略设置为允许脚本运行。例如:PowerShell.exe -ExecutionPolicy UnRestricted -File .\install-service-metricbeat.ps1。
-
与 Filebeat 设置类似,请使用管理员用户运行所有仪表板的初始设置,然后使用 API 密钥。
POST /_security/api_key { "name": "metricbeat_javalin-app", "role_descriptors": { "metricbeat_writer": { "cluster": ["monitor", "read_ilm"], "index": [ { "names": ["metricbeat-*"], "privileges": ["view_index_metadata", "create_doc"] } ] } } } -
将
id和api_key字段的组合存储在密钥库中。./metricbeat keystore create echo -n "IhrJJHMB4JmIUAPLuM35:1GbfxhkMT8COBB4JWY3pvQ" | ./metricbeat keystore add ES_API_KEY --stdin echo -n "observability-javalin-app:ZXUtY2VudHJhbC0xLmF3cy5jbG91ZC5lcy5pbyQ4NDU5M2I1YmQzYTY0N2NhYjA2MWQ3NTJhZWFhNWEzYyQzYmQwMWE2OTQ2MmQ0N2ExYjdhYTkwMzI0YjJiOTMyYQ==" | ./metricbeat keystore add CLOUD_ID --stdin
不要忘记像这样进行初始设置。
./metricbeat setup -e -E 'cloud.id=${CLOUD_ID}' -E 'cloud.auth=elastic:YOUR_SUPER_SECRET_PASS' -
配置 Metricbeat 以读取我们的 Prometheus 指标。从基本的
metricbeat.yaml开始。metricbeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false name: javalin-metrics-shipper cloud.id: ${CLOUD_ID} output.elasticsearch: api_key: ${ES_API_KEY} processors: - add_host_metadata: ~ - add_cloud_metadata: ~ - add_docker_metadata: ~ - add_kubernetes_metadata: ~由于 Metricbeat 支持数十个模块,而这些模块又是摄取指标的不同方式(Filebeat 也适用于不同类型的日志文件和格式),因此需要启用 Prometheus 模块。
./metricbeat modules enable prometheus
在
./modules.d/prometheus.yml中添加要轮询的 Prometheus 端点。- module: prometheus period: 10s hosts: ["localhost:7000"] metrics_path: /metrics username: "metrics" password: "secret" use_types: true rate_counters: true
- 为了提高安全性,您应该将用户名和密码添加到密钥库中,并在配置中引用两者。
- 启动 Metricbeat。
sudo service metricbeat start
如果您使用 init.d 脚本启动 Metricbeat,则无法指定命令行标志(请参见命令参考)。要指定标志,请在前景中启动 Metricbeat。
另请参见Metricbeat 和 systemd。
sudo service metricbeat start
如果您使用 init.d 脚本启动 Metricbeat,则无法指定命令行标志(请参见命令参考)。要指定标志,请在前景中启动 Metricbeat。
另请参见Metricbeat 和 systemd。
|
您将以 root 用户身份运行 Metricbeat,因此您需要更改配置文件的所有权,或者使用指定的 |
|
您将以 root 用户身份运行 Metricbeat,因此您需要更改配置文件的所有权,或者使用指定的 |
PS C:\Program Files\metricbeat> Start-Service metricbeat
默认情况下,Windows 日志文件存储在 C:\ProgramData\metricbeat\Logs 中。
在 Windows 上,目前不捕获有关系统负载和交换使用情况的统计信息。
验证 Prometheus 事件是否正在流入 Elasticsearch。
GET metricbeat-*/_search?filter_path=**.prometheus,hits.total
{
"query": {
"term": {
"event.module": "prometheus"
}
}
}
步骤 6:在 Kibana 中查看指标
编辑由于这是来自我们 Javalin 应用程序的自定义数据,因此没有预定义的仪表板来显示此数据。
让我们检查每个日志级别的日志消息数量。
GET metricbeat-*/_search
{
"query": {
"exists": {
"field": "prometheus.log4j2_events_total.counter"
}
}
}
可视化一段时间内的日志消息数量,按日志级别细分。自 Elastic Stack 7.7 以来,有一种创建名为 Lens 的可视化的新方法。
- 登录 Kibana 并选择可视化 → 创建可视化。
-
创建一个折线图,并选择
metricbeat-*作为数据源。基本思想是在 y 轴上对
prometheus.log4j2_events_total.rate字段进行最大聚合,而 x 轴则使用@timestamp字段上的date_histogram 聚合按日期划分。在每个日期直方图桶内还有一个细分,使用
prometheus.labels.level(包含日志级别)上的terms 聚合按日志级别细分。此外,将日志级别的 size 增加到六,以显示每个日志级别。最终结果如下所示。
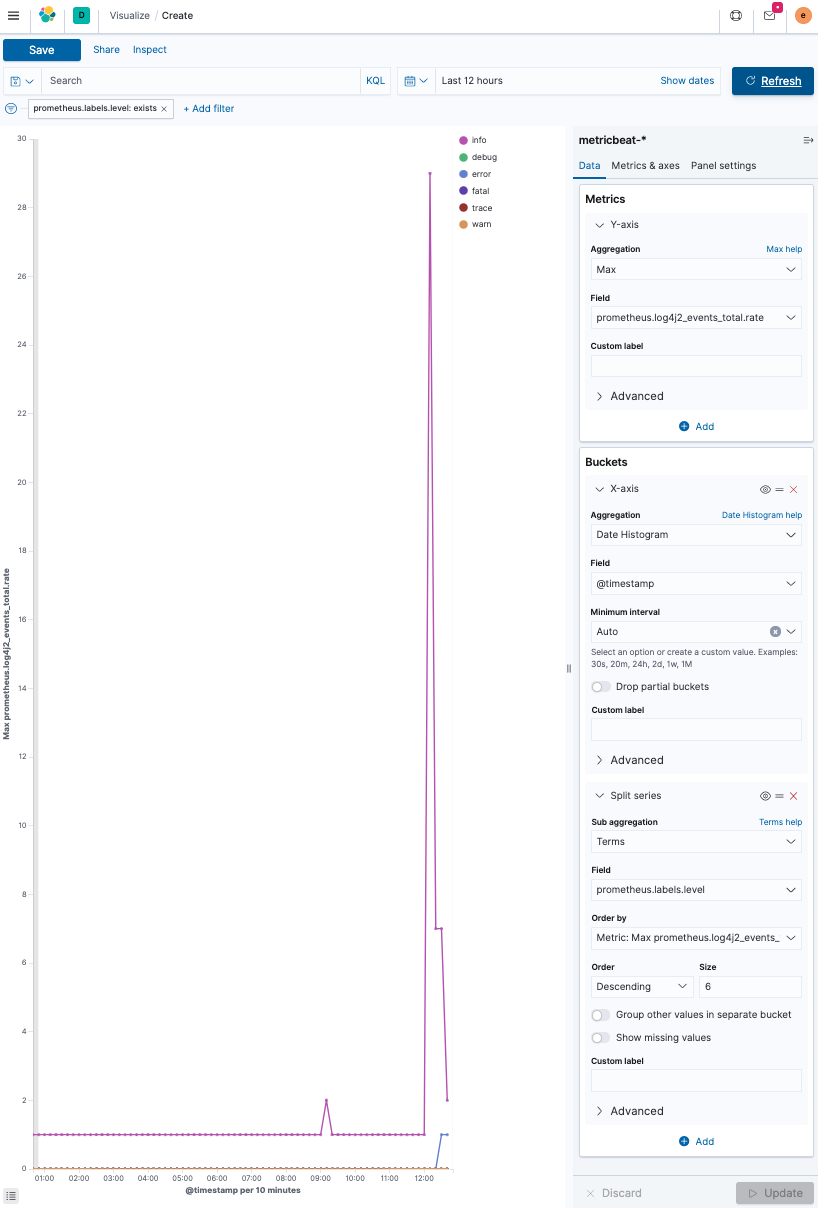
可视化一段时间内的打开文件
编辑第二个可视化是检查应用程序中打开的文件数量。
由于没有人能够记住所有字段名称,让我们再次首先查看指标输出。
curl -s localhost:7000/metrics -u metrics:secret | grep ^process process_files_max_files 10240.0 process_cpu_usage 1.8120711232436825E-4 process_uptime_seconds 72903.726 process_start_time_seconds 1.594048883317E9 process_files_open_files 61.0
让我们看看 process_files_open_files 指标。这应该是一个很少变化的静态值。如果您运行一个在 JVM 中存储数据或打开和关闭网络套接字的应用程序,则此指标会根据负载而增加和减少。对于 Web 应用程序,这相当静态。让我们弄清楚为什么我们的小型 Web 应用程序上打开了 60 个文件。
-
运行
jps,它将包含您在进程列表中的应用程序。$ jps 14224 Jps 82437 Launcher 82438 App 40895
-
对该进程使用
lsof。$ lsof -p 82438
您将看到比所有打开的文件更多的输出,因为文件也是当前正在发生的 TCP 连接。
-
添加一个端点以通过具有长时间运行的 HTTP 连接来增加打开的文件数量(每个连接也被视为打开的文件,因为它需要文件描述符),然后针对它运行
wrk。... import java.util.concurrent.CompletableFuture; import java.util.concurrent.Executor; import java.util.concurrent.TimeUnit; ... public static void main(String[] args) { ... final Executor executor = CompletableFuture.delayedExecutor(20, TimeUnit.SECONDS); app.get("/wait", ctx -> { CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "done", executor); ctx.result(future); }); ...每个 future 都会延迟 20 秒,这意味着单个 HTTP 请求会保持打开状态 20 秒。
-
让我们运行
wrk工作负载。wrk -c 100 -t 20 -d 5m https://127.0.0.1:7000/wait
结果显示仅发送了 20 个请求,鉴于处理时间,这是有道理的。
现在让我们使用 Kibana 中的Lens构建可视化。
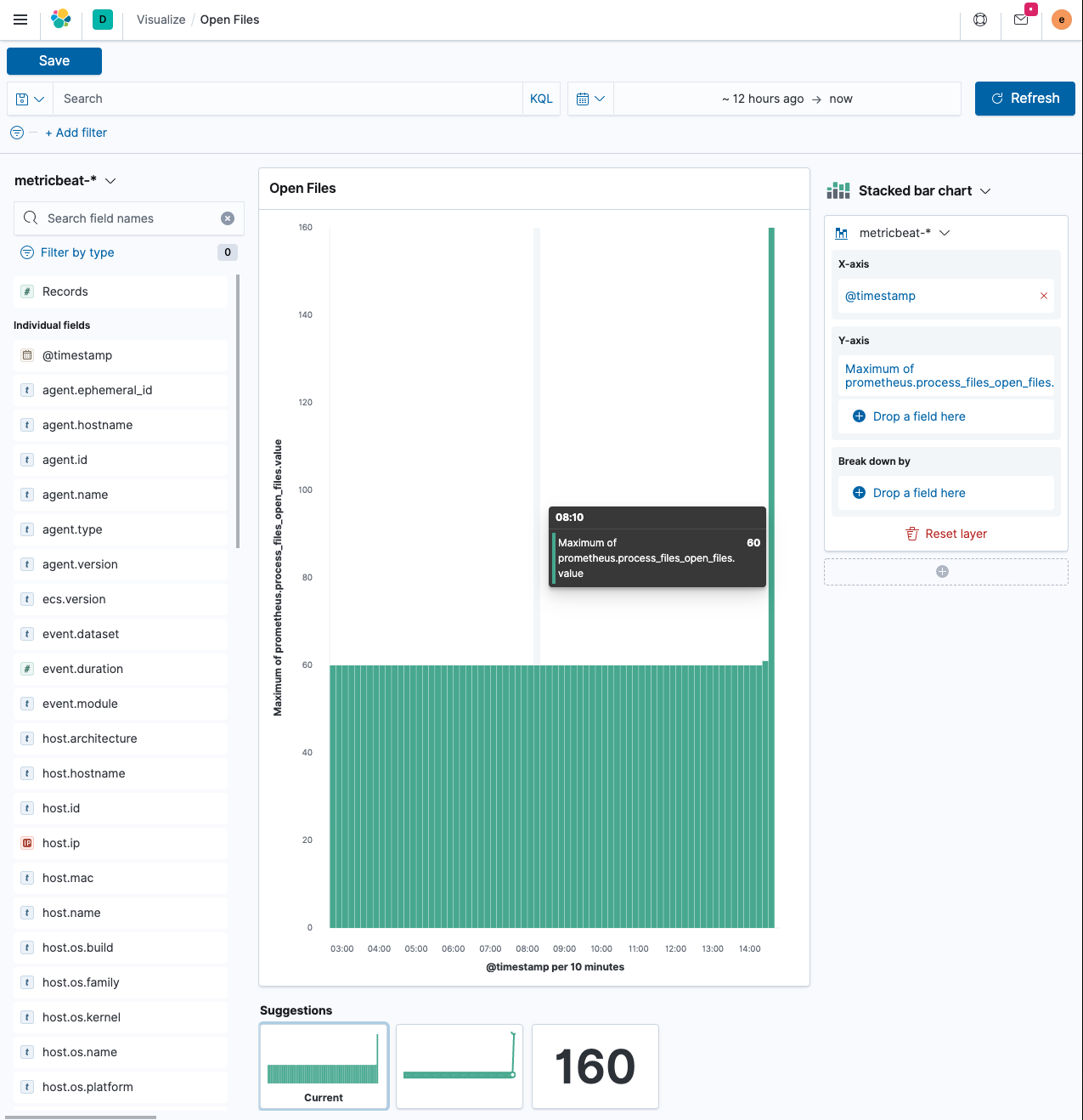
-
在
添加过滤器下,选择metricbeat-*索引模式。这可能会使用filebeat-*作为默认值。x 轴使用
@timestamp字段 - 这反过来将再次创建一个date_histogram聚合。y 轴不应该是文档计数,因为该计数始终稳定,而是桶中文档的最大值。单击 y 轴上字段名称的右侧,然后选择Max。这将为您提供与所示类似的可视化效果,在您运行上面的wrk命令的地方有一个峰值。 -
现在让我们看看 Kibana 中的 Infrastructure 应用程序。选择可观察性 → 基础设施。
您只会看到来自单个发件人的数据。尽管如此,如果您运行多个服务并且能够按 Kubernetes pod 或主机分组,您就可以发现 CPU 或内存消耗高的主机。
-
单击指标资源管理器,您可以开始探索特定主机的数据或节点上的 CPU 使用情况。
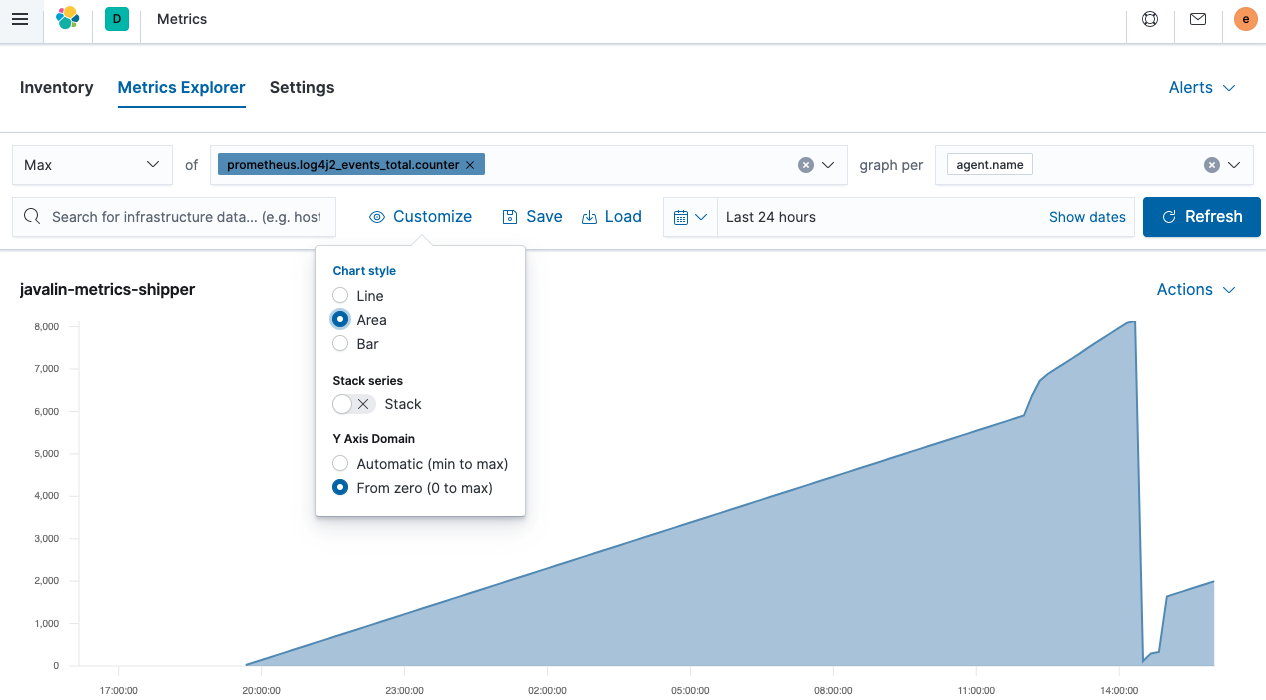
这是一个 Javalin 应用程序发出的总事件计数器的面积图。它正在上升,因为有一个组件正在轮询一个端点,该端点反过来会产生另一个日志消息。较陡峭的峰值是由于发送了更多请求。但是突然下降是从哪里来的呢?JVM 重新启动。由于这些指标不会持久保存,因此它们会在 JVM 重新启动时重置。考虑到这一点,通常最好记录
rate而不是counter字段。
步骤 7:检测应用程序
编辑可观察性的第三个部分是应用程序性能管理 (APM)。APM 设置包括一个接受数据的 APM 服务器(已在我们 Elastic Cloud 设置中运行)和一个将数据传递到服务器的代理。
该代理有两个任务:检测 Java 应用程序以提取应用程序性能信息并将该数据发送到 APM 服务器。
APM 的核心思想之一是能够跟踪用户会话在整个堆栈中的流程,无论您有几十个微服务还是一个单体来响应您的用户请求。这意味着能够在整个堆栈中标记请求。
为了完全捕获用户活动,您需要从使用真实用户监控 (RUM) 的用户浏览器开始,一直到您的应用程序,该应用程序向您的数据库发送 SQL 查询。
数据模型
编辑尽管 APM 环境高度分散,但术语通常相似。两个最重要的术语是跨度和事务。
事务封装了一系列跨度,其中包含有关代码片段执行的信息。让我们看看 Kibana Applications UI 的此屏幕截图。
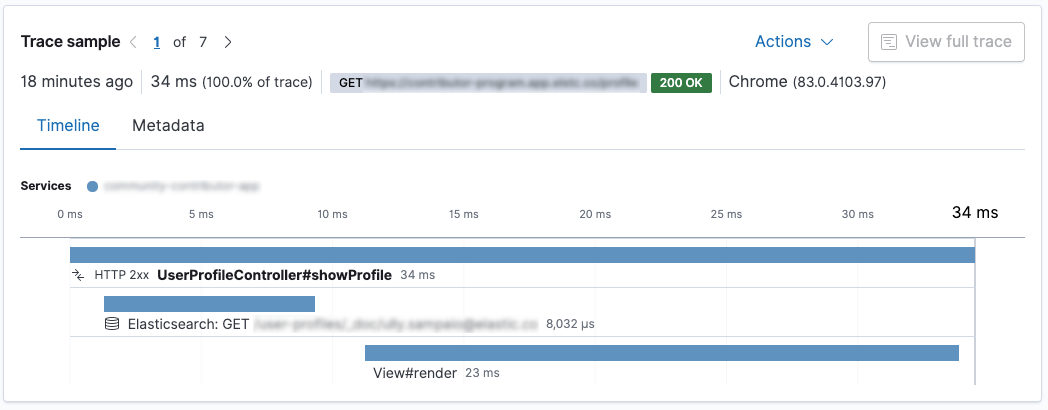
这是一个 Spring Boot 应用程序。调用了 UserProfileController.showProfile() 方法,该方法标记为事务。里面有两个跨度。首先,使用 Elasticsearch REST 客户端向 Elasticsearch 发送请求,响应呈现后使用 Thymeleaf。在这种情况下,对 Elasticsearch 的请求比呈现更快。
Java APM 代理可以自动检测特定框架。Spring 和 Spring Boot 得到很好的支持,上述数据是通过将代理添加到 Spring Boot 应用程序创建的;无需任何配置。
目前有 Go、.NET、Node、Python、Ruby 和浏览器 (RUM) 的代理。代理不断添加,因此您可能需要检查APM 代理文档。
将 APM 代理添加到您的代码中
编辑您可以通过两种方式将 Java 代理检测添加到您的应用程序。
首先,您可以在调用 java 二进制文件时通过参数添加代理。这样,它不会干扰应用程序的打包。此机制在启动时检测应用程序。
首先,下载代理,您可以检查最新的版本。
wget https://repo1.maven.org/maven2/co/elastic/apm/elastic-apm-agent/1.17.0/elastic-apm-agent-1.17.0.jar
指定启动时的代理以及将 APM 数据发送到的位置的配置参数。在启动 Java 应用程序之前,让我们获取在 Elastic Cloud 中运行的 APM 服务器的 API 密钥。
当您在 Elastic Cloud 中检查您的部署并单击左侧的 APM 时,您将看到 APM Server Secret Token,您可以使用它。您也可以从此处复制 APM 端点 URL。
java -javaagent:/path/to/elastic-apm-agent-1.17.0.jar\ -Delastic.apm.service_name=javalin-app \ -Delastic.apm.application_packages=de.spinscale.javalin \ -Delastic.apm.server_urls=$APM_ENDPOINT_URL \ -Delastic.apm.secret_token=PqWTHGtHZS2i0ZuBol \ -jar build/libs/javalin-app-all.jar
您现在可以继续打开 Applications UI,您应该会看到数据流入。
自动附加
编辑如果您不想更改应用程序的启动选项,则独立代理允许您附加到主机上正在运行的 JVM。
这要求您下载独立的 jar 文件。您可以在官方文档中找到链接。
要列出您本地运行的 Java 应用程序,您可以运行
java -jar /path/to/apm-agent-attach-1.17.0-standalone.jar --list
由于我通常在我的系统上运行多个 Java 应用程序,因此我需要指定要附加到的应用程序。此外,请确保您已停止带有已附加代理的 Javalin 应用程序,然后只需启动一个未配置附加代理的常规 Javalin 应用程序。
java -jar /tmp/apm-agent-attach-1.17.0-standalone.jar --pid 30730 \ --config service_name=javalin-app \ --config application_packages=de.spinscale.javalin \ --config server_urls=$APM_ENDPOINT_URL \ --config secret_token=PqWTHGtHZS2i0ZuBol
上述消息将返回类似以下内容
2020-07-10 15:04:48.144 INFO Attaching the Elastic {apm-agent} to 30730
2020-07-10 15:04:49.649 INFO Done
现在,代理已使用特殊配置附加到正在运行的应用程序。
虽然前两种方法都有效,但您也可以使用第三种方法:将 APM 代理作为直接依赖项。这允许您在我们的应用程序中编写自定义跨度和事务。
编程设置
编辑编程设置允许您通过在源代码中添加一行 Java 代码来附加代理。
-
添加 Java 代理依赖项。
dependencies { ... implementation 'co.elastic.apm:apm-agent-attach:1.17.0' ... } -
在我们的
main()方法中,立即为应用程序添加检测功能。import co.elastic.apm.attach.ElasticApmAttacher; ... public static void main(String[] args) { ElasticApmAttacher.attach(); ... }我们尚未配置任何端点或 API 令牌。文档 建议使用
src/main/resources/elasticapm.properties文件,但我更喜欢使用环境变量,因为这可以防止将 API 令牌提交到您的源代码或合并另一个存储库。像 vault 这样的机制允许您以这种方式管理您的密钥。对于我的本地部署,我通常使用类似 direnv 的工具进行本地设置。
direnv是您本地 shell 的一个扩展,当您进入某个目录(例如您的应用程序目录)时,它会加载/卸载环境变量。direnv还可以执行更多操作,例如加载正确的 node/ruby 版本或将目录添加到您的 $PATH 变量。 -
要启用
direnv,您需要创建一个包含以下内容的.envrc文件。dotenv
这告诉
direnv将.env文件的内容作为环境变量加载。.env文件应如下所示ELASTIC_APM_SERVICE_NAME=javalin-app ELASTIC_APM_SERVER_URLS=https://APM_ENDPOINT_URL ELASTIC_APM_SECRET_TOKEN=PqWTHGtHZS2i0ZuBol
如果您不习惯将敏感数据放入
.env文件中,您可以使用 envchain 等工具,或在.envrc文件中调用任意命令,例如访问 Vault。 -
您现在可以像以前一样运行 Java 应用程序。
java -jar build/libs/javalin-app-all.jar
如果您想在 IDE 中运行它,您可以手动设置环境变量,或者搜索支持
.env文件的插件。等待几分钟,最后让我们看看 Applications UI。
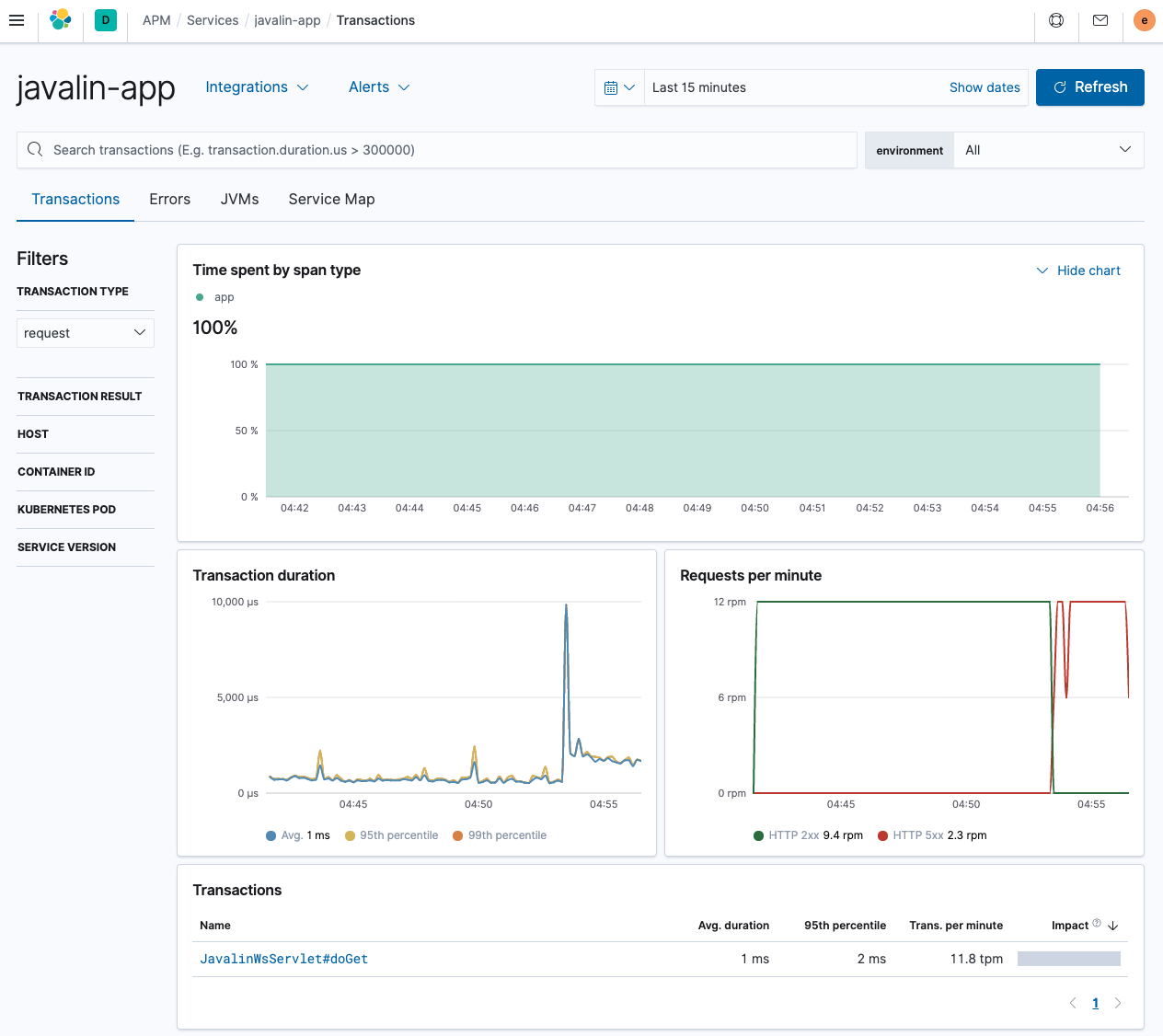
如您所见,这与前面显示的 Spring Boot 应用程序有很大不同。未列出不同的端点;但是,我们可以看到每分钟的请求数,包括错误。
唯一的事务来自单个 servlet,这不太有用。让我们尝试通过引入自定义编程事务来解决这个问题。
自定义事务
编辑-
添加另一个依赖项。
dependencies { ... implementation 'co.elastic.apm:apm-agent-attach:1.17.0' implementation 'co.elastic.apm:apm-agent-api:1.17.0' ... } -
修复事务名称以包含 HTTP 方法和请求路径
app.before(ctx -> ElasticApm.currentTransaction() .setName(ctx.method() + " " + ctx.path()));
-
重启您的应用程序并查看数据流。测试几个不同的端点,尤其是抛出异常的端点和触发 404 的端点。
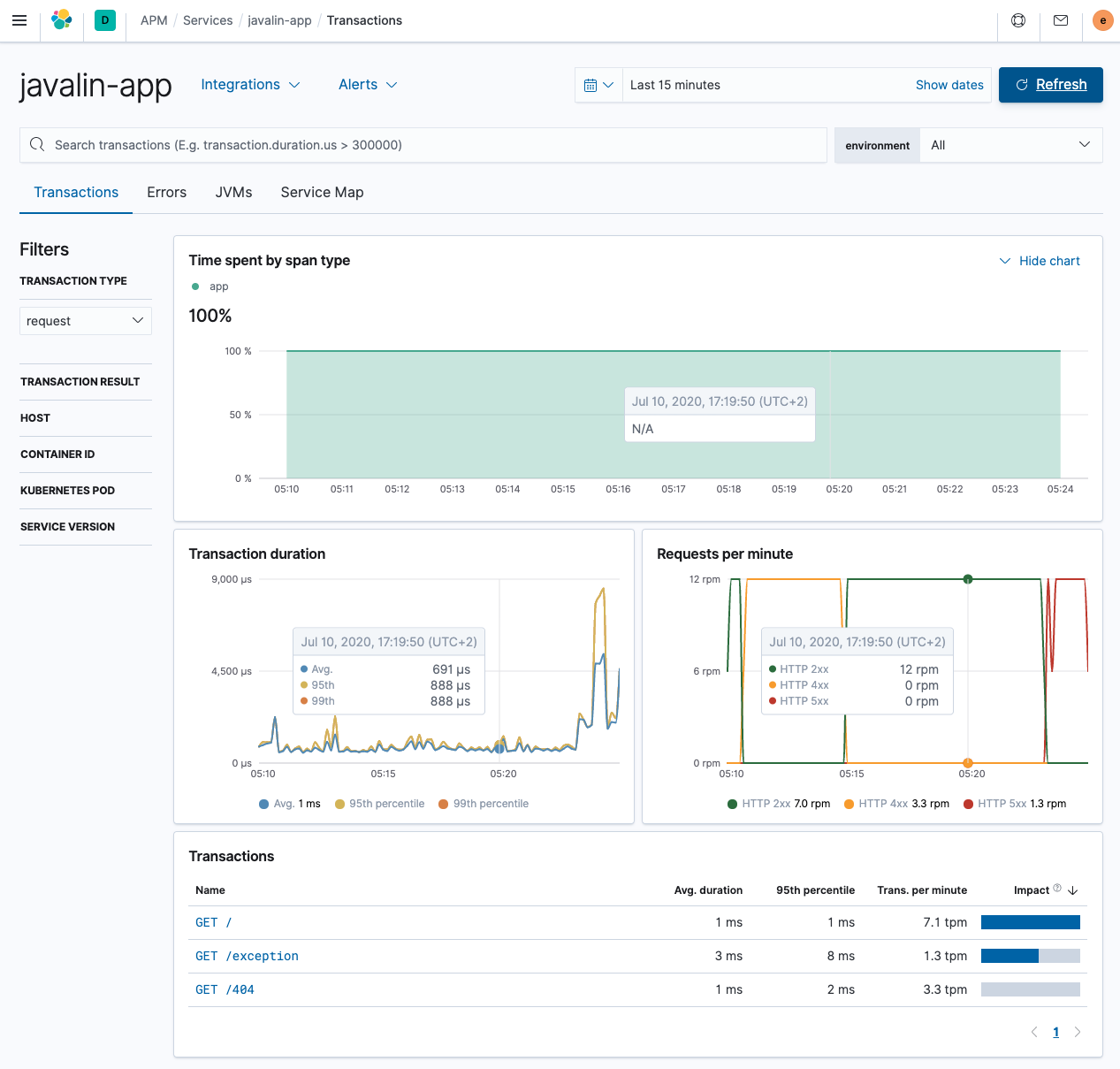
这样看起来好多了,端点之间存在差异。
-
添加另一个端点以查看事务的强大功能,该端点轮询另一个 HTTP 服务。您可能听说过 wttr.in,这是一个从该端点轮询天气信息的工具。让我们实现一个将请求转发到该端点的代理 HTTP 方法。让我们使用 Apache HTTP 客户端,这是最典型的 HTTP 客户端之一。
implementation 'org.apache.httpcomponents:fluent-hc:4.5.12'
这是我们的新端点。
import org.apache.http.client.fluent.Request; ... public static void main(String[] args) { ... app.get("/weather/:city", ctx -> { String city = ctx.pathParam("city"); ctx.result(Request.Get("https://wttr.in/" + city + "?format=3").execute() .returnContent().asBytes()) .contentType("text/plain; charset=utf-8"); }); ... -
使用 Curl 命令
https://127.0.0.1:7000/weather/Munich并查看关于当前天气的单行响应。让我们检查 APM UI。在概述中,您可以看到大部分时间都花在了 HTTP 客户端上,这并不奇怪。
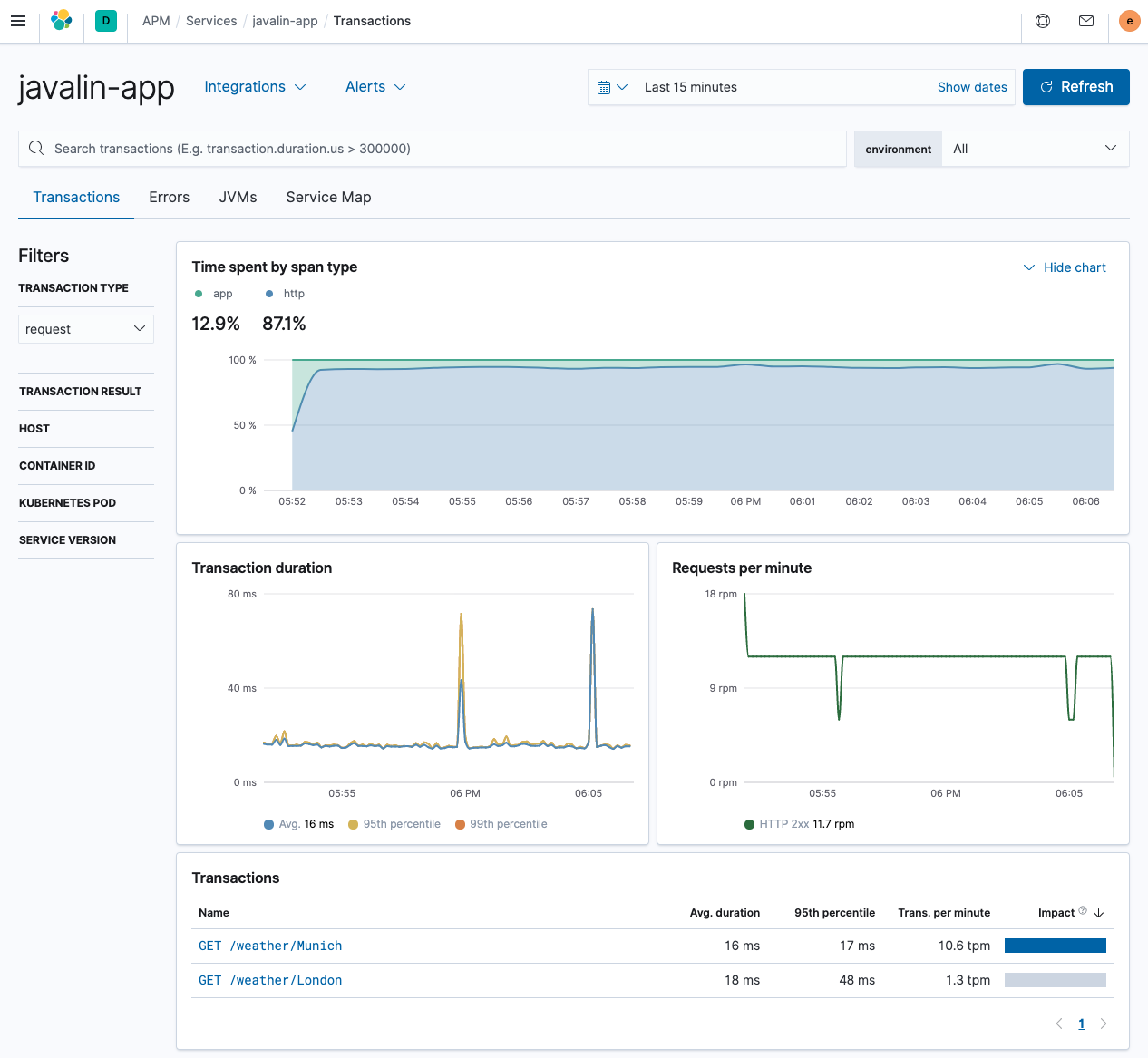
我们
/weather/Munich的事务现在包含一个跨度,显示了获取天气数据所花费的时间。由于 HTTP 客户端是自动检测的,因此无需执行任何操作。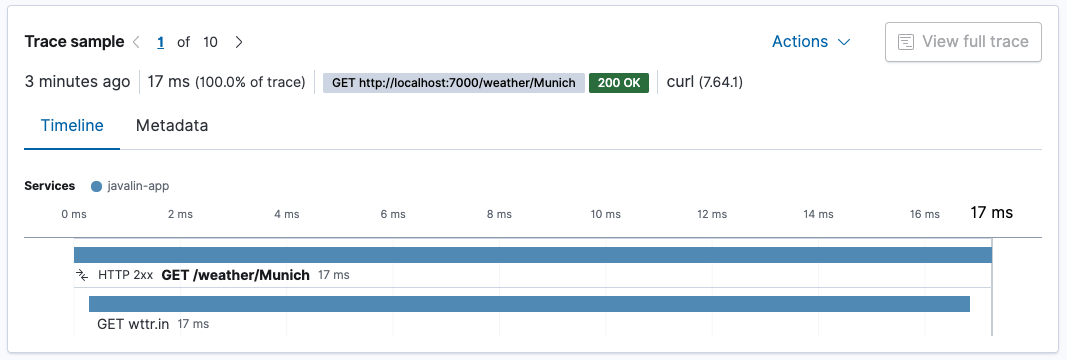
如果该 URL 的
city参数基数很高,这将导致提及大量 URL,而不是通用端点。如果您想防止这种情况,一种方法是使用ctx.matchedPath()将对天气 API 的每次调用记录为GET /weather/:city。但这需要一些重构工作,需要删除app.before()处理程序并将其替换为app.after()处理程序。app.after(ctx -> ElasticApm.currentTransaction().setName(ctx.method() + " " + ctx.endpointHandlerPath()));
通过代理配置进行方法追踪
编辑无需编写代码来追踪方法,您也可以配置代理来执行此操作。让我们尝试确定日志记录是否是应用程序的瓶颈,并追踪我们前面添加的请求日志记录语句。
代理可以根据其签名 追踪方法。
要监控的接口是 io.javalin.http.RequestLogger 接口以及 handle 方法。因此,让我们尝试使用 io.javalin.http.RequestLogger#handle 来识别要记录的方法,并将其放入您的 .env 文件中。
ELASTIC_APM_TRACE_METHODS="de.spinscale.javalin.Log4j2RequestLogger#handle"
-
创建一个专用的日志记录类以匹配上述追踪方法。
package de.spinscale.javalin; import io.javalin.http.Context; import io.javalin.http.RequestLogger; import org.jetbrains.annotations.NotNull; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class Log4j2RequestLogger implements RequestLogger { private final Logger logger = LoggerFactory.getLogger(Log4j2RequestLogger.class); @Override public void handle(@NotNull Context ctx, @NotNull Float executionTimeMs) throws Exception { String userAgent = ctx.userAgent() != null ? ctx.userAgent() : "-"; logger.info("{} {} {} {} \"{}\" {}", ctx.method(), ctx.req.getPathInfo(), ctx.res.getStatus(), ctx.req.getRemoteHost(), userAgent, executionTimeMs.longValue()); } } -
修复我们在
App类中的调用。config.requestLogger(new Log4j2RequestLogger());
-
重启您的应用程序,看看日志记录需要多长时间。
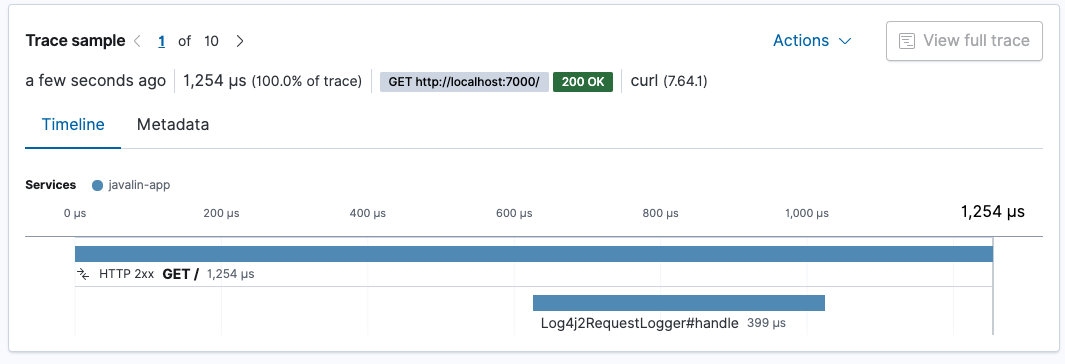
请求日志记录大约需要 400 微秒。整个请求大约需要 1.3 毫秒。大约三分之一的请求处理时间用于日志记录。
如果您正在寻求更快的服务,您可能需要重新考虑日志记录。但是,此日志记录是在结果写入客户端之后发生的,因此虽然总处理时间随着日志记录而增加,但对客户端的响应时间不会增加(但是关闭连接可能会)。还要注意,这些测试是在没有适当预热的情况下进行的。我认为在适当的 JVM 预热之后,您将拥有更快的请求处理速度。
推断跨度的自动性能分析
编辑一旦您的应用程序比我们的示例应用程序拥有更多代码路径,您可以尝试通过设置以下内容来启用 推断跨度的自动性能分析。
ELASTIC_APM_PROFILING_INFERRED_SPANS_ENABLED=true
此机制使用 异步分析器 来创建跨度,而无需您进行任何检测,从而使您可以更快地找到瓶颈。
日志关联
编辑事务 ID 会自动添加到日志中。您可以检查通过 Filebeat 发送到 Elasticsearch 的生成的日志文件。条目如下所示。
{
"@timestamp": "2020-07-13T12:03:22.491Z",
"log.level": "INFO",
"message": "GET / 200 0:0:0:0:0:0:0:1 \"curl/7.64.1\" 0",
"service.name": "my-javalin-app",
"event.dataset": "my-javalin-app.log",
"process.thread.name": "qtp34871826-36",
"log.logger": "de.spinscale.javalin.Log4j2RequestLogger",
"trace.id": "ed735860ec0cd3ee3bdf80ed7ea47afb",
"transaction.id": "8af7dff698937dc5"
}
添加了 trace.id 和 transaction.id,如果发生错误,您将获得一个 error.id 字段。
我们尚未介绍 Elastic APM OpenTracing 桥接,也没有查看代理提供的 其他指标,这使我们能够查看诸如垃圾收集或应用程序的内存占用量等内容。
步骤 8:摄取正常运行时间数据
编辑到目前为止,我们的应用程序具有一些基本的监控功能。我们索引日志(带有跟踪)、索引指标,我们甚至可以通过 APM 查看应用程序以找出单个性能瓶颈。但是,仍然存在一个弱点。到目前为止所做的一切都在应用程序内部,但所有用户都是通过互联网访问应用程序的。
如何检查我们的用户是否拥有与我们的 APM 数据建议相同的体验。想象一下,有一个滞后的负载均衡器位于您的应用程序前面,这会使每个请求额外花费 50 毫秒。这将是毁灭性的。或者 TLS 协商成本很高。即使这些外部事件都不是您的错,您仍然会受到影响,应该尝试减轻这些影响。这意味着您需要首先了解它们。
正常运行时间 不仅使您可以监控服务的可用性,还可以绘制一段时间内的延迟图表,并接收有关 TLS 证书到期的通知。
设置
编辑要将正常运行时间数据发送到 Elasticsearch,需要 Heartbeat(轮询组件)。要下载和安装 Heartbeat,请使用适合您系统的命令
curl -L -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-8.16.0-amd64.deb sudo dpkg -i heartbeat-8.16.0-amd64.deb
curl -L -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-8.16.0-x86_64.rpm sudo rpm -vi heartbeat-8.16.0-x86_64.rpm
curl -L -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-8.16.0-darwin-x86_64.tar.gz tar xzvf heartbeat-8.16.0-darwin-x86_64.tar.gz
curl -L -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-8.16.0-linux-x86_64.tar.gz tar xzvf heartbeat-8.16.0-linux-x86_64.tar.gz
- 从 下载页面 下载 Heartbeat Windows zip 文件。
- 将 zip 文件的内容解压缩到
C:\Program Files。 - 将
heartbeat-<version>-windows目录重命名为Heartbeat。 - 以管理员身份打开 PowerShell 提示符(右键单击 PowerShell 图标并选择以管理员身份运行)。
-
从 PowerShell 提示符下,运行以下命令将 Heartbeat 安装为 Windows 服务
PS > cd 'C:\Program Files\Heartbeat' PS C:\Program Files\Heartbeat> .\install-service-heartbeat.ps1
如果您的系统禁用了脚本执行,则需要将当前会话的执行策略设置为允许脚本运行。例如:PowerShell.exe -ExecutionPolicy UnRestricted -File .\install-service-heartbeat.ps1。
下载并解压后,我们必须再次设置云 ID 和密码。
-
我们需要在 Kibana 中以 elastic 管理员用户的身份创建另一个
API_KEY。POST /_security/api_key { "name": "heartbeat_javalin-app", "role_descriptors": { "heartbeat_writer": { "cluster": ["monitor", "read_ilm"], "index": [ { "names": ["heartbeat-*"], "privileges": ["view_index_metadata", "create_doc"] } ] } } } -
让我们设置 Heartbeat 密钥库并运行设置。
./heartbeat keystore create echo -n "observability-javalin-app:ZXUtY2VudHJhbC0xLmF3cy5jbG91ZC5lcy5pbyQ4NDU5M2I1YmQzYTY0N2NhYjA2MWQ3NTJhZWFhNWEzYyQzYmQwMWE2OTQ2MmQ0N2ExYjdhYTkwMzI0YjJiOTMyYQ==" | ./heartbeat keystore add CLOUD_ID --stdin echo -n "SCdUSHMB1JmLUFPLgWAY:R3PQzBWW3faJT01wxXD6uw" | ./heartbeat keystore add ES_API_KEY --stdin ./heartbeat setup -e -E 'cloud.id=${CLOUD_ID}' -E 'cloud.auth=elastic:YOUR_SUPER_SECRET_PASS' -
添加一些要监控的服务。
name: heartbeat-shipper cloud.id: ${CLOUD_ID} output.elasticsearch: api_key: ${ES_API_KEY} heartbeat.monitors: - type: http id: javalin-http-app name: "Javalin Web Application" urls: ["https://127.0.0.1:7000"] check.response.status: [200] schedule: '@every 15s' - type: http id: httpbin-get name: "httpbin GET" urls: ["https://httpbin.org/get"] check.response.status: [200] schedule: '@every 15s' - type: tcp id: javalin-tcp name: "TCP Port 7000" hosts: ["localhost:7000"] schedule: '@every 15s' processors: - add_observer_metadata: geo: name: europe-munich location: "48.138791, 11.583030" - 现在启动 Heartbeat 并等待几分钟以获取一些数据。
sudo service heartbeat start
如果您使用 init.d 脚本启动 Heartbeat,则无法指定命令行标志(请参阅 命令参考)。要指定标志,请在前景中启动 Heartbeat。
另请参阅 Heartbeat 和 systemd。
sudo service heartbeat start
如果您使用 init.d 脚本启动 Heartbeat,则无法指定命令行标志(请参阅 命令参考)。要指定标志,请在前景中启动 Heartbeat。
另请参阅 Heartbeat 和 systemd。
|
您将以 root 用户身份运行 Heartbeat,因此您需要更改配置文件的所有权,或者使用指定的 |
|
您将以 root 用户身份运行 Heartbeat,因此您需要更改配置文件的所有权,或者使用指定的 |
PS C:\Program Files\heartbeat> Start-Service heartbeat
默认情况下,Windows 日志文件存储在 C:\ProgramData\heartbeat\Logs 中。
要查看正常运行时间应用程序,请选择 可观察性 → 正常运行时间。概述如下所示。
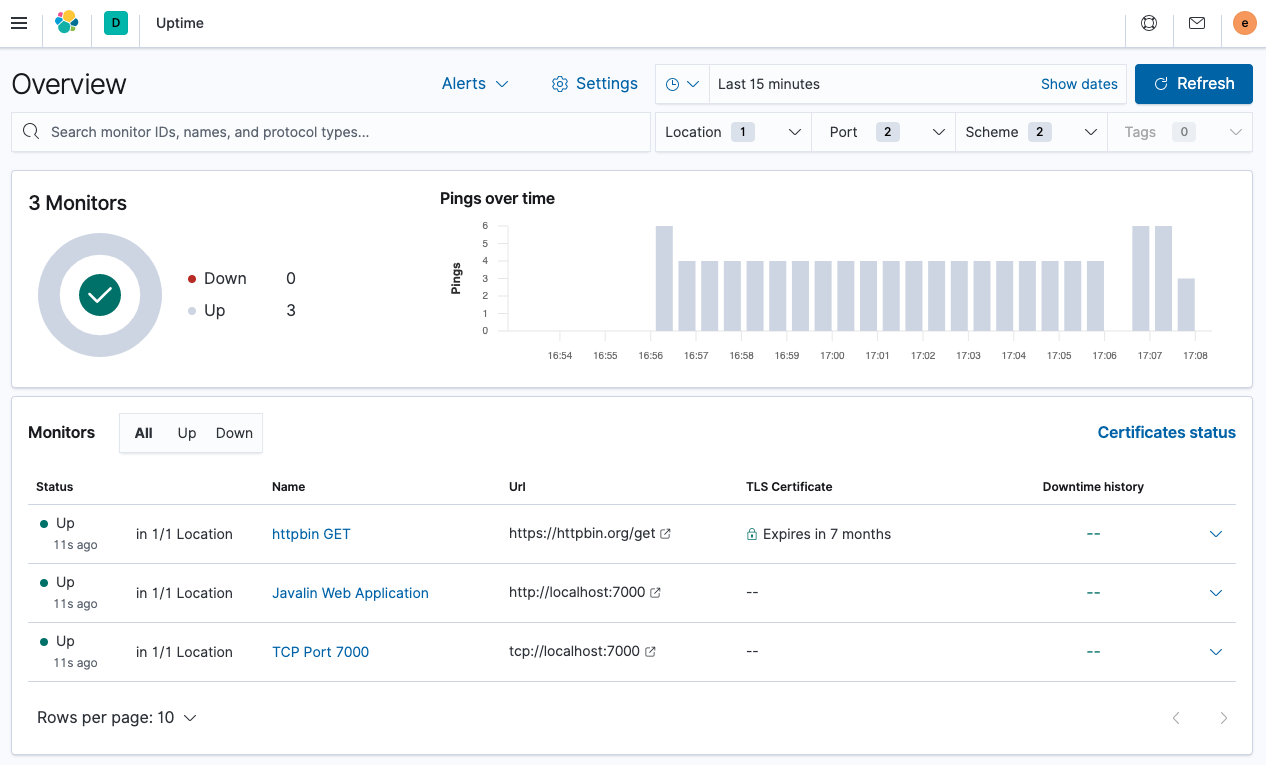
您可以看到监视器的列表和全局概述。让我们查看其中一个警报的详细信息。单击 Javalin Web 应用程序。
您可以看到上次计划检查的执行情况,但每次检查的持续时间可能更有趣。您可以查看检查之一的延迟是否正在上升。
有趣的部分是顶部的世界地图。您可以在配置中指定检查的来源,在本例中是欧洲慕尼黑。通过配置在全球运行的多个 Heartbeat,您可以比较延迟并找出需要运行应用程序以靠近用户的哪个数据中心。
监控时长在毫秒级,非常快速。检查指向httpbin.org端点的监控,您会看到更高的时长。在这种情况下,每次请求大约需要400毫秒。这并不令人意外,因为该端点不在本地,并且每次请求都需要启动TLS连接,这比较耗时。
不要低估这种监控的重要性。此外,这仅仅是开始,下一步是使用合成监控来监控应用程序的正确行为,例如,确保您的结账流程始终有效。
下一步是什么?
编辑有关使用 Elastic 可观测性的更多信息,请参阅可观测性文档。