过滤和聚合日志
编辑过滤和聚合日志
编辑过滤和聚合您的日志数据,以查找特定信息、获得洞察力并更有效地监控您的系统。您可以根据结构化字段(如时间戳、日志级别和 IP 地址)进行过滤和聚合,这些字段是从您的日志数据中提取的。
本指南将向您展示如何:
开始之前
编辑本页上的示例使用以下摄取管道和索引模板,您可以在 开发人员工具 中设置它们。如果您尚未使用摄取管道和索引模板来解析您的日志数据并提取结构化字段,请从 解析和组织日志 文档开始。
使用以下命令设置摄取管道:
PUT _ingest/pipeline/logs-example-default
{
"description": "Extracts the timestamp log level and host ip",
"processors": [
{
"dissect": {
"field": "message",
"pattern": "%{@timestamp} %{log.level} %{host.ip} %{message}"
}
}
]
}
使用以下命令设置索引模板:
PUT _index_template/logs-example-default-template
{
"index_patterns": [ "logs-example-*" ],
"data_stream": { },
"priority": 500,
"template": {
"settings": {
"index.default_pipeline":"logs-example-default"
}
},
"composed_of": [
"logs-mappings",
"logs-settings",
"logs@custom",
"ecs@dynamic_templates"
],
"ignore_missing_component_templates": ["logs@custom"]
}
过滤日志
编辑使用您提取的字段来过滤您的数据,以便您可以专注于具有特定日志级别、时间戳范围或主机 IP 的日志数据。您可以以不同的方式过滤您的日志数据:
- 在日志浏览器中过滤日志 – 使用日志浏览器在 Kibana 中过滤和可视化日志数据。
- 使用查询 DSL 过滤日志 – 使用查询 DSL 从开发人员工具中过滤日志数据。
在日志浏览器中过滤日志
编辑日志浏览器是一个 Kibana 工具,它根据集成和数据流自动提供您的日志数据视图。要打开 日志浏览器,请在 全局搜索字段中查找 日志浏览器。
在日志浏览器中,您可以使用搜索栏中的 Kibana 查询语言 (KQL) 来缩小日志浏览器中显示的日志数据范围。例如,您可能想调查特定时间范围内发生的事件。
向您的数据流添加一些具有不同时间戳和日志级别的日志:
- 要打开 控制台,请在 全局搜索字段中查找
开发工具。 - 在 控制台 选项卡中,运行以下命令:
POST logs-example-default/_bulk
{ "create": {} }
{ "message": "2023-09-15T08:15:20.234Z WARN 192.168.1.101 Disk usage exceeds 90%." }
{ "create": {} }
{ "message": "2023-09-14T10:30:45.789Z ERROR 192.168.1.102 Critical system failure detected." }
{ "create": {} }
{ "message": "2023-09-10T14:20:45.789Z ERROR 192.168.1.105 Database connection lost." }
{ "create": {} }
{ "message": "2023-09-20T09:40:32.345Z INFO 192.168.1.106 User logout initiated." }
在此示例中,让我们查找在 9 月 14 日或 15 日发生的日志级别为 WARN 或 ERROR 的日志。从日志浏览器:
-
在搜索栏中添加以下 KQL 查询,以筛选日志级别为
WARN或ERROR的日志:log.level: ("ERROR" or "WARN") -
单击当前时间范围,选择 绝对,并将 开始日期 设置为
2023 年 9 月 14 日 @ 00:00:00.000。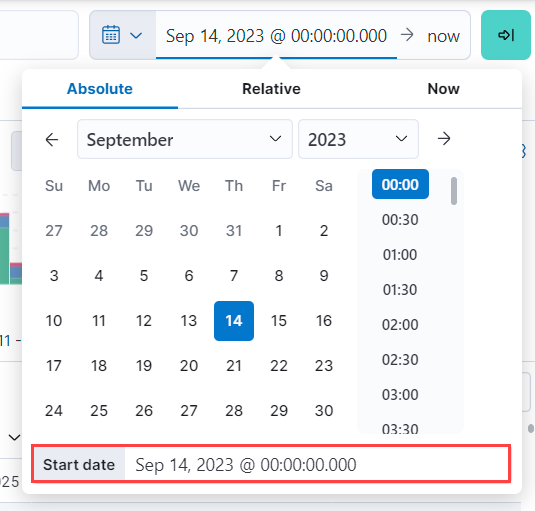
-
单击当前时间范围的结尾,选择 绝对,并将 结束日期 设置为
2023 年 9 月 15 日 @ 23:59:59.999。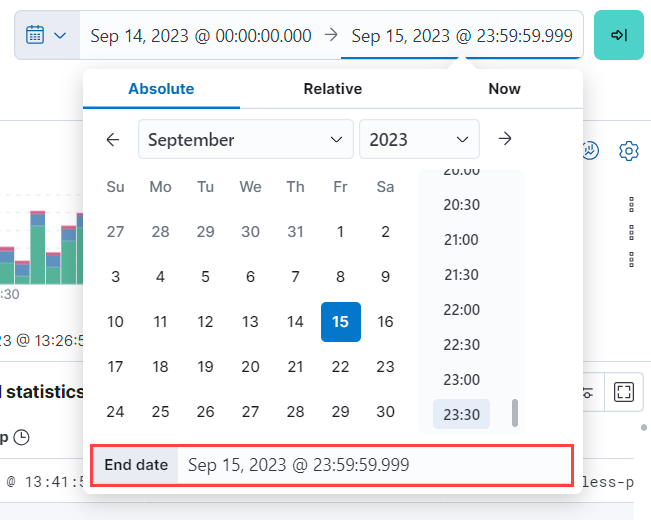
在 文档 选项卡下,您将看到与您的查询匹配的已过滤日志数据。
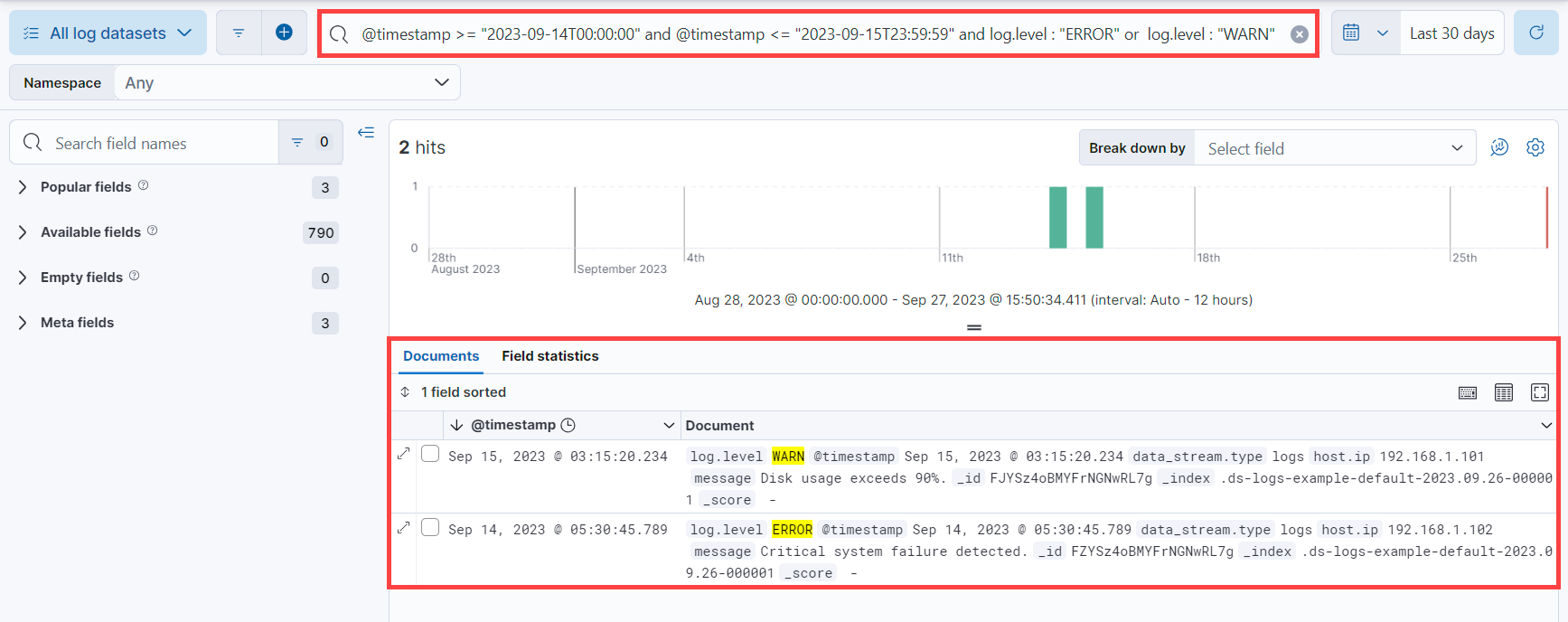
有关使用日志浏览器的更多信息,请参阅 Discover 文档。
使用查询 DSL 过滤日志
编辑查询 DSL 是一种基于 JSON 的语言,用于发送请求并从索引和数据流中检索数据。您可以使用 开发人员工具 中的查询 DSL 过滤您的日志数据。
例如,您可能想排查在特定日期或特定时间发生的问题。为此,请使用带有 范围查询 的布尔查询,以过滤特定的时间戳范围,并使用 术语查询 来过滤 WARN 和 ERROR 日志级别。
首先,从 开发人员工具 中,使用以下命令向您的数据流添加一些具有不同时间戳和日志级别的日志:
POST logs-example-default/_bulk
{ "create": {} }
{ "message": "2023-09-15T08:15:20.234Z WARN 192.168.1.101 Disk usage exceeds 90%." }
{ "create": {} }
{ "message": "2023-09-14T10:30:45.789Z ERROR 192.168.1.102 Critical system failure detected." }
{ "create": {} }
{ "message": "2023-09-10T14:20:45.789Z ERROR 192.168.1.105 Database connection lost." }
{ "create": {} }
{ "message": "2023-09-20T09:40:32.345Z INFO 192.168.1.106 User logout initiated." }
假设您想调查 9 月 14 日和 15 日之间发生的事件。以下布尔查询会筛选出在这些天的时间戳内且日志级别为 ERROR 或 WARN 的日志。
POST /logs-example-default/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"@timestamp": {
"gte": "2023-09-14T00:00:00",
"lte": "2023-09-15T23:59:59"
}
}
},
{
"terms": {
"log.level": ["WARN", "ERROR"]
}
}
]
}
}
}
过滤后的结果应显示在时间戳范围内发生的 WARN 和 ERROR 日志:
{
...
"hits": {
...
"hits": [
{
"_index": ".ds-logs-example-default-2023.09.25-000001",
"_id": "JkwPzooBTddK4OtTQToP",
"_score": 0,
"_source": {
"message": "192.168.1.101 Disk usage exceeds 90%.",
"log": {
"level": "WARN"
},
"@timestamp": "2023-09-15T08:15:20.234Z"
}
},
{
"_index": ".ds-logs-example-default-2023.09.25-000001",
"_id": "A5YSzooBMYFrNGNwH75O",
"_score": 0,
"_source": {
"message": "192.168.1.102 Critical system failure detected.",
"log": {
"level": "ERROR"
},
"@timestamp": "2023-09-14T10:30:45.789Z"
}
}
]
}
}
聚合日志
编辑使用聚合来分析和汇总您的日志数据,以查找模式并获得洞察力。存储桶聚合将日志数据组织成有意义的组,从而更容易识别日志中的模式、趋势和异常情况。
例如,您可能想通过分析每个日志级别的日志计数来了解错误分布。
首先,从 开发人员工具 中,使用以下命令向您的数据流添加一些具有不同日志级别的日志:
POST logs-example-default/_bulk
{ "create": {} }
{ "message": "2023-09-15T08:15:20.234Z WARN 192.168.1.101 Disk usage exceeds 90%." }
{ "create": {} }
{ "message": "2023-09-14T10:30:45.789Z ERROR 192.168.1.102 Critical system failure detected." }
{ "create": {} }
{ "message": "2023-09-15T12:45:55.123Z INFO 192.168.1.103 Application successfully started." }
{ "create": {} }
{ "message": "2023-09-14T15:20:10.789Z WARN 192.168.1.104 Network latency exceeding threshold." }
{ "create": {} }
{ "message": "2023-09-10T14:20:45.789Z ERROR 192.168.1.105 Database connection lost." }
{ "create": {} }
{ "message": "2023-09-20T09:40:32.345Z INFO 192.168.1.106 User logout initiated." }
{ "create": {} }
{ "message": "2023-09-21T15:20:55.678Z DEBUG 192.168.1.102 Database connection established." }
接下来,运行此命令以使用 log.level 字段聚合您的日志数据:
POST logs-example-default/_search?size=0&filter_path=aggregations
{
"size": 0,
"aggs": {
"log_level_distribution": {
"terms": {
"field": "log.level"
}
}
}
}
结果应显示每个日志级别中的日志数:
{
"aggregations": {
"error_distribution": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "ERROR",
"doc_count": 2
},
{
"key": "INFO",
"doc_count": 2
},
{
"key": "WARN",
"doc_count": 2
},
{
"key": "DEBUG",
"doc_count": 1
}
]
}
}
}
您还可以组合聚合和查询。例如,您可能想通过添加范围查询来限制先前聚合的范围:
GET /logs-example-default/_search
{
"size": 0,
"query": {
"range": {
"@timestamp": {
"gte": "2023-09-14T00:00:00",
"lte": "2023-09-15T23:59:59"
}
}
},
"aggs": {
"my-agg-name": {
"terms": {
"field": "log.level"
}
}
}
}
结果应显示在您的时间戳范围内发生的日志的聚合:
{
...
"hits": {
...
"hits": []
},
"aggregations": {
"my-agg-name": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "WARN",
"doc_count": 2
},
{
"key": "ERROR",
"doc_count": 1
},
{
"key": "INFO",
"doc_count": 1
}
]
}
}
}
有关聚合类型和可用聚合的更多信息,请参阅 聚合 文档。