
可观测性不仅仅是监控;它是真正了解您的系统。为了实现这种全面的视图,从业者需要一个统一的可观测性解决方案,该解决方案原生结合了来自指标、日志、追踪以及至关重要的**持续分析**的见解。虽然指标、日志和追踪提供了有价值的见解,但它们无法回答最重要的“为什么”。持续分析信号就像放大镜,提供对系统隐藏复杂性的细粒度代码可见性。它们填补了其他数据源留下的空白,使您能够回答关键问题——为什么此追踪速度缓慢?代码中哪个位置存在瓶颈?
追踪提供“什么”和“哪里”——发生了什么以及在系统中的哪个位置。持续分析通过精确定位“为什么”并验证您关于“什么”的假设来完善这种理解。就像全身核磁共振扫描一样,Elastic 的全系统持续分析(由 eBPF 提供支持)揭示了系统中的未知未知数。这不仅包括您的代码,还包括由您的应用程序事务触发的第三方库和内核活动。这种全面的可见性提高了您的平均检测时间 (MTTD) 和平均恢复时间 (MTTR) KPI。
[相关文章: 为什么指标、日志和追踪还不够]
弥合持续分析和 OTel 追踪之间的断连
从历史上看,持续分析信号在很大程度上与 OpenTelemetry (OTel) 追踪断连。这里有一个令人兴奋的消息:我们正在弥合这一差距!我们正在引入持续分析信号和 OTel 追踪之间的原生关联,从 Java 开始。
想象一下:您正在排除性能问题,并发现了一个缓慢的追踪。全系统持续分析介入,就像对整个代码库和系统进行核磁共振扫描一样。它将罪魁祸首缩小到分布式追踪上下文中占用 CPU 时间的特定代码行。这使您能够以最小的努力和信心回答“为什么”的问题,所有操作都在相同的故障排除环境中进行。
此外,通过将持续分析与分布式追踪相关联,Elastic 可观测性客户可以衡量每个代码更改在服务和事务级别的云成本和 CO2 影响。
这个里程碑意义重大,特别是考虑到 OTel 社区最近的发展。随着 OTel 采用分析,以及 Elastic 向 OTel 捐赠业界最先进的基于 eBPF 的持续分析代理,我们正在为可观测性领域迎来一场变革——为 OTel 最终用户提供从用户空间中的追踪跨度到内核的关联系统可见性。
此外,实现这一目标,特别是对于 Java 而言,提出了重大挑战,并需要进行认真的工程研发。这篇博文将深入探讨这些挑战,探索我们在概念验证中考虑的方法,并解释我们如何得出可以轻松扩展到其他 OTel 语言代理的解决方案。最重要的是,此解决方案在代理级别而不是在后端将追踪与分析信号相关联——以确保最佳的查询性能并最大程度地减少对供应商后端存储架构的依赖。
确定活动的 OTel 追踪和跨度
此项工作的首要技术挑战本质上是以下内容:每当分析器中断一个 OTel 检测的过程以捕获堆栈跟踪时,我们需要能够高效地确定活动的跨度和追踪 ID(每个线程)以及服务名称(每个进程)。
为了本文的目的,我们将重点关注最近发布的 OTel Java 检测的 Elastic 发行版,但我们最终采用的方法可以推广到任何可以加载并调用本机库的语言。那么,我们如何获取这些 ID 呢?
OTel Java 代理本身通过将跨度堆栈存储在 OpenTelemetryContext 中来跟踪活动的跨度,该跨度本身存储在 ThreadLocal 变量中。我们最初考虑直接从 BPF 读取这些 Java 结构,但最终放弃了这种方法。关于如何实现 ThreadLocal 没有记录在案的规范,并且可靠地读取和遵循 JVM 的内部数据结构会带来很高的维护负担。对 JVM 的任何小更新都可能更改结构布局的详细信息。此外,我们还必须逆向工程每个 JVM 版本如何在内存中布局 Java 类字段,以及上下文对象中使用的所有高级 Java 类型如何在底层实际实现。此方法进一步无法推广到任何非 JVM 语言,并且对于我们希望支持的任何语言都需要重复此操作。
在我们确信直接读取 Java ThreadLocal 不是答案之后,我们决定寻找更可移植的替代方案。我们最终确定的选项是加载并调用 C++ 库,该库负责在跨度更改时通过已知和定义的接口提供所需的信息。
与 Java 的 ThreadLocal 不同,关于本机共享库应如何公开每个进程和每个线程数据的详细信息在 System V ABI 规范和特定于架构的 ELF ABI 文档中得到了很好的定义。
公开每个进程的信息
公开每个进程的数据很容易:我们只需声明一个全局变量 。。。
void* elastic_tracecorr_process_storage_v1 = nullptr;
。。。并通过 ELF 符号公开它。当用户初始化 OTel 库以设置服务名称时,我们会分配一个缓冲区并使用 为此目的定义的协议 中的数据填充它。一旦缓冲区完全填充,我们就会更新全局指针以指向该缓冲区。
在性能分析代理端,我们已经有代码可以检测加载到任何进程地址空间中的库和可执行文件。我们通常使用此机制来检测和分析加载时的高级语言解释器(例如,libpython,libjvm),但事实证明它也非常适合检测 OTel 追踪关联库。当在进程中检测到该库时,我们会扫描其导出,解析符号,并直接从被检测进程的内存中读取每个进程的信息。
公开每个线程的信息
在完成了简单的部分之后,让我们进入最核心的部分:通过线程本地存储 (TLS) 公开每个线程的信息。那么,到底什么是 TLS,它是如何工作的?最基本的概念是为每个线程都有一个变量实例。在语义上,您可以将其视为拥有一个全局的 Map<ThreadID, T>,尽管它不是这样实现的。
在 Linux 上,线程本地存储主要有两种选择:TSD 和 TLS。
线程特定数据 (TSD)
TSD 是较旧且可能更广为人知的变体。它的工作原理是通过 pthread_key_create 显式地分配一个键 - 通常在进程启动期间 - 并将其传递给所有需要访问线程本地变量的线程。然后,线程可以将该键传递给 pthread_getspecific 和 pthread_setspecific 函数,以读取和更新当前正在运行的线程的变量。
TSD 很简单,但出于我们的目的,它有一系列的缺点
-
pthread_key_t 结构是不透明的,没有定义的布局。类似于 Java 的 ThreadLocals,底层数据结构不是由 ABI 文档定义的,不同的 libc 实现(glibc,musl)会以不同的方式处理它们。
-
我们无法从 BPF 调用像 pthread_getspecific 这样的函数,因此我们必须逆向工程并重新实现逻辑。逻辑可能会在 libc 版本之间发生变化,我们必须检测版本并支持所有可能在实际使用中出现的变体。
-
TSD 的性能是不可预测的,并且取决于先前在进程中已分配多少个线程本地变量。对于 Java 来说,这可能不是一个主要问题,因为 span 通常不会快速交换,但是对于用户模式调度语言来说,在每个等待点/协程 yield 时可能都需要切换上下文,这种情况可能会非常明显。
这些都不是严格禁止的,但至少有很多是令人烦恼的。让我们看看是否可以做得更好!
线程本地存储 (TLS)
从 C11 和 C++11 开始,这两种语言都分别通过 _Thread_local 和 thread_local 存储说明符直接支持线程本地变量。现在只需添加关键字就可以将变量声明为每个线程的变量
thread_local void* elastic_tracecorr_tls_v1 = nullptr;
您可能会认为,当访问以此声明的变量时,编译器只是插入对相应的 pthread 函数调用的调用,但事实并非如此。现实情况非常复杂,并且事实证明,编译器可以选择生成四种不同的 TLS 模型。对于某些模型,还有多种方言可用于实现它们。不同的模型和方言在可移植性和性能之间进行不同的权衡。如果您对细节感兴趣,我建议您阅读这篇博客文章,其中对此进行了很好的解释。
TLS 模型和方言通常由编译器根据一组有些不透明且复杂的特定于体系结构的规则选择。幸运的是,gcc 和 clang 都允许用户使用 -ftls-model 和 -mtls-dialect 参数选择特定的模型和方言。我们最终出于目的而选择的变体是 -ftls-model=global-dynamic 和 -mtls-dialect=gnu2 (以及 aarch64 上的 desc)。
让我们看一下在这些设置下访问 thread_local 变量时生成的汇编代码。我们的函数
void setThreadProfilingCorrelationBuffer(JNIEnv* jniEnv, jobject bytebuffer) {
if (bytebuffer == nullptr) {
elastic_tracecorr_tls_v1 = nullptr;
} else {
elastic_tracecorr_tls_v1 = jniEnv->GetDirectBufferAddress(bytebuffer);
}
}
被编译为以下汇编代码
两个可能的分支都为我们的线程本地变量赋值。让我们专注于对应于 nullptr 情况的右分支,以消除 GetDirectBufferAddress 函数调用产生的噪声
lea rax, elastic_tracecorr_tls_v1_tlsdesc ;; Load some pointer into rax.
call qword ptr [rax] ;; Read & call function pointer at rax.
mov qword ptr fs:[rax], 0 ;; Assign 0 to the pointer returned by
;; the function that we just called.
mov 指令的 fs: 部分是使内存读取每个线程的实际魔力位。稍后我们会讨论这一点;让我们首先看一下编译器在此处发出的神秘的 elastic_tracecorr_tls_v1_tlsdesc 变量。它是位于 .got.plt ELF 部分的 tlsdesc 结构的实例。该结构如下所示
struct tlsdesc {
// Function pointer used to retrieve the offset
uint64_t (*resolver)(tlsdesc*);
// TLS offset -- more on that later.
uint64_t tp_offset;
}
resolver 字段初始化为 nullptr,tp_offset 初始化为每个可执行文件的偏移量。可执行文件中的第一个线程本地变量通常具有偏移量 0,下一个是 sizeof(first_var),依此类推。乍一看,这可能类似于 TSD 的工作方式,调用 pthread_getspecific 来解析实际偏移量,但是存在一个关键的区别。当库加载时,加载器 (ld.so) 会用 __tls_get_addr 的地址填充 resolver 字段。__tls_get_addr 是一个相对繁重的函数,它会分配一个在进程中所有共享库之间全局唯一的 TLS 偏移量。然后,它会更新 tlsdesc 结构本身,插入全局偏移量,并将解析器函数替换为一个简单的函数
void* second_stage_resolver(tlsdesc* desc) {
return tlsdesc->tp_offset;
}
本质上,这意味着第一次访问基于 tlsdesc 的线程本地变量相当昂贵,但所有后续访问都很便宜。我们进一步知道,在我们的 C++ 库开始发布每个线程的数据时,它必须已经完成了初始解析过程。因此,我们所需要做的就是从进程的内存中读取最终偏移量并记住它。我们还会时不时地刷新偏移量,以确保我们确实拥有最终偏移量,从而避免我们读取偏移量时尚未初始化的不可能但可能发生的竞争条件。我们可以通过将解析器地址与 ld.so 导出的 __tls_get_addr 函数的地址进行比较来检测这种情况。
从外部进程确定 TLS 偏移量
解决了这个问题之后,接下来出现的问题是如何在内存中实际找到 tlsdesc,以便我们可以读取偏移量。直观地讲,人们可能期望 ELF 文件上导出的动态符号指向该描述符,但事实并非如此。
$ readelf --wide --dyn-syms elastic-jvmti-linux-x64.so | grep elastic_tracecorr_tls_v1
328: 0000000000000000 8 TLS GLOBAL DEFAULT 19 elastic_tracecorr_tls_v1
动态符号实际上包含相对于 .tls ELF 部分起点的偏移量,并指向 libc 在分配时初始化 TLS 值的初始值。那么 ld.so 如何找到 tlsdesc 来填充初始解析器呢?除了动态符号之外,编译器还会为我们的符号发出一个重定位记录,并且该记录实际上指向我们正在寻找的描述符结构。
$ readelf --relocs --wide elastic-jvmti-linux-x64.so | grep R_X86_64_TLSDESC
00000000000426e8 0000014800000024 R_X86_64_TLSDESC 0000000000000000
elastic_tracecorr_tls_v1 + 0
因此,要读取最终的 TLS 偏移量,我们只需执行以下操作
-
等待通知我们有关新共享库加载到进程中的事件
-
执行一些廉价的启发式方法来检测我们的 C++ 库,从而避免对系统上的每个不相关的库执行下面更昂贵的分析
-
分析磁盘上的库,并扫描 ELF 重定位以查找我们的每个线程变量,以提取 tlsdesc 地址
-
重新定位该地址以匹配我们的库在该特定进程中的加载位置
-
从 tlsdesc+8 读取偏移量
确定 TLS 基址
现在我们有了偏移量,如何使用它来实际读取库在那里为我们放置的数据呢?这使我们回到了我们之前讨论的 mov 指令的神奇 fs: 部分。在 X86 中,大多数内存操作数都可以选择性地提供一个段寄存器,该寄存器会影响地址转换。
段是 16 位 X86 早期的古老结构,当时它们用于扩展地址空间。本质上,该体系结构提供了一系列段寄存器,可以使用不同的基地址进行配置,从而允许访问超过 16 位内存。在 64 位处理器时代,这几乎不再是一个问题。实际上,X86-64(又名 AMD64)取消了除 fs 和 gs 之外的所有段寄存器。
那么为什么要保留其中两个呢?事实证明,它们对于线程本地数据的用例非常有用。由于可以配置每个线程以使其在这些段寄存器中具有自己的基地址,因此我们可以使用它来指向此特定线程的数据块。这正是 Linux 上的 libc 实现对 fs 段所做的事情。我们之前从进程内存中获取的偏移量用作 fs 段寄存器的地址,并且 CPU 会自动将其添加到每个线程的基地址。
要在内核中检索 fs 段寄存器指向的基地址,我们需要从内核的 task_struct 中读取我们碰巧用性能分析计时器事件中断的线程的目的地。获取 task_struct 很容易,因为我们有幸拥有 bpf_get_current_task BPF 辅助函数。BPF 辅助函数实际上是 BPF 程序的系统调用:我们可以直接要求 Linux 内核将指针交给我们。
有了任务指针,我们现在必须读取 thread.fsbase (X86-64) 或 thread.uw.tp_value (aarch64) 字段,以获取用户模式进程通过 fs 访问的所需基地址。至少如果我们希望支持没有 BTF 支持的旧内核(我们确实希望!),那么事情最后一次变得复杂起来。 task_struct 很大,并且存在数百个字段,这些字段是否出现取决于内核的配置方式。作为调度程序的内核原语,它还经常会因内核版本的不同而发生变化。在现代 Linux 发行版上,内核通常足够好,可以通过 BTF 告诉我们偏移量。在旧版本上,情况更加复杂。由于如果我们希望代码可移植,那么硬编码偏移量显然不是一种选择,因此我们必须自己找出偏移量。
我们通过查阅 /proc/kallsyms(一个包含内核函数及其地址之间映射的文件),然后使用 BPF 转储很少更改并使用所需偏移量的内核函数的编译代码来实现此目的。我们动态反汇编并分析该函数,并直接从汇编代码中提取偏移量。对于 X86-64,我们专门转储 aout_dump_debugregs 函数,该函数访问 thread->ptrace_bps,对于我们曾经看过的所有内核,该函数始终与我们感兴趣的 fsbase 字段相差 16 个字节。
从内核读取 TLS 数据
有了所有必需的偏移量,我们现在终于可以做我们最初打算做的事情了:使用它们来使用我们的 C++ 库为我们准备的 OTel 跟踪和 span ID 来丰富我们的堆栈跟踪!
void maybe_add_otel_info(Trace* trace) {
// Did user-mode insert a TLS offset for this process? Read it.
TraceCorrProcInfo* proc = bpf_map_lookup_elem(&tracecorr_procs, &trace->pid);
// No entry -> process doesn't have the C++ library loaded.
if (!proc) return;
// Load the fsbase offset from our global configuration map.
u32 key = 0;
SystemConfig* syscfg = bpf_map_lookup_elem(&system_config, &key);
// Read the fsbase offset from the kernel's task struct.
u8* fsbase;
u8* task = (u8*)bpf_get_current_task();
bpf_probe_read_kernel(&fsbase, sizeof(fsbase), task + syscfg->fsbase_offset);
// Use the TLS offset to read the **pointer** to our TLS buffer.
void* corr_buf_ptr;
bpf_probe_read_user(
&corr_buf_ptr,
sizeof(corr_buf_ptr),
fsbase + proc->tls_offset
);
// Read the information that our library prepared for us.
TraceCorrelationBuf corr_buf;
bpf_probe_read_user(&corr_buf, sizeof(corr_buf), corr_buf_ptr);
// If the library reports that we are currently in a trace, store it into
// the stack trace that will be reported to our user-land process.
if (corr_buf.trace_present && corr_buf.valid) {
trace->otel_trace_id.as_int.hi = corr_buf.trace_id.as_int.hi;
trace->otel_trace_id.as_int.lo = corr_buf.trace_id.as_int.lo;
trace->otel_span_id.as_int = corr_buf.span_id.as_int;
}
}
发送映射
从这里开始,一切都非常简单。C++ 库在启动时设置一个 Unix 数据报套接字,并通过每个进程的数据块将套接字路径传达给分析器。带有 OTel 跟踪和跨度 ID 注释的堆栈跟踪通过 perf 事件缓冲区从 BPF 发送到我们的用户模式分析器进程,该进程又将 OTel 跨度和跟踪之间的映射以及堆栈跟踪哈希值发送到 C++ 库。然后,我们对 OTel 检测框架的扩展会读取这些映射,并将堆栈跟踪哈希值插入到 OTel 跟踪中。
与另一种可能更明显的替代方案(即通过分析器的堆栈跟踪记录发送 OTel 跨度和跟踪 ID)相比,这种方法有几个主要优点。我们希望将堆栈跟踪关联存储在跟踪索引中,以便能够根据 OTel 跟踪上可用的众多字段来筛选和聚合堆栈跟踪。如果我们要通过分析器的 gRPC 连接发送跟踪 ID,则必须在分析收集器中搜索并更新相应的 OTel 跟踪记录,以插入堆栈跟踪哈希值。
这并非易事:堆栈跟踪发送频率相当高(截至撰写本文时,每 5 秒发送一次),并且相应的 OTel 跟踪可能尚未在我们集群中相应的堆栈跟踪到达时被发送和存储。我们必须构建一种延迟队列,并定期重试更新 OTel 跟踪文档,从而在收集器中引入可避免的数据库工作和复杂性。使用将堆栈跟踪映射发送到 OTel 检测过程的方法,则完全不需要服务器端合并。
跟踪关联的实际应用
完成所有繁重的工作后,让我们来看看跟踪关联在实际中的样子!
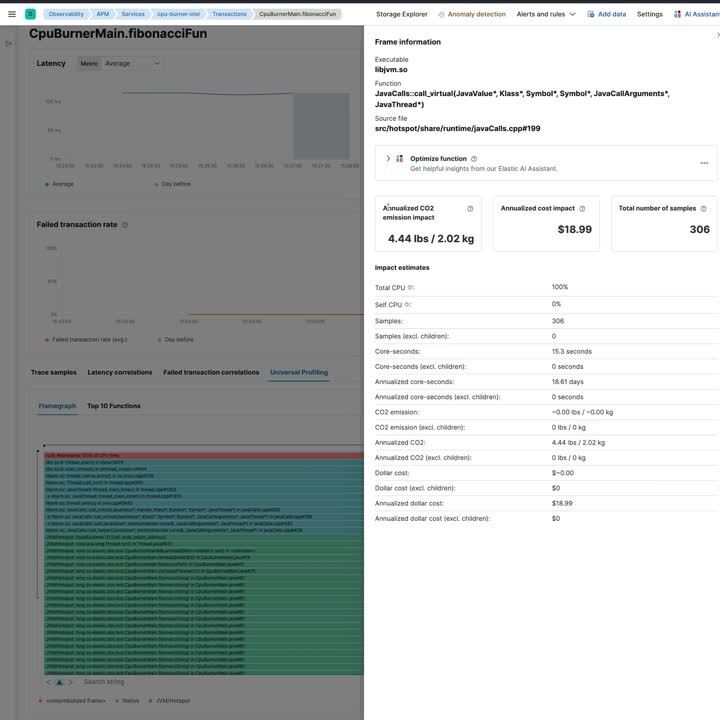
未来工作:支持其他语言
我们已经证明了跟踪关联在 Java 中可以很好地工作,但我们无意止步于此。我们之前讨论的通用方法应该适用于任何可以高效加载并调用我们的 C++ 库,并且不使用协程进行用户模式调度的语言。用户模式调度的问题在于,逻辑线程可以在任何 await/yield 点更改,从而需要我们在 TLS 中更新跟踪 ID。许多这样的协程环境(例如 Rust 的 Tokio)都提供了为每当活动任务被交换时注册回调的能力,因此它们可以轻松得到支持。然而,其他语言不提供该选项。
该类别中的一个突出示例是 Go:goroutine 是基于用户模式调度构建的,但据我们所知,没有办法检测调度程序。这些语言将需要不通过通用 TLS 路径的解决方案。对于 Go,我们已经构建了一个原型,该原型使用与特定 Goroutine 关联的 pprof 标签,让 Go 的调度程序自动为我们更新它们。
入门指南
我们希望这篇博文能让您大致了解如何将分析信号与分布式跟踪相关联,以及它对最终用户的好处。
要开始使用,请下载OTel 代理的 Elastic 发行版,其中包含新的跟踪关联库。此外,您还需要与Elastic Stack 版本 8.13捆绑的最新版本的通用分析代理。
致谢
感谢 OTel Java 代理的维护者 Trask Stalnaker 对我们的方法的反馈,并感谢他对这篇博文的早期草稿进行了审查。
本帖中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。任何当前不可用的特性或功能可能不会按时或根本不会交付。