衡量“知识平均获取时间” (MTTK)
实时洞察基础设施运营情况,加速对事件真正原因的了解。
完全控制和更易于管理
更少的事件,更长的正常运行时间
每一分钟都很重要。监控工具提供端到端的视图,帮助为客户提供无事件的体验。
可见性提高生产力
公司概况
Cerner 是一家在医疗保健和信息技术两大行业交叉领域的公司。它设计开放且可互操作的解决方案,并提供广泛的托管服务,以支持当今具有挑战性的医疗保健领域的组织。Cerner 以创新而闻名,为各种规模的医疗保健组织提供解决方案和服务。Cerner 与其客户一起致力于创建一个未来,让医疗保健系统能够改善个人和社区的福祉。
CERNER 与 ELASTIC 的合作历程
Cerner:加速知识平均获取时间 (MTTK)
Cerner 的健康信息和电子健康记录技术将全球 27,000 多个签约供应商机构(例如医院和医疗诊所)的人员、信息和系统连接起来。每天,超过 662,000 名医生和 200 万非医生依赖于 Cerner 的应用程序,例如患者门户、电子健康记录、医生移动应用程序等。监控这些应用程序的网络连接的健康状况至关重要。
作为一家医疗保健公司,任何中断时间都影响巨大。每一秒都很重要。就像打开灯一样,我们的客户希望我们的应用程序始终可用,以便他们可以专注于患者而不是技术。这意味着尽可能快地获取根本原因知识并进行补救。
超越假设
Jim Avazpour 是 Cerner 全球运营中心的主管,向 Asby 汇报,他和他的 60 多人团队负责端到端基础设施监控,从操作系统下方一直到所有基础设施层。自 Avazpour 于 2013 年加入 Cerner 以来,他一直在采取措施改进数据收集和分析,目标是创建主动(最终是预测性)的基础设施监控。
Avazpour 和他的团队正在经历大量的警报,而熟悉的“大海捞针”场景使得人类几乎不可能有效地调查每一个问题。
为了实现接近实时的故障解决时间,Avazpour 对平均故障解决时间(MTTR)指标采取了新的视角:平均知识获取时间(Mean Time to Knowledge),该指标基于你多快能拼凑出可共享的见解并找到事件的根本原因。
如果你是为了解决未来的问题,那么有一个假设是好的。但是,如果你试图主动阻止事件发生,那么假设就是在浪费时间,而不是解决问题。你现在需要的是数据。
Cerner 需要提高数据的可见性,并推动更快的知识获取和更快的故障解决。现在是时候超越传统的企业方法,转而采用开源技术和流程了。在寻找解决方案时,规模是一个挑战;很难找到一个能够以可扩展的方式提供所需摄取性能的解决方案。
虽然 Elastic Stack 提供了一种经济高效的解决方案来实现大规模的性能,但真正促成合作的是活跃的开源社区和真诚的合作关系。Avazpour 和他的团队对开源软件有着强烈的兴趣,他们加入了 Elastic 的聚会和技术社区,并与 Elastic 的一些客户建立了联系。当他们的 Elastic 销售总监联系他们时,他们对这些产品已经有了信心。与 Avazpour 见过的许多销售人员不同,这位销售总监不是在推销“下一个闪亮的新玩意”,而是介绍了其他 Elastic 员工,他们都表现出真正有兴趣倾听他的需求,并促进一个最适合 Cerner 的解决方案。作为合作伙伴,建立了真正的信任。
正如 Avazpour 解释的那样,“每次我有问题或需要帮助时,Elastic 都会立即找到合适的人来做我们需要的一切。他们是我们实现内部目标的盟友,这种关系具有巨大的价值。”
一种用于主动监控的开源方法
如今,该团队使用 Elastic Stack 以及开源网络监控解决方案 OpenNMS 来主动监控其基础设施。
我们需要一个功能强大的分析解决方案,它快速、灵活、可扩展、经济高效且具有弹性。虽然有其他方法可以解决这个问题,但开源和 Elastic 解决方案的优雅性和成本效益令人振奋。
Elasticsearch 处理从连接到 Cerner 系统的 8,000 多个网络设备发送到监控平台的数十亿条系统日志和事件。Cerner 庞大的足迹目前生成 3TB 的监控数据,预计未来 12 个月将增长 11 倍。在缺乏专门的内部数据分析师和数据科学家资源的情况下,该团队依靠 Elasticsearch 来实时排序、分类和分组警报,以提高基础设施的健康可见性。
从警报到洞察的飞跃
以前,当客户的系统出现故障或运行缓慢时,即时响应中心(IRC)会呼叫所有值班工程师开始调查并加入事件电话会议以分享他们的发现;但他们经常发现自己处于可怕的境地,无话可说。被动的呼叫导致了数小时的调查时间。该团队想要找到一种更好的方法。
解决方案是使用 Elastic Stack 来索引和分析事件,并梳理出需要立即关注的警报。这包括两个数据源:一个显示在 24x7x365 监控团队的控制台上,另一个发送到 Elastic Stack 以进行高分辨率可见性和机器学习分析。利用 Elastic 机器学习 功能的模型,他们能够利用更高分辨率的数据来寻找模式和异常。
- 数据源 1(“DF1”)生成的警报符合行业标准阈值(例如,连续三个或四个五分钟周期超过 80% 时,生成警报)。
- 数据源 2(“DF2”)打破了减少噪音的行业规则,实际上会对每次违规生成警报。由于这些警报数量巨大,因此无法由人工处理,必须发送到 Elastic Stack 以进行近乎实时的分析、可视化、警报和机器学习任务。
这些警报通过 Kibana 近乎实时地显示,使值班工程师能够将基础设施数据(DF1 和 DF2)与应用程序数据结合起来,快速查明问题的起因,然后将其移交给 24x7 监控团队以采取立即行动解决问题。以前不会被注意到的单独阈值违规现在很容易通过更高分辨率的数据和警报进行调查。
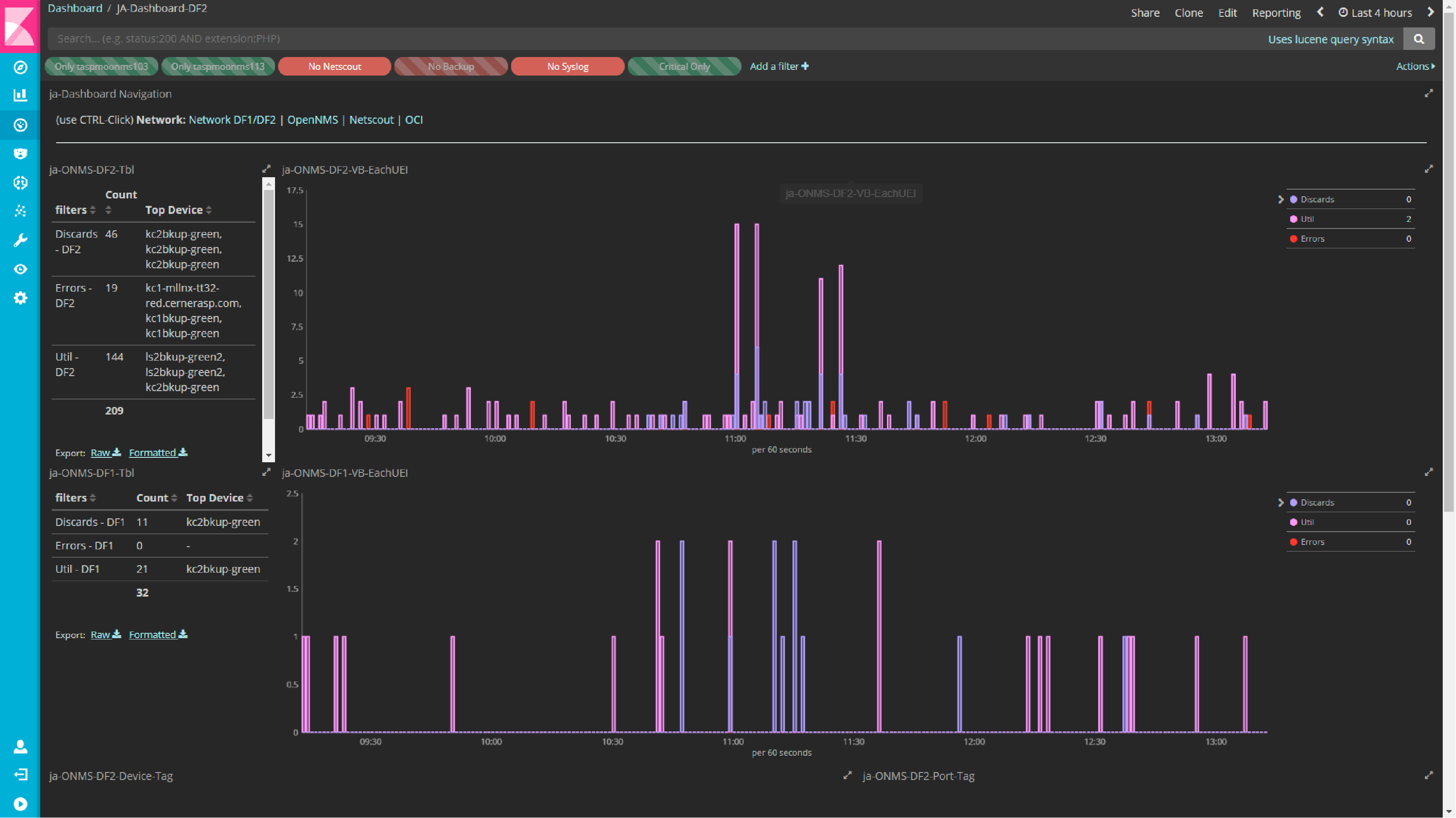
基于 Kibana 构建的仪表板消除了多余警报的干扰(上图),提供了一个数据单一视图,并将原本如海啸般的网络警报(每小时 600-700 个)转化为有意义的洞察。
按基础设施层和客户洞察
最重要的是,开源解决方案使 Cerner 能够按基础设施层(例如网络、存储、虚拟化、LDAP/DNS、硬件)的服务通道以及按客户实时关联和可视化警报。
该团队使用专有的内部技术和 Elastic Stack 构建了一个工具,该工具使用客户助记符和其他关键信息标记每个事件。此客户标记揭示了基础设施拓扑中正在发生的事情,以及每个端口级别的设备和客户在何时发生的事情。Cerner 目前正在生产中使用网络和存储搜索,并正在探索将客户标记扩展到所有服务通道中搜索异常的计划。
Cerner 还计划利用预测分析,并使用插入 Elastic Stack 的机器学习功能来寻找模式和异常。“能够使用 Elastic Stack 排序和可视化数据对我们来说是一个巨大的改变,”Avazpour 说。“在问题之上进行智能化处理对于提供最佳的客户体验非常重要和有用。”
影响“平均知识获取时间”
在使用 Elastic Stack 之前,在所有服务通道的事件和警报中以安全的方式进行搜索、分析和可视化既繁琐又耗时。现在,如果发生事件,该团队可以准确地缩小到问题所在。这使得 MTTK 从数小时缩短到几分钟,甚至接近实时。
有了这些见解,工程师可以加快修复速度,并与高管和内部团队(如负责 Cerner 外部客户的应用程序监控团队)闭环沟通。在许多情况下,该团队能够从一开始就阻止事件的发生。
据 Asby 称,目标是争取实现零事件影响客户。事实上,Cerner 的报告模型将“无事件时间”作为客户服务级别协议的一部分。“我们越接近零,我们就越好,”Asby 说。“Elastic Stack 为我们提供了端到端的视图,以帮助我们掌控事件,并最终为客户提供无事件体验。”
为了确保用于分析、预测和警报的监控数据的准确性,Cerner 决定在其收集节点上使用 Elastic Stack 的 Metricbeat。Metricbeat 是一种发送系统和服务统计信息的轻量级方式,它提供了必要的监控指标,以保证其数据收集平台不会丢失数据并保持其 100% 的正常运行时间目标。
虽然资源限制会限制项目以传统方式实施的速度,但 Elastic Stack 的开源和分布式模型使 Cerner 能够利用现有工程资源快速扩展并满足其 IT 路线图要求。“如今,你最有价值的资产是你的数据。如果你没有像 Elastic Stack 这样的工具,那么数据将被收集,但你将不知道如何处理它,”Avazpour 说。
我非常习惯使用 Elastic Stack,我非常喜欢它,我无法想象没有它会怎么样。
一旦你开始解决一个问题,就很容易不断解决新问题。基于该项目迄今为止的成功,应用程序和基础设施支持部门的更多团队希望加入进来。
基础设施增长,数据增加,事件减少
结合 Cerner 的整体技术和流程改进,Elastic Stack 以及 OpenNMS 为生产力的显着提高做出了贡献,这要归功于事件数量的减少,即使面对不断增加的数据量也是如此。工程师现在有能力解决基础设施问题,而其他人则可以腾出手来专注于更具战略意义的计划。“我们在很短的时间内取得了巨大的进步,”Asby 说。
虽然传统的成功衡量可能侧重于投资回报率和总拥有成本(TCO),但 Cerner 团队对客户满意度有新的看法。根据 Avazpour 的说法:“在 IT 运营中,每一分钟都很重要。导致停机或性能缓慢的事件越少,我们的客户就越满意。”
Cerner 的集群
- 集群数量9
- 节点数量主节点和数据节点:64
总计:74 - 文档总数当前 3,881,415,067 预计:未来一年增加 11 倍
- 数据总大小3TB 预计:未来一年增加 11 倍
- 副本1
- 托管环境本地 Oracle Enterprise Linux 6.6
- 每日摄取率约 4 亿个文档 预计:45 亿个文档
- 硬件统计ProLiant BL460c Gen9,128 GB Ram,48 核,6TB Tier 1 SAN 存储