异常分数解释
编辑异常分数解释
编辑每个异常都有一个分配给它的异常分数。该分数指示数据点的异常程度,这使得可以定义其与其他异常相比的严重程度。此页面为您提供了计算异常分数的关键因素、分数如何计算以及重归一化如何工作的高级解释。
异常分数影响因素
编辑异常检测作业将时间序列数据拆分为时间桶。桶内的数据使用函数进行聚合。异常检测发生在桶值上。三个因素会影响记录的初始异常分数:
- 单桶影响,
- 多桶影响,
- 异常特征影响。
单桶影响
编辑首先计算桶中实际值的概率。此概率取决于过去看到了多少相似的值。它通常与实际值和典型值之间的差异有关。典型值是桶的概率分布的中值。此概率导致单桶影响。它通常主导短峰或短谷的初始异常分数。
多桶影响
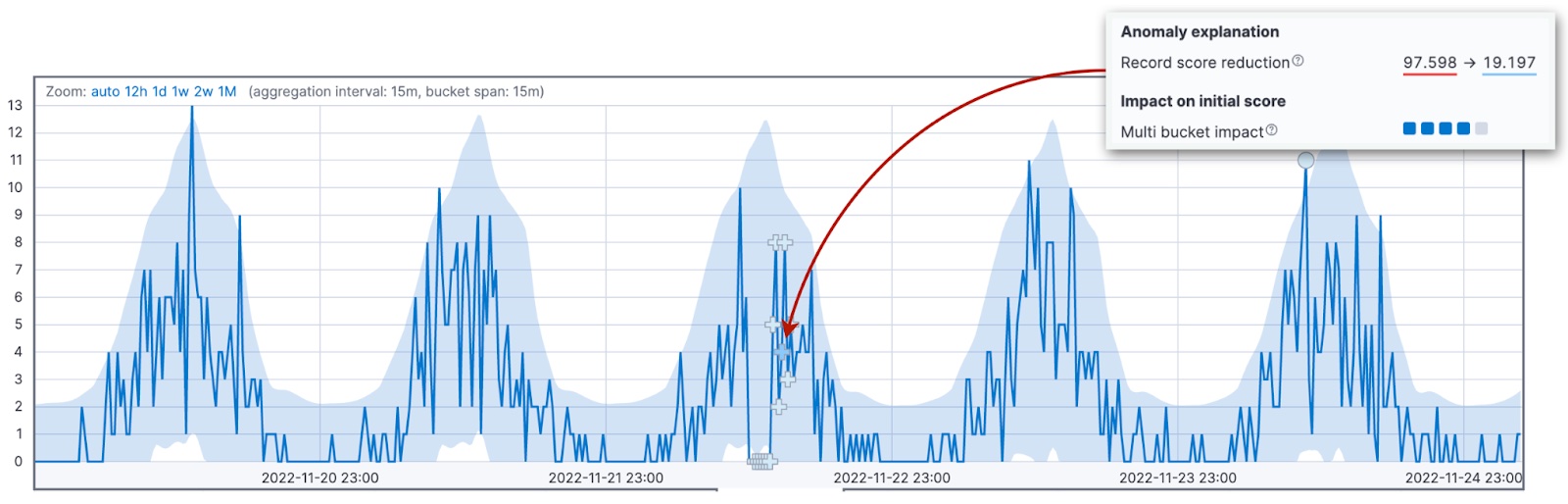
编辑当前桶和前 11 个桶中的值的概率会影响多桶影响。实际值和典型值之间累积的差异会导致对当前桶的初始异常分数产生多桶影响。高多桶影响表明在当前桶之前的间隔内存在异常行为,即使此桶的值可能在 95% 置信区间内。
不同的符号标记具有高多桶影响的异常,以突出区别。在 Kibana 中,这些异常用十字号“+”表示,而不是圆圈。
异常特征影响
编辑异常特征的影响考虑了异常的不同特征,例如其长度和大小。考虑异常的总持续时间,而不是像多桶影响计算那样的固定间隔。长度可能只有一个桶或三十个(或更多)桶。将异常的长度和大小与历史平均值进行比较,可以适应您的领域和数据中的模式。该算法的默认行为是对较长异常的评分高于短暂的峰值。在实践中,短异常通常是数据中的错误,而长异常是您可能需要做出反应的事情。
结合多桶影响和异常特征影响可以更可靠地检测各个领域的异常行为。
记录分数降低(重归一化)
编辑异常分数范围在 0 到 100 之间。接近 100 的值表示该作业迄今为止看到的最大异常。因此,当检测到比以前任何其他异常都大的异常时,需要降低先前异常的分数。
当异常检测算法在有新数据传入时调整过去记录的异常分数时,该过程称为重归一化。renormalization_window_days 配置参数指定此调整的时间间隔。Kibana 中的单指标查看器突出显示了重归一化更改。
其他分数降低因素
编辑另外两个因素可能导致初始分数降低:高方差间隔和不完整的桶。
如果当前桶是数据具有高可变性的季节性模式的一部分,则异常检测的可靠性会降低。例如,您可能每晚午夜都有服务器维护作业正在运行。这些作业可能会导致请求处理的延迟出现高可变性。如果当前桶收到的观测数量与历史预期相似,则该作业的可靠性也更高。
现实世界中的异常通常显示出多种因素的影响。单指标查看器中的异常解释部分可以帮助您解释其上下文中的异常。
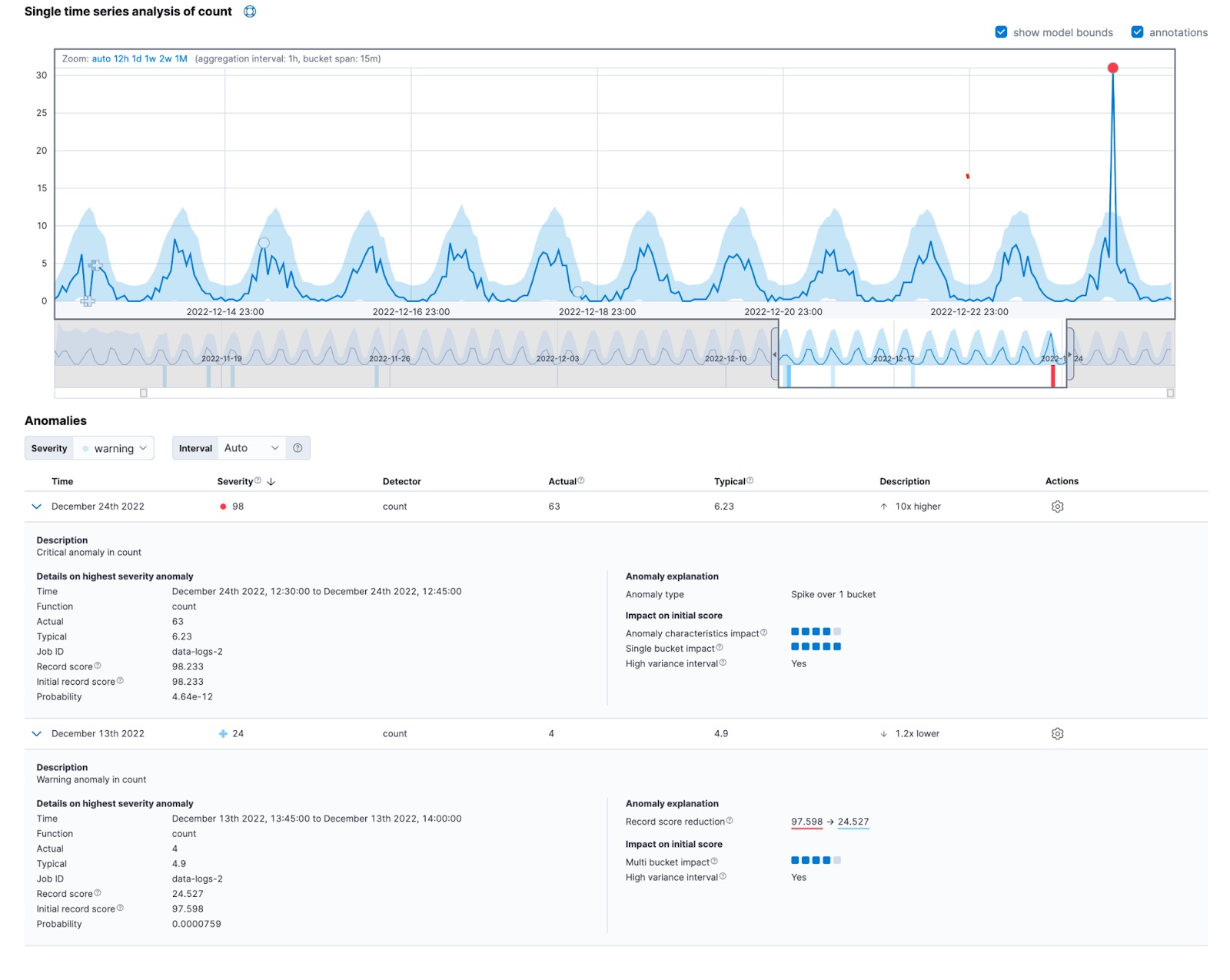
您也可以在获取记录 API 的 anomaly_score_explanation 字段中找到此信息。