检测指标异常
编辑检测指标异常
编辑当启用机器学习的异常检测功能时,您可以创建机器学习作业来检测和检查主机和 Kubernetes Pod 的内存使用率和网络流量异常。
您可以对系统内存使用率以及跨主机或 Pod 的入站和出站网络流量进行建模。您可以检测到主机或 Pod 的内存使用率异常增加以及入站或出站流量异常高的情况。
为主机或 Kubernetes Pod 启用机器学习作业
编辑创建一个机器学习作业,以自动检测异常内存使用率和网络流量。
创建机器学习作业后,您将无法更改设置。您可以稍后重新创建这些作业。但是,您将删除任何先前检测到的异常。
- 要打开 基础设施清单,请在主菜单中找到 基础设施,或使用全局搜索字段。
- 单击页面顶部的 异常检测 链接。
- 系统将提示您为 主机 或 Kubernetes Pod 创建机器学习作业。单击 启用。
-
选择机器学习分析的开始日期。
机器学习作业会分析最近四周的数据,并无限期地继续运行。
-
选择一个分区字段。
默认情况下,会选择 Kubernetes 分区字段
kubernetes.namespace。分区允许您为共享相似行为的不同数据组创建独立模型。例如,您可能希望为机器类型或云可用区构建单独的模型,以便异常不会在各个组之间被平等地加权。
- 默认情况下,机器学习作业会分析您的所有指标数据,结果会列在 异常 选项卡下。您可以过滤此列表以仅查看您感兴趣的作业或指标。例如,您可以按作业名称和节点名称进行过滤,以查看该主机的特定异常检测作业。
- 单击 启用作业。
-
现在,您可以开始探索指标异常了。单击 异常。
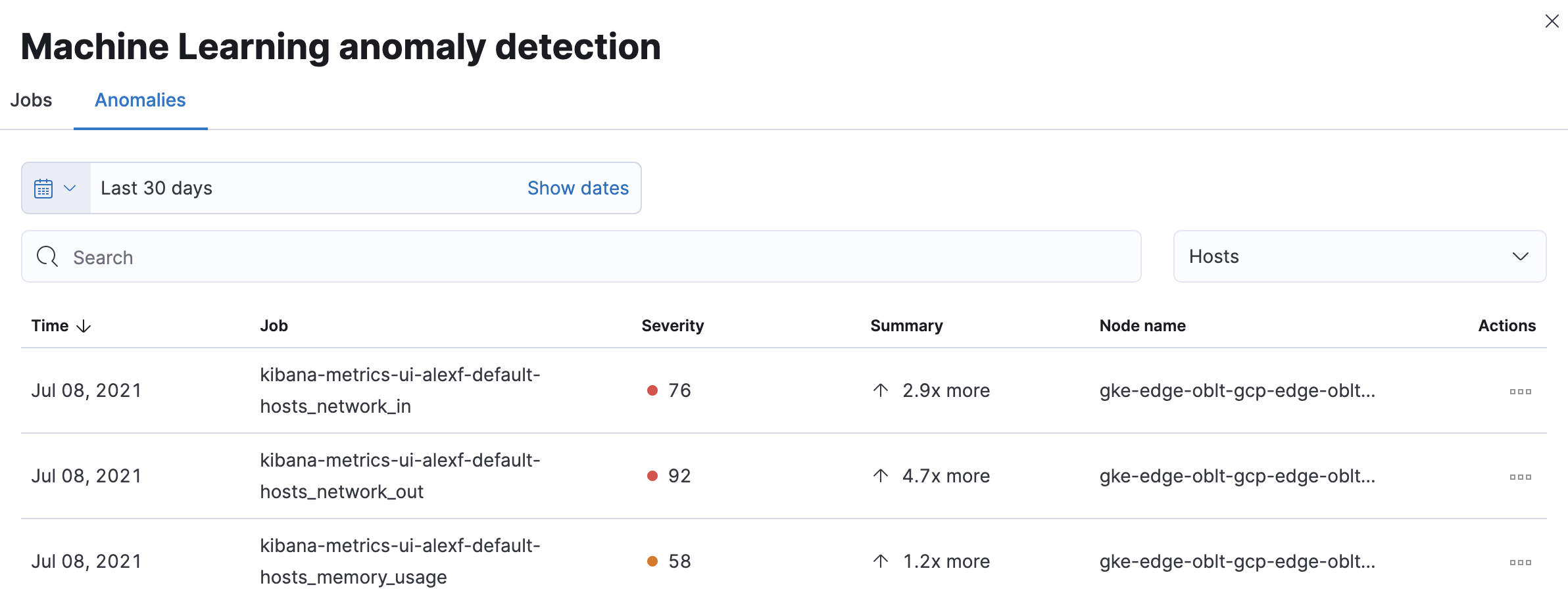
异常表显示了特定主机或 Kubernetes Pod 的每个单独的指标异常检测作业的列表。默认情况下,异常作业按时间排序以显示最近的作业。
除了每个异常作业和节点名称之外,还列出了严重性评分等于或高于 50 的检测到的异常。这些评分代表所选时间段内的“警告”或更高级别的严重性。摘要值表示异常记录结果中指标的实际值与预期(“典型”)值之间的增加。
要向下钻取并分析指标异常,请选择 操作 → 在异常资源管理器中打开 以查看机器学习中的异常资源管理器。您还可以选择 操作 → 在清单中显示 以查看主机或 Kubernetes Pod 的清单页面,并按特定指标进行过滤。
历史图表
编辑在 清单 页面上,单击 显示历史记录 以查看所选时间范围内的指标值。检测到的异常(异常分数等于或高于 50)会以红色突出显示。要检查检测到的异常,请使用异常资源管理器。
