

使用 AIOps 自动化异常检测并加速根本原因分析
大规模消费和处理大型可观测性数据集,以快速定位与业务最相关的信息。Elastic 可观测性利用上下文感知的生成式 AI 和高级机器学习来减少劳动密集型故障排除并简化分类活动,以便团队可以专注于创新和未来转型。
通过 AI 驱动的洞察力赋能 SRE
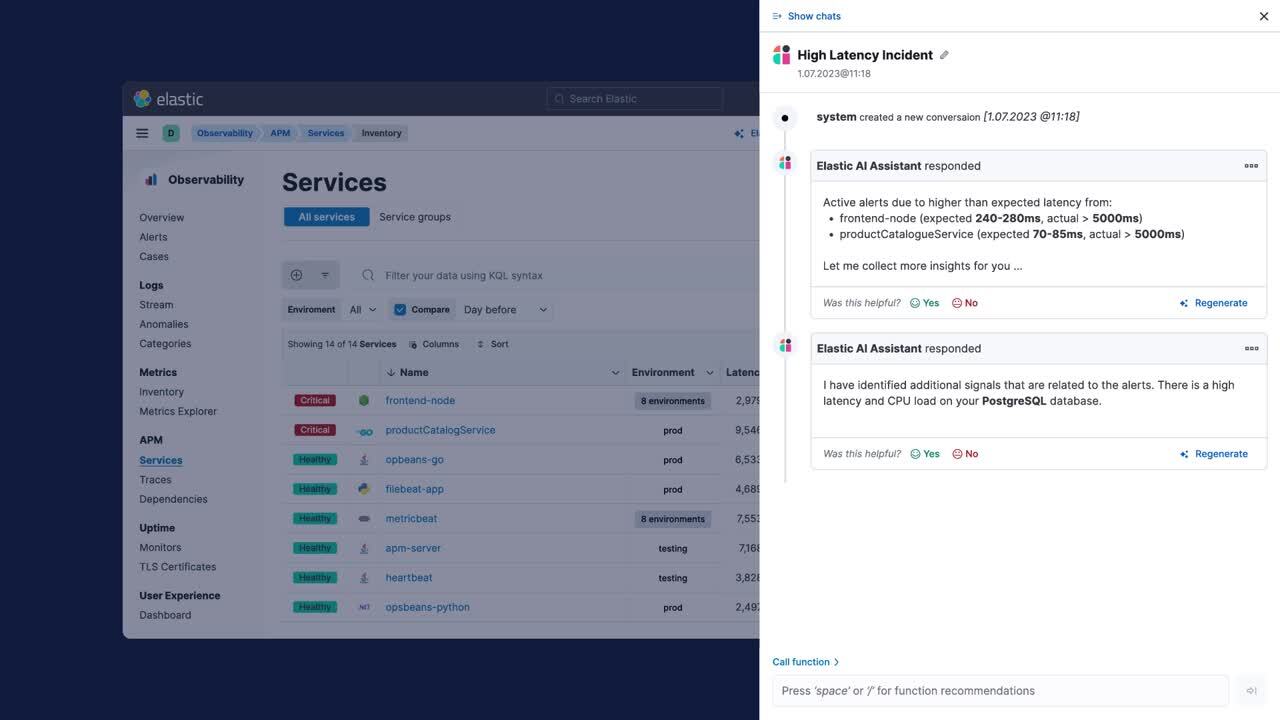
将生成式 AI 与 Elastic 可观测性和高级机器学习相结合,基于您的专有数据和运行手册获得上下文感知的交互式聊天体验。Elastic AI 助手可以帮助您解释日志消息和错误,为最佳代码效率提供建议,编写报告,甚至帮助识别和执行运行手册。实现更快的问题解决,改善协作,解锁知识孤岛,并赋能所有用户,使团队能够专注于构建更好的软件。
主动检测异常值和趋势
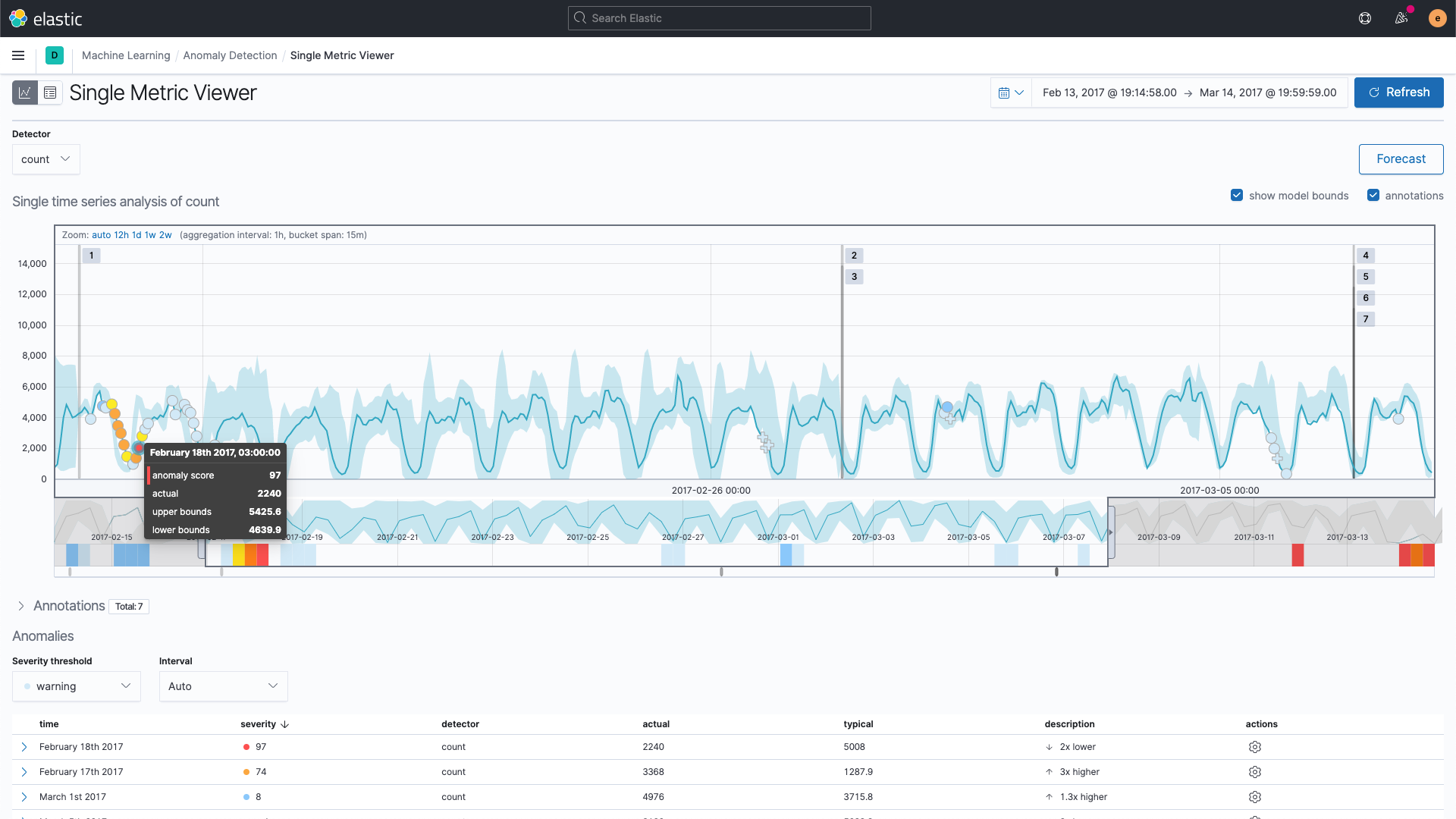
将监督和非监督机器学习应用于任何类型的日志、跟踪、事件或指标数据,无论是业务数据还是运营数据。使用特定领域的功能检测异常值和异常情况,预测趋势,发现模式,对日志进行分类等等。从可定制的开箱即用的 ML 模型的大型开放库中进行选择,或构建、测试和部署您自己的模型。自动发现版本之间的回归,并识别在快速变化的基于微服务的云原生环境中更改应用程序或基础设施的下游影响。
释放数据的全部力量
借助性能出色且可扩展的机器学习引擎,在几分钟内从 PB 级的可观测性数据中提取答案。通过 100 多个针对常见用例的预配置模型、易于使用的向导式工作流程以方便自定义以及集成的数据探索工具,将 ML 和分析民主化给组织中非数据科学家,例如 SRE 团队和业务用户。开放 ML 模型为成熟的用户提供了“了解底层”并根据需要进行自定义的灵活性。
加速问题解决
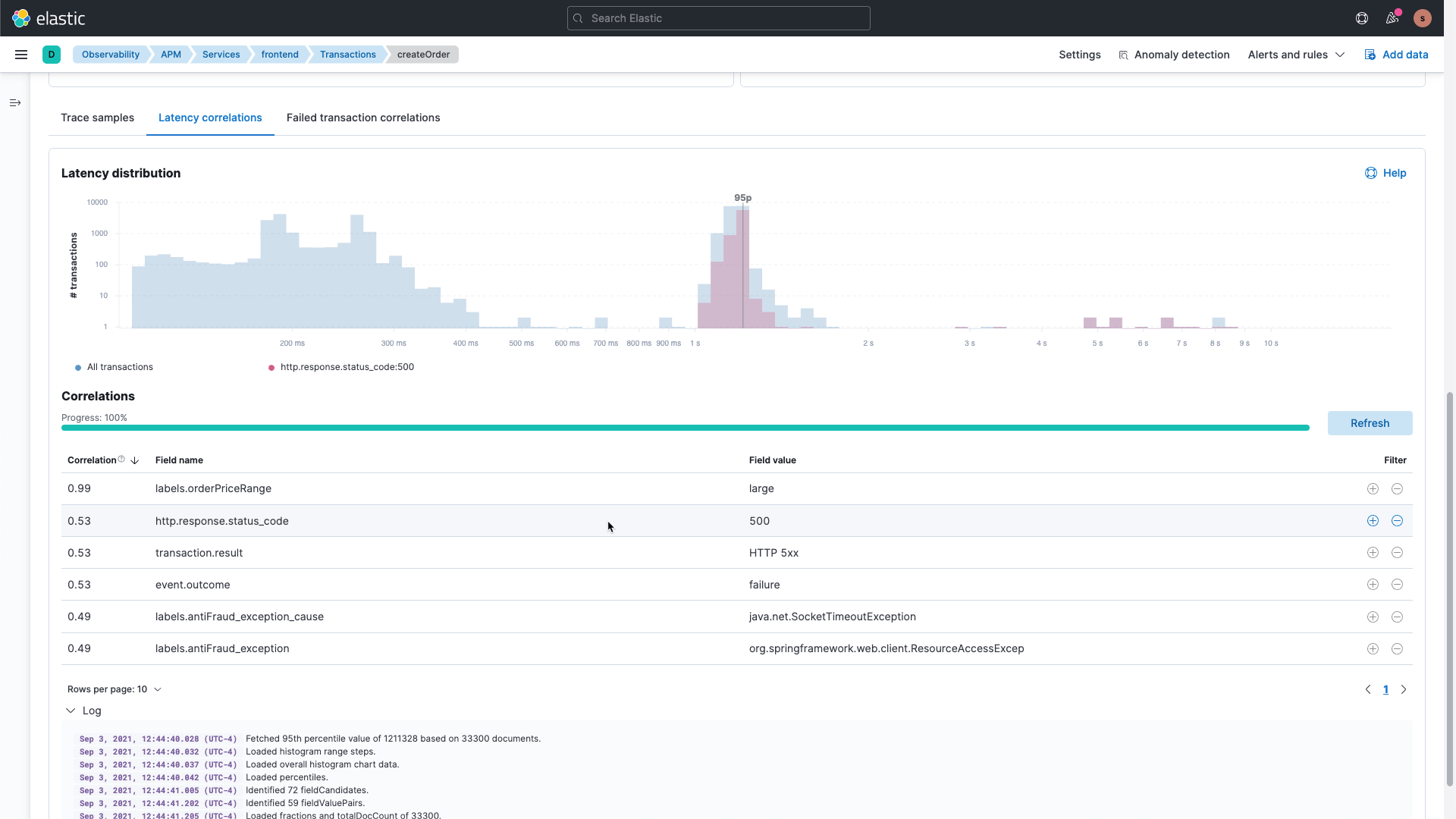
自动显示与高延迟或错误事务相关并且对整体服务性能影响最大的应用程序和基础设施数据集的属性。基于机器学习的相关性可以查明可观测性数据中的 *未知未知*,以帮助更快地找到根本原因。通过自动日志分类将数百万行非结构化日志数据减少到几个类别,从而快速分析事件并对其采取措施。使用自动异常检测来识别诸如日志中的异常模式、服务降级、日志速率峰值、异常事务活动或资源利用率激增等问题。
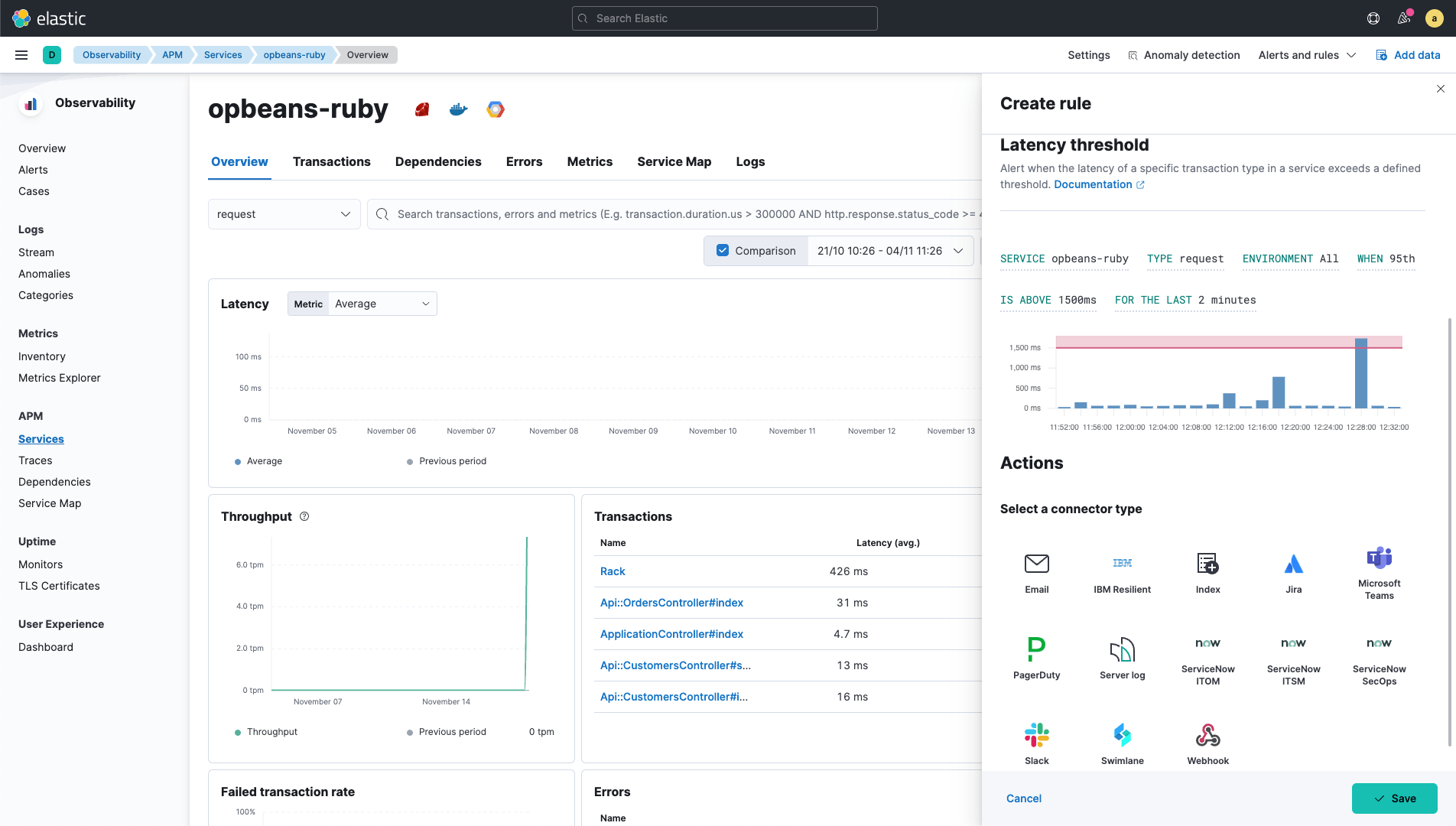
使用您的工作流程和事件管理来简化警报
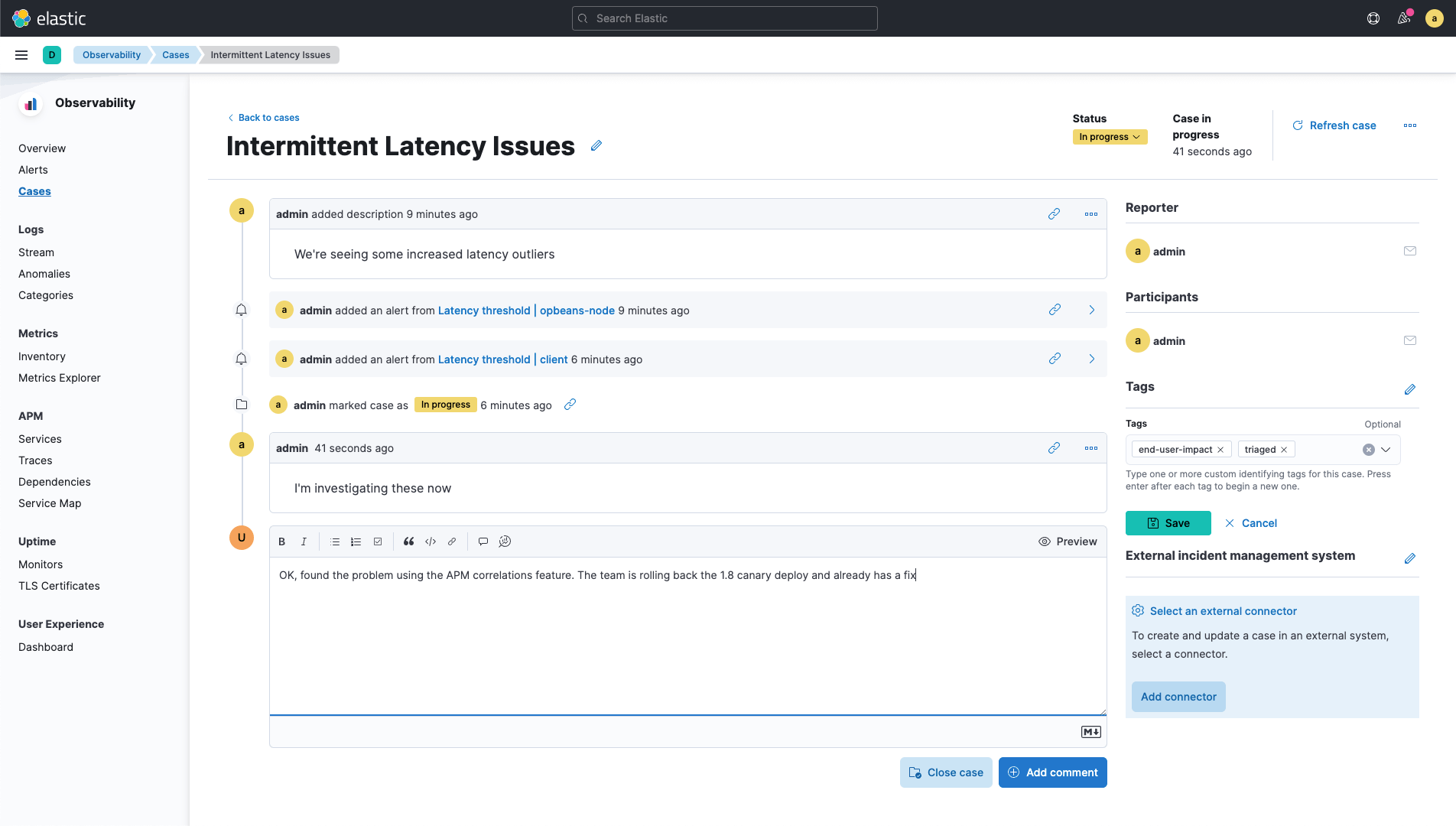
当检测到满足特定条件的异常时,接收上下文警报通知。通过在 Elastic 可观测性中直接打开和跟踪服务问题,启动案例以开始事件管理流程。通过使用 PagerDuty、ServiceNow、Jira、Microsoft Teams、Slack 和电子邮件的内置集成,将您的警报连接到操作。利用 Elastic Stack 中强大的 webhook 输出,让您可以连接到对您的组织很重要的其他第三方系统,并与您团队的工作流程集成。
使用全栈可观测性解决方案实现技术运营现代化
在单个堆栈中大规模统一您的日志、指标和 APM 跟踪。

