

可观测性:使用通用剖析优化工作负载
概述
Elastic 可观测性简介
更熟悉 Elastic 可观测性,并概述如何使用 Elastic Cloud 摄取、查看和分析来自应用程序的客户日志。了解如何现代化应用程序并自信地采用云。
让我们开始吧
创建 Elastic Cloud 帐户
转到 cloud.elastic.co 并创建帐户后,请按照此视频了解如何在我们在全球 50 多个受支持的区域中的任何一个区域启动您的第一个 Elastic Stack。
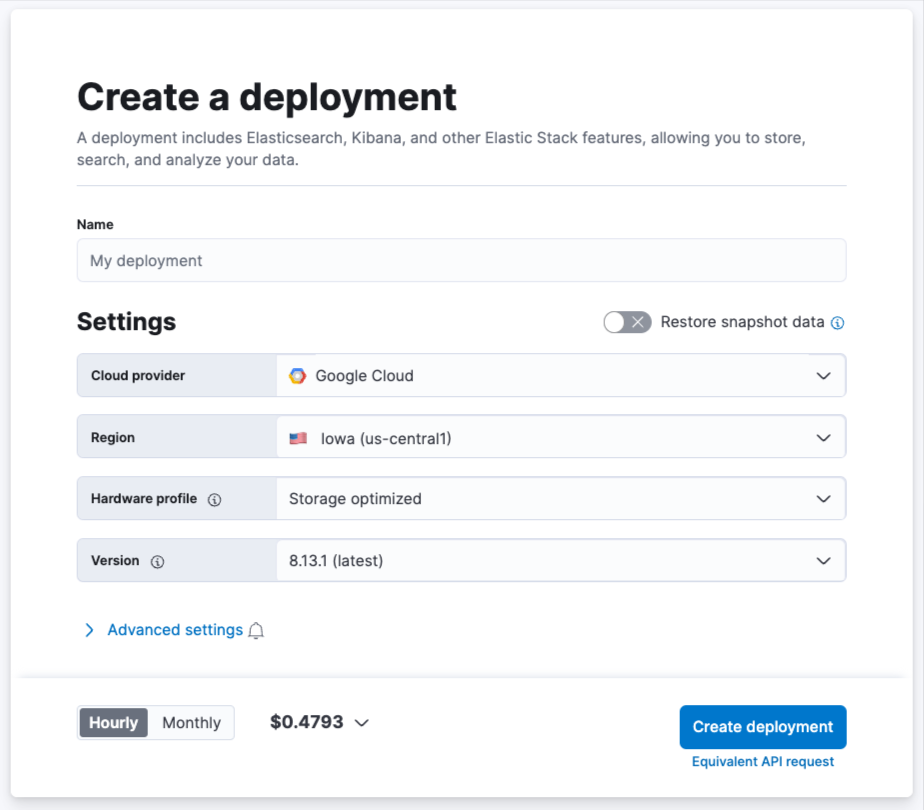
部署完成后,在 可观测性 选项卡下,选择 使用通用剖析优化我的工作负载。
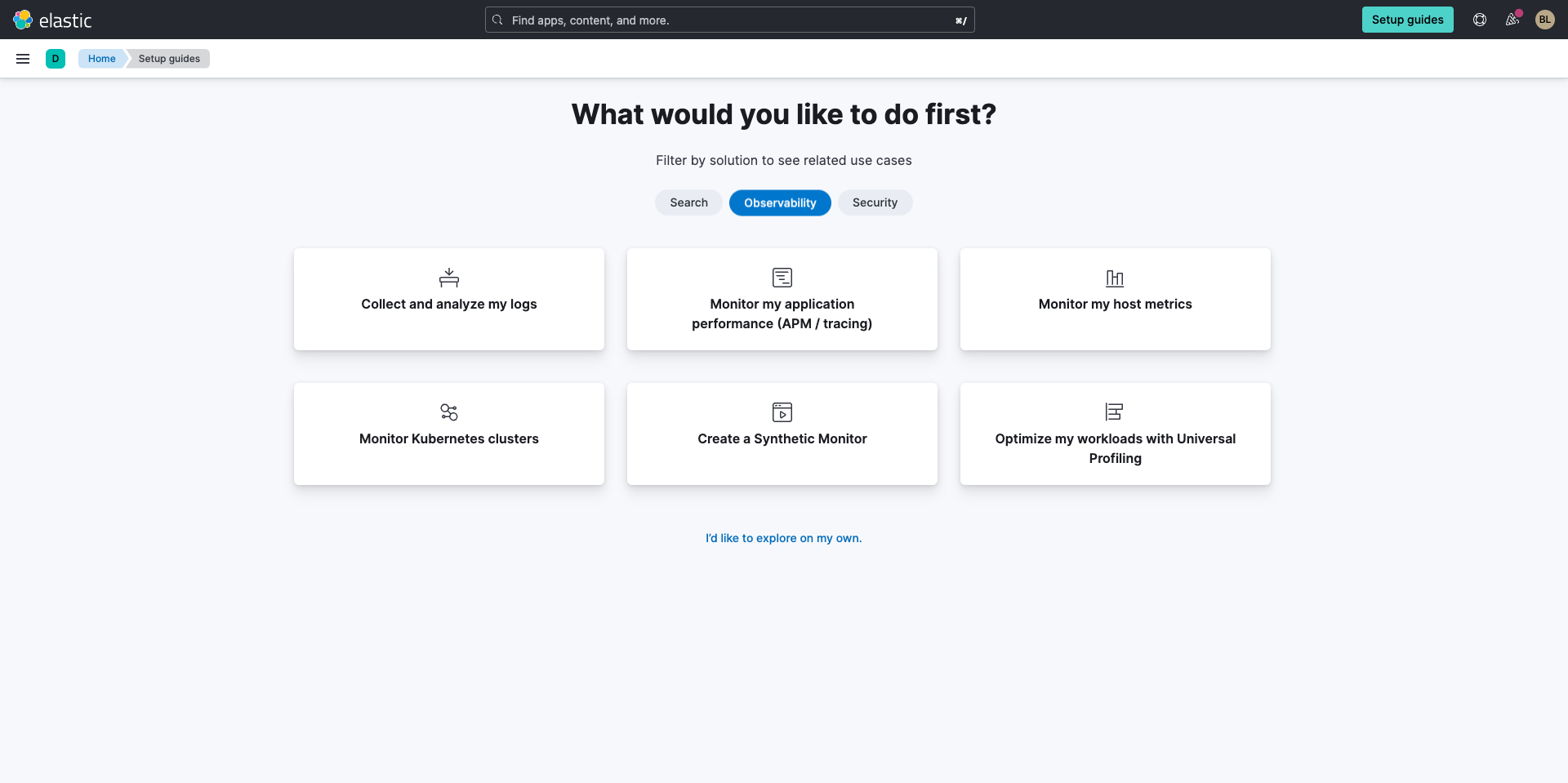
现在,系统会提示您添加数据以开始使用。选择 设置通用剖析。
如果这是您第一次使用通用剖析代理,系统会提示您进行设置。只需按照以下说明操作即可。
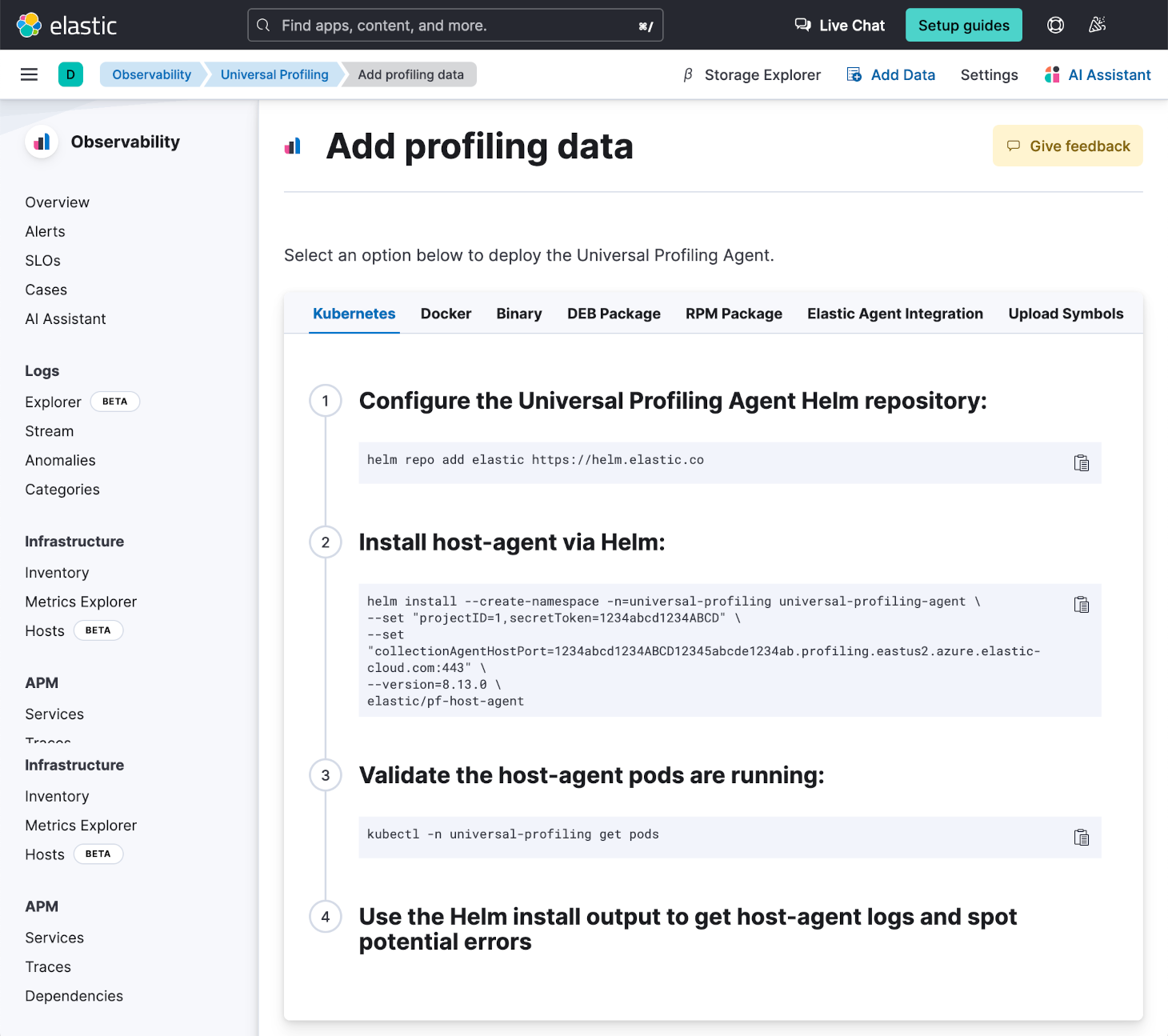
以下是在 Microsoft Azure AKS 集群中运行上述命令的示例。
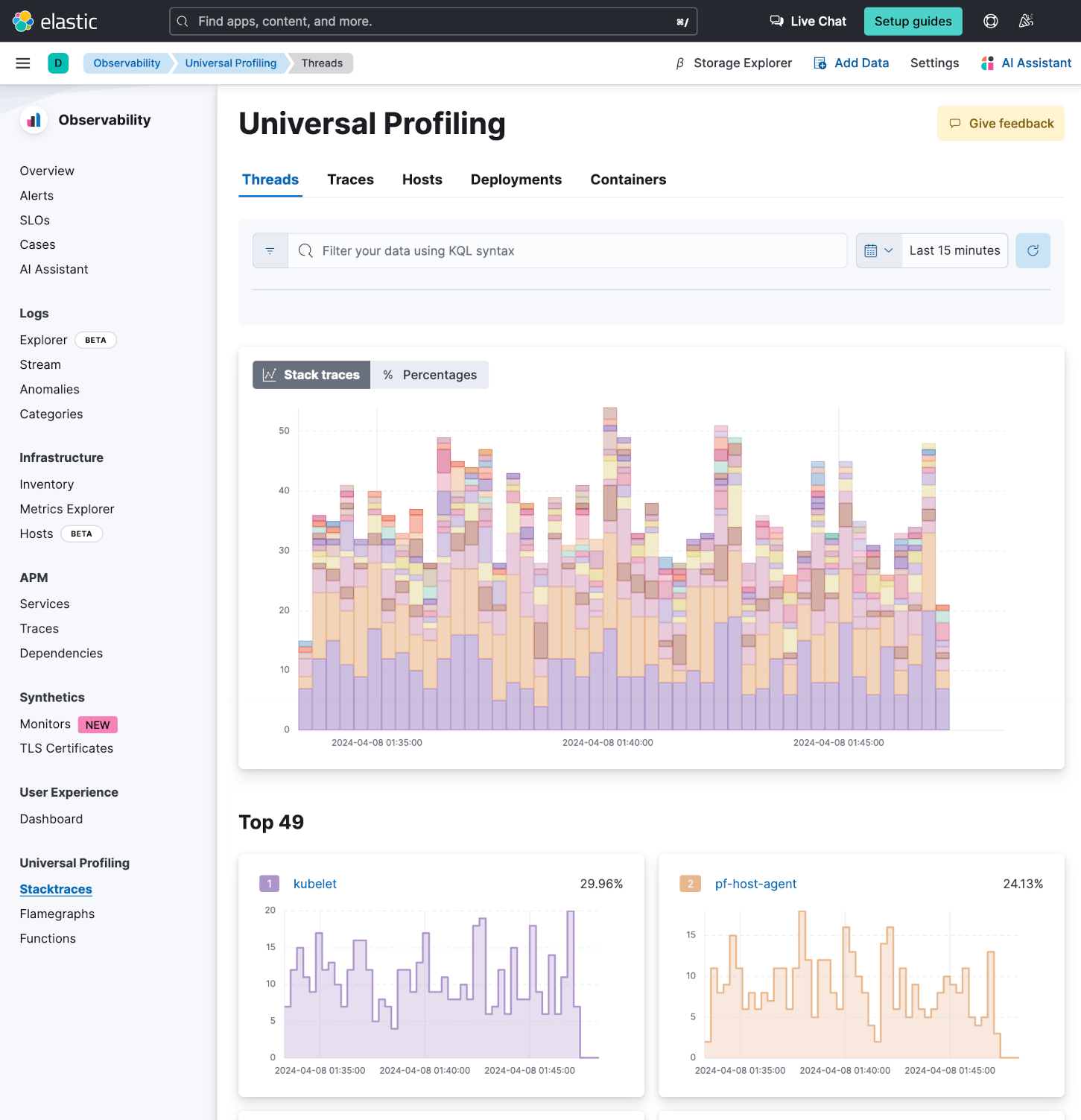
数据开始显示后,请导航到左侧菜单中 通用剖析 下的 堆栈跟踪。查看堆栈跟踪是为了了解什么消耗的时间最多。将鼠标光标悬停在图表上以查看各个线程的波形模式。
堆栈跟踪视图按线程、主机、Kubernetes 部署和容器显示分组的堆栈跟踪图。它可用于检测线程中意外的 CPU 峰值,并深入到较小的时间范围,以便使用火焰图进一步调查。
您将在大约 3 分钟或更短的时间内开始看到数据。查看此博客,了解有关如何读取堆栈跟踪的更多信息。
使用 Elastic 可观测性
分析火焰图
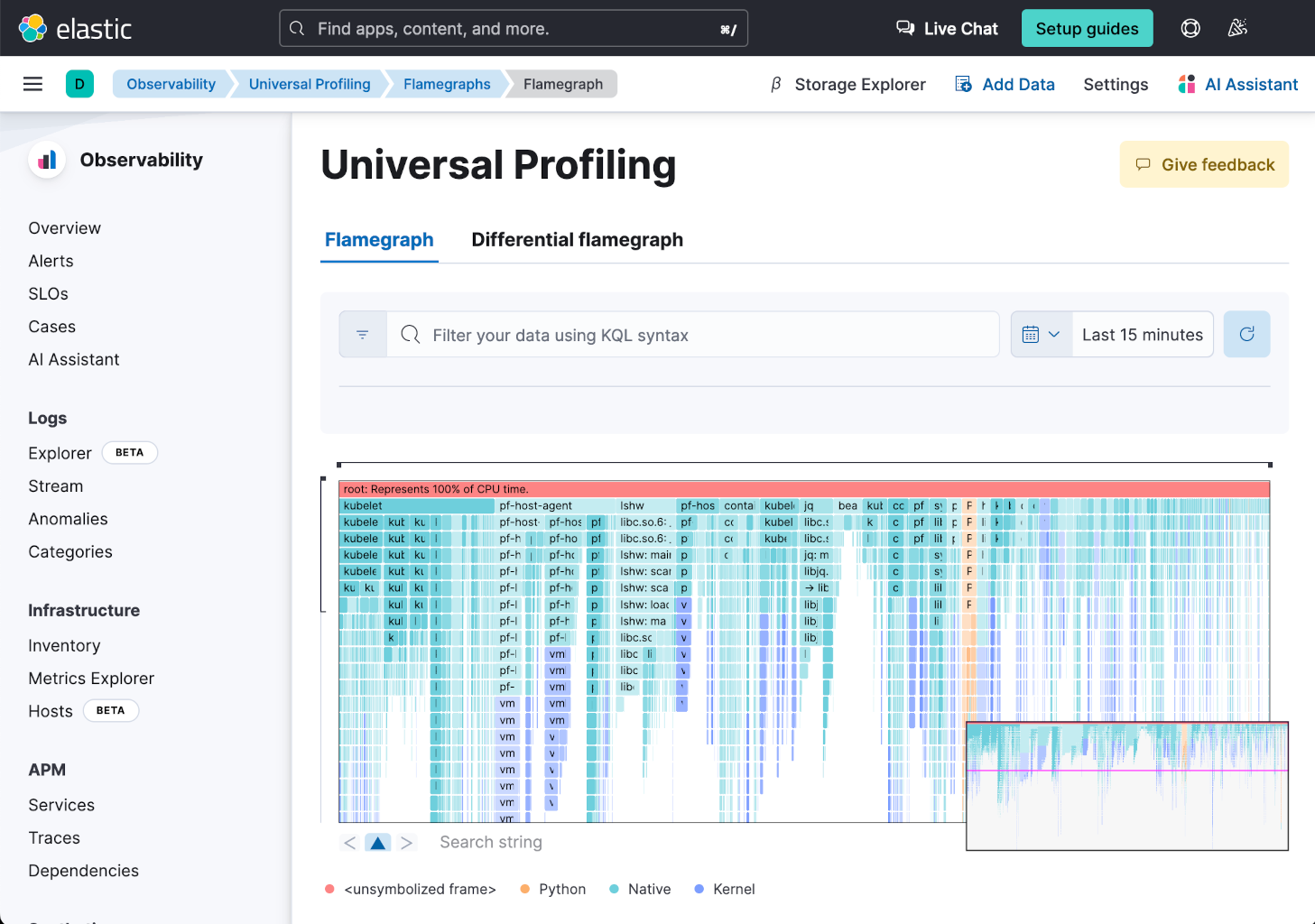
接下来,导航到左侧菜单中 通用剖析 下的 火焰图。本质上,剖析与火焰图同义。它从左到右表示最昂贵的代码或最昂贵的函数。
火焰图页面是您很可能花费最多时间的地方,尤其是在调试和优化时。我们建议您使用此博客,以使用火焰图识别性能瓶颈和优化机会。需要注意的三个关键要素 - 条件是宽度、层次结构和高度。
- 从左到右水平扫描,重点关注 CPU 密集型函数的宽度。
- 垂直检查以检查堆栈并发现瓶颈。
- 寻找高耸的堆栈,以识别代码中潜在的复杂性。
要开始探索,建议将其限制为特定的线程、主机、部署或容器。只需在搜索栏中输入即可。
注意: Elastic Universal Profiling 是业界唯一的持续剖析解决方案,无需主机上的调试符号即可提供从内核到本机代码到高级编程语言的混合语言可见性。
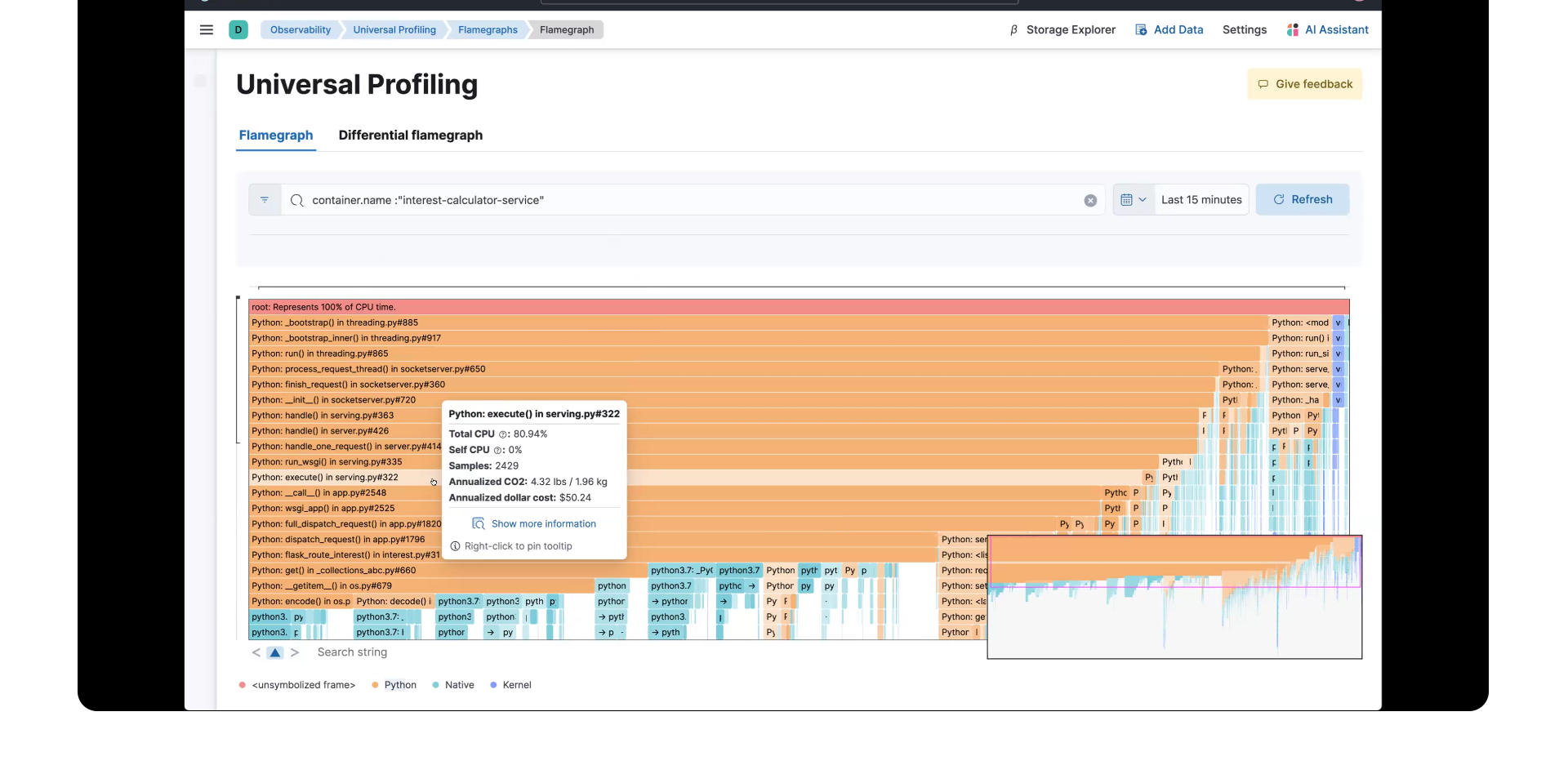
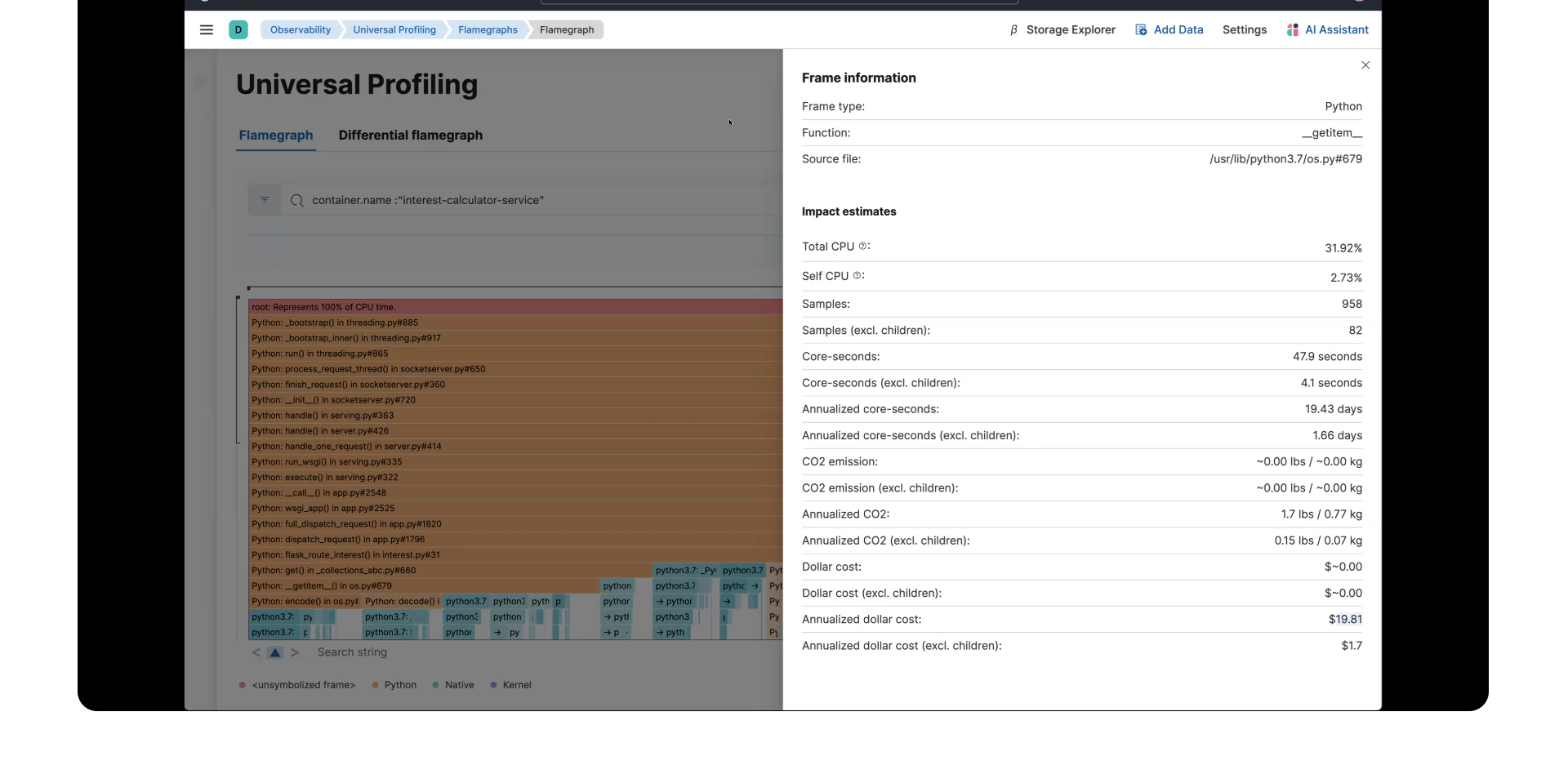
在您分析图形时,请注意线越长,在 CPU 时间方面花费的时间就越多。如果您选择其中一条线,您将获得一个包含更多详细信息的弹出窗口。 函数 是当时执行的代码行,您还将看到其他关键详细信息,如 总 CPU、年度化 CO2 和 年度化美元成本。
比较更改前后的代码
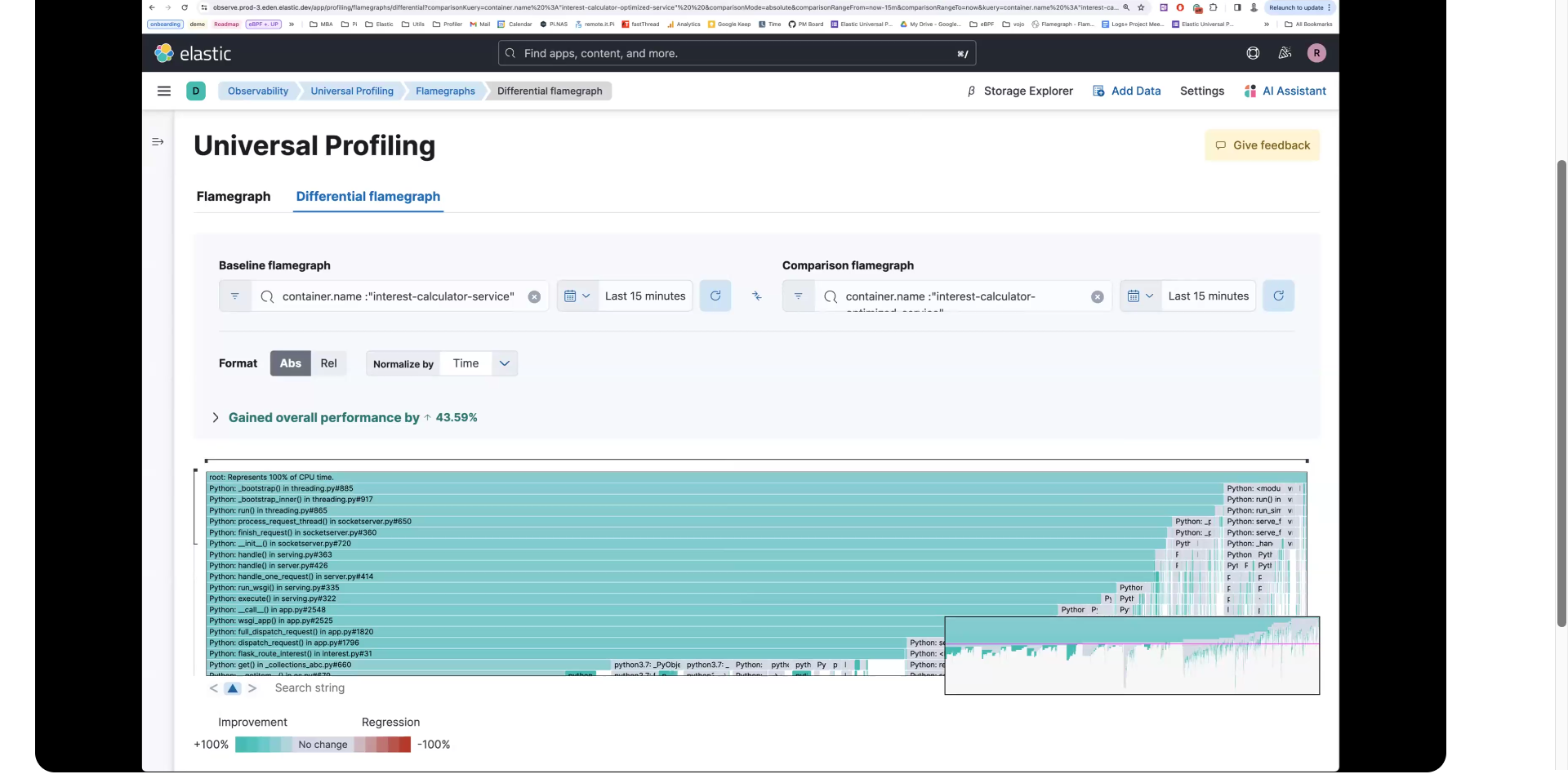
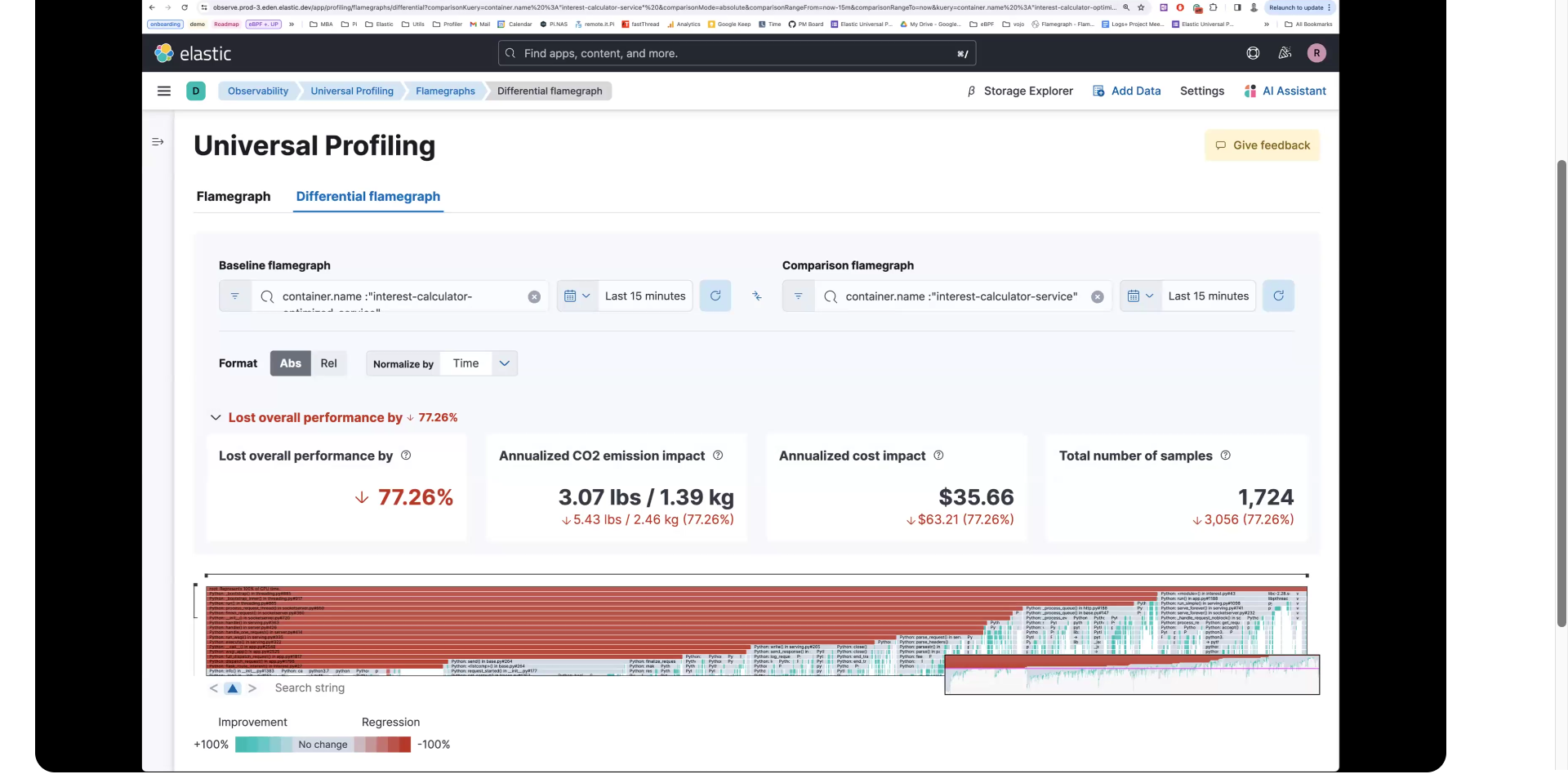
差异火焰图允许您在推送到生产环境之前比较更改前后的代码。青色表示改进,红色表示回归。
在下面的图像中,您可以看到优化的容器在颜色上更好。
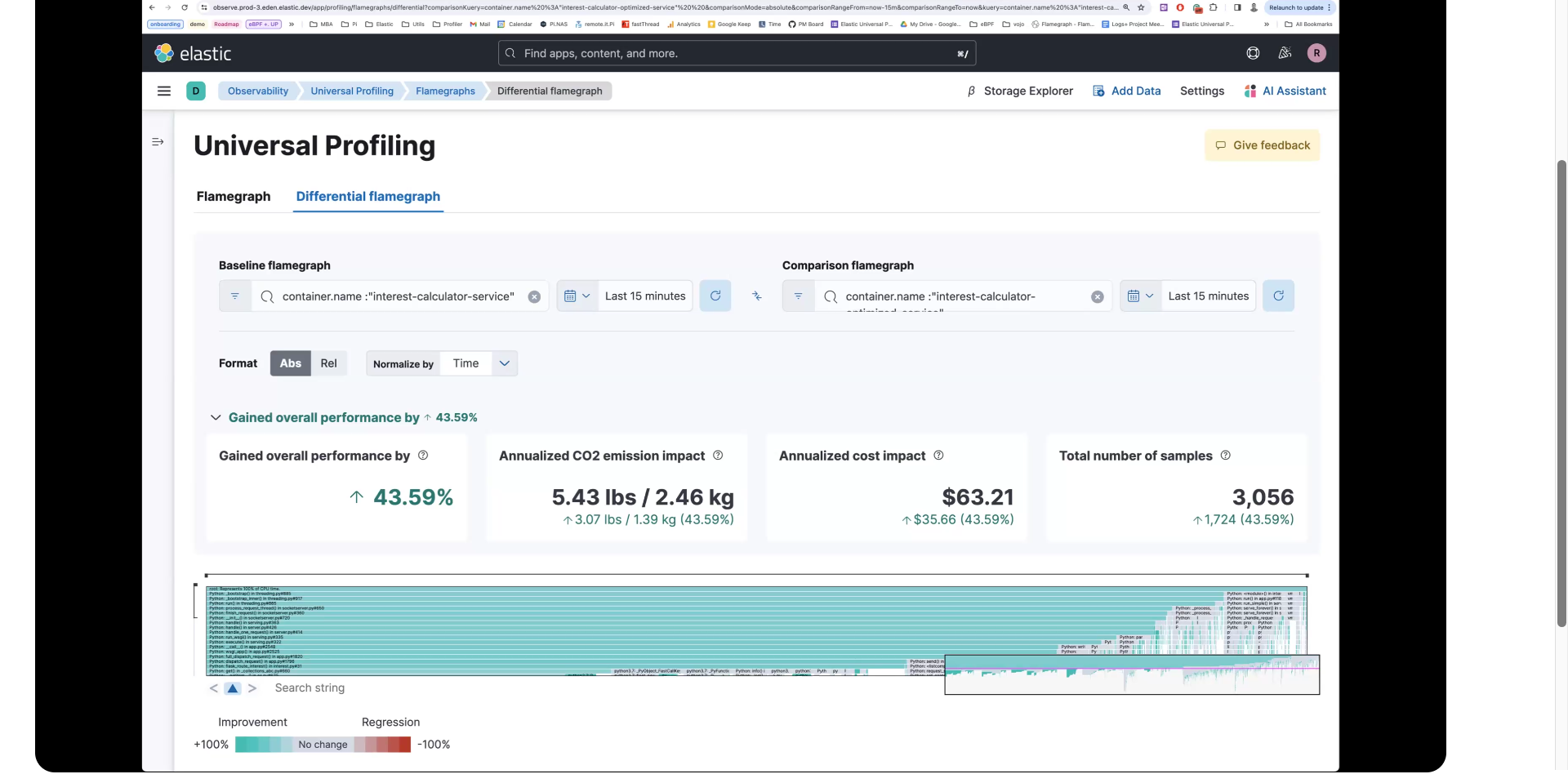
如果您选择 整体性能提升 旁边的下拉箭头,您可以看到整体改进值。
接下来,如果您选择 交换侧面 图标(被比较的容器之间有箭头指向相反方向的图标)。您可以看到,恢复到优化之前的容器的代码将导致回归。
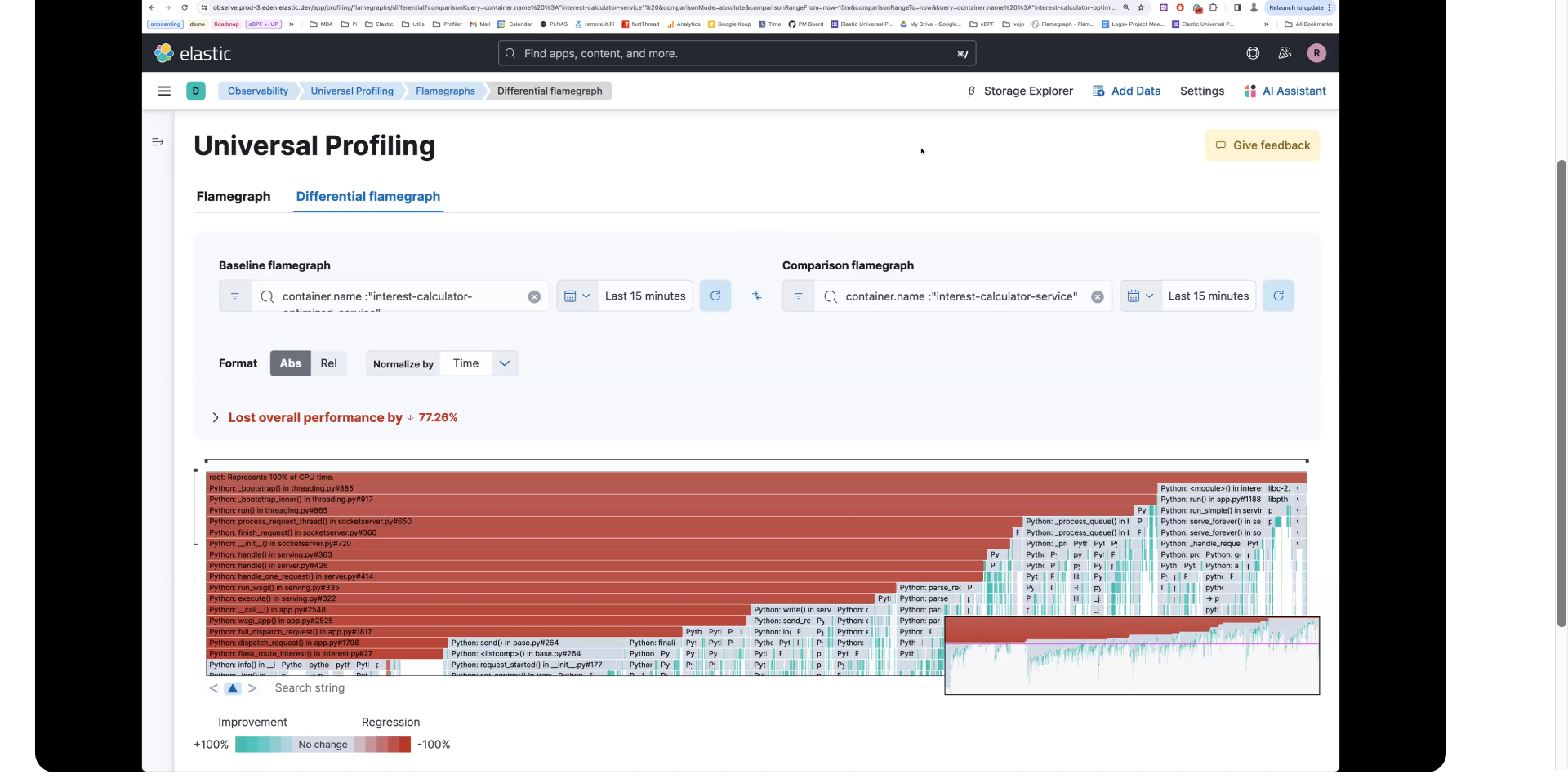
如果您选择 整体性能损失 旁边的下拉箭头,您可以看到整体回归值。
接下来,如果您选择 转到监控,您将立即获得一些高级见解。这些图表将随着更多测试的进行而开始呈现,但您可以快速查看可用性、执行测试的持续时间、时间线,还可以深入到瀑布图。要深入查看,请单击 查看测试运行 下的图标。
后续步骤
感谢您花费时间使用 Elastic Cloud 收集和分析日志。如果您是 Elastic 的新用户,请务必注册一个免费的 14 天试用版。
此外,在您开始使用 Elastic 之旅时,请了解当您在环境中部署时,作为用户,您应该管理的一些运营、安全和数据组件。