在 Kubernetes 上扩展 Elastic Agent
编辑在 Kubernetes 上扩展 Elastic Agent
编辑有关如何在 Kubernetes 上部署 Elastic Agent 的更多信息,请查看以下页面
大规模可观测性
编辑本文档总结了使用 Elastic 可观测性大规模监控 Kubernetes 基础设施的一些关键因素和最佳实践。用户需要考虑不同的参数并相应地调整 Elastic Stack。随着 Kubernetes 集群规模的增加,这些因素会受到影响
- 从多个 Kubernetes 端点收集的指标数量
- Elastic Agent 的资源,以应对内部处理对高 CPU 和内存的需求
- 由于指标摄取率较高而需要的 Elasticsearch 资源
- 仪表板的可视化响应时间,因为在给定的时间窗口内请求了更多数据
本文档分为两个主要部分
配置最佳实践
编辑配置 Agent 资源
编辑Kubernetes 可观测性基于 Elastic Kubernetes 集成,该集成从多个组件收集指标
-
每个节点
- kubelet
- controller-manager
- scheduler
- proxy
-
集群范围(例如整个集群的唯一指标)
- kube-state-metrics
- apiserver
仅在实际基于自动发现规则运行的特定节点上启用 Controller manager 和 Scheduler 数据流
提供的默认清单将 Elastic Agent 部署为 DaemonSet,这会导致在 Kubernetes 集群的每个节点上都部署一个 Elastic Agent。
此外,默认情况下,一个 agent 被选为 领导者(有关更多信息,请访问 Kubernetes LeaderElection 提供程序)。拥有领导权锁的 Elastic Agent Pod 除了其节点的指标外,还负责收集集群范围的指标。
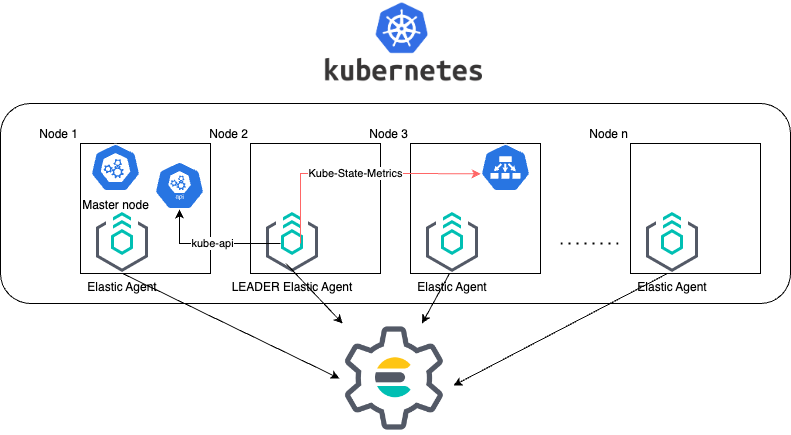
上面的架构说明了 Elastic Agent 如何收集指标并将其发送到 Elasticsearch。由于领导者 Agent 也负责收集集群级别的指标,这意味着它需要额外的资源。
具有领导者选举的 DaemonSet 部署方法简化了 Elastic Agent 的安装,因为我们在清单中定义的 Kubernetes 资源较少,并且我们的 Agent 只需要一个 Agent 策略。因此,它是 托管 Elastic Agent 安装的默认支持方法
在 Agent 清单中指定资源和限制
编辑Pod 的资源分配和它们的调度优先级(查看 调度优先级部分)是随着 Kubernetes 集群规模增加可能会受到影响的两个主题。不断增长的资源需求可能会导致集群的 Elastic Agent 资源不足。
根据我们的测试,我们建议仅在清单的 resources 部分中配置 limit 部分。这样,resources 的 request 设置将回退到指定的 limits。limits 是微服务进程的上限限制,这意味着它可以在较少的资源中运行,并保护 Kubernetes 分配更大的使用量,并防止可能的资源耗尽。
resources: limits: cpu: "1500m" memory: "800Mi"
根据我们的 Elastic Agent 扩展测试,下表提供了有关在不同 Kubernetes 大小上调整 Elastic Agent 限制的指南
示例 Elastic Agent 配置
K8s 集群中的 Pod 数量 |
领导者 Agent 资源 |
其余 Agent |
1000 |
cpu: "1500m", memory: "800Mi" |
cpu: "300m", memory: "600Mi" |
3000 |
cpu: "2000m", memory: "1500Mi" |
cpu: "400m", memory: "800Mi" |
5000 |
cpu: "3000m", memory: "2500Mi" |
cpu: "500m", memory: "900Mi" |
10000 |
cpu: "3000m", memory: "3600Mi" |
cpu: "700m", memory: "1000Mi" |
以上测试是在 Elastic Agent 8.7 版和
10 秒的抓取周期(Kubernetes 集成的周期设置)下进行的。这些数字仅是指标,应针对每个不同的 Kubernetes 环境和工作负载量进行验证。
为大规模提出的 Agent 安装
编辑尽管 daemonset 安装很简单,但它无法适应因收集的指标而异的 agent 资源需求。大规模适当资源分配的需求需要更细粒度的安装方法。
Elastic Agent 部署分为以下几组
- 用于从 apiserver 收集集群范围指标的单个 Agent 的专用 Elastic Agent 部署
- Daemonset 中的节点级 Elastic Agent(无领导者 Agent)
- kube-state-metrics 分片和 kube-state-metrics 自动分片清单中定义的 StatefulSet 中的 Elastic Agent
每个 Elastic Agent 组都将具有其特定于其功能的策略,并且可以在适当的清单中独立设置资源,以适应其特定的资源需求。
资源分配使我们找到了替代的安装方法。
大型集群的主要建议是将 Elastic Agent 作为 side container 与 kube-state-metrics 分片一起安装。安装详细信息请参阅 使用 Kustomize 在自动分片中安装 Elastic Agent
以下替代配置方法已经过验证
-
使用
hostNetwork:false- KSM 分片 pod 内的 Side Container 中的 Elastic Agent
- 对于每个 KSM 分片收集的非领导者 Elastic Agent 部署
- 使用
taint/tolerations将 Elastic Agent daemonset pod 与其余部署隔离
您可以在名为 Elastic Agent 清单以支持 Kube-State-Metrics 分片的文档中找到更多信息。
根据我们的 Elastic Agent 扩展测试,下表旨在帮助用户了解如何在 Kubernetes 集群扩展时配置其 KSM 分片
K8s 集群中的 Pod 数量 |
KSM 分片数 |
Agent 资源 |
1000 |
可以使用默认 KSM 配置处理 No Sharding |
limits: memory: 700Mi , cpu:500m |
3000 |
4 个分片 |
limits: memory: 1400Mi , cpu:1500m |
5000 |
6 个分片 |
limits: memory: 1400Mi , cpu:1500m |
10000 |
8 个分片 |
limits: memory: 1400Mi , cpu:1500m |
上面的测试是在 Elastic Agent 8.8 + TSDB 启用和
10 秒的抓取周期(对于 Kubernetes 集成)下进行的。这些数字仅是指标,应针对不同的 Kubernetes 策略配置以及 Kubernetes 集群可能包含的应用程序进行验证
测试已运行到每个集群 10K 个 pod。扩展到更大的 pod 数量可能需要 Kubernetes 端和云提供商的其他配置,但安装 Elastic Agent 并水平扩展 KSM 的基本思想保持不变。
Agent 调度
编辑与其他 pod 相比,将 Elastic Agent 设置为低优先级也可能导致 Elastic Agent 处于 Pending 状态。调度程序尝试抢占(驱逐)较低优先级的 Pod,以使较高挂起的 Pod 可以进行调度。
尝试在其余应用程序微服务之前优先安装 agent,建议使用 PriorityClasses
Kubernetes 包配置
编辑Kubernetes 包的策略配置会严重影响收集并最终摄取的指标数量。为了使您的收集和摄取更轻量,应考虑以下因素
- Kubernetes 端点的抓取周期
- 禁用日志收集
- 保持禁用审计日志
- 禁用事件数据集
- 在云托管的 Kubernetes 实例中禁用 Kubernetes 控制平面数据集(请参阅更多信息 **在 Fleet 管理的 GKE 上运行 Elastic Agent,在 Fleet 管理的 Amazon EKS 上运行 Elastic Agent,在 Fleet 管理的 Azure AKS 上运行 Elastic Agent页面)
仪表板和可视化
编辑仪表板指南文档提供了有关如何实施仪表板的指导,并且会不断更新以跟踪大规模可观测性的需求。
仪表板响应的用户体验也受到所请求数据大小的影响。由于仪表板可以包含多个可视化,因此一般考虑是拆分可视化并根据访问频率对其进行分组。可视化数量越少,往往会改善用户体验。
禁用索引 host.ip 和 host.mac 字段
编辑引入了一个新的环境变量 ELASTIC_NETINFO: false,以全局禁用 Kubernetes 集成中 host.ip 和 host.mac 字段的索引。有关更多信息,请参阅 环境变量。
对于 host.ip 和 host.mac 字段的索引大小增加的大规模设置,建议将其设置为 false。随着 Kubenetes 集群的增长,报告的 IP 和 MAC 地址的数量会显着增加。这会导致索引时间显着增加,以及需要额外的存储和可视化渲染的额外开销。
Elastic Stack 配置
编辑在大型部署中,需要考虑 Elastic Stack 的配置。对于 Elastic Cloud 部署,选择部署的 Elastic Cloud 硬件配置文件很重要。
对于繁重的处理和大摄取率需求,建议使用 CPU 优化配置文件。
验证和故障排除实践
编辑定义 Agent 是否按预期进行数据采集
编辑在 Elastic Agent 部署之后,我们需要验证 Agent 服务是否运行状况良好,没有重启(稳定性),并且指标的采集是否以预期的速率持续进行(延迟)。
关于稳定性
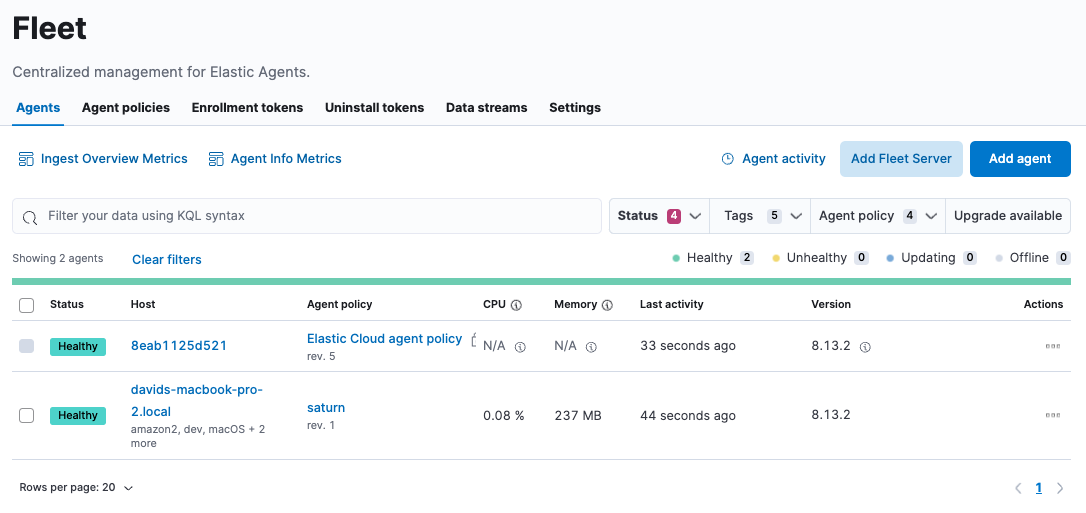
如果 Elastic Agent 配置为托管模式,您可以在 Kibana 的 Fleet > Agents 下进行观察。
此外,您可以使用以下命令验证进程状态
kubectl get pods -A | grep elastic kube-system elastic-agent-ltzkf 1/1 Running 0 25h kube-system elastic-agent-qw6f4 1/1 Running 0 25h kube-system elastic-agent-wvmpj 1/1 Running 0 25h
查找领导 Agent
❯ k get leases -n kube-system | grep elastic NAME HOLDER AGE elastic-agent-cluster-leader elastic-agent-leader-elastic-agent-qw6f4 25h
进入领导 Agent 并验证进程状态
❯ kubectl exec -ti -n kube-system elastic-agent-qw6f4 -- bash root@gke-gke-scaling-gizas-te-default-pool-6689889a-sz02:/usr/share/elastic-agent# ./elastic-agent status State: HEALTHY Message: Running Fleet State: HEALTHY Fleet Message: (no message) Components: * kubernetes/metrics (HEALTHY) Healthy: communicating with pid '42423' * filestream (HEALTHY) Healthy: communicating with pid '42431' * filestream (HEALTHY) Healthy: communicating with pid '42443' * beat/metrics (HEALTHY) Healthy: communicating with pid '42453' * http/metrics (HEALTHY) Healthy: communicating with pid '42462'
随着 Kubernetes 规模的增长,Agent 进程因缺乏 CPU/内存资源而重启是一个常见问题。在 Agent 的日志中
kubectl logs -n kube-system elastic-agent-qw6f4 | grep "kubernetes/metrics" [ouptut truncated ...] (HEALTHY->STOPPED): Suppressing FAILED state due to restart for '46554' exited with code '-1'","log":{"source":"elastic-agent"},"component":{"id":"kubernetes/metrics-default","state":"STOPPED"},"unit":{"id":"kubernetes/metrics-default-kubernetes/metrics-kube-state-metrics-c6180794-70ce-4c0d-b775-b251571b6d78","type":"input","state":"STOPPED","old_state":"HEALTHY"},"ecs.version":"1.6.0"} {"log.level":"info","@timestamp":"2023-04-03T09:33:38.919Z","log.origin":{"file.name":"coordinator/coordinator.go","file.line":861},"message":"Unit state changed kubernetes/metrics-default-kubernetes/metrics-kube-apiserver-c6180794-70ce-4c0d-b775-b251571b6d78 (HEALTHY->STOPPED): Suppressing FAILED state due to restart for '46554' exited with code '-1'","log":{"source":"elastic-agent"}
您可以通过运行 top pod 命令来验证即时资源消耗,并确定 Agent 是否接近您在清单中指定的限制。
kubectl top pod -n kube-system | grep elastic NAME CPU(cores) MEMORY(bytes) elastic-agent-ltzkf 30m 354Mi elastic-agent-qw6f4 67m 467Mi elastic-agent-wvmpj 27m 357Mi
验证数据摄取延迟
编辑可以使用 Kibana Discovery 来识别您的指标被摄取的频率。
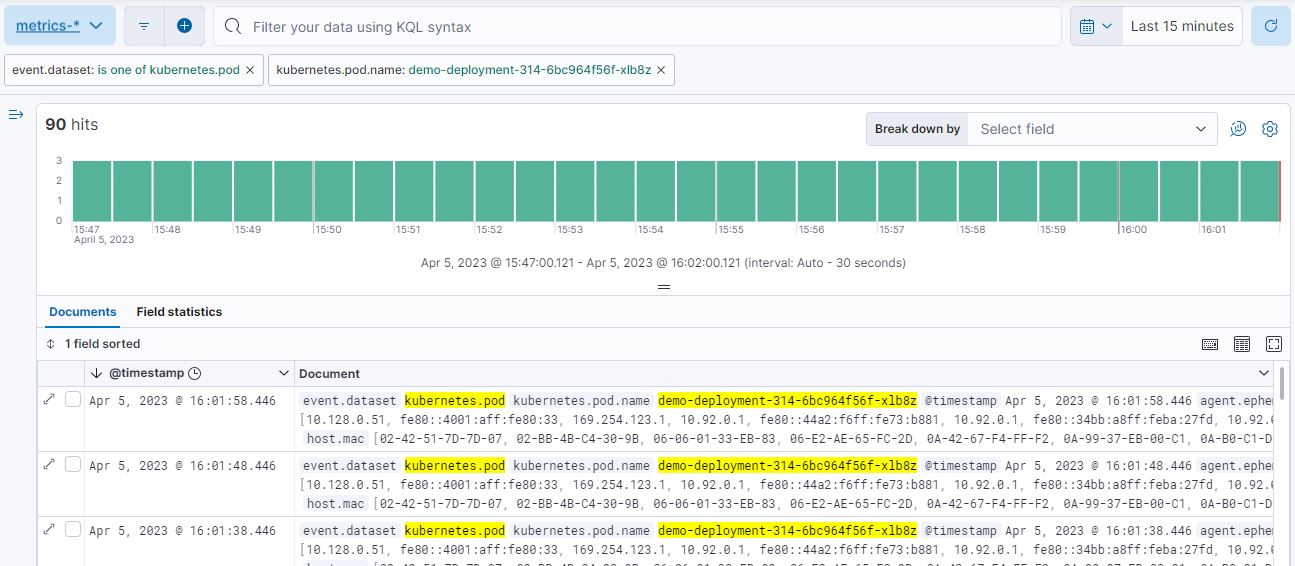
筛选 Pod 数据集
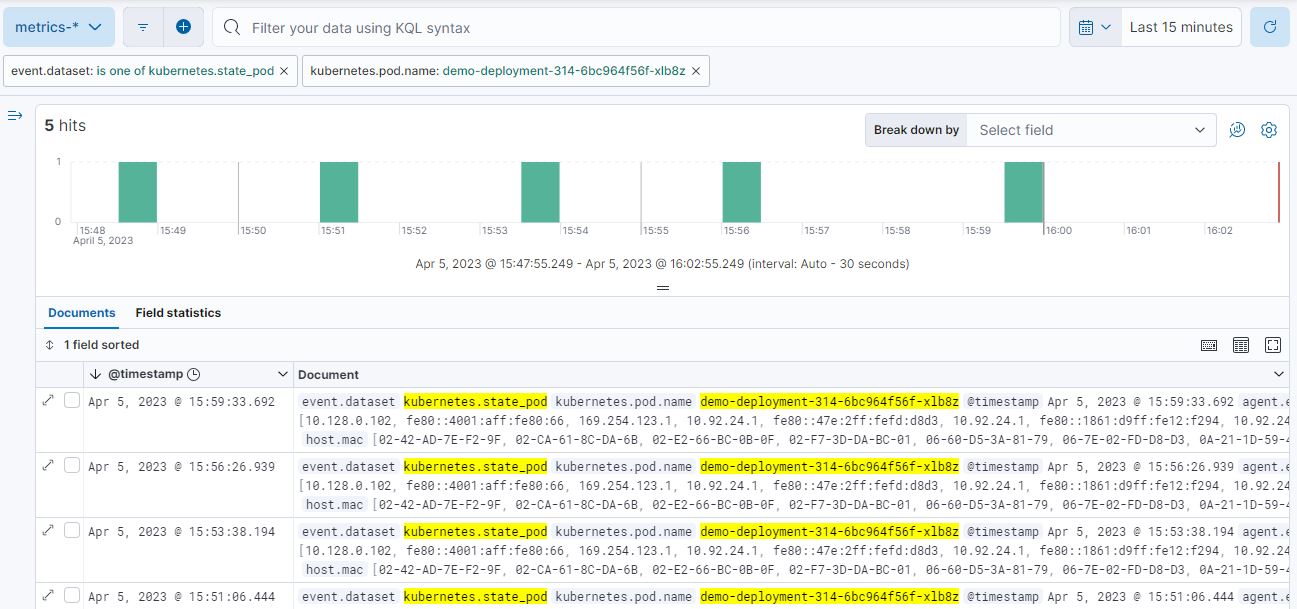
筛选 State_Pod 数据集
确定有多少事件已发送到 Elasticsearch
kubectl logs -n kube-system elastic-agent-h24hh -f | grep -i state_pod [ouptut truncated ...] "state_pod":{"events":2936,"success":2936}
事件的数量表示应该在 Kibana Discovery 页面中显示的文件数量。
例如,在一个拥有 798 个 Pod 的集群中,Kibana 中应该显示 798 个文件的摄取块。
定义 Elasticsearch 是否是数据摄取的瓶颈
编辑在某些情况下,Elasticsearch 可能无法应对尝试摄取的数据速率。为了验证资源利用率,建议安装 Elastic Stack 监控集群。
此外,在 Elastic Cloud 部署中,您可以导航到 Manage Deployment > Deployments > Monitoring > Performance。 CPU Usage、Index Response Times 和 Memory Pressure 的相应仪表板可以揭示潜在的问题,并建议对 Elastic Stack 资源进行垂直扩展。