死信队列 (DLQ)
编辑死信队列 (DLQ)
编辑死信队列 (DLQ) 被设计为临时写入无法处理的事件的地方。DLQ 使您可以灵活地调查有问题的事件,而不会阻塞管道或丢失事件。您的管道保持流动,并且立即解决问题。但是这些事件仍然需要处理。
您可以使用 从 DLQ 处理事件 与 dead_letter_queue 输入插件 。
处理事件不会从队列中删除项目,DLQ 有时需要注意。有关更多信息,请参阅 跟踪死信队列大小 和 清除死信队列。
死信队列的工作原理
编辑默认情况下,当 Logstash 遇到因数据包含映射错误或其他问题而无法处理的事件时,Logstash 管道要么挂起,要么删除失败的事件。为了在这种情况下防止数据丢失,您可以 配置 Logstash 将失败的事件写入死信队列,而不是删除它们。
目前,死信队列仅支持 Elasticsearch 输出 和 条件语句评估。死信队列用于响应代码为 400 或 404 的文档,这两者都表示无法重试的事件。当条件评估遇到错误时也会使用它。
写入死信队列的每个事件都包含原始事件、描述事件无法处理的原因的元数据、有关写入事件的插件的信息以及事件进入死信队列的时间戳。
要处理死信队列中的事件,请创建一个 Logstash 管道配置,该配置使用 dead_letter_queue 输入插件 从队列中读取。有关更多信息,请参阅 处理死信队列中的事件。
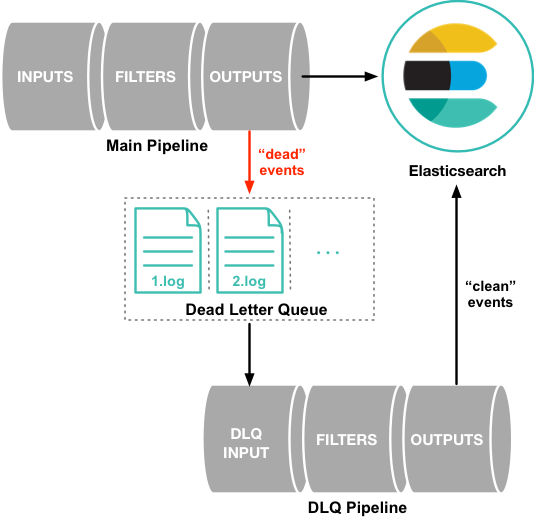
Elasticsearch 处理和死信队列
编辑HTTP 请求失败。 如果 HTTP 请求失败(因为 Elasticsearch 无法访问或因为它返回了 HTTP 错误代码),Elasticsearch 输出会无限期地重试整个请求。在这些情况下,死信队列没有机会拦截。
HTTP 请求成功。 Elasticsearch Bulk API 可以使用相同的请求执行多个操作。如果 Bulk API 请求成功,它会返回 200 OK,即使批处理中的某些文档 失败。在这种情况下,请求的 errors 标志将为 true。
响应正文可以包含元数据,指示批量请求中的一个或多个特定操作无法执行,以及每个条目的 HTTP 样式状态代码,以指示操作无法执行的原因。如果配置了 DLQ,则个别索引失败将被路由到那里。
即使您定期处理事件,事件仍会保留在死信队列中。死信队列需要 手动干预 来清除它。
条件语句和死信队列
编辑当条件语句在处理事件时遇到错误时(例如,比较字符串和整数值),该事件(在评估时)将被插入到死信队列中。
配置 Logstash 以使用死信队列
编辑默认情况下,死信队列处于禁用状态。要启用死信队列,请在 logstash.yml 设置文件 中设置 dead_letter_queue_enable 选项
dead_letter_queue.enable: true
死信队列作为文件存储在 Logstash 实例的本地目录中。默认情况下,死信队列文件存储在 path.data/dead_letter_queue 中。每个管道都有一个单独的队列。例如,main 管道的死信队列默认存储在 LOGSTASH_HOME/data/dead_letter_queue/main 中。队列文件按顺序编号:1.log、2.log 等。
您可以在 logstash.yml 文件中设置 path.dead_letter_queue,以指定文件的不同路径
path.dead_letter_queue: "path/to/data/dead_letter_queue"
使用本地文件系统以保证数据完整性和性能。不支持网络文件系统 (NFS)。
死信队列条目被写入一个临时文件,然后将其重命名为死信队列段文件,该文件随后有资格进行摄取。当此临时文件被视为已满时,或者自上次将符合条件的死信队列事件写入临时文件以来经过一段时间时,就会发生重命名。
可以使用 dead_letter_queue.flush_interval 设置来设置此时间长度。此设置以毫秒为单位,默认为 5000 毫秒。此处的值较低意味着在不频繁地写入死信队列的情况下,可能会写入更多、更小的队列文件,而较大的值会在将项目“写入”死信队列与死信队列输入可读取之间引入更多延迟。
Note that this value cannot be set to lower than 1000ms.
dead_letter_queue.flush_interval: 5000
您不能为两个不同的 Logstash 实例使用相同的 dead_letter_queue 路径。
文件轮换
编辑死信队列具有内置的文件轮换策略,该策略管理队列的文件大小。当文件大小达到预配置的阈值时,会自动创建一个新文件。
大小管理
编辑默认情况下,每个死信队列的最大大小设置为 1024mb。要更改此设置,请使用 dead_letter_queue.max_bytes 选项。如果条目会使死信队列的大小超过此设置,则会将其删除。使用 dead_letter_queue.storage_policy 选项来控制应删除哪些条目,以避免超出大小限制。将值设置为 drop_newer(默认),以停止接受会使文件大小超出限制的新值。将值设置为 drop_older,以删除最旧的事件,为新事件腾出空间。
年龄策略
编辑您可以使用年龄策略来自动控制死信队列中的事件量。使用 dead_letter_queue.retain.age 设置(在 logstash.yml 或 pipelines.yml 中)让 Logstash 删除早于您定义的值的事件。可用的时间单位分别为 d、h、m、s,分别表示天、小时、分钟和秒。没有默认的时间单位,因此您需要指定它。
dead_letter_queue.retain.age: 2d
年龄策略在事件写入和管道关闭期间进行验证和应用。因此,您的死信队列文件夹可能会存储过期的事件的时间长于指定的时间,并且读取器管道可能会遇到过时的事件。
自动清理已使用事件
编辑默认情况下,死信队列输入插件不会删除它使用的事件。相反,它会提交一个引用以避免重新处理事件。在死信队列输入插件中使用 clean_consumed 设置,以便删除已完全使用的段,从而在处理过程中释放空间。
input { dead_letter_queue { path => "/path/to/data/dead_letter_queue" pipeline_id => "main" clean_consumed => true } }
处理死信队列中的事件
编辑当您准备好处理死信队列中的事件时,您可以创建一个管道,该管道使用 dead_letter_queue 输入插件 从死信队列中读取。您使用的管道配置当然取决于您需要做什么。例如,如果死信队列包含因 Elasticsearch 中的映射错误而产生的事件,则可以创建一个管道,该管道读取“死”事件,删除导致映射问题的字段,然后将清理后的事件重新索引到 Elasticsearch 中。
以下示例显示了一个简单的管道,该管道从死信队列读取事件,并将包括元数据的事件写入标准输出
input { dead_letter_queue { path => "/path/to/data/dead_letter_queue" commit_offsets => true pipeline_id => "main" } } output { stdout { codec => rubydebug { metadata => true } } }
|
包含死信队列的顶级目录的路径。此目录包含为每个写入死信队列的管道单独的文件夹。要查找此目录的路径,请查看 |
|
|
当为 |
|
|
写入死信队列的管道的 ID。默认值为 |
有关另一个示例,请参阅 示例:处理具有映射错误的数据。
当管道完成处理死信队列中的所有事件时,它将继续运行并处理新事件,因为它们会流到队列中。这意味着您不需要停止生产系统来处理死信队列中的事件。
如果来自 dead_letter_queue 输入插件 插件发出的事件无法正确处理,则不会将其重新提交到死信队列。
从时间戳读取
编辑当您从死信队列读取时,您可能不想处理队列中的所有事件,尤其是在队列中有很多旧事件的情况下。您可以使用 start_timestamp 选项从队列中的特定点开始处理事件。此选项配置管道以根据事件进入队列的时间戳开始处理事件
input { dead_letter_queue { path => "/path/to/data/dead_letter_queue" start_timestamp => "2017-06-06T23:40:37" pipeline_id => "main" } }
在此示例中,管道开始读取在 2017 年 6 月 6 日 23:40:37 或之后传递到死信队列的所有事件。
示例:处理存在映射错误的数据
编辑在此示例中,用户尝试索引包含 geo_ip 数据的文件,但由于数据包含映射错误而无法处理。
{"geoip":{"location":"home"}}
索引失败,因为 Logstash 输出插件期望 location 字段中存在一个 geo_point 对象,但该值是一个字符串。失败的事件以及导致失败的错误的元数据会被写入死信队列。
{ "@metadata" => { "dead_letter_queue" => { "entry_time" => #<Java::OrgLogstash::Timestamp:0x5b5dacd5>, "plugin_id" => "fb80f1925088497215b8d037e622dec5819b503e-4", "plugin_type" => "elasticsearch", "reason" => "Could not index event to Elasticsearch. status: 400, action: [\"index\", {:_id=>nil, :_index=>\"logstash-2017.06.22\", :_type=>\"doc\", :_routing=>nil}, 2017-06-22T01:29:29.804Z My-MacBook-Pro-2.local {\"geoip\":{\"location\":\"home\"}}], response: {\"index\"=>{\"_index\"=>\"logstash-2017.06.22\", \"_type\"=>\"doc\", \"_id\"=>\"AVzNayPze1iR9yDdI2MD\", \"status\"=>400, \"error\"=>{\"type\"=>\"mapper_parsing_exception\", \"reason\"=>\"failed to parse\", \"caused_by\"=>{\"type\"=>\"illegal_argument_exception\", \"reason\"=>\"illegal latitude value [266.30859375] for geoip.location\"}}}}" } }, "@timestamp" => 2017-06-22T01:29:29.804Z, "@version" => "1", "geoip" => { "location" => "home" }, "host" => "My-MacBook-Pro-2.local", "message" => "{\"geoip\":{\"location\":\"home\"}}" }
为了处理失败的事件,您需要创建以下管道,该管道从死信队列中读取数据并消除映射问题。
input { dead_letter_queue { path => "/path/to/data/dead_letter_queue/" } } filter { mutate { remove_field => "[geoip][location]" } } output { elasticsearch{ hosts => [ "localhost:9200" ] } }
|
|
|
|
|
|
|
清理后的事件将发送到 Elasticsearch,在那里可以进行索引,因为映射问题已解决。 |
跟踪死信队列的大小
编辑在死信队列成为问题之前对其大小进行监控。通过定期检查,您可以确定每个管道的最大队列大小。
每个管道的 DLQ 大小可在节点统计 API 中找到。
pipelines.${pipeline_id}.dead_letter_queue.queue_size_in_bytes.
其中 {pipeline_id} 是启用了 DLQ 的管道的名称。
清除死信队列
编辑无法在运行上游管道时清除死信队列。
死信队列是一个页面目录。要清除它,请停止管道并删除 location/<file-name>。
${path.data}/dead_letter_queue/${pipeline_id}
其中 {pipeline_id} 是启用了 DLQ 的管道的名称。
管道在再次启动时会创建一个新的死信队列。